
2026 年,智能体将在企业级应用中取得哪些实质性突破?点击下载《2026 年 AI 与数据发展预测》白皮书,获悉专家一手前瞻,抢先拥抱新的工作方式!
概述
Snowpark Connect 支持您在 Snowflake 环境中使用 PySpark DataFrame API 进行数据处理。通过本综合指南,您将深入了解 Snowpark Connect 如何在 Snowflake 基础设施上高效执行 PySpark 作业,并掌握构建可用于生产环境的数据管道的方法。
学习目标
完成本快速入门指南后,您将能够:
理解 Snowpark Connect 将 PySpark 代码转换为 Snowflake 原生操作的核心机制;
连接至 Snowpark Connect 服务器并初始化 Spark 会话;
从数据表、内部阶段以及云存储中高效摄取数据;
利用 PySpark DataFrame API 执行数据转换、连接与聚合等操作;
在数据管道各环节实施数据质量验证;
采用分区与压缩策略优化输出结果的存储与访问;
应用可观测性技术及最佳实践,构建健壮的生产级数据管道。
什么是 Snowpark
Snowpark 是一套集库与代码执行环境于一体的框架,可在 Snowflake 平台内部与数据紧密相邻的位置,运行 Python 及其他编程语言。通过 Snowpark,用户可以构建数据管道、开发机器学习模型、设计应用程序以及执行各类数据处理任务。
什么是适用于 Apache Spark™ 的 Snowpark Connect
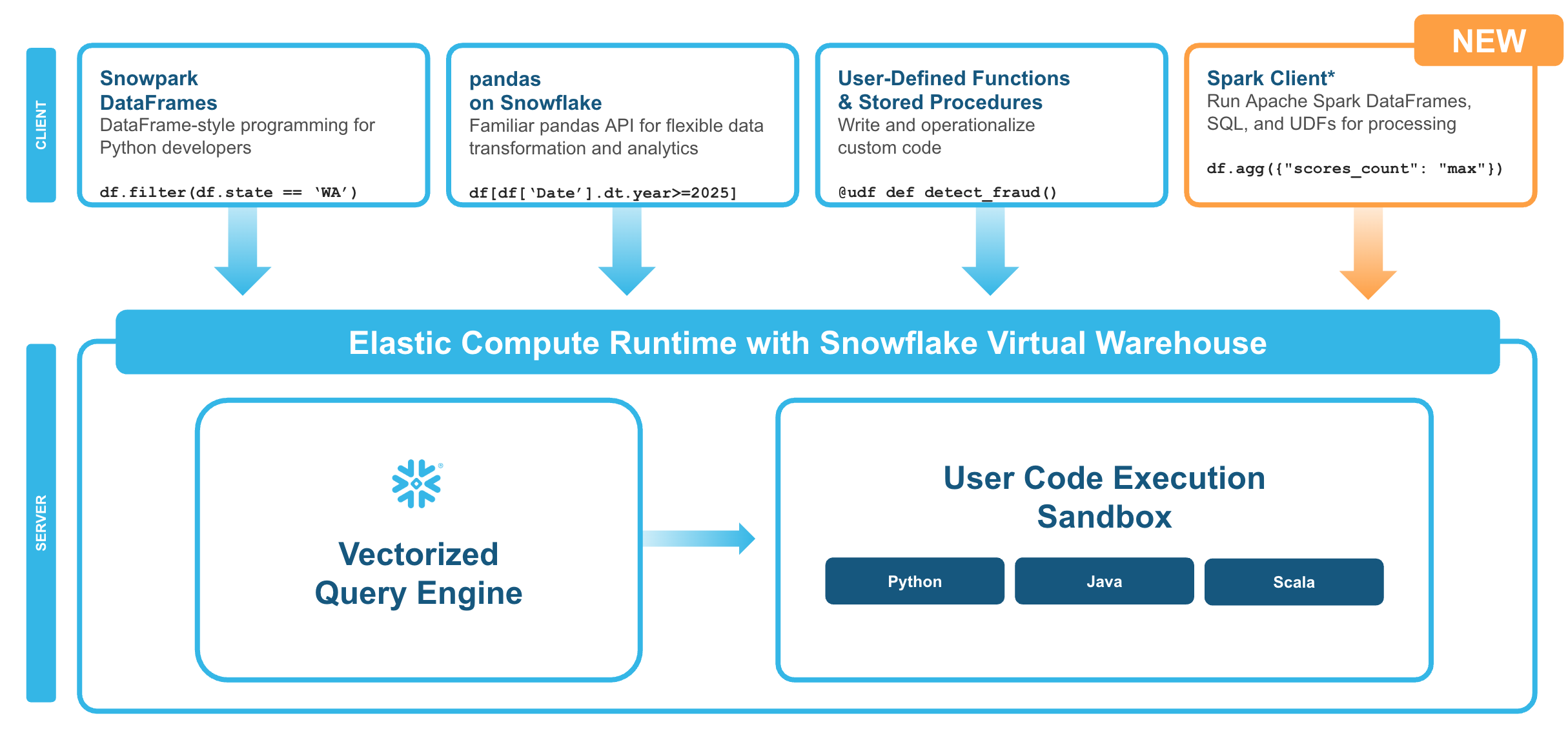
适用于 Apache Spark 的 Snowpark Connect 使用户能够将现有的 Spark 工作负载直接连接到 Snowflake,并在 Snowflake 的计算引擎上运行这些工作负载。Snowpark Connect for Spark 支持在 Snowflake 环境中使用 Spark DataFrame API,所有任务均在 Snowflake 虚拟仓库中执行。这意味着用户可以在充分利用 Snowflake 引擎各项优势的同时,继续运行其 PySpark DataFrame 代码。
在 Apache Spark™ 3.4 版本中,Apache Spark 社区引入了 Spark Connect。其解耦的客户端-服务器架构将用户代码与执行作业的 Spark 集群分离。这一新型架构使得 Snowflake 能够为 Spark 作业提供计算支持。
关键概念
执行模型:
您的 DataFrame 操作将被转换为 Snowflake SQL 语句;
计算过程在 Snowflake 数仓中完成;
结果通过 Apache Arrow 格式流式传回;
无需 Spark 集群、驱动器或执行器。
查询下推:
全面优化:DataFrame 操作、SQL 函数、聚合计算均可下推至 Snowflake 执行;
性能影响:Python UDF 在客户端运行(需获取数据→处理数据→回传结果);
优化方案:建议使用内置 SQL 函数替代 UDF。
构建内容
您将为一个虚构的全球餐车网络 Tasty Bytes 构建一套生产就绪的菜单分析管道,该方案将展示以下能力:
从外部阶段实现数据摄入;
执行数据验证与质量检查;
完成利润计算与分类管理;
实现品牌层级的数据聚合;
输出带有遥测数据及指标追踪的结果。
准备要求
拥有 Snowflake 账户。若尚未开通 Snowflake 账户,可注册免费试用账户。
具备 Python 及 PySpark 概念的基础知识。
流水线概览
该演示流水线包含以下八个步骤,从环境搭建到结果汇总:
1. 环境搭建与配置-初始化会话并定义流水线参数;
2. 监测系统初始化 -设置日志记录与指标追踪;
3. 数据接入 -从内部阶段加载数据至 Spark 数据帧;
4. 数据验证 -在处理前校验数据质量;
5. 数据转换 -应用业务逻辑并进行收益分析;
6. 数据质量检查 -在写入前验证输出结果;
7. 结果写入-将最终数据保存至 Snowflake 数据表;
8. 资源清理与结果汇总 -释放资源并报告运行指标。
步骤 1:初始化会话
首先,导入必要的程序包并初始化您的 Spark 会话。
在进行下一步前,请在 Snowflake 笔记本的“程序包”下拉菜单中选择“snowpark-connect”。
# =============================================================================# STEP 0: INITIALIZE SESSION# =============================================================================# import packages - select "snowpark_connect" from the packages dropdownfrom snowflake import snowpark_connectfrom snowflake.snowpark.context import get_active_session# initialize sessionsession = get_active_session()session.sql("USE ROLE SNOWFLAKE_LEARNING_ROLE").collect()spark = snowpark_connect.server.init_spark_session()# print session infoprint(session)步骤 2:设置与配置
使用数据类定义您的管道配置,以实现类型安全、集中化的设置。
# =============================================================================# STEP 1: SETUP & CONFIGURATION# =============================================================================import osimport uuidimport loggingfrom datetime import datetimefrom dataclasses import dataclassfrom typing import Optional, Listfrom pyspark.sql import DataFramefrom pyspark.sql.functions import ( col, lit, when, coalesce, trim, upper, sum, avg, count, min, max, countDistinct, current_timestamp, round)# --- Configuration for Tasty Bytes Menu Pipeline ---@dataclassclass PipelineConfig: """Centralized configuration for the menu analytics pipeline.""" # Pipeline metadata pipeline_name: str = "tastybytes_menu_analytics" pipeline_version: str = "1.0.0" environment: str = os.getenv("ENVIRONMENT", "dev") # Snowflake context role: str = "SNOWFLAKE_LEARNING_ROLE" warehouse: str = "SNOWFLAKE_LEARNING_WH" database: str = "SNOWFLAKE_LEARNING_DB" # Source configuration stage_url: str = "s3://sfquickstarts/tastybytes/" stage_path: str = "@blob_stage/raw_pos/menu/" source_table: str = "MENU_RAW" # Output configuration output_table: str = "MENU_BRAND_SUMMARY" output_mode: str = "overwrite" # Quality thresholds min_expected_rows: int = 50 max_expected_rows: int = 10_000 max_null_percentage: float = 0.05 min_profit_margin: float = 0.0 # No negative margins allowedconfig = PipelineConfig()# --- Initialize sessions ---# Note: session and spark should already be initializedprint(f"🚀 Pipeline: {config.pipeline_name} v{config.pipeline_version}")print(f"📍 Environment: {config.environment}")步骤 3:遥测初始化
设置日志记录和指标追踪功能,以实现可观测性。
# =============================================================================# STEP 2: TELEMETRY INITIALIZATION# =============================================================================logging.basicConfig( level=logging.INFO, format="%(asctime)s | %(levelname)s | %(message)s", datefmt="%Y-%m-%d %H:%M:%S")logger = logging.getLogger(config.pipeline_name)@dataclassclass PipelineMetrics: """Track metrics throughout pipeline execution.""" run_id: str start_time: datetime end_time: Optional[datetime] = None status: str = "running" # Stage metrics rows_ingested: int = 0 rows_after_validation: int = 0 rows_after_transform: int = 0 rows_written: int = 0 # Business metrics total_menu_items: int = 0 total_brands: int = 0 avg_profit_margin: float = 0.0 # Quality metrics validation_passed: bool = False quality_score: float = 0.0 warnings: List[str] = None def __post_init__(self): self.warnings = self.warnings or [] def add_warning(self, message: str): self.warnings.append(message) logger.warning(f"⚠️ {message}") def duration_seconds(self) -> float: end = self.end_time or datetime.now() return (end - self.start_time).total_seconds()metrics = PipelineMetrics( run_id=str(uuid.uuid4())[:8], start_time=datetime.now())logger.info(f"{'='*60}")logger.info(f"🚀 PIPELINE START | Run ID: {metrics.run_id}")logger.info(f"{'='*60}")print(f"📊 Telemetry initialized | Run ID: {metrics.run_id}")步骤 4:数据接入
将数据从 Snowflake 阶段加载到 Spark 数据帧中。
# =============================================================================# STEP 3: DATA INGESTION# =============================================================================def setup_snowflake_context(session, config: PipelineConfig) -> str: """Set up Snowflake role, warehouse, database, and schema.""" logger.info("Setting up Snowflake context...") session.sql(f"USE ROLE {config.role}").collect() session.sql(f"USE WAREHOUSE {config.warehouse}").collect() session.sql(f"USE DATABASE {config.database}").collect() # Create user-specific schema current_user = session.sql("SELECT current_user()").collect()[0][0] schema_name = f"{current_user}_INTRO_TO_SNOWPARK_CONNECT" session.sql(f"CREATE SCHEMA IF NOT EXISTS {schema_name}").collect() session.sql(f"USE SCHEMA {schema_name}").collect() logger.info(f" Context: {config.database}.{schema_name}") return schema_namedef create_stage_and_table(session, config: PipelineConfig): """Create external stage and target table.""" logger.info("Creating stage and table...") # Create stage for S3 access session.sql(f""" CREATE OR REPLACE STAGE blob_stage URL = '{config.stage_url}' FILE_FORMAT = (TYPE = CSV) """).collect() # Create raw table with proper schema session.sql(f""" CREATE OR REPLACE TABLE {config.source_table} ( MENU_ID NUMBER(19,0), MENU_TYPE_ID NUMBER(38,0), MENU_TYPE VARCHAR, TRUCK_BRAND_NAME VARCHAR, MENU_ITEM_ID NUMBER(38,0), MENU_ITEM_NAME VARCHAR, ITEM_CATEGORY VARCHAR, ITEM_SUBCATEGORY VARCHAR, COST_OF_GOODS_USD NUMBER(38,4), SALE_PRICE_USD NUMBER(38,4), MENU_ITEM_HEALTH_METRICS_OBJ VARIANT ) """).collect() logger.info(" ✓ Stage and table created")def load_data_from_stage(session, config: PipelineConfig) -> int: """Load CSV data using COPY INTO.""" logger.info(f"Loading data from: {config.stage_path}") result = session.sql(f""" COPY INTO {config.source_table} FROM {config.stage_path} """).collect() # Get loaded row count count_result = session.sql(f"SELECT COUNT(*) FROM {config.source_table}").collect() row_count = count_result[0][0] logger.info(f" ✓ Loaded {row_count:,} rows") return row_count# Execute ingestionlogger.info("STEP 3: Data Ingestion")schema_name = setup_snowflake_context(session, config)create_stage_and_table(session, config)metrics.rows_ingested = load_data_from_stage(session, config)# Read into Spark DataFrame for processingdf_raw = spark.read.table(config.source_table)logger.info(f" ✓ DataFrame created with {len(df_raw.columns)} columns")print(f"✅ Data ingestion complete: {metrics.rows_ingested:,} rows loaded into {config.source_table}")数据接入方法参考
除上述管道示例外,以下是将数据加载到 Spark 数据帧的其他方式。
从 Snowflake 表读取
直接查询现有表,或使用 SQL 进行筛选读取。
df = spark.read.table("MY_DATABASE.MY_SCHEMA.MY_TABLE")df = spark.sql("SELECT * FROM MY_TABLE WHERE status = 'active' LIMIT 1000")从 Snowflake 阶段读取
直接从内部或外部阶段以多种格式加载文件。
# parquetdf = spark.read.parquet("@MY_STAGE/path/to/data.parquet")# CSVdf = spark.read.format("csv") \ .option("header", True) \ .option("inferSchema", False) \ .option("delimiter", ",") \ .option("quote", '"') \ .option("escape", "\\") \ .option("nullValue", "") \ .option("dateFormat", "yyyy-MM-dd") \ .load("@MY_STAGE/path/to/data.csv")# JSONdf = spark.read.format("json") \ .option("multiLine", True) \ .option("allowComments", True) \ .option("dateFormat", "yyyy-MM-dd") \ .load("@MY_STAGE/path/to/data.json")直接云存储访问
在配置了相应凭证的情况下,可直接从 S3、GCS 或 Azure Blob Storage 读取数据。
# S3df = spark.read.parquet("s3://my-bucket/path/to/data/")# GCPdf = spark.read.parquet("gs://my-bucket/path/to/data/")# Azuredf = spark.read.parquet("wasbs://container@account.blob.core.windows.net/path/to/data/")读取多个文件
支持使用通配符和递归选项,一次性从多个文件中加载数据。
# Wildcard pattern - Match all parquet files in a directorydf = spark.read.parquet("@MY_STAGE/data/*.parquet")# Match files with a naming patterndf = spark.read.csv("@MY_STAGE/logs/2024-*/events_*.csv")# Recursive directory searchdf = spark.read.option("recursiveFileLookup", True).parquet("@MY_STAGE/nested_data/")处理大型 CSV 文件
通过明确定义 Schema 以及为重复访问转换为 Parquet 格式,优化 CSV 文件的读取性能。
❌低效模式-需要扫描整个文件来推断列类型:
df = spark.read.format("csv") \ .option("header", True) \ .option("inferSchema", True) \ .load("@MY_STAGE/large_file.csv")
✅高效模式-明确定义 Schema:
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, DoubleType, TimestampType, BooleanTypeschema = StructType([ StructField("id", IntegerType(), False), StructField("name", StringType(), True), StructField("amount", DoubleType(), True), StructField("created_at", TimestampType(), True), StructField("is_active", BooleanType(), True)])df = spark.read.format("csv") \ .option("header", True) \ .schema(schema) \ .load("@MY_STAGE/large_file.csv")
✅压缩文件-读取时自动解压:
df = spark.read.format("csv") \ .option("header", True) \ .schema(schema) \ .load("@MY_STAGE/data.csv.gz")
✅最佳实践-将 CSV 转换为 Parquet 格式:
# Read CSV oncedf_csv = spark.read.format("csv") \ .option("header", True) \ .schema(schema) \ .load("@MY_STAGE/raw.csv")# Write as Parquetdf_csv.write.mode("overwrite").parquet("@MY_STAGE/optimized/data.parquet")# Read from Parquet for all future queriesdf = spark.read.parquet("@MY_STAGE/optimized/data.parquet")步骤 5:数据验证
在处理前对菜单数据进行验证。
# =============================================================================# STEP 4: DATA VALIDATION# =============================================================================class ValidationError(Exception): """Raised when critical validation fails.""" passdef validate_menu_data( df: DataFrame, config: PipelineConfig, metrics: PipelineMetrics) -> DataFrame: """ Validate menu data before processing. Checks: - Row count within expected range - Required columns present - No nulls in key columns - No duplicate menu items - Prices are positive """ logger.info("STEP 4: Data Validation") errors = [] row_count = metrics.rows_ingested # Check 1: Row count bounds if row_count < config.min_expected_rows: errors.append(f"Row count {row_count:,} below minimum {config.min_expected_rows:,}") if row_count > config.max_expected_rows: errors.append(f"Row count {row_count:,} exceeds maximum {config.max_expected_rows:,}") else: logger.info(f" ✓ Row count ({row_count:,}) within bounds") # Check 2: Required columns required = ["MENU_ITEM_ID", "MENU_ITEM_NAME", "TRUCK_BRAND_NAME", "COST_OF_GOODS_USD", "SALE_PRICE_USD"] missing = [c for c in required if c not in df.columns] if missing: errors.append(f"Missing required columns: {missing}") else: logger.info(f" ✓ All {len(required)} required columns present") # Check 3: Null check on key columns key_columns = ["MENU_ITEM_ID", "MENU_ITEM_NAME", "COST_OF_GOODS_USD", "SALE_PRICE_USD"] for col_name in key_columns: null_count = df.filter(col(col_name).isNull()).count() null_pct = null_count / row_count if row_count > 0 else 0 if null_pct > config.max_null_percentage: errors.append(f"Column '{col_name}' has {null_pct:.1%} nulls") elif null_pct > 0: metrics.add_warning(f"Column '{col_name}' has {null_pct:.1%} nulls") if not any("nulls" in str(e) for e in errors): logger.info(" ✓ Null check passed") # Check 4: No duplicate menu items unique_items = df.select("MENU_ITEM_ID").distinct().count() if unique_items < row_count: duplicates = row_count - unique_items metrics.add_warning(f"Found {duplicates:,} duplicate menu items") else: logger.info(" ✓ No duplicate menu items") # Check 5: Positive prices negative_prices = df.filter( (col("COST_OF_GOODS_USD") < 0) | (col("SALE_PRICE_USD") < 0) ).count() if negative_prices > 0: errors.append(f"Found {negative_prices:,} items with negative prices") else: logger.info(" ✓ All prices are positive") # Handle validation results if errors: for error in errors: logger.error(f" ✗ VALIDATION FAILED: {error}") raise ValidationError(f"Validation failed with {len(errors)} error(s)") metrics.validation_passed = True metrics.rows_after_validation = row_count logger.info(" ✅ Validation PASSED") return df# Execute validationdf_validated = validate_menu_data(df_raw, config, metrics)print(f"✅ Validation complete: {metrics.rows_after_validation:,} rows passed all checks")功能特性支持矩阵
了解 PySpark 支持哪些功能特性,有助于编写高效代码。
✅完全支持的 DataFrame 操作
select,filter,where;
groupBy,agg(所有聚合函数);
join(内连接、左连接、右连接、外连接、广播连接);
orderBy,sort;
distinct,dropDuplicates;
Window functions(如 row_number, rank, lag, lead 等);
Built-in functions(覆盖率超过 95%);
cache,persist(在 Snowflake 中创建临时表)。
⚠️有限支持
repartition(仅逻辑操作);
coalesce(与 repartition 类似);
Python UDF(可用但性能较慢,如非必要请避免使用);
Pandas UDF(可用但性能较慢,如非必要请避免使用);
MLlib(部分支持:转换器可用,估计器功能受限)。
❌不支持
RDD API 完全不支持;
.rdd、.foreach()、.foreachPartition() 等方法;
Structured Streaming 流处理;
GraphX 图计算;
自定义数据源;
.checkpoint() 方法。
数据类型支持
✅支持:
字符串、整型、长整型、浮点型、双精度浮点型、十进制数;
布尔型、日期型、时间戳;
数组、映射、结构体;
二进制类型。
❌不支持:
日期间隔类型(DayTimeIntervalType);
年月间隔类型(YearMonthIntervalType);
用户自定义类型。
支持的文件格式
Parquet、CSV、JSON、Avro、ORC;
不支持 Delta Lake、Hudi。
步骤 6:数据转换
对菜单数据应用业务转换。
# =============================================================================# STEP 5: TRANSFORMATIONS# =============================================================================def transform_menu_data( df: DataFrame, metrics: PipelineMetrics) -> DataFrame: """ Apply business transformations to menu data. Stages: 5A. Data Cleaning 5B. Profit Calculations 5C. Categorization 5D. Aggregation by Brand """ logger.info("STEP 5: Transformations") # ------------------------------------------------------------------------- # STAGE 5A: Data Cleaning # ------------------------------------------------------------------------- logger.info(" 5A: Data Cleaning") df_clean = df \ .withColumn("TRUCK_BRAND_NAME", trim(upper(col("TRUCK_BRAND_NAME")))) \ .withColumn("ITEM_CATEGORY", trim(upper(col("ITEM_CATEGORY")))) \ .withColumn("MENU_TYPE", trim(upper(col("MENU_TYPE")))) \ .filter(col("COST_OF_GOODS_USD").isNotNull()) \ .filter(col("SALE_PRICE_USD").isNotNull()) # ------------------------------------------------------------------------- # STAGE 5B: Profit Calculations # ------------------------------------------------------------------------- logger.info(" 5B: Profit Calculations") df_with_profit = df_clean \ .withColumn( "PROFIT_USD", round(col("SALE_PRICE_USD") - col("COST_OF_GOODS_USD"), 2) ) \ .withColumn( "PROFIT_MARGIN_PCT", round( (col("SALE_PRICE_USD") - col("COST_OF_GOODS_USD")) / col("SALE_PRICE_USD") * 100, 2 ) ) # ------------------------------------------------------------------------- # STAGE 5C: Categorization # ------------------------------------------------------------------------- logger.info(" 5C: Profit Categorization") df_categorized = df_with_profit \ .withColumn( "PROFIT_TIER", when(col("PROFIT_MARGIN_PCT") >= 70, "Premium") .when(col("PROFIT_MARGIN_PCT") >= 50, "High") .when(col("PROFIT_MARGIN_PCT") >= 30, "Medium") .otherwise("Low") ) \ .withColumn( "PRICE_TIER", when(col("SALE_PRICE_USD") >= 10, "Premium") .when(col("SALE_PRICE_USD") >= 5, "Mid-Range") .otherwise("Value") ) # ------------------------------------------------------------------------- # STAGE 5D: Aggregation by Brand # ------------------------------------------------------------------------- logger.info(" 5D: Aggregation by Brand") df_brand_summary = df_categorized.groupBy( "TRUCK_BRAND_NAME", "MENU_TYPE" ).agg( count("*").alias("ITEM_COUNT"), round(avg("COST_OF_GOODS_USD"), 2).alias("AVG_COST_USD"), round(avg("SALE_PRICE_USD"), 2).alias("AVG_PRICE_USD"), round(avg("PROFIT_USD"), 2).alias("AVG_PROFIT_USD"), round(avg("PROFIT_MARGIN_PCT"), 2).alias("AVG_MARGIN_PCT"), round(min("PROFIT_USD"), 2).alias("MIN_PROFIT_USD"), round(max("PROFIT_USD"), 2).alias("MAX_PROFIT_USD"), round(sum("PROFIT_USD"), 2).alias("TOTAL_POTENTIAL_PROFIT_USD") ).orderBy(col("AVG_MARGIN_PCT").desc()) # Add metadata df_final = df_brand_summary \ .withColumn("PIPELINE_RUN_ID", lit(metrics.run_id)) \ .withColumn("PROCESSED_AT", current_timestamp()) # Update metrics metrics.rows_after_transform = df_final.count() metrics.total_brands = df_final.select("TRUCK_BRAND_NAME").distinct().count() metrics.total_menu_items = df_categorized.count() # Calculate overall average margin avg_margin = df_final.agg(avg("AVG_MARGIN_PCT")).collect()[0][0] metrics.avg_profit_margin = float(avg_margin) if avg_margin else 0.0 logger.info(f" ✓ Aggregated to {metrics.rows_after_transform:,} brand/menu-type combinations") logger.info(f" ✓ {metrics.total_brands} unique brands analyzed") logger.info(f" ✓ Average profit margin: {metrics.avg_profit_margin:.1f}%") return df_final# Execute transformationsdf_transformed = transform_menu_data(df_validated, metrics)df_transformed.cache()# Preview resultslogger.info("\n📊 Brand Summary Preview:")df_transformed.select( "TRUCK_BRAND_NAME", "MENU_TYPE", "ITEM_COUNT", "AVG_PRICE_USD", "AVG_PROFIT_USD", "AVG_MARGIN_PCT").show(10, truncate=False)转换 API 参考
所有转换操作都会下推到 Snowflake SQL 中执行——在您明确收集结果之前,数据不会离开数据仓库。
所需导入
导入转换所需的函数。
from pyspark.sql.functions import ( col, lit, when, coalesce, sum, avg, count, min, max, countDistinct, collect_list, year, month, dayofmonth, hour, minute, second, dayofweek, dayofyear, weekofyear, quarter, to_date, to_timestamp, date_add, date_sub, months_between, datediff, date_trunc, upper, lower, initcap, trim, ltrim, rtrim, lpad, rpad, concat, substring, regexp_replace, regexp_extract, row_number, rank, dense_rank, percent_rank, lag, lead, first, last, broadcast)from pyspark.sql.window import Window1、选择与过滤
选择数据列并过滤行记录,以缩小数据集范围。
选择列:
df.select("id", "name", "amount")df.select(col("id"), col("name").alias("customer_name")) # with rename
过滤行:
df.filter(col("status") == "active")df.where(col("amount") > 100)df.filter((col("status") == "active") & (col("amount") > 100)) # ANDdf.filter((col("status") == "active") | (col("amount") > 1000)) # OR
去重:
df.distinct() # all columnsdf.dropDuplicates(["customer_id", "order_date"]) # specific columns2、添加与修改列
创建新列、重命名现有列以及处理数据类型转换。
添加计算列:
df.withColumn("total", col("price") * col("quantity"))df.withColumn("discounted_price", col("price") * 0.9)df.withColumn("status_flag", when(col("status") == "active", 1).otherwise(0))重命名列:
df.withColumnRenamed("old_name", "new_name")df.toDF("col1", "col2", "col3") # rename all at once
转换数据类型:
df.withColumn("amount", col("amount").cast("double"))df.withColumn("event_date", col("timestamp_col").cast("date"))
处理空值:
df.fillna(0, subset=["amount"]) # single columndf.fillna({"amount": 0, "name": "Unknown"}) # multiple columnsdf.withColumn("value", coalesce(col("value"), lit(0))) # using coalesce3、聚合
对数据进行分组,并计算计数、求和及平均值等汇总统计。
分组与聚合:
df.groupBy("category").agg( count("*").alias("row_count"), countDistinct("customer_id").alias("unique_customers"), sum("amount").alias("total_amount"), avg("amount").alias("avg_amount"), min("amount").alias("min_amount"), max("amount").alias("max_amount"), collect_list("product_name").alias("products"))多列分组:
df.groupBy("category", "region").agg( sum("amount").alias("total_sales"), avg("amount").alias("average_sale"))4、连接操作
使用多种连接类型对数据框进行组合,并通过广播提示进行性能优化。
显式连接条件:
df1.join(df2, df1["id"] == df2["id"], "inner")
广播小表(性能优化):
df_large.join(broadcast(df_small), "key_column", "left")
处理列名冲突:
df_joined = df1.alias("a").join(df2.alias("b"), col("a.id") == col("b.id"))df_result = df_joined.select(col("a.id"), col("a.name"), col("b.value"))5、窗口函数
在不折叠数据的情况下,对与当前行相关的多行数据进行计算。
定义窗口规范:
window_spec = Window.partitionBy("customer_id").orderBy("order_date")# With frame boundswindow_frame = Window.partitionBy("customer_id") \ .orderBy("order_date") \ .rowsBetween(-2, 0)
排名函数:
df.withColumn("row_num", row_number().over(window_spec))df.withColumn("rank", rank().over(window_spec)) # gaps for tiesdf.withColumn("dense_rank", dense_rank().over(window_spec)) # no gapsdf.withColumn("pct_rank", percent_rank().over(window_spec))
分析函数:
df.withColumn("prev_amount", lag("amount", 1).over(window_spec))df.withColumn("next_amount", lead("amount", 1).over(window_spec))df.withColumn("first_order", first("amount").over(window_spec))df.withColumn("last_order", last("amount").over(window_spec))滚动计算:
window_running = Window.partitionBy("customer_id") \ .orderBy("order_date") \ .rowsBetween(Window.unboundedPreceding, 0)df.withColumn("running_total", sum("amount").over(window_running))df.withColumn("running_avg", avg("amount").over(window_running))6、日期和时间操作
提取日期部分、解析字符串并执行日期运算。
提取组件:
将字符串解析为日期:
df.withColumn("date_col", to_date("date_string", "yyyy-MM-dd"))df.withColumn("ts_col", to_timestamp("ts_string", "yyyy-MM-dd HH:mm:ss"))日期运算:
df.withColumn("next_week", date_add("date_col", 7))df.withColumn("last_week", date_sub("date_col", 7))df.withColumn("days_diff", datediff("end_date", "start_date"))df.withColumn("months_diff", months_between("end_date", "start_date"))df.withColumn("month_start", date_trunc("month", "date_col"))7、字符串操作
转换大小写、匹配模式以及处理文本数据。
大小写转换:
df.withColumn("upper_name", upper("name"))df.withColumn("lower_name", lower("name"))df.withColumn("title_name", initcap("name"))
模式匹配:
df.withColumn("has_email", col("text").contains("@"))df.withColumn("cleaned", regexp_replace("text", "[^a-zA-Z0-9]", ""))df.withColumn("domain", regexp_extract("email", "@(.+)$", 1))修剪与填充:
df.withColumn("trimmed", trim("text"))df.withColumn("padded_id", lpad("id", 10, "0")) # "42" → "0000000042"df.withColumn("padded_right", rpad("code", 5, "X")) # "AB" → "ABXXX"8、排序与限制
对结果进行排序并限制输出行数。
结果排序:
df.orderBy("name") # ascendingdf.orderBy(col("amount").desc()) # descendingdf.orderBy(col("category").asc(), col("amount").desc()) # multipledf.orderBy(col("value").asc_nulls_first()) # nulls firstdf.orderBy(col("value").desc_nulls_last()) # nulls last
行数限制:
df.limit(10) # first 10 rowsdf.orderBy(col("amount").desc()).limit(10) # top 10 by amount步骤 7:数据质量检查
在写入数据前,验证输出数据的质量。
# =============================================================================# STEP 6: DATA QUALITY CHECKS# =============================================================================def quality_checks( df: DataFrame, config: PipelineConfig, metrics: PipelineMetrics) -> float: """Validate output data quality before writing.""" logger.info("STEP 6: Data Quality Checks") checks_passed = 0 total_checks = 4 row_count = metrics.rows_after_transform # Check 1: Non-zero output if row_count > 0: checks_passed += 1 logger.info(f" ✓ Output has {row_count:,} rows") else: logger.error(" ✗ Output is empty!") # Check 2: No duplicate keys key_cols = ["TRUCK_BRAND_NAME", "MENU_TYPE"] distinct_keys = df.select(key_cols).distinct().count() if distinct_keys == row_count: checks_passed += 1 logger.info(" ✓ No duplicate brand/menu-type combinations") else: logger.error(f" ✗ Found {row_count - distinct_keys:,} duplicate keys") # Check 3: All margins are reasonable (not negative) negative_margins = df.filter(col("AVG_MARGIN_PCT") < config.min_profit_margin).count() if negative_margins == 0: checks_passed += 1 logger.info(" ✓ All profit margins are positive") else: metrics.add_warning(f"Found {negative_margins:,} brands with negative margins") # Check 4: Data completeness null_brands = df.filter(col("TRUCK_BRAND_NAME").isNull()).count() if null_brands == 0: checks_passed += 1 logger.info(" ✓ All records have brand names") else: logger.error(f" ✗ Found {null_brands:,} records without brand names") quality_score = checks_passed / total_checks logger.info(f"\n 📈 Quality Score: {quality_score:.0%} ({checks_passed}/{total_checks} checks)") return quality_score# Execute quality checksmetrics.quality_score = quality_checks(df_transformed, config, metrics)print(f"✅ Quality checks complete: {metrics.quality_score:.0%} score")步骤 8:写入输出
将转换后的数据写入 Snowflake 表。
# =============================================================================# STEP 7: WRITE OUTPUT# =============================================================================def write_output( df: DataFrame, config: PipelineConfig, metrics: PipelineMetrics) -> int: """Write transformed data to Snowflake table.""" logger.info("STEP 7: Write Output") logger.info(f" Destination: {config.output_table}") logger.info(f" Mode: {config.output_mode}") # Write to Snowflake df.write.mode(config.output_mode).saveAsTable(config.output_table) # Verify written_count = spark.read.table(config.output_table).count() logger.info(f" ✓ Rows written: {written_count:,}") return written_count# Execute writemetrics.rows_written = write_output(df_transformed, config, metrics)print(f"✅ Write complete: {metrics.rows_written:,} rows written to {config.output_table}")写入数据参考
将转换后的数据写回 Snowflake 表、内部阶段或云存储。
写入 Snowflake 表
使用不同的写入模式将数据帧保存为托管表。
# Overwrite replaces all existing datadf.write.mode("overwrite").saveAsTable("MY_TABLE")# Append adds new rows to existing data (use for incremental loads)df.write.mode("append").saveAsTable("MY_TABLE")# Ignore skips write if destination exists (use for idempotent operations)df.write.mode("ignore").saveAsTable("MY_TABLE")# Error fails if destination existsdf.write.mode("error").saveAsTable("MY_TABLE")写入 Snowflake 内部阶段
将数据以 Parquet、CSV 或 JSON 格式导出到内部阶段。
# Parquet (recommended)df.write.mode("overwrite").parquet("@MY_STAGE/output/data.parquet")# CSVdf.write.mode("overwrite") \ .option("header", True) \ .option("compression", "gzip") \ .option("delimiter", ",") \ .option("quote", '"') \ .csv("@MY_STAGE/output/data.csv")# JSONdf.write.mode("overwrite") \ .option("compression", "gzip") \ .json("@MY_STAGE/output/data.json")写入云存储
直接写入 S3、GCS 或 Azure Blob 存储。
# S3df.write.mode("overwrite").parquet("s3://my-bucket/output/data/")# GCPdf.write.mode("overwrite").parquet("gs://my-bucket/output/data/")# Azuredf.write.mode("overwrite").parquet("wasbs://container@account.blob.core.windows.net/output/data/")性能与压缩
通过分区和压缩策略优化存储及查询性能。
基于分区的性能优化
按关键列组织数据,以实现更快速的过滤查询。
# Multi-column partitioningdf.write.mode("overwrite") \ .partitionBy("year", "month") \ .parquet("@MY_STAGE/partitioned_data/")# Single column partitioningdf.write.mode("overwrite") \ .partitionBy("event_date") \ .parquet("@MY_STAGE/daily_data/")
优势:
针对分区列的过滤查询速度更快;
支持对不同分区进行并行读取;
数据管理更便捷(例如,删除旧分区)。
注意事项:
分区过多会导致产生大量小文件;
应选择基数适中的列作为分区列;
基于日期的分区是常见的做法。
压缩选项
根据您的访问模式和存储需求选择合适的压缩编解码器。
# Snappy (default)df.write.option("compression", "snappy").parquet("@MY_STAGE/data/")# Gzipdf.write.option("compression", "gzip").parquet("@MY_STAGE/data/")# LZ4df.write.option("compression", "lz4").parquet("@MY_STAGE/data/")# Zstddf.write.option("compression", "zstd").parquet("@MY_STAGE/data/")# Nonedf.write.option("compression", "none").parquet("@MY_STAGE/data/")步骤 9:清理与总结
释放资源并记录最终的总结日志。
# =============================================================================# STEP 8: CLEANUP & SUMMARY# =============================================================================def cleanup_and_summarize(df_cached: DataFrame, metrics: PipelineMetrics): """Release resources and log final summary.""" logger.info("STEP 8: Cleanup & Summary") # Release cache try: df_cached.unpersist() logger.info(" ✓ Cache released") except Exception as e: logger.warning(f" Could not unpersist: {e}") # Finalize metrics metrics.end_time = datetime.now() metrics.status = "SUCCESS" if metrics.quality_score >= 0.75 else "COMPLETED_WITH_WARNINGS" # Print summary print(f"\n{'='*60}") print("🎉 PIPELINE SUMMARY") print(f"{'='*60}") print(f" Run ID: {metrics.run_id}") print(f" Status: {metrics.status}") print(f" Duration: {metrics.duration_seconds():.1f} seconds") print(f" {'─'*56}") print(f" Menu Items: {metrics.total_menu_items:,}") print(f" Brands Analyzed: {metrics.total_brands}") print(f" Avg Profit Margin: {metrics.avg_profit_margin:.1f}%") print(f" {'─'*56}") print(f" Rows In: {metrics.rows_ingested:,}") print(f" Rows Out: {metrics.rows_written:,}") print(f" Quality Score: {metrics.quality_score:.0%}") if metrics.warnings: print(f" {'─'*56}") print(f" ⚠️ Warnings ({len(metrics.warnings)}):") for w in metrics.warnings: print(f" • {w}") print(f"{'='*60}\n")# Execute cleanupcleanup_and_summarize(df_transformed, metrics)最佳实践
遵循以下最佳实践,以充分发挥 Snowpark Connect 的性能。
优先使用 SQL 函数而非 UDF:Python UDF(用户自定义函数)需要将数据传输至客户端进行处理,然后再传回——其速度比原生操作慢 10 到 100 倍;
小表连接使用广播:在将大表与小维度表进行连接时,使用 broadcast()函数来优化连接操作;
缓存频繁访问的 DataFrame:缓存会在 Snowflake 中创建临时表,以便更快地重复访问。操作完成后,请记得使用 unpersist() 进行清理;
最小化数据移动:在 Snowflake 内部完成数据处理,仅传输最终结果。切勿对大型数据集使用 collect() 操作;
注意分区优化:在分区列上进行过滤,以实现分区剪枝,减少数据扫描量。
性能检查清单
使用 COPY INTO 进行批量数据加载(比使用 spark.read 读取 CSV 文件更快);
对需要多次操作的 DataFrame 进行缓存;
避免使用 UDF,优先采用内置 SQL 函数;
在写入输出前设置数据质量检查;
使用数据类实现类型安全的配置;
通过自定义异常进行完善的错误处理;
在每个阶段实施结构化日志记录;
使用唯一的运行 ID 以便追溯;
记录行数和业务指标等关键度量。
总结与资源
恭喜您!您已成功完成这份全面的 Snowpark Connect for Apache Spark 指南。
本课要点
PySpark 代码转换:了解 Snowpark Connect 如何将 PySpark 代码转换为 Snowflake SQL;
会话初始化:掌握如何初始化连接到 Snowflake 的 Spark 会话;
多种数据摄入模式:熟悉多种数据摄入方式(表、阶段、云存储);
数据验证策略:了解数据验证与质量检查的策略。;
数据转换技术:掌握包括连接、聚合和窗口函数在内的数据转换技术;
数据写入优化:学习如何使用分区和压缩选项进行数据写入;
生产环境可观测性:了解生产管道的遥测与指标跟踪;
性能优化实践:掌握实现最佳性能的实践方法。
相关资源
官方文档:
Snowpark Submit CLI:
使用 Snowpark Submit CLI 将 Spark 工作负载作为批处理作业运行。
安装命令:
pip install snowpark-submit
提交作业命令:
snowpark-submit \ --snowflake-workload-name MY_JOB \ --snowflake-connection-name MY_CONNECTION \ --compute-pool MY_COMPUTE_POOL \ app.py
更多资源:
Getting Started with Snowpark Connect
原文地址:https://www.snowflake.com/en/developers/guides/intro-to-snowpark-connect-for-apache-spark/
点击链接立即报名注册:Ascent - Snowflake Platform Training - China,更多 Snowflake 精彩活动请关注专区。




