
一、云上架构大数据平台的挑战和机遇
选择 Cloud 还是 Local 的诸多讨论和实践中,成本一直是绕不开的话题。
“公有云太贵了,一年机器就够托管三五年了”,这基本上是刚开始接触公有云的企业,在进行了详细价格对比后的第一结论,也因此导致国内中大型公司很少选择公有云。
反观国外很多中大型企业(例如 netflix,pinterest),还有体量较大的中国出海公司(如 Shareit,mobvista)会倾向选择公有云。
什么原因导致了这样的差异呢?核心差异就在于云原生技术的普及和落地。
具体到数据平台差异的核心就是云原生数据湖架构极大的降低了企业的上云成本,可以达到比 Local 更低的 IT 成本,同时享受公有云的各种好处。
1. 挑战
直接迁移 local 大数据平台(存算耦合且固定规模)存在下面问题:
利用率低/时效性差:预留资源太多利用率低,集群规模过小数据生产时效性差;
灵活性差:很难快速应对多变的 adhoc 需求 /backfill 等类型任务;集群升级困难,迁移数据;
成本高:基于 hdfs 的存储规模跟计算规模不匹配,大量浪费;云主机本身小时价格高;hdfs 维护成本高;
性能差:统一实例类型,不能很好优化不同计算负载要求,比如 shuffle 本地磁盘 iops 等等;
可靠性难以保障:容灾以及利用多 az(可用区)计算资源难,hdfs 多 az 部署,跨 az 流量属于紧缺型资源,通常比较紧张。
2. 机遇:公有云共享经济
弹性计算:充分利用弹性计算能够大幅度降低成本,尤其是利用更低价的 spot 机器;
对象存储:云服务对象存储得益于 EC 编码,以及不需要预留存储,无需专业人员开发运维等等特性,相比于 hdfs 有 1:5 到 1:10 的成本优势,并且有很好的跨 az 网络带宽支撑;
多样性:利用更加丰富的实例类型为不同 workload 提供相应的性能提升。
如何避免直接迁移 local 大数据架构到云上带来的问题,充分利用公有云特性,正确的搭建/使用云原生大数据平台,提炼出了云原生数据湖架构,是我们研究的重点。
二、云原生数据湖架构三大原则
云原生数据湖架构的核心理念是低成本,并且追求不俗的性能。
综合公有云上的机遇,我们提出云原生数据湖架构三大原则:
存算分离采用对象存储降低存储成本、充分利用云上弹性资源降低计算成本、通过缓存及建模革新等一些列补偿架构来提升性能,下面分别看看三大原则的优势和要克服的困难。
1. 对象存储
存算分离是数据湖架构中最重要的原则,使用公有云对象存储服务代替 hdfs 有下面一系列好处:
云服务对象存储得益于 EC 编码,以及不需要预留存储,无需专业人员开发运维等等特性,相比于 hdfs 有 1:5 到 1:10 的成本优势。
对象存储有很好的 sla 保障 4 个 9 的可用性,对比 hdfs 要花不少力气才能做到 3 个 9;对象存储有 11 个 9 的持久化保障,对比 hdfs 即使三副本仍有较高丢数据可能性。
对象存储有 hdfs 不具有的特性:多版本、数据生命周期管理、跨 region 备份、事件驱动、访问方付费等等。
解决计算资源与存储资源不匹配,通常需求的 hdfs 存储资源是计算集群的两倍以上。
各种负载的大数据集群共享一份数据,减少数据同步复杂性和降低成本。
对象存储有诸多好处,但是直接把对象存储用于大数据,需要专业的公有云和大数据背景知识来解决,比如误用就有可能会出现以下情况:
对象存储没有 rename 语义,会导致分布式任务 commit 性能很差,通常会导致任务时长翻倍甚至更长。
对象存储大多都是最终一致性,最终一致性导致任务频繁失败,甚至读取数据错误等严重后果。
对象存储 list 性能都不太好,导致分析/建仓任务耗时增加。
2. 弹性计算
充分利用弹性计算资源,能够大大减少集群空闲时期的成本浪费,并且能够快速响应各种临时需求 /backfill 需求。
Spot 价格通常能到三折甚至一折,如何充分利用 Spot 计算资源,又不至于被回收导致任务失败是云原生数据平台的一大挑战。
大数据计算并非是无状态的,shuffle 文件/数据很大程度上阻塞了集群的弹性缩容,如何解决 shuffle 排布,达成最高效率的集群缩容至关重要。同时集群扩容如何满足波动性很大的大数据计算需求也是一个评价云原生数据平台性能的重要指标。
yarn 的整体设计更适合 local 数据平台的固定集群规模,如何利用 k8s 来达到高效的资源调度策略是云原生数据湖的另一个核心难点。
3. 性能提升:缓存加速和建模革新
云原生数据湖采用对象存储代替 hdfs,损失掉了 hdfs 的 locality 的优势,需要做一定的补偿架构。
数据倾斜多年来一直是数据工程的宿敌,对云原生数据湖架构而言却是个好消息;数据 scan 阶段,数据热度的巨大差异可以用很少的缓存来撬动达到很好的加速效果,下面是引用自 snowflake 的论文,read-only 的请求的缓存命中率高达 80%。
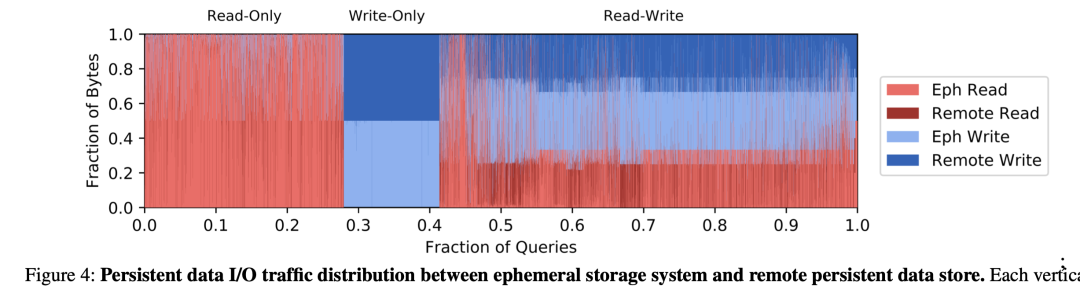
除了缓存加速,减少数据文件的扫描量在数据湖架构下更重要,如何做好数据排布需要新一代的建模技术。除了分区,分桶等传统技术,稀疏索引在数据湖扮演非常重要的作用。ap 向 tp 存储格式设计的靠拢大大加速了分析性能,可以看到 clickhouse 等高性能数仓系统都会引入稀疏索引技术,在不怎么增加存储的基础上大大提升了查询性能。
三、腾讯云数据湖产品架构
1. 腾讯云数据湖产品
要解决数据湖架构三大原则中的诸多问题,从 0 打造云原生数据湖,需要很多专业的公有云背景和数据湖技术能力,腾讯云为此推出两款数据湖产品,便于客户数据平台架构升级。
腾讯云数据湖计算(Data Lake Compute,DLC)【1】提供了敏捷高效的数据湖分析与计算服务。该服务采用无服务器架构(Serverless)设计,用户无需关注底层架构或维护计算资源,使用标准 SQL 即可完成对象存储服务(COS)及其他云端数据设施的联合分析计算。借助该服务,用户无需进行传统的数据分层建模,大幅缩减了海量数据分析的准备时间,有效提升了企业数据敏捷度。
【1】DLC:
https://cloud.tencent.com/product/dlc?!version=2&!preview=
腾讯云数据湖构建(Data Lake Formation,DLF)【2】提供了数据湖的快速构建,与湖上元数据管理服务,帮助用户快速高效的构建企业数据湖技术架构,包括统一元数据管理、多源数据入湖、任务编排、权限管理等数据湖构建工具。借助数据湖构建,用户可以极大的提高数据入湖准备的效率,方便的管理散落各处的孤岛数据。
【2】DLF:
https://cloud.tencent.com/product/dlf?!version=2&!preview=
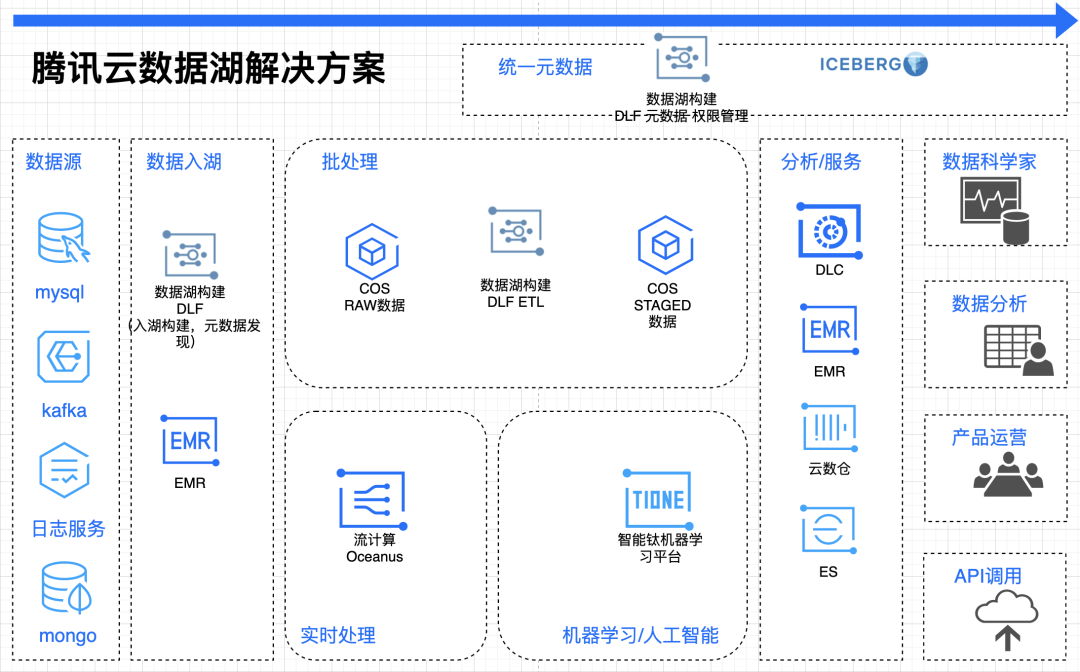
两款数据湖产品功能定位差异如下图所示:

2. 展望数据湖解决方案
未来,腾讯云数据湖解决方案建设将以对象存储 COS 为数据湖存储,以容器服务为云原生资源调度,以数据湖构建 DLF 为统一元数据纽带,构建腾讯云上的数仓建模、数据分析、机器学习的数据湖解决方案。
四、应用场景
1. 数据入湖构建
快速构建数据湖,以及在各种数据之间同步和处理数据,为高性能分析数据计算作数据准备。
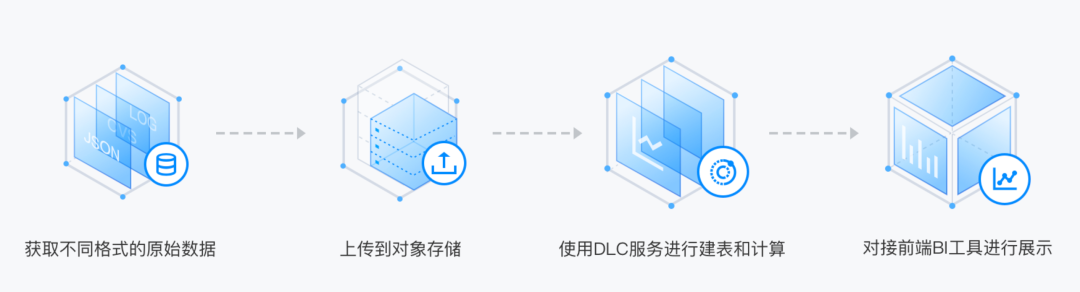
2. 数据分析
用户可直接查询和计算 COS 桶中的数据,而无需将数据聚合或加载到数据湖计算中。数据湖计算能够处理非结构化、半结构化和结构化的数据集,格式包括 CSV、JSON、Avro、Parquet、ORC 等。可以将数据湖计算集成到数据可视化应用中,生成数据报表,轻松实现数据可视化。
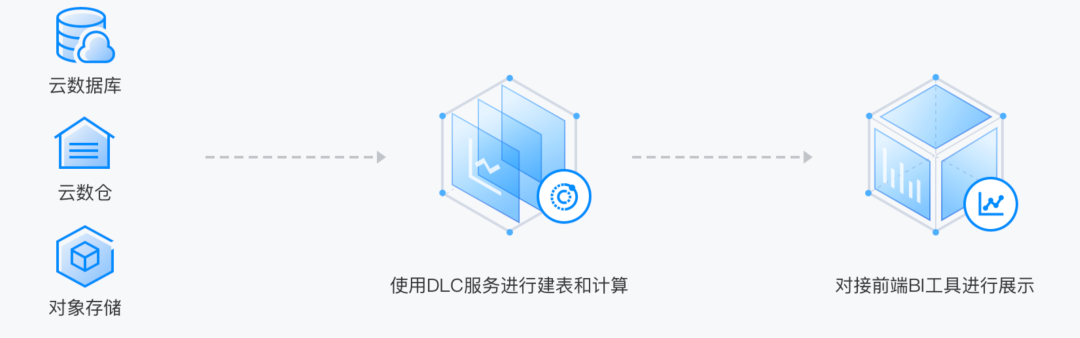
3. 联邦分析
数据湖计算支持对多源异构数据进行联合查询分析,包括对象存储、云数据库、大数据服务等。用户通过统一的数据视图,使用标准的 SQL 即可实现多源数据联合查询分析。无需依赖数据工程团队进行传统数据分层建模的 ETL 操作,也无需加载数据。
4. 统一元数据
有统一技术元数据管理诉求,希望统一管理分散在各处的数据源,并建立企业级权限管理,从而在各种分析计算引擎上使用,而无需在数据孤岛之间移动数据。
头图:Unsplash
作者:于华丽
原文:https://mp.weixin.qq.com/s/KD_XFbywC_0BcoAKDwBIAw
原文:云原生数据湖 101
来源:云加社区 - 微信公众号 [ID:QcloudCommunity]
转载:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。




