
Hadoop 技术栈,一直是企业自建大数据平台的首选。随着企业数据量的指数级增长,云计算时代的到来,企业对存储的弹性、运维及 TCO 都提出了更高要求。曾经自建 Hadoop 大数据平台的企业正逐步将大数据平台迁移至云上。本文中,“一面数据”分享了其大数据平台迁移的架构设计及实践,文末有份超详细的云平台运维避坑实践。
背景
一面数据创立于 2014 年,是一家领先的数据智能解决方案提供商,通过解读来自电商平台和社交媒体渠道的海量数据,提供实时、全面的数据洞察。长期服务全球快消巨头(宝洁、联合利华、玛氏等),获得行业广泛认可。公司与阿里、京东、字节合作共建多个项目,旗下知乎数据专栏“数据冰山”拥有超 30 万粉丝。一面所属艾盛集团(Ascential)在伦敦证券交易所上市,在 120 多个国家为客户提供本地化专业服务。
公司在 2016 年线下机房部署了 CDH 集群,到 2021 年已存储和处理 PB 级的数据。公司自创立以来一直保持每年翻一番的高增长,而比业务量增长更快的是 Hadoop 集群的数据量。
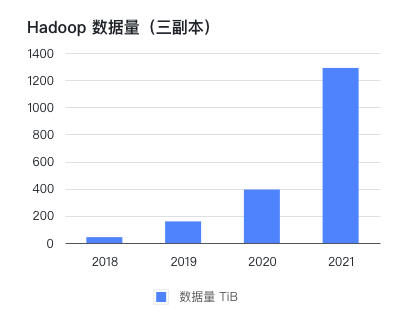
在这几年间,按 1 到 2 年规划的硬件,往往因数据增长超出预期而在半年后不得不再次扩容。每次扩容周期可达到一个月,除了花费大量精力跟进行政和技术流程,业务端也不得不安排较多人日控制数据量。
为了降低运维难度,发展可持续扩张的大数据处理方案,我们从 2021 年 10 月份开始探索取代现有 Hadoop 集群的方案。
当时提出了这些需求:
上云,弹性伸缩、灵活运维
存储计算分离
尽量使用开源组件,避免云厂商绑定
尽量降低业务迁移工作量
最终选择的方案是使用阿里云 EMR + JuiceFS + 阿里云 OSS 来搭建存算分离的大数据平台,将云下数据中心的业务逐步迁移上云。截至目前(2022 年 7 月)整体迁移进度约 40%,计划在 2022 年内完成全部业务的搬迁,届时云上 EMR 的数据量预计会超过单副本 1 PB.
技术选型
首先是决定使用哪家云厂商。由于业务需求,AWS、Azure 和阿里云都有在用,综合考虑后认为阿里云最适合,有这些因素:
物理距离:阿里云在我们线下机房同城有可用区,网络专线的延迟小,成本低
开源组件齐全:阿里云 EMR 上包含的开源组件很多很全,除了我们重度使用的 Hive、Impala、Spark、Hue,也能方便集成 Presto、Hudi、Iceberg 等。我们在调研时发现只有阿里云 EMR 自带了 Impala,AWS 和 Azure 要么版本低,要么要自己安装部署。
阿里云的 EMR 本身也有使用 JindoFS 的存算分离方案,但基于以下考虑,我们最终选择了 JuiceFS:
灵活性:JuiceFS 使用 Redis 和对象存储为底层存储,客户端完全是无状态的,可以在不同环境访问同一个文件系统,提高了方案的灵活性。而 JindoFS 元数据存储在 EMR 集群的本地硬盘,不便于维护、升级和迁移。
可移植性:JuiceFS 的存储方案丰富,而且支持不同方案的在线迁移,提高了方案的可移植性。JindoFS 块数据只支持 OSS.
开源:JuiceFS 以开源社区为基础,支持所有公有云环境,方便后期扩展到多云架构。
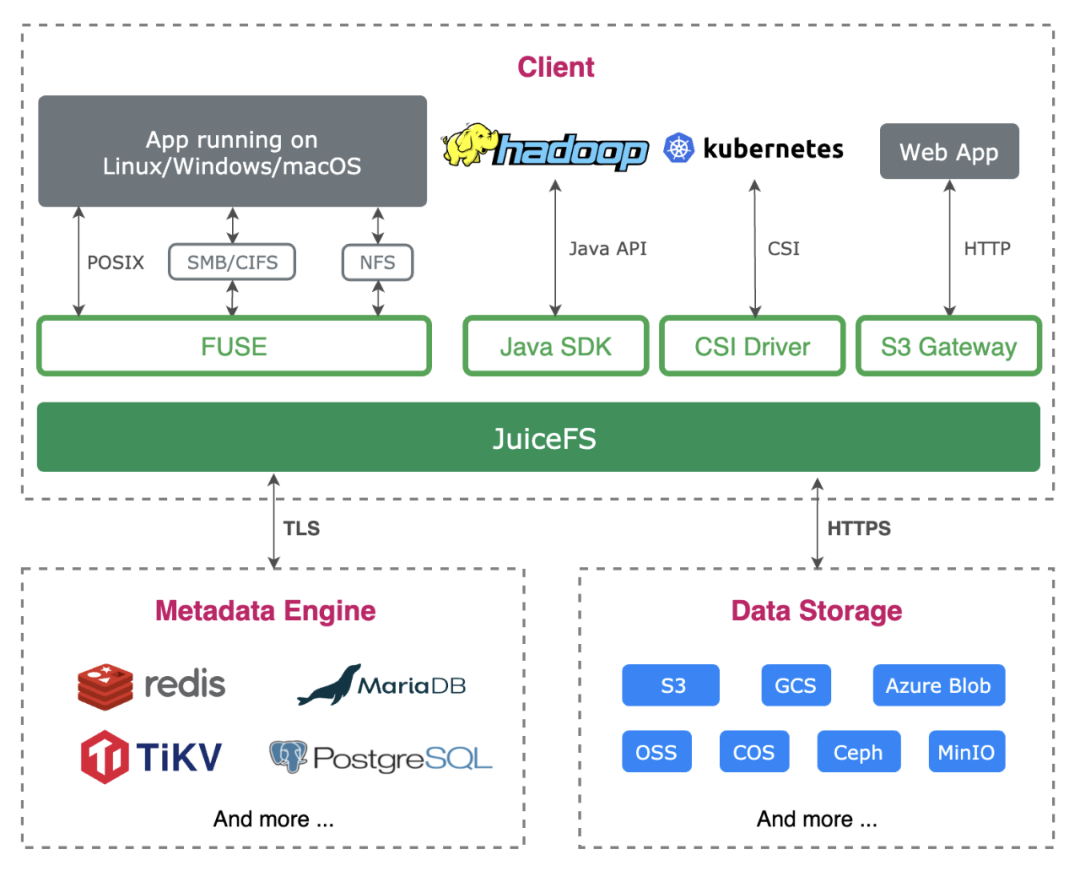
关于 JuiceFS
直接截取官方文档[1]的介绍:
JuiceFS 是一款面向云原生设计的高性能共享文件系统,在 Apache 2.0 开源协议下发布。提供完备的 POSIX[2] 兼容性,可将几乎所有对象存储接入本地作为海量本地磁盘使用,亦可同时在跨平台、跨地区的不同主机上挂载读写。
JuiceFS 采用「数据」与「元数据」分离存储的架构,从而实现文件系统的分布式设计。使用 JuiceFS 存储数据,数据本身会被持久化在对象存储[3](例如,Amazon S3),相对应的元数据可以按需持久化在 Redis、MySQL、TiKV、SQLite 等多种数据库[4]中。
除了 POSIX 之外,JuiceFS 完整兼容 HDFS SDK,与对象存储结合使用可以完美替换 HDFS,实现存储和计算分离。
实施过程
我们在 2021 年 10 月开始探索 Hadoop 的上云方案;11 月做了大量调研和讨论,基本确定方案内容;12 月和 2022 年 1 月春节前做了 PoC 测试,在春节后 3 月份开始搭建正式环境并安排迁移。为了避免导致业务中断,整个迁移过程以相对较慢的节奏分阶段执行,截至目前(2022 年 7 月)进度约 40%,计划在 2022 年内完成整体的搬迁。迁移完后,云上的 EMR 集群数据量预计会超过单副本 1 PB.
架构设计
做完技术选型之后,架构设计也能很快确定下来。考虑到除了 Hadoop 上云之外,仍然有大部分业务会继续保留在数据中心,所以整体实际上是个混合云的架构。
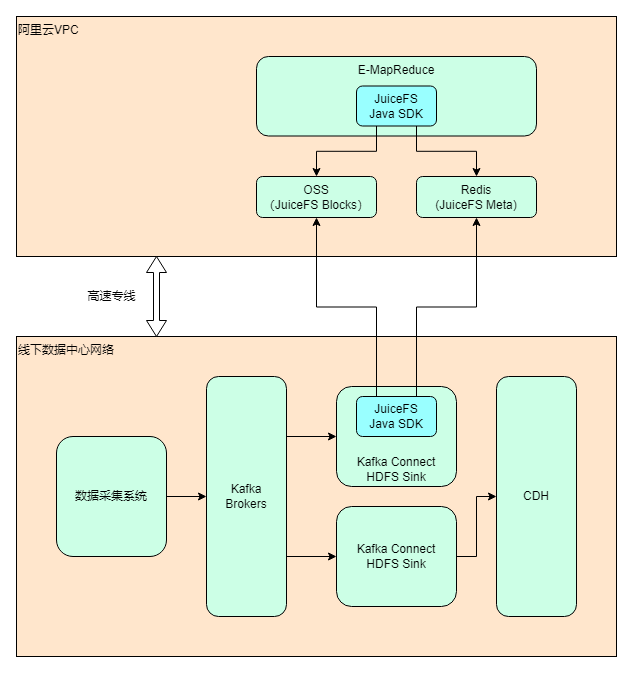
部署和配置
关于 IDC-阿里云专线:能提供专线服务的供应商很多,包括 IDC、阿里云、运营商等,选择的时候主要考虑线路质量、成本、施工周期等因素,最终我们选择了 IDC 的方案。IDC 跟阿里云有合作,很快就完成了专线的开通。这方面如果遇到问题,可以找 IDC 和阿里云的支持。除专线租用成本,阿里云也会收取下行(从阿里云到 IDC)方向传输费用。专线两端的内网 IP 完全互通,阿里云和 IDC 两侧都需要一些路由配置。
关于 EMR Core/Task 节点类型的选择:
JuiceFS 可以使用本地硬盘做缓存,能进一步减少 OSS 带宽需求并提高 EMR 性能。更大的本地存储空间,可以提供更高的缓存命中率。
阿里云本地 SSD 实例是较高性价比的 SSD 存储方案(相对于云盘),用作缓存正合适。
JuiceFS 社区版未支持分布式缓存,意味着每一个节点都需要一个缓存池,所以应该选用尽量大的节点。
基于以上考虑和配置对比,我们决定选用 ecs.i2.16xlarge,每个节点 64 vCore、512GiB Memory、1.8T*8 SSD。
关于 EMR 版本:软件方面,主要包括确定组件版本、开启集群、修改配置。我们机房使用的是 CDH 5.14,其中 Hadoop 版本是 2.6,阿里云上最接近的版本是 EMR 3.38. 但调研时发现该版本的 Impala 和 Ranger 不兼容(实际上我们机房使用的是 Sentry 做权限管理,但 EMR 上没有),最终经过评估对比,决定直接使用 EMR 5 的最新版,几乎所有组件的大版本都做了升级(包含 Hadoop 3、Spark 3 和 Impala 3.4)。此外,使用外部 MySQL 作为 Hive Metastore、Hue、Ranger 的数据库。
关于 JuiceFS 配置:基本参考 JuiceFS 官方文档《在 Hadoop 中通过 Java 客户端访问 JuiceFS[5]》即可完成配置。另外我们也配置了这些参数:
缓存相关:其中最重要的是
juicefs.cache-dir缓存目录。这个参数支持通配符,对多个硬盘的实例环境很友好,如设置为/mnt/disk*/juicefs-cache(需要手动创建目录,或在 EMR 节点初始脚本中创建),即用全部本地 SSD 作为缓存。另外也要关注juicefs.cache-size、juicefs.free-space两个参数。juicefs.push-gateway:设置一个 Prometheus Push Gateway,用于采集 JuiceFS Java 客户端的指标。juicefs.users、juicefs.groups:分别设置为 JuiceFS 中的一个文件(如jfs://emr/etc/users、jfs://emr/etc/groups),解决多个节点 uid 和 gid 可能不统一的问题。关于 Kafka Connect 使用 JuiceFS:
经过一些测试,确认 JuiceFS 可以完美应用于 Kafka Connect 的 HDFS Sink 插件(我们把配置方式也补充到了官方文档[6])。相比使用 HDFS Sink 写入 HDFS,写入 JuiceFS 需要增加或修改以下配置项:
将 JuiceFS Java SDK 的 JAR 包发布到 Kafka Connect 每一个节点的 HDFS Sink 插件目录。Confluent 平台的插件路径是:
/usr/share/java/confluentinc-kafka-connect-hdfs/lib编写包含 JuiceFS 配置的
core-site.xml,发布到 Kafka Connect 每一个节点的任意目录。包括这些必须配置的项目:
fs.jfs.impl = io.juicefs.JuiceFileSystemfs.AbstractFileSystem.jfs.impl = io.juicefs.JuiceFSjuicefs.meta = redis://:password@my.redis.com:6379/请参见 JuiceFS Java SDK 的配置文档。
Kafka Connector 任务设置:
hadoop.conf.dir=<core-site.xml所在目录>store.url=jfs://<JuiceFS文件系统名称>/<路径>PoC
PoC 的目的是快速验证方案的可行性,有几个具体目标:
验证 EMR + JuiceFS + OSS 整体方案的可行性
检查 Hive、Impala、Spark、Ranger 等组件版本的兼容性
评估对比性能表现,用了 TPC-DS 的测试用例和部分内部真实业务场景,没有非常精确的对比,但能满足业务需求
评估生产环境所需的节点实例类型和数量(算成本)
探索数据同步方案
探索验证集群与自研 ETL 平台、Kafka Connect 等的集成方案
期间做了大量测试、文档调研、内外部(阿里云 + JuiceFS 团队)讨论、源码理解、工具适配等工作,最终决定继续推进。
数据同步
要迁移的数据包括两部分:Hive Metastore 元数据以及 HDFS 上的文件。由于不能中断业务,采用存量同步 + 增量同步(双写)的方式进行迁移;数据同步完后需要进行一致性校验。
存量同步
对于存量文件同步,可以使用 JuiceFS 提供的功能完整的数据同步工具 sync 子命令[8] 来实现高效迁移。JuiceFS sync 命令支持单节点和多机并发同步,实际使用时发现单节点开多线程即可打满专线带宽,CPU 和内存占用低,性能表现非常不错。
Hive Metastore 的数据同步则相对麻烦些:
两个 Hive 版本不一致,Metastore 的表结构有差异,因此无法直接使用 MySQL 的导出导入功能
迁移后需要修改库、表、分区存储路径(即
dbs表的DB_LOCATION_URI和sds表的LOCATION)
因此我们开发了一套脚本工具,支持表和分区粒度的数据同步,使用起来很方便。
增量同步
增量数据主要来自两个场景:Kafka Connect HDFS Sink 和 ETL 程序,我们采用了双写机制。
Kafka Connect 的 Sink 任务都复制一份即可,配置方式上文有介绍。ETL 任务统一在内部自研的低代码平台上开发,底层使用 Airflow 进行调度。通常只需要把相关的 DAG 复制一份,修改集群地址即可。实际迁移过程中,这一步遇到的问题最多,花了大量时间来解决。主要原因是 Spark、Impala、Hive 组件版本的差异导致任务出错或数据不一致,需要修改业务代码。这些问题在 PoC 和早期的迁移中没有覆盖到,算是个教训。
数据校验
数据同步完后需要进行一致性校验,分三层:
文件一致。在存量同步阶段做校验,通常的方式是用 checksum. 最初的 JuiceFS sync 命令不支持 checksum 机制,我们建议和讨论后,JuiceFS 团队很快就加上了该功能(issue[9],pull request[10])。除了 checksum,也可考虑使用文件属性对比的方式:确保两个文件系统里所有文件的数量、修改时间、属性一致。比 checksum 的可靠性稍弱,但更轻量快捷。
元数据一致。有两种思路:对比 Metastore 数据库的数据,或对比 Hive 的 DDL 命令的结果。
计算结果一致。即使用 Hive/Impala/Spark 跑一些查询,对比两边的结果是否一致。一些可以参考的查询:表/分区的行数、基于某个字段的排序结果、数值字段的最大/最小/平均值、业务中经常使用的统计聚合等。
数据校验的功能也封装到了脚本里,方便快速发现数据问题。
后续计划
大致有几个方向:
继续完成剩余业务的上云迁移
探索 JuiceFS + OSS 的冷热分级存储策略。JuiceFS 的文件在 OSS 上完全被打散,无法基于文件级别做分级。目前的思路是将冷数据从 JuiceFS 迁移到 OSS 上,设置为归档存储,修改 Hive 表或分区的 LOCATION,不影响使用。
目前 JuiceFS 使用 Redis 作为元数据引擎,假如将来数据量增加,使用 Redis 有压力的话可能考虑切换为 TiKV 或其他引擎。
探索 EMR 的弹性计算实例,争取能在满足业务 SLA 的前提下降低使用成本
一手实战经验
在整个实施过程中陆陆续续踩了一些坑,积累了一些经验,分享给大家做参考。
阿里云 EMR 和组件相关
兼容性
EMR 5 的 Hive 和 Spark 版本不兼容,无法使用 Hive on Spark,可以把默认的引擎改成 Hive on Tez.
Impala 的 stats 数据从旧版同步到新版后,可能因为 IMPALA-10230[11] 导致表无法查询。解决方案是在同步元数据时,将
num_nulls=-1的改成num_nulls=0. 可能需要用到 CatalogObjects.thrift 文件[12]。原集群有少量 Textfile 格式的文件用了 snappy 压缩,新版 Impala 无法读取,报错
Snappy: RawUncompress failed,可能是 IMPALA-10005[13] 导致的。规避方案是不要对 Textfile 文件使用 snappy 压缩。Impala 3.4 相比 2.11 的
CONCAT_WS函数行为有差异,老版本CONCAT_WS('_', 'abc', NULL)会返回NULL,而新版本返回'abc'.Impala 3.4 对 SQL 中的保留关键字引用更严格,必须加上``. 其实一个好习惯是业务代码不要使用保留关键字。
PoC 或前期测试的覆盖度尽可能完整,用真实的业务代码去跑。我们在 PoC 和早期迁移的业务中用到的组件特性比较少,基本都是最常用、保持兼容的功能,因此比较顺利。但在第二批迁移过程中就暴露出了很多问题,虽然最终都有解决,但花了很多额外的时间去做诊断和定位,打乱了节奏。
性能
EMR 5 的 Impala 3.4 打了 IMPALA-10695[14] 这个补丁,支持对
oss://和jfs://(本意是支持 JindoFS,但 JuiceFS 也默认使用 jfs 这个 scheme)设置独立的 IO 线程数。在 EMR 控制台上增加或修改 Impala 的配置项num_oss_io_threads.阿里云 OSS 有账号级别的带宽限制,默认 10Gbps,随着业务规模上升容易成为瓶颈。可以与阿里云沟通调整。
运维
EMR 可以关联一个 Gateway 集群,通常用来部署业务程序。如果要在 Gateway 上用 client 模式提交 Spark 任务,需要先将 Gateway 机器的 IP 加到 EMR 节点的 hosts 文件。默认可以使用 cluster 模式。
EMR 5 会开启一个 Spark ThriftServer,在 Hue 上可以直接写 Spark SQL,用起来很方便。但默认配置有个坑,会写大量日志(路径大概是
/mnt/disk1/log/spark/spark-hadoop-org.apache.spark.sql.hive.thriftserver.HiveThriftServer2-1-emr-header-1.cluster-xxxxxx.out),导致硬盘写满。解决方案有两个:配置 log rotate 或把spark.driver.extraJavaOptions配置清空(阿里云技术支持的建议)。
JuiceFS 相关
JuiceFS 需要每个节点上具有相同的 UID 和 GID,否则很容易出现权限问题。有两种实现方式:修改操作系统的用户[15](比较适合新机器,没有历史包袱),或者在 JuiceFS 上维护一个用户映射表[16]。我们之前也分享过一篇 JuiceFS + HDFS 权限问题定位[17],有详细讨论。通常需要维护映射的用户有
impala,hive,hadoop等。如果使用 Confluent Platform 搭建 Kafka Connect,也需要配置cp-kafka-connect用户。使用默认的 JuiceFS IO 配置[18]时,相同的写查询,Hive on Tez 和 Spark 都比 Impala 快很多(但在机房里 Impala 更快)。最终发现将
juicefs.memory-size从默认的300(MiB) 改成1024之后 Impala 的写入性能有成倍的提升。在做 JuiceFS 的问题诊断和分析时,客户端日志很有用,需要注意 POSIX 和 Java SDK 的日志是不一样的,详见 JuiceFS 故障诊断和分析 | JuiceFS Document Center[19]
注意监控 Redis 的空间用量,Redis 如果满了,整个 JuiceFS 集群无法写入。
使用 JuiceFS sync 把机房数据往云上同步时,选择在有 SSD 的机器上跑,获得更好的性能。
作者简介:
刘畅,一面数据运维负责人,十五年程序老兵,计算机原理、算法、编程爱好者。
李阳良,一面数据大数据部门负责人,九年互联网工作经验,对后台开发、大数据技术接触比较多。
引用链接
[1] 官方文档: https://juicefs.com/docs/zh/community/introduction/
[2] POSIX: https://en.wikipedia.org/wiki/POSIX
[3] 对象存储: https://juicefs.com/docs/zh/community/how_to_setup_object_storage#支持的存储服务
[4] 数据库: https://juicefs.com/docs/zh/community/databases_for_metadata
[5] 在 Hadoop 中通过 Java 客户端访问 JuiceFS: https://juicefs.com/docs/zh/community/hadoop_java_sdk
[6] 官方文档: https://juicefs.com/docs/zh/community/hadoop_java_sdk#kafka-connect
[8] sync 子命令: https://juicefs.com/docs/zh/community/administration/sync
[9] issue: https://github.com/juicedata/juicefs/issues/1105
[10] pull request: https://github.com/juicedata/juicefs/pull/1208
[11] IMPALA-10230: https://issues.apache.org/jira/browse/IMPALA-10230
[12] CatalogObjects.thrift 文件: https://github.com/apache/impala/blob/3.x/common/thrift/CatalogObjects.thrift
[13] IMPALA-10005: https://issues.apache.org/jira/browse/IMPALA-10005
[14] IMPALA-10695: https://issues.apache.org/jira/browse/IMPALA-10695
[15] 修改操作系统的用户: https://juicefs.com/docs/zh/community/sync_accounts_between_multiple_hosts
[16] 用户映射表: https://juicefs.com/docs/zh/community/hadoop_java_sdk/#%E5%85%B6%E5%AE%83%E9%85%8D%E7%BD%AE
[17] JuiceFS + HDFS 权限问题定位: https://zhuanlan.zhihu.com/p/452232533
[18] JuiceFS IO 配置: https://juicefs.com/docs/zh/community/hadoop_java_sdk#io-%E9%85%8D%E7%BD%AE
[19] JuiceFS 故障诊断和分析 | JuiceFS Document Center: https://juicefs.com/docs/zh/community/fault_diagnosis_and_analysis




