
虽然该领域的公司数量在不断增加,但可以看到,其中有几个类别的产品出现了整合迹象。MLOps 趋向于端到端,Notebook 正在进入编排领域,而编排正在转向数据谱系和可观察性。与此同时,我们看到,开放式表格式进入了元存储功能。而在治理层,安全和权限管理工具进入目录领域,反之亦然。
本文最初发布于 lakeFS 官方博客。
自我们分享“2021 年数据工程现状”已经过了一年。从去年 5 月我们发布那篇文章以来,数据领域并没有多少变化。事实上,我们曾在内部讨论过 2022 年还要不要做一次更新。
开玩笑的。这一年还是很值得说的。所以,我们再次回来,对数据工程的现状做下更新和分享。
这一年有什么变化呢?
过去一年的主要主题是整合(consolidation)。一些公司扩大了他们的业务范围,进入了新的类别,也有一些公司的出现仅仅是为了取代数据工程栈中一些现有的工具。
让我们来看看更新后的数据工程地图,今年的分辨率更高。
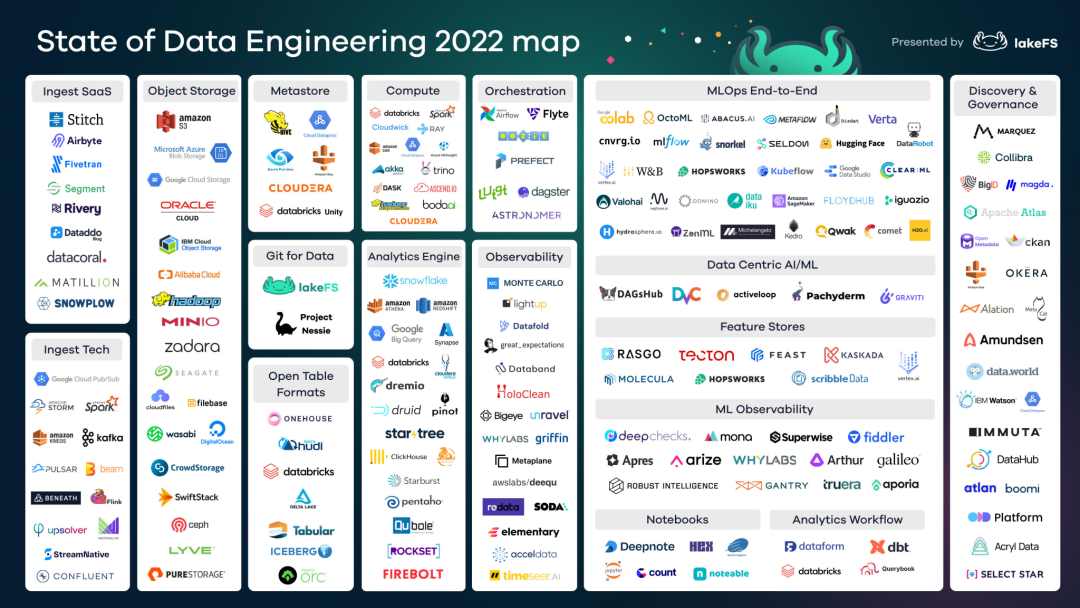
点击查看 2022 年数据工程现状全尺寸地图(可放大)
数据摄取
这一层包括流技术和 SaaS 服务,提供从业务系统到数据存储的管道。
这方面值得一提的进展是 Airbyte 的戏剧性崛起。Airbyte 成立于 2020 年,在这年年底才转向其当前的产品。Airbyte 是一个开源项目,目前有超过 15000 家公司在使用。其社区有超过 600 名贡献者。在采用和社区方面,如此指数级的增长非常罕见。
Airbyte 刚刚推出了他们的商业产品,并通过收购 Grouparoo(一个反向 ETL 连接器开源项目)扩展到反向 ETL(一个在数据工程现状地图中没有涉及的类别)。我们认为,反向 ETL 是一个与 ETL 有很大差别的产品,因为它需要将数据集成到业务系统中,帮助用户完成该系统中的工作流。
我们很想知道事情的结果如何。
数据湖
2021 年,我们将数据仓库和湖仓(lakehouse)作为数据湖层的一部分。但今年,我们决定保留数据湖这个类别,仅指用作数据湖的对象存储技术。我们将所有的数据仓库和湖仓移至分析引擎类别。
为什么?如今,数据工程师处理的大多数架构都很复杂,足以同时包括对象存储和分析引擎。因此,你要么只需要一个分析数据库(这种情况没有数据湖,只有一个作为分析引擎的数据仓库),要么两者都要。而当两者都需要时,你通常会在对象存储上执行一些分析,在分析引擎上执行另一些分析。这就是为什么它们需要很容易搭配使用。
这种依赖关系发生在不同的层。大型数据集会托管在对象存储中,而工件和服务层数据集将存储在分析引擎和数据库中。在我们知道的架构中,没有看到一个征服另一个的情况。
我们看到,在现实中,这些解决方案是并存的。这种架构产生的背后有多种原因,但其中一个肯定是成本考虑。在 Snowflake 或 BigQuery 中查询大量的数据是很昂贵的。因此,与其让分析数据库管理整个湖,不如在对象存储中管理一切它可以管理的东西,在它上面执行计算更便宜,而将所有必须由分析引擎管理的东西交给分析引擎。
我们认为,湖仓是一个分析引擎(尽管在 Databricks 中,它既包括数据湖,也包括分析引擎)。这个架构的特点是使用 Spark SQL 的优化版本在 Delta 表格式上创建一个分析引擎。这提供了人们希望从分析引擎获得的性能和成本。
同样的规则适用于 Iceberg 上的 Dremio,或支持将 Iceberg 作为数据库外部表的 Snowflake。
元数据管理
在元数据领域发生了很多事情!元数据的两个层次——这一层和图表顶部的组织层——正成为许多组织的关注点。
回顾我们作为可扩展数据从业者所面临的挑战,在过去十年中,我们一直在围绕存储和计算机进行创新——所有这些都是为了确保它们支持数据的扩展。
如今,我们面临的主要是可管理性问题,我们可以通过生成和管理元数据来解决这些问题。这一层涉及元数据的不同方面,让我们逐个看下。
开放式表格式
我们看到,在过去的一年里,开放式表格式取得了有趣的进步。它们正在成为数据湖中保存结构化数据的标准。
一年之前,Delta Lake 是一个 Databricks 项目,它有一个商业化产品叫 Delta。然后在今年,Onehouse 公司商业化了 Apache Hudi,Tabular 公司商业化了 Apache Iceberg。这两家公司都是由这些开源项目的创建者创立的。
因此,整个领域从开源变成了完全由商业实体支撑。这让人不禁会问,既然背后有商业利益,其他参与者对开源项目还能有多大影响。
由于这三个开源项目都属于 Apache/Linux 基金会,所以对社区而言风险很低。这似乎并不能平息这三个项目的创建者和粉丝之间的激烈争论,围绕谁“真正”开源以及谁提供了最好的解决方案。Netflix 很快就会把这个故事作为电视剧的绝佳素材。
Metastore 的未来仍不明朗……
我们看到,Hive Metastore 被从架构中移除,开放式表格式或许可以替代它。并不是所有的组织都充分利用了 Metastore 的能力,如果他们唯一的用例是虚拟化表,那么开放式表格式和以它为基础构建的商业产品提供了一个很好的选择。Metastore 的其他用例还没有更好的替代解决方案。
Git For Data
Git For Data 的概念在社区中日渐流行。dbt 鼓励分析师在不同版本的数据(开发、过渡和生产)上使用最佳实践,但不支持在数据湖中创建和维护这些数据集。
数据运营团队越来越需要提供跨组织的数据版本控制,以管理随着时间推移做过不同修订的数据集。对一个数据集进行不同修订的例子有:重新计算,这是算法和 ML 模型所必需的,或者是来自运营系统的回填,这在 BI 中经常发生,或者是遵循 GDPR 被遗忘权规定而删除一个子集。
这一趋势从 LakeFS 及其社区的急剧增长可以明显看出来,我亲眼目睹了这一点。LakeFS 同时提供了结构化和非结构化数据操作服务,在两者都存在的情况下大放光彩。
遗憾的是,关于 Dremio 的 Nessie 项目的使用情况,很难找到公开数据。有趣的是,它还提供了一个名为 Arctic 的免费服务。这可能是为了与 Tabular 竞争而做出的战略决定。
计算
为了更好地反映生态系统现状,我们今年对计算层做了一些修改。首先,我们完全删除了虚拟化这个类别。它目前似乎还没有流行开来。
然后我们把计算引擎分成两类:分布式计算和分析引擎。它们之间的主要区别在于这些工具对其存储层的要求。
分布式计算包括对存储没有要求的计算引擎,而分析引擎类别包含有要求的计算引擎(无论是否分布式)。
分布式计算
一般的分布式计算引擎允许工程师分发任意 SQL 或任何其他代码。当然,它们可能对编程语言有要求,但它们会在(通常是)联合数据上进行普遍分发。这可能是跨许多格式和数据源的数据。
分布式计算类别中新增了两个有趣的补充:Ray 和 Dask。
Ray 是一个开源项目,允许工程师扩展任何计算密集型的 Python 工作负载,主要用于机器学习。Dask 也是一个基于 Pandas 的分布式 Python 引擎。
你可能认为,Spark 将是统治这个领域的分布式引擎,看不到任何竞争。因此,见证新技术在这一类别中的崛起还是相当令人兴奋的。
分析引擎
分析引擎类别包括所有的数据仓库,如 Snowflake、BigQuery、Redshift、Firebolt 以及老好的 PostgreSQL。它还包含像 Databricks lakehouse、Dremio 或 Apache Pinot 这样的湖仓。所有这些工具都有自己支持的数据格式,为的是使查询引擎提供更好的性能。
由于所有的分析引擎都使用数据湖作为深层存储或存储,所以值得一提的是,Snowflake 现在支持将 Apache Iceberg 作为外部表格式之一,可以由 Snowflake 直接从湖中读取。
编排和可观察性
这是今年新增加的一层,但由现有的类别组成。编排工具去年是元数据层的一部分,但我们把它移到了它真正属于的计算引擎层——它主要是跨计算引擎和数据源编排管道。
与此同时,我们看到,可观察性工具在 2021 年有了很大的发展,可以支持更多的数据源(产生于任何计算引擎)。
编排
关于编排,有什么引人注目的事情发生吗?Airflow 仍然是最大的开源产品。从加入云计算行列至今,Astronomer 多年来一直以它为基础。现在,Astronomer 直接与云供应商在托管 Airflow 领域展开了竞争。
Astronomer 另一个非常有趣的举动是收购了提供数据谱系的 Datakin。这让人不禁要问——当一个编排工具具备了数据谱系能力时会发生什么?
理论上,这可以帮助数据团队构建更安全、更有弹性的管道。了解哪些数据集依赖于缺失、损坏或低质量的数据,将逻辑(由编排工具管理)和它们的输出(由谱系工具管理)联系起来,影响分析将变得相当容易。这是否会成为编排生态系统的一个组成部分,还有待观察。
可观察性
这个类别由 Monte Carlo 数据公司创建,也由它主导。Monte Carlo 的频繁融资表明其产品在市场上被迅速采用。该产品不断发展,提供了更多的集成(如 Databricks 生态系统),以及额外的可观察性和根源分析功能。或许正是这种成功推动了这一类别的增长,至少从如今在探索这一领域的公司数量来看是如此。2021 年,有几家公司成立或打破隐身状态,最有趣的是 Elementary,又一个来自 YC 的开源项目。
数据科学和分析的可用性
这一层是为数据架构(通过前几层创建)用户准备的:数据科学家和分析师,他们从数据获取洞察力。我们把这个类别分成三个子类别:
端到端 MLOps 工具以数据中心化 ML 方法为基础的工具 ML 可观察性和监控
端到端 MLOps 工具
当我着手考察这个领域时,有人告诉我,我应该把这个类别命名为:“准备好失望吧”。虽然这个类别有很棒的工具,但没有一个是真正的端到端。它们为 ML 过程中的某些步骤提供了很好的解决方案,但对 ML 管道的其他方面缺乏支持。
尽管如此,提供端到端解决方案的方法在 2021 年还是很受欢迎。有几款面向特定任务的工具走上了这一道路,成为了端到端的产品,如 Comet、Weights & Biases、Clear.ml 和 Iguazio。
数据中心化 ML
这个子类别也没有逃脱端到端的陷阱,但其中列出的工具采用了不同的方法来提供功能。它们以数据及其管理作为任务的中心。
这个领域有两个新成员 Activeloop 和 Graviti。它们是由经验丰富的数据从业者构建的,他们了解数据管理对数据操作成功的重要性。在 LakeFS,我们也有这样的感受。
DagsHub 采取了一种独特的方法,提供了一个以数据为中心的端到端解决方案,不过是基于开源解决方案。他们在 ML 生命周期的每个阶段都很出色,提供了很好的可用性,并且易于集成。在这样一个混乱的领域里,这是一个可靠的方法,可以得到一个不错的端到端解决方案,同时也可以取悦用户。我们正满心期待地看着这家公司…
ML 可观察性和监控
这个子类别包括专注于模型质量监控和可观察性的工具。与数据可观察性类别非常相似,这一领域正在成长并逐步形成良好的发展势头。2022 年初,Deepchecks 开放了源代码,并迅速获得关注,吸引了不少贡献者和合作伙伴。
Notebooks
在 Notebooks 类别中,我们看到,得益于 Databricks 和 Snowflake 的投资,Hex 得到了更多的关注和验证。Hex 在其 Notebook 中提供了更多编排能力。Ploomber 也是如此,它的出现为 Jupyter 提供了编排能力。
在过去的一年里,这个面向分析师的工具类别确立了自己的地位,并赢得了一些竞争。dbt 证明了自己是分析师的标准。2021 年,它发布了与可扩展数据工程栈的集成,包括对象存储、HMS 和 Databricks 的产品。在与生态系统合作的同时,2021 年,Databricks 推出了其“活性表”产品的正式版本,与 dbt 展开了直接竞争。
目录、权限和治理
对于这个生态系统,我的感觉是,现在各种规模的公司对数据目录的需求都很明确。我们将看到,它会成为一种标准。基于开源项目的商业产品显示出良好的采用水平。
与此同时,企业解决方案的长期供应商,Alation 和 Collibra,继续扩展他们的产品。而安全和权限管理供应商 BigID 也在试图提供一个目录。
Immuta 继续致力于数据访问控制,其独特的技术使它现在可以兼容更多的数据源。为了加速发展,该公司早在 2021 年中期就完成了 9000 万美元的 D 轮融资。
小结
虽然该领域的公司数量在不断增加,但可以看到,其中有几个类别的产品出现了整合迹象。
MLOps 趋向于端到端,Notebook 正在进入编排领域,而编排正在转向数据谱系和可观察性。与此同时,我们看到,开放式表格式进入了元存储功能。而在治理层,安全和权限管理工具进入目录领域,反之亦然…
这些迹象是否预示着市场(仍然)有限,也许是 MLOps 市场有限?这种整合是否反映了由于激烈的竞争而产生的差异化需求(在编排方面可能是这种情况)?还是说这是一个填补空白的机会,像开放式表格或数据中心化 ML 那样的情况?还是说,这都是因为用户希望使用更少的工具来做更多的事情?
我打算把这些问题留给读者,希望能引发对 2022 年数据工程状况的讨论。
2022 年,还有哪些项目正在获得发展的动力?哪些工具正在成为行业内的事实标准?欢迎在评论区分享您的想法。
关于 lakeFS
lakeFS 项目是一项开源技术,为数据湖提供类似 Git 的版本控制接口,并与流行的数据工具和框架无缝集成。我们的使命是最大限度地提高开源数据分析解决方案的可管理性。
查看英文原文:




