
FACTS基准测试套件发布,这是一个旨在系统性评估大型语言模型事实准确性的全新行业基准。该套件由 FACTS 团队与 Kaggle 联合开发,扩展了早期事实基础研究相关的工作,并引入了一个更广泛的多维度框架,用于衡量语言模型在不同使用场景下产生事实正确响应的可靠性。
FACTS 基准测试套件基于原先的 FACTS Grounding Benchmark,并增加了三个新基准:参数化(Parametric)、搜索(Search)和多模态(Multimodal)。结合更新后的 Grounding Benchmark v2,该套件可以从反映现实世界常见模型使用场景的四个维度评估事实性。该基准测试总共包括 3513 个精选示例,分为公共和私有评估集两部分。Kaggle 负责管理保留的私有数据集,评估参赛模型,并通过公开排行榜发布结果。总体性能以 FACTS 评分的形式呈现。该分值是通过所有基准测试以及两部分数据集的平均准确率计算得出的。
参数化基准测试侧重于模型仅凭内部知识(无需外部工具)回答基于事实的问题的能力。问题形式类似于常见的知识问答题,通常可通过维基百科等来源找到答案。搜索基准测试评估模型能否通过标准的 Web 搜索工具准确地检索并整合信息,通常需要多步检索才能完成单个查询。多模态基准测试在回答图像相关的问题时检验事实准确性,需要结合背景知识进行正确的视觉解读。更新后的 Grounding Benchmark v2 评估响应是否基于提供的上下文信息进行了合理推演。
初步结果既凸显了进展,也揭示了接下来要面对的挑战。在评估的模型中,Gemini 3 Pro 以 68.8%的总体 FACTS 评分位居首位,其参数化事实性与搜索事实性较前代模型均有显著提升。然而,评估的所有模型总体准确率均未突破 70%,多模态事实性成为各模型普遍面临的难题。
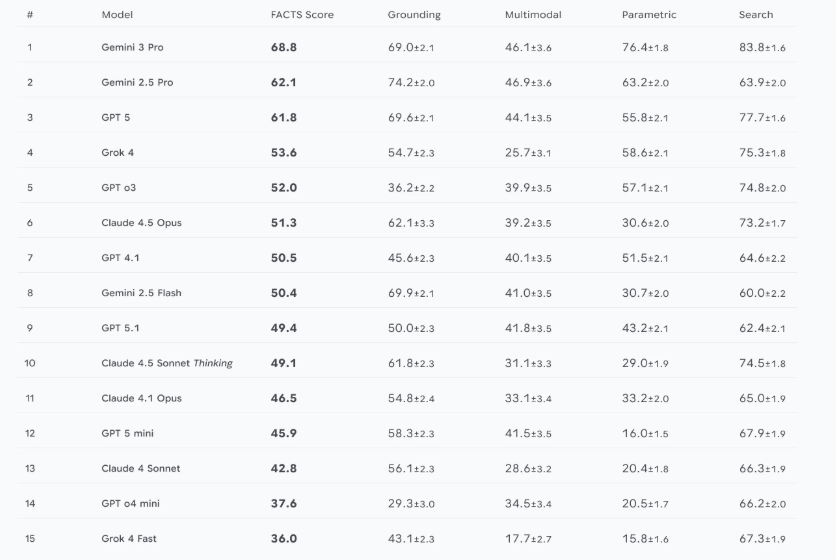
图片来源:谷歌 DeepMind 博客
基准测试的结构引起了从业者的关注。资深 iOS 工程师 Alexey Marinin 在评论此次发布时指出:
这种四维视角(知识、Web、基础、多模态)感觉更接近人们日常实际使用这些模型的方式。
FACTS 团队表示,该基准旨在支持正在进行的研究,而不是作为模型质量的最终衡量标准。通过公开数据集并规范评估标准,该项目旨在为衡量语言模型的事实可靠性提供一个共同的基准,以适应其持续演进的发展需求。
原文链接:




