
Pinterest 工程团队通过提升可观测性、优化配置以及采用自动内存重试机制,显著提高了 Apache Spark 工作负载的可靠性,将内存不足(OOM)故障减少了 96%。这项工作解决了长期存在的作业故障问题。这些问题曾导致数据管道中断、值班人员工作负担增加,并威胁到了为推荐系统和大规模数据处理提供支持的内存密集型工作负载的及时分析能力。
多年来,OOM 错误一直是个挥之不去的难题。任务经常在执行后期失败,通常是在经过数小时的计算之后,为了维持管道的运行,工程师们不得不手动调整内存设置。这既打乱了下游流程,又增加了值班人员的负担,还使得团队难以专注于交付新功能。要解决这个问题,减少故障的发生,同时将人工干预降至最低,既需要技术层面的解决方案,也需要工作流层面的解决方案。
关键的第一步是提高作业内存消耗情况的可见性。工程师们针对执行器的内存使用情况、shuffle 操作以及任务执行时间构建了详细的指标。这些数据有助于识别热点、倾斜分区以及资源消耗异常大的阶段。正如 Pinterest 工程师在其博客中所解释的那样,了解内存是在作业的哪个环节被消耗的,对于有效解决故障至关重要。通过准确掌握问题发生的位置,团队能够进行精准地调整,而不是简单地全面增加内存。
可视化 Spark 工作流中的执行器级内存使用情况和自动内存重试(图片来源:Pinterest 博客)
配置调优进一步完善了这些洞察。内存分配、shuffle 分区和广播连接等 Spark 设置均根据工作负载模式进行了优化。自适应查询执行使系统能够动态调整分区,从而在高负载阶段缓解内存压力。额外增加的预处理有助于消除数据倾斜,而验证检查则能在庞大或异常数据集引发故障之前将其标记出来。对于高风险任务,人工审核仍是工作流的一部分,为的是确保管道保持稳定且可预测。
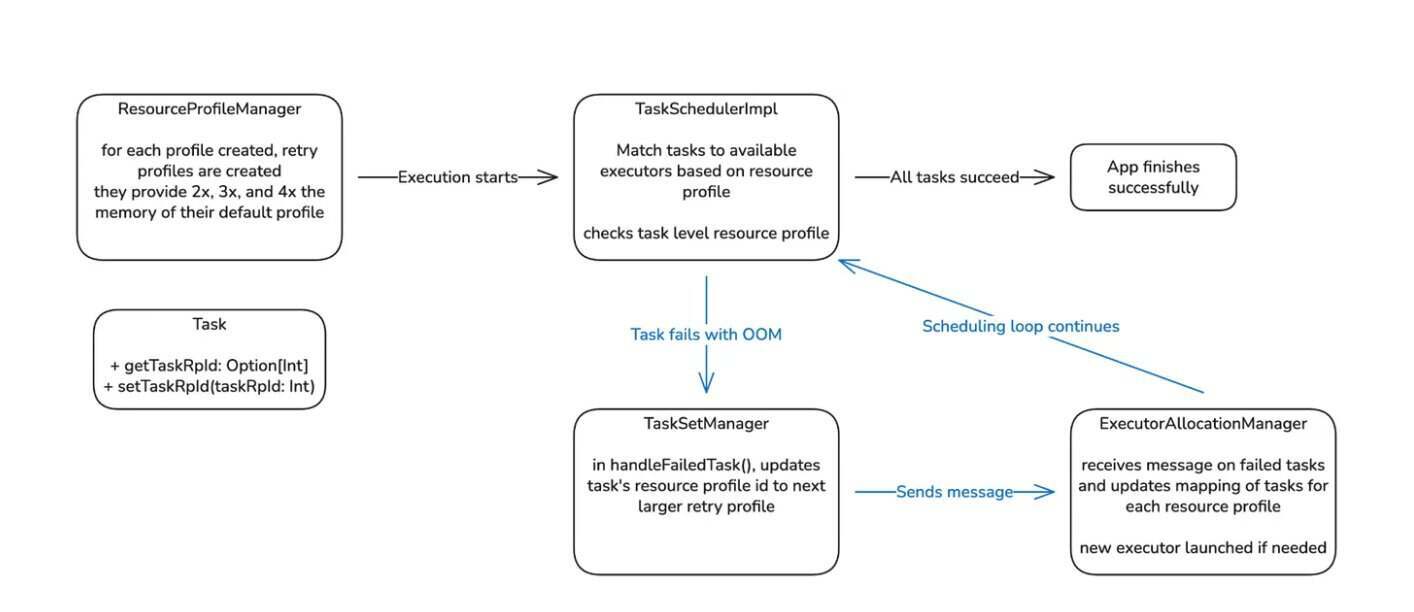
自动内存重试功能标志着工作流的重大转变。之前因内存耗尽而失败的任务,现在可以自动重启并采用更新后的内存设置。这种自动化消除了大量原本非常耗费工程师时间的手动调试工作,而且不需更改核心任务逻辑就可以让管道顺利完成。
这次部署经过了周密的规划。工程师们首先从临时任务入手,将重试率从 0% 逐步提升至 100%,随后转向计划任务,从优先级较低的工作负载开始,并最终将其应用于关键工作负载。仪表盘实时追踪了关键指标,包括恢复的任务数量、节省的成本、节省的内存(MB)和虚拟核心秒数(vCore seconds),以及重试后的失败情况。这种分阶段的方法使团队能够在全面部署前及早发现问题,确保系统的可靠性,并优化重试策略。
在这个过程中,各团队总结了重要的运维经验,包括提升大型任务集(TaskSet)的调度器性能、处理用于兼容 Apache Gluten 的自定义资源配置文件,以及调整主机故障排除规则,确保内存不足(OOM)故障不再妨碍重试。未来的工作将包括主动增加内存,即为处于高风险阶段的任务提前增加内存,以避免故障的发生,从而进一步减少重试次数并降低集群开销。
声明:本文为 InfoQ 翻译,未经许可禁止转载。
原文链接:https://www.infoq.com/news/2026/04/pinterest-spark-oom-reduction/




