
Claude Code 定义了当前 AI 编程工具的上限,但它不对中国开发者开放。这个缺口,就是 DeepSeek 的机会。最新组建的团队,正在补上这一层最关键的基础设施——它叫 Harness。
DeepSeek 公开招兵买马:从零开始,对标 Claude Code
5 月中下旬,DeepSeek 开始了一场横跨多个平台的招聘动作:官网、小红书、X 同步放出信息,目标是组建一支全新的 Harness 团队,从零开始构建对标 Claude Code 的代码智能体产品。
DeepSeek 官网上发布的“Agent Harness 产品经理”和“Agent Harness 研发工程师”职位,开头就写着一句很醒目的公式:Model + Harness = Agent。DeepSeek 对这个团队的定义很清楚:他们正在把 DeepSeek 的前沿模型能力转化为领先的 Agent 产品,而除模型本身以外的所有工作,都属于 Harness 的范畴。
在小红书上,“陈小礼”发布的帖子也非常直白:“简单来说就是对标 Claude Code,做 DeepSeek Code Harness”。
在 X(推特)上,DeepSeek 高级研究员陈德里(Deli Chen)发布了一条更带个人色彩的招聘推文:
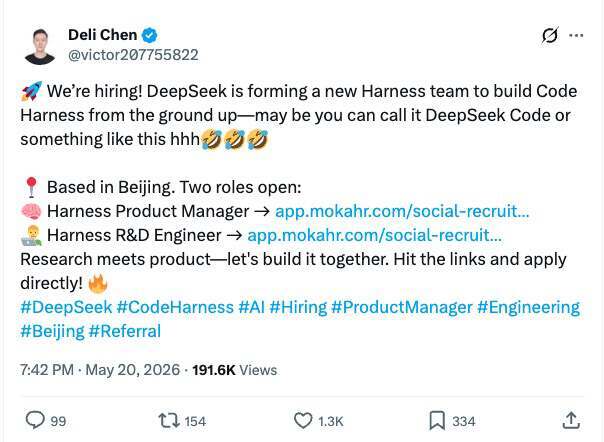
陈德里毕业于北京大学,于 2023 年加入 DeepSeek 担任研究员,此后他的名字多次出现在公司发布的重要研究报告中。由于创始人梁文锋很少公开露面,陈德里已成为公司对外沟通的重要代表,曾在 2024 年 NVIDIA GTC 开发者大会和 2025 年世界互联网大会乌镇峰会上发表过公开演讲。
在这条推文的评论区,陈德里还补充了一句:“简历直达部门老大”,鼓励大家私信内推。这条推文获得了超过 30 万次浏览,以及 1600 多个点赞。网友反应普遍积极,可以说是万众期待。连 Redis 之父也在头排推荐人选 Armin Ronacher(Rust 核心贡献者、常用命令行工具的知名开发者)和 Mario Zechner(游戏开发领域的技术专家)。
再回到官网 JD,会发现 DeepSeek 对这个产品的要求很高。这个团队要连接研究员、工程师、开源社区和大厂用户,把真实任务里的问题、反馈和使用数据,反过来喂给产品和模型训练。
职位要求覆盖了当前 Agent 工程涉及的多个关键技术方向。DeepSeek 还明确写到,候选人要深度使用过 Claude Code、Cowork、Codex、Cursor、OpenCode、GitHub Copilot、Manus、OpenClaw、Hermes 等类似产品,并熟悉其中的使用方法、设计思想和产品实现。这已经不是传统产品经理的画像,而是一个真正理解 coding agent、开发者工具和 Agent 工作流的人。
还有一个细节也很 DeepSeek:官网职位的加分项最后写着,“其它超乎常人的与工作相关的才能”。这句带点极客气质的表达,甚至可以理解为这个产品不仅要对标 Claude Code,更是希望它能做到“标新立异”一些。

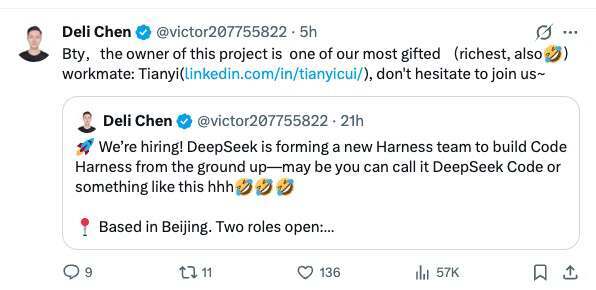
陈德里还特地指出,DeepSeek 已经招揽了曾在 Jane Street 工作多年、“有才华且富有”的工程师 Cui Tianyi,加入这个 Harness 团队。Cui Tianyi 毕业于浙江大学,在 Jane Street 工作了近九年,从事股票和固定收益领域的软件开发与研究,后联合创办了香港量化基金 TSY Capital。
Anthropic 一边定义未来,一边把中国开发者挡在门外
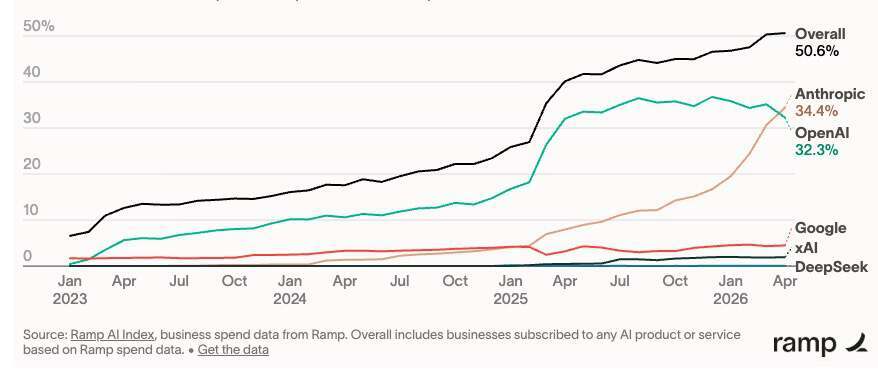
最近,Anthropic 在企业 AI 采用率上,把 OpenAI 从王座上拽了下来。
过去一年,Anthropic 的客户增长接近四倍,OpenAI 却几乎原地踏步。在首次采购 AI 服务的企业里,Anthropic 面对 OpenAI 的正面竞争,已经能赢下约 70% 的订单。Ramp 的报告说,这是“一个惊人的逆转”——他们从未见过一个软件行业的新来者能在短短几个月内颠覆市场领导者地位。这也足够说明 Anthropic 已经从“模型公司”变成了企业软件工作流里的重要供应商。
去年 2 月,Claude Code 推出预览版,不到一年就跑出数十亿美元的年化收入。但更重要的是,Claude Code 不只是一个编程工具,而是 AI Agent 发展中的一个转折点。按 Claude Code 创建者 Boris Cherny 的说法,代码只是第一个跑通的场景。根据 SemiAnalysis 在 2026 年 2 月的报告,Claude Code 已经占到 GitHub 公开提交量的 4%,而且仅在一个月内日活用户就翻了一倍。
Boris Cherny 说,对他日常做的编程工作,Claude 基本已经能搞定,2026 年底就会“跨 domain 变成所有人的通用能力”。也就是说,Anthropic 先拿代码开刀,是因为代码反馈明确、工具链成熟、易验证。coding 则是第一个被打穿的工作流,下一步是把这种 agentic 工作方式扩展到更多职业和日常办公场景。
然而 Anthropic 一路高歌猛进的同时,又一直把中国开发者挡在门外。Anthropic 官方明确禁止中国大陆访问 Claude。2025 年 9 月,它又出了更狠的政策:任何由中国资本控制超过 50%的公司,不管注册地在哪,都不准用。而 CEO 达里奥·阿莫迪本人也公开主张对中国实施技术制裁。
结果是:全球最好的 AI 编程产品之一,正在重新定义下一代软件开发的工作方式,而中国开发者连正式使用的资格都没有。今年 4 月还有报道指出,尽管封禁存在,Claude 在中国仍然需求旺盛,灰色渠道正在扩大:Claude Code 越强,这个缺口就越大。
这就是 DeepSeek 做 Harness 最直接的背景:不是“我们要做一个更好的工具”,而是“我们没有别的选择”。
Harness 为什么突然成了必争之地?
同一个模型,换一套 Harness,结果可能完全不同。
以 Claude Opus 4.5 为例:放进 Claude Code 的 Harness,在 CORE-Bench Hard 上能达到 95%;换成一个朴素的 Hugging Face Smolagents 配置,成绩只剩 42%。同样的权重、同样的智能水平,单是 Harness 就拉开了 53 个百分点。
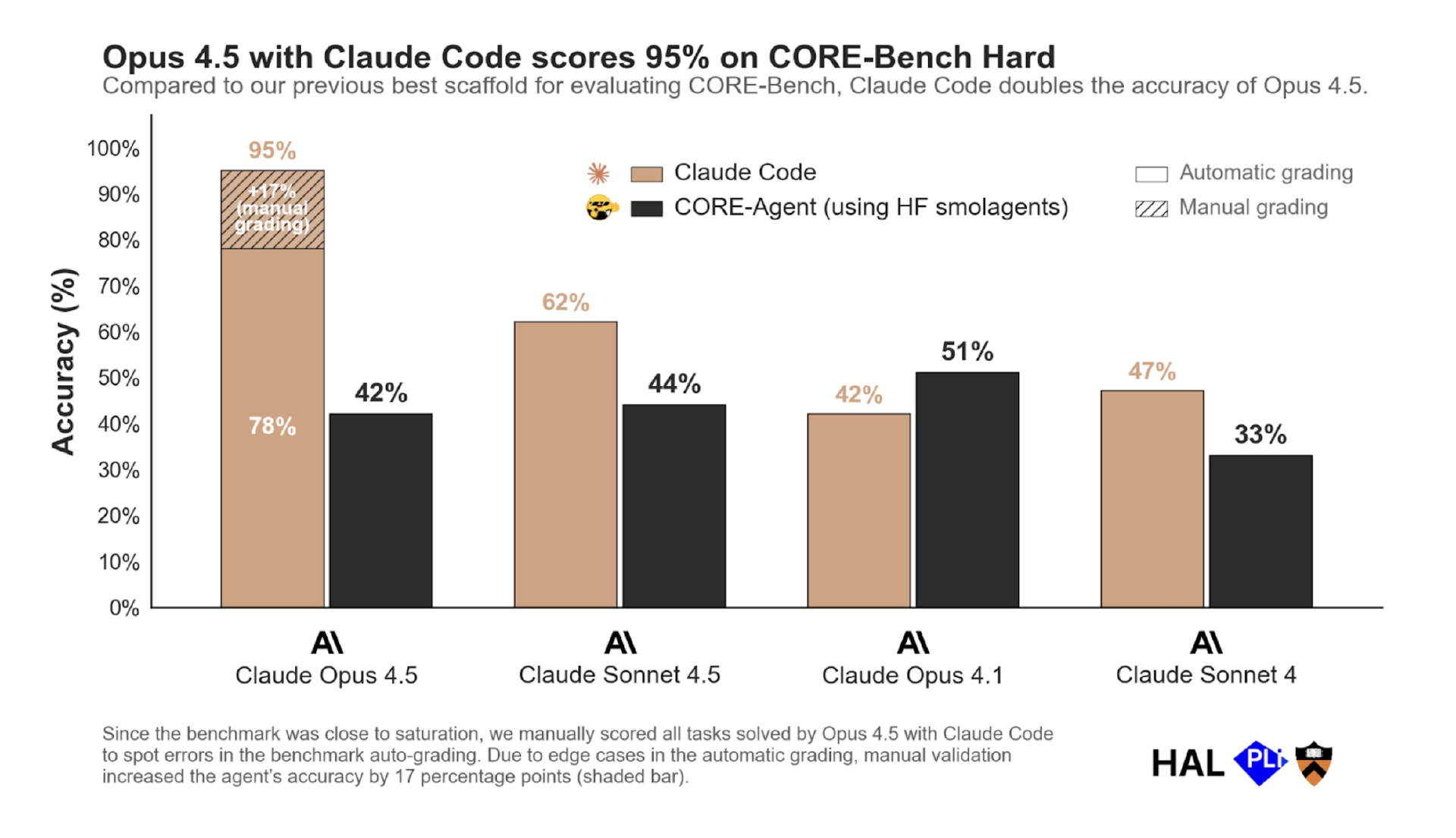
https://x.com/sayashk/status/1996334941832089732
Terminal Bench 上也能看到类似现象:头部清一色用 Claude Opus 4.6,大家拼的已经不是模型,而是谁的 Harness 更好。更极端一点,一个更小、更便宜的模型,只要配上设计良好的 Harness,也可能打败一个大模型加粗糙 Harness。
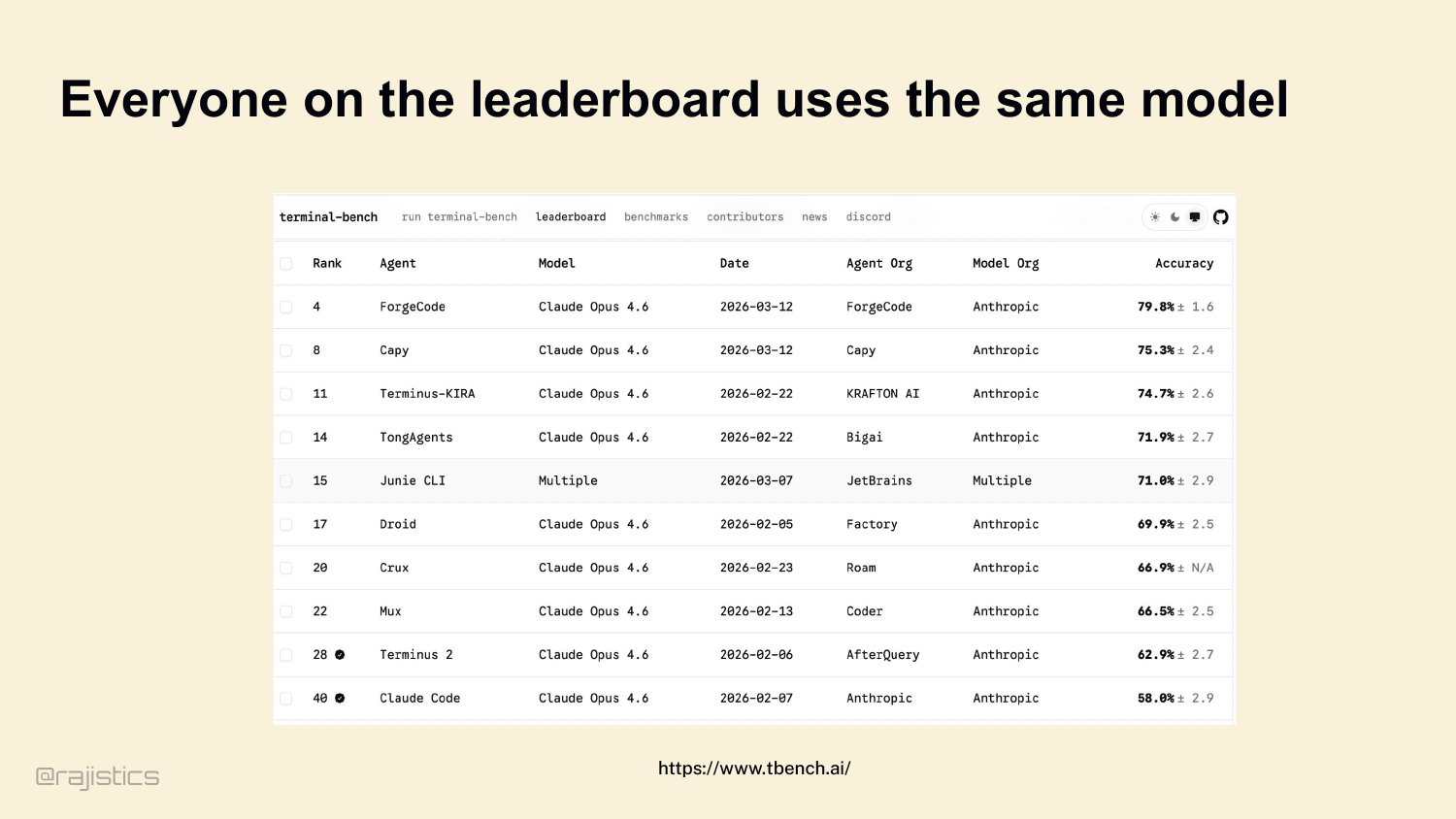
这就是 2026 年 Harness 突然站到台前的原因。AI 编程已经过了“模型会不会写代码”的阶段,现在几乎所有前沿模型都会写代码,真正拉开差距的地方,变成了模型能不能在真实代码库里稳定干活。
AI 行业的关注点一直在往模型外层移动。2022 年,大家盯着权重、微调和 RLHF;2023 年,焦点转向上下文、RAG 和长上下文;2024 年,工具调用、MCP 成了关键词;到了 2026 年,真正站到台前的,是最外层的 Harness。
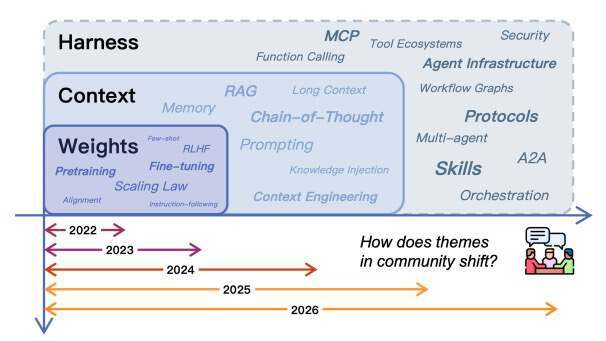
截图来源:https://arxiv.org/pdf/2604.08224
几年前,语言模型处理的还是很轻的任务:给它一段评论,让它判断情绪,几十个 token,几乎瞬间返回。现在的 coding agent 面对的是另一类任务:看完整个代码库,找到 bug,写补丁,跑测试,再验证结果。一次任务可能消耗上千万 token、持续几十分钟,背后还有数百次工具调用。到了这个阶段,单个模型已经撑不起全部体验,真正决定成败的是模型外面那套系统。
Harness 负责组织代码库、项目规则、上下文摘要;控制迭代次数、重试策略和任务边界;把模型的决策转成 shell 命令、文件编辑和测试执行,再把测试失败、日志输出、浏览器截图重新喂回模型。现代 coding agent 跑的已经不是一次性问答,而是一个“思考—行动—反馈—修正”的长循环。这个循环能不能跑稳,靠的就是 Harness。
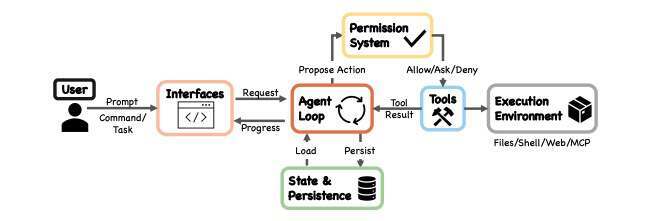
截图来源:https://arxiv.org/pdf/2604.14228
Claude Code 的内部机制,也正好说明了这一点。它的核心并不神秘,本质上就是一个 loop:调用模型,运行工具,拿到反馈,再继续调用模型。
真正的护城河在外围:权限控制、上下文压缩、MCP 工具、插件、Skills、Hooks、Subagent 调度、会话存储和安全策略。它把一个简单循环包成了可控、可扩展、可长时间运行的工程系统。
不同的产品会长出不同的 Harness。Claude Code 重安全与稳定性,OpenClaw 重开放与可实验性——没有标准答案,所以各家公司必须自己掌握这套能力。
Claude Code 的爆发,正是 Harness 的力量。它用的模型并不比对手强一大截,但 Harness 做得细——终端集成、文件读写、权限控制、代码检索、并行子 Agent,组合成一个开发者愿意天天用的环境。你扔给它一句“修这个 bug”,它不会只生成代码让你复制粘贴,而是会沿着代码库往下走:定位、修改、运行、读报错、再修正。对开发者来说,这才是 AI 编程从“玩具”变成“生产力工具”的分界线。
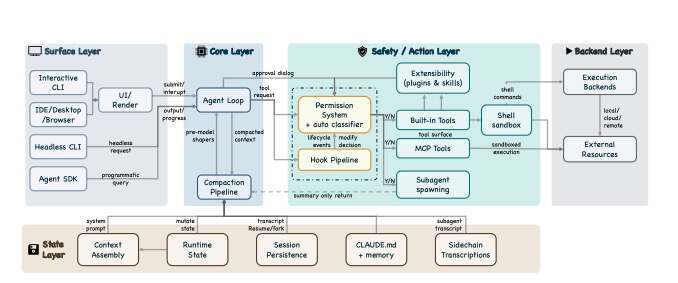
截图来源:https://arxiv.org/pdf/2604.14228
而且 Claude Code 改变的不只是效率,而是任务边界。Anthropic 内部调查显示,约 27% 的任务是开发者没有这个工具时原本不会尝试的。它把“太麻烦、不值得、不敢碰”的工作变成可尝试的任务,让 AI 编程的价值从“省时间”转向“扩大人能做什么”。
更关键的是,Anthropic 把这套 Harness 放出去,每一次真实使用都在收集问题、失败轨迹和用户修正,反哺模型训练,形成了飞轮效应。模型越强,Harness 越顺手;Harness 越顺手,使用越多,模型进步越快。
只做模型,远远不够:模型和 Harness 一起进化
DeepSeek 现在最需要补的,正是这一点。它已经有足够强的模型,也有很强的开发者认同,但模型本身不会自动变成 Claude Code。一个强模型如果只是接在 API 后面,它依然只是一个模型;只有进入一套成熟的 Harness,它才能开始接触真实代码库、真实终端、真实测试、真实失败路径,并在这些反馈里不断变得更能干。
Claude Code 的演进史说明,模型和 Harness 从来不是两条分开的线。
Boris Cherny 曾在 Claude Code 一周年时回顾说,一年前,Claude 连写 bash 命令、处理字符串转义都还很吃力,一次只能运行几秒钟或几分钟;一年后,几乎整个 Claude Code 都是由 Claude Code 自己写出来的,而且 Claude 已经可以稳定地连续运行几分钟、几小时,甚至几天。

仅仅一年时间,变化幅度非常大。
长运行时直接区分了“会写代码”和“能完成任务”。 短任务里,模型一次生成就够了;而真实工程任务是持续的“修改、测试、出错、再修改”循环,可能持续几十分钟甚至数小时。一个只能稳定跑几分钟的 Agent,本质上仍是代码助手;而一个能跑几小时甚至几天的 Agent,才开始像真正的工程代理。
而长时间运行的难点在于:上下文窗口有限且越跑越乱,模型规划能力弱容易半途而废,它还总高估自己的完成度——明明只做了半成品,却会说“好了”。
解决这些问题有两条路。第一条是模型本身,把能力直接烘焙进权重。根据 Anthropic 展示的图表,在最小脚手架下,一个代理能稳定完成 50%任务的运行时长,从 Opus 3.7 的大约 1 小时,提升到 Opus 4.6 的 12 小时,并且已经很难再提升了。第二条路是改 Harness,也就是模型外面的脚手架。
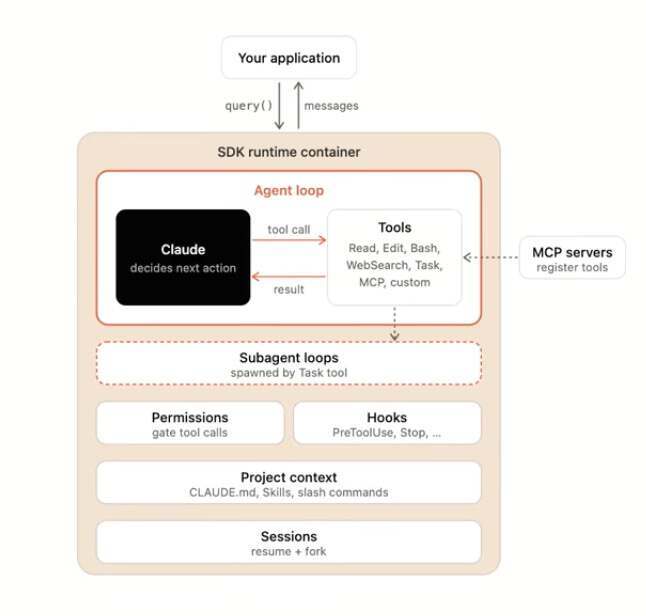
回顾过去一年的发布节奏,每次发布新模型,几乎都会同步更新 Harness。两者不是先后关系,而是一起共同演化。
一年前,Sonnet 3.5 第一次在 Claude.ai 的 artifacts 里展现出编码潜力——它能自己验证构建出的东西,然后继续迭代。那是 Claude Code 出现前的第一个“aha 时刻”。
2025 年 2 月,Sonnet 3.7 发布,同时 Claude Code 以研究预览版发布。Anthropic 在公告中明确写道:“我们推出 Claude Code 的目标,是更好地理解开发者如何使用 Claude 进行编码,从而为未来的模型改进提供依据。”也就是说,Claude Code 从一开始就不只是一个开发者工具,更是一个实验性入口——用来观察开发者如何使用 Claude 编码,并把这些观察反哺给模型训练。它承担的任务,远不止产品本身,而是“让模型暴露真实问题”。
同年 5 月,Opus 4 和 Sonnet 4 发布,模型在管理上下文、推进任务方面变得更好。Claude Code 正式 GA,SDK 开放(也就是驱动 Claude Code 的那套 Harness 被公开)。到了 Sonnet 4.5,模型开始具备上下文感知能力,但还不够稳定,于是 Harness 加入了 checkpoints(回退机制)来补这个缺口,运行时长被推到约 30 小时。
这时,Claude Code SDK 改名为 Agent SDK,因为 Anthropic 意识到它的用途比编码广泛得多:这些长时间运行的 harness 可以应用到其他领域了。
Haiku 4.5 和 Opus 4.5 补齐后,用 Opus 做规划、Sonnet 做执行的分工成为可能——这又是 Harness 在模型分化出不同特长后重新编排的结果。同时发布的 skills 采用渐进式披露,本质上也是为了补“上下文窗口”不够用的缺。
随后是 Opus 4.6 和 Sonnet 4.6。Sonnet 4.6 以更低价格提供 Opus 级别的智能,成为主力编码模型;Opus 4.6 则在规划上极强,被称作“非常 agentic 的模型”——在极简 Harness 下,稳定运行时长从约 4 小时跳到了 12 小时。伴随这次发布,Anthropic 推出了 agent teams(子代理之间可以直接沟通,减少主代理负担)、server-side compaction(服务端压缩,解决上下文爆满问题)以及 100 万上下文窗口。这些都是 Harness 在模型变强后重新设计的“脚手架”。
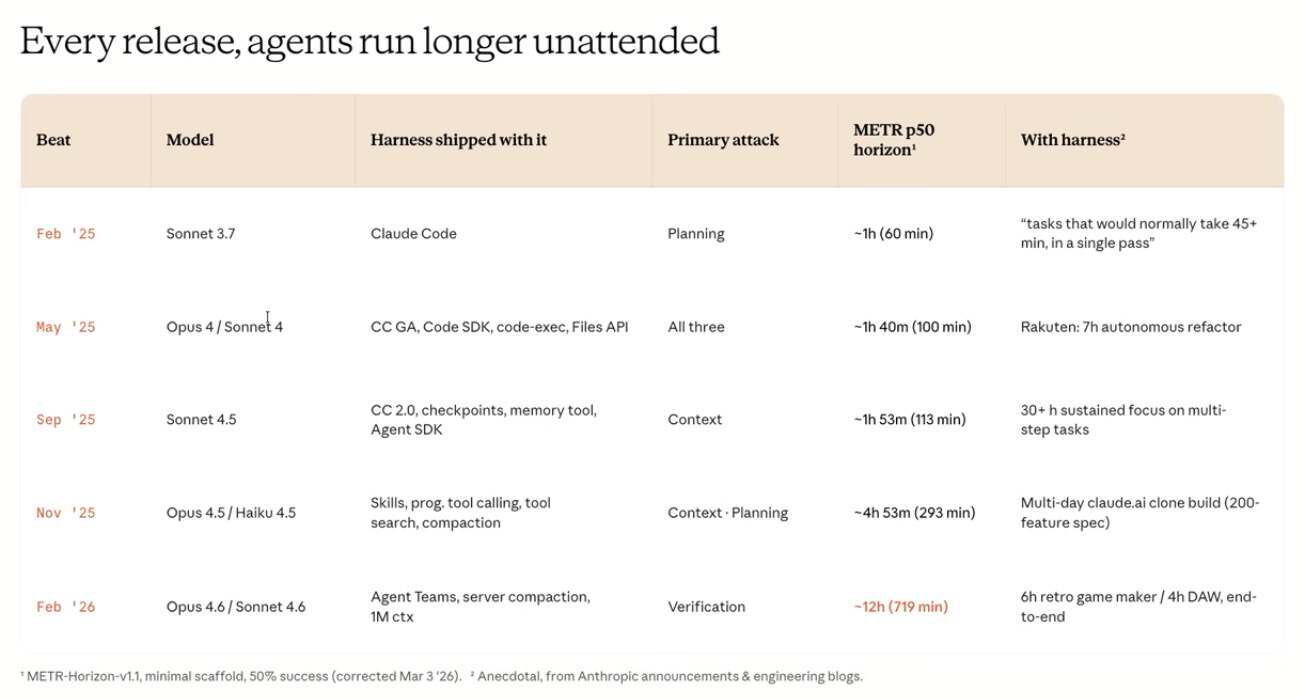
每一次模型的升级,都伴随着 Harness 的同步进化。模型变强,Harness 就利用新能力去补新缺口,或者把旧逻辑简化。Anthropic 方面的总结是:“找到模型里的缺口,用 Harness 补上,再用 Harness 的数据去训练模型——到某个时间点,那部分 Harness 可能就不再需要了,然后循环继续。”
这也是 DeepSeek 面临的真正挑战。做一个代码助手的外观并不难,把模型接进终端、给它文件读写和命令执行,也只是第一步。真正难的是建立自己的长时运行闭环:让 DeepSeek 模型在真实代码库里工作,让 Harness 记录它在哪里失败、为什么失败、用户怎么修正,再把这些失败变成下一轮产品设计、工具设计和模型训练的输入。如果 DeepSeek 只做模型,它永远会被包在别人的工具里;如果它能跑通模型和 Harness 共同演化的循环,它才有机会长出自己的 Claude Code。
结语:模型之外,皆属 Harness
DeepSeek 官网那句 Model + Harness = Agent,正在成为行业共识。控制层不再只是模型的附属品,而是一个独立的产品维度。没有 Harness,模型只是能力;有了 Harness,模型才开始变成能运行、能交付、能持续迭代的产品。
更大的变化是,Harness 本身正在变成一个新市场。Anthropic 选择把托管运行时单独计费,按会话小时收费;谷歌和微软把会话、内存、代码执行、工具调用拆成平台里的消费项;OpenAI 则把 Agents SDK 开源,不额外收第一方运行时费用,只对模型和工具调用收费。各家都承认这层很重要,分歧只在于它到底应该是什么:一个付费托管服务,一组平台原语,还是一个用来带动模型消费的免费开源层。
DeepSeek 的机会也在这里。它本来就有模型价格优势,如果再补上一套自己的 Code Harness,就不只是“用更便宜的模型对标 Claude”,而是用更低成本的模型,加上自己的 Agent 工程系统,去挑战 Claude Code 这类产品的完整体验。AI 编程下一阶段拼的不是单点模型,也不是单点工具,而是模型能力、Harness 设计、运行成本和开发者入口的组合。
参考链接:
https://arxiv.org/pdf/2604.08224
https://arxiv.org/pdf/2604.14228
https://www.youtube.com/watch?v=mR-WAvEPRwE
https://www.infoq.cn/article/Z3MKvAKFC2Hjjk643oKQ
https://www.anthropic.com/engineering/harness-design-long-running-apps




