一.为何要在大规模 SNS 中挖掘兴趣圈子
随着国外的 facebook、twitter 以及国内的人人、新浪微博等 SNS 及内容分享平台的逐步流行,如何从上亿的海量用户中自动挖掘兴趣圈子成为了一个有趣也非常必要的工作。所谓“兴趣圈子”,指的是在同一分享平台下,有着共同的兴趣爱好的用户群体,比如新浪微博里哪些用户是对云计算感兴趣的?他们是否形成了一个密切交互的圈子?对这些信息的挖掘是很有趣也很有实际用处的。
如果能够从海量用户中通过自动手段挖掘出一个个的兴趣圈子,对于很多具体应用来说是非常重要的基础数据,比如可以利用用户所属兴趣圈子进行感兴趣人物推荐,或者根据所属圈子的群体特性分析用户的个人兴趣点等,所以在 SNS 平台下,如何对海量数据自动进行兴趣圈子挖掘是个非常有用的基础功能。
二.如何挖掘兴趣圈子
现在的问题是:给定海量用户,如何才能挖掘出具有相似兴趣的圈子?我们基于微博用户的互动信息,构建了一整套兴趣圈子挖掘算法,并取得了较好的挖掘效果。如果把每个用户想象成一个巨大的图中一个节点,如果用户 A 对用户 B 有互动行为(转发,评论等),我们可以在用户 A 和用户 B 之间建立一条有向边,通过这种方式可以构建出有上亿节点,几十亿边的巨大的有向图。挖掘兴趣圈子就是在这样的巨图中进行的。我们把兴趣圈子挖掘转换为一个图切割问题的具体应用。图 1 是这个思路的简化图示例。
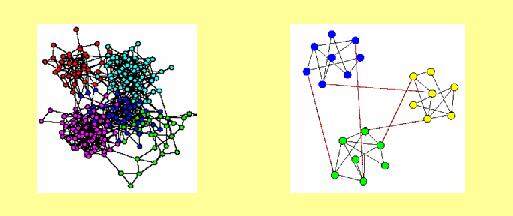
图 ****1 兴趣图例子
2.1 图切割问题
图切割问题本质上是一个聚类问题,几乎所有聚类算法的基本思想都是相近的:给定一批数据,自动对数据进行聚类,使得聚合到同一类别的数据之间比较相似,而不同类别之间的数据差异较大。图切割问题也符合这个定义,等于是将图中节点进行聚类,把密集相连的一批节点聚合到一起,而连接比较稀疏的节点尽可能划分到不同的类别中。
如果用相对形式化的语言来描述的话,图切割问题就是:给定 n 个点 (x1, x2…,xn),聚类的目标是将这 n 个点分成 k 个簇,使得同一簇中的数据点比较相似,不同簇间的数据点比较相异。如果按照节点之间的兴趣相似度构建关系图 G(V, E),问题就转化为了在图 G 上做划分,将图 G 分成 k 个子图 A1,A2,…Ak, 使得划分后子图内包含边的总权值尽可能高,而子图之间边的权重尽可能小。在图 1 所示的例子中,标为相同颜色的节点可被视为聚合到相同子图中,边的权值直观表示为边的长度,即边越长,两个节点距离越远,即其相似性越小,也就是说其边的权值小。
图切割算法有很多,比如 min-cut,min-max cut,ratio cut 等等,我们采用了谱聚类算法来挖掘用户兴趣圈子。
2.2 谱聚类算法
谱聚类算法和很多其他距离算法相比有很多优点,下文会详述此点,同样的,谱聚类也适合解决图切割问题。
谱聚类有个比较有趣的特性,即这个算法可以将图切割问题转换为求由图形成的矩阵的特征值和对应的特征向量问题,这样就把图切割问题转换为矩阵特征值求解及在其基础上的聚类问题。
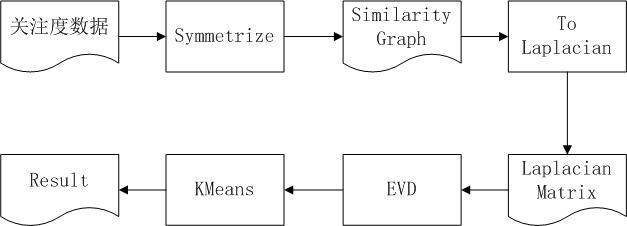
图 ****2 谱聚类算法流程
图 2 是利用谱聚类进行兴趣圈子挖掘的算法流程示意图,首先我们获得用户之间的互动数据,由于谱聚类只能处理无向图,而用户之间的互动数据是有向的,所以首先根据一定规则将有向图转换为无向图,之后就形成了所有用户的兴趣相似性图。根据谱聚类算法要求,将这个相似性图转换为拉普拉斯矩阵,然后对这个矩阵求其前 K 个特征值及其对应的特征向量,求解前 K 个特征向量 s1,s2,…,sk,组成矩阵 S[n][k](n 为用户编号),这样就将一个原本是 n*n 的矩阵转换为小很多的 n*k 矩阵,对 S 按行进行 Kmeans 聚类,每一行对应相似兴趣图中一个节点。其最终聚类结果就是谱聚类最终的输出结果。
之所以采取谱聚类来解决这个问题,源于这个算法本身具有的一些优点,比如:
- 谱聚类具有坚实的理论基础:图谱理论
- 谱聚类不含凸球形数据分布的隐性假设,而常见的很多聚类算法比如 KMeans, EM 算法都存在这一假设。比如对于图 3 所示的例子中,谱聚类的聚类效果比较好。
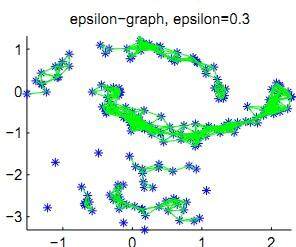
图 ****3 非凸球形数据
由于谱聚类具备独特的优点,所以近来应用非常广泛(语音识别、文本挖掘等),但是谱聚类的计算复杂度还是较高,所以面对海量数据,如何能够快速计算是个问题。
为了能够处理上亿的海量数据,我们主要采取了两项措施来对原始算法进行改造,首先是利用 MPI 平台构建分布式计算系统,对于这种计算密集型迭代式应用,通常 hadoop 平台被认为是不太合适的,所以通过构建 MPI 分布式平台来加快数据的分布以提升计算速度。
第二项主要改进措施是将谱聚类由平面型聚类(flat) 改造为层次聚类(hierarchy), 其基本思想也很简单,即通过多次谱聚类迭代,首先将一个巨大的图划分为较少数的密集子图,然后针对每个密集子图再次迭代使用谱聚类来递归地将其划分为较小的密集子图,通过几个层级的切割,也可以有效增加分布式计算效果并大大提快整体运行效率。
当然,除了以上两项主要改进措施,还包含一些相对细小的改进,在此就不赘述细节了。
2.3 应用谱聚类在 SNS 中挖掘兴趣圈子
正像上文所述,大规模 SNS 用户中挖掘兴趣圈子的问题可以进一步抽象为用户兴趣图的一个图切割问题,我们通过对谱聚类处理大规模数据进行了技术改进后,使得这项技术可以在多机并行环境下较快地处理上亿规模数据的图切割,在兴趣圈子自动挖掘方面既实现了较好的挖掘效果,又能够使得算法处理真实世界的大规模数据,使其在现实中可行而非仅仅停留在小规模数据处理的学术研究阶段。
下面给出三个使用上述技术在新浪微博平台挖掘出的兴趣圈子,因为实际的兴趣圈子很大(大部分包含几十到几百个节点),所以只列出了兴趣圈子的一部分,从这些例子可以看出其效果还是比较理想的。
用户微博 ID
微博名
身份说明
1197161814
李开复
创新工场董事长兼首席执行官
1656232852
JackF2
创新工场豌豆实验室 联合创始人
1738208940
宓金华
创新工场魔图精灵项目负责人
1652837301
徐磊 Ryan
布丁 创始人 CEO 原创新工场战略发展部总经理
1642333010
张亮
创新工场投资经理;Apple4us 发起人
1926746140
许红梅 Grace
创新工场人力资源部副总裁
1650741047
cuijin
创新工场市场总监崔瑾
1676705655
裘伯纯 Benjamin
创新工场法务负责人裘伯纯
1751792424
dikanggu
创新工场员工
1419563143
zouyu9631
创新工场员工
…
** 表 ****1 “**** 李开复 ****”**** 所属兴趣圈子 **
用户微博 ID
微博名
身份说明
1656809190
赵薇
著名演员,代表作《画皮》《还珠格格》等
1829847745
一号立井
李亚鹏
1679085395
邓讴歌
太合麦田音乐制作人
1719232542
那英
内地流行乐天后
1629810574
veggieg
王菲
1496813600
老焦爱民
《杜拉拉升职记》制片人
1768955554
张扬张杨
著名导演
1262945510
廖凡
演员廖凡
1919269943
王一涵
北京中艺博文化传播有限公司董事长兼总经理
1497323383
磨刀哎呦霍霍
编剧霍昕
…
** 表 ****2 "**** 赵薇 ****"**** 所属兴趣圈子 **
用户微博 ID
微博名
身份说明
1922397344
白硕 sse
上海证券交易所总工程师,IR 与 NLP 专家
1937618377
林鸿飞
大连理工大学电子信息与电气工程学部 副部长
1684953923
关毅的围脖
哈尔滨工业大学计算机学院教授、博士生导师关毅
1936526225
王斌 _ICTIR
中国科学院计算技术研究所副研究员,博士生导师王斌
1808067361
ITNLP
哈尔滨工业大学智能技术与自然语言处理 (ITNLP) 研究室
1970879995
孙茂松
清华大学计算机科学与技术系教授、中国中文信息学会副理事长孙茂松
1788077877
张颖峰
上海载和网络科技有限公司 研发总监
1340489195
韩先培
中国科学院软件所助理研究员
1497035431
梁斌 penny
清华大学计算机科学与技术系在读博士;《走进搜索引擎》《深入搜索引擎》作者,THUIRDB 的 Coder。
1064649941
张俊林 say
《这就是搜索引擎:核心技术详解》作者。本文作者。
…
** 表 ****3 “**** 自然语言处理与信息检索 ****”**** 兴趣圈子 **
通过大量的聚类数据分析,使用互动数据构建用户兴趣图得出的兴趣圈子大部分属于以下两种类型:一种类型是同事朋友圈子,这是因为线下关系迁移到网络的体现;另外一种比较常见的是兴趣类似的微博用户,比如 NLP 圈子,NOSQL 圈子这种根据讨论技术确定的兴趣圈子等,这是由于共同关注相似话题并经常互动形成的。
三.结束语
大规模 SNS 与内容分享平台中如何自动挖掘兴趣圈子是个很有趣也非常必要的功能,现有公开文献很少提及超大规模数据如何实现自动挖掘的算法,大多数是在 10 万以下规模数据进行的研究工作,本文简述了在新浪微博平台通过改造的谱聚类进行的大规模兴趣圈子挖掘,实践表明取得了很好的挖掘效果。当然,现有系统还面临一些问题,比如属于硬聚类,即每个用户只能隶属于一个兴趣圈子,而实际上很可能一个用户属于多个兴趣组中,所以我们面对大规模数据的软聚类,也在进行进一步的研发与改进。
关于作者
张俊林,《这就是搜索引擎:核心技术详解》作者、新浪微博研发人员。
感谢张龙对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。




