
本文将主要针对 VPA(Vertical Pod Autoscaler,Pod 垂直自动扩缩容)中的核心组件 Recommender(V0.9.2 版)进行源码级别的解析与实践,该组件对 VPA 整体设计、多种调度策略组合应用有着重大的影响。
文章结构如下:
文章将先对 VPA 进行一个整体的介绍,包括目标、架构、Recommender 设计理念等;
接着针对核心组件 Recommender 各个流程进行详细解读;
第三部分将介绍预测模型中的滑动窗口思想与半衰指数直方图组件,以及如何扩展该功能以实现资源预测;
第四部分主要介绍我们针对 VPA Recommender 组件的一些实践,包括如何将 CPU、内存指标扩展至磁盘、网络等 13 项指标以实现应用画像的功能,以及我们做的一些性能优化。
最后一部分将简要介绍 Google 的 Autopilot 以及 VPA 在工业界的其他应用。
1. VPA 简介
VPA 使用户无需为 pod 中的容器设置最新的资源请求。 配置后,它将根据资源(cpu 与内存)使用情况自动设置 requests。 在对 pod 的调度过程中,使得每个 pod 都可以使用适当的资源量从而分配到适合的节点上。 它既可以缩小资源请求过多的 pod,也可以根据一段时间内的使用情况扩大资源请求不足的 pod。
目标
垂直缩放有两个目标:
通过自动配置资源需求来降低维护成本。
提高集群资源的利用率,同时最大限度地降低容器内存不足或 CPU 不足的风险。
架构
下图引自 vpa 官方 git 架构图,具体介绍如下:
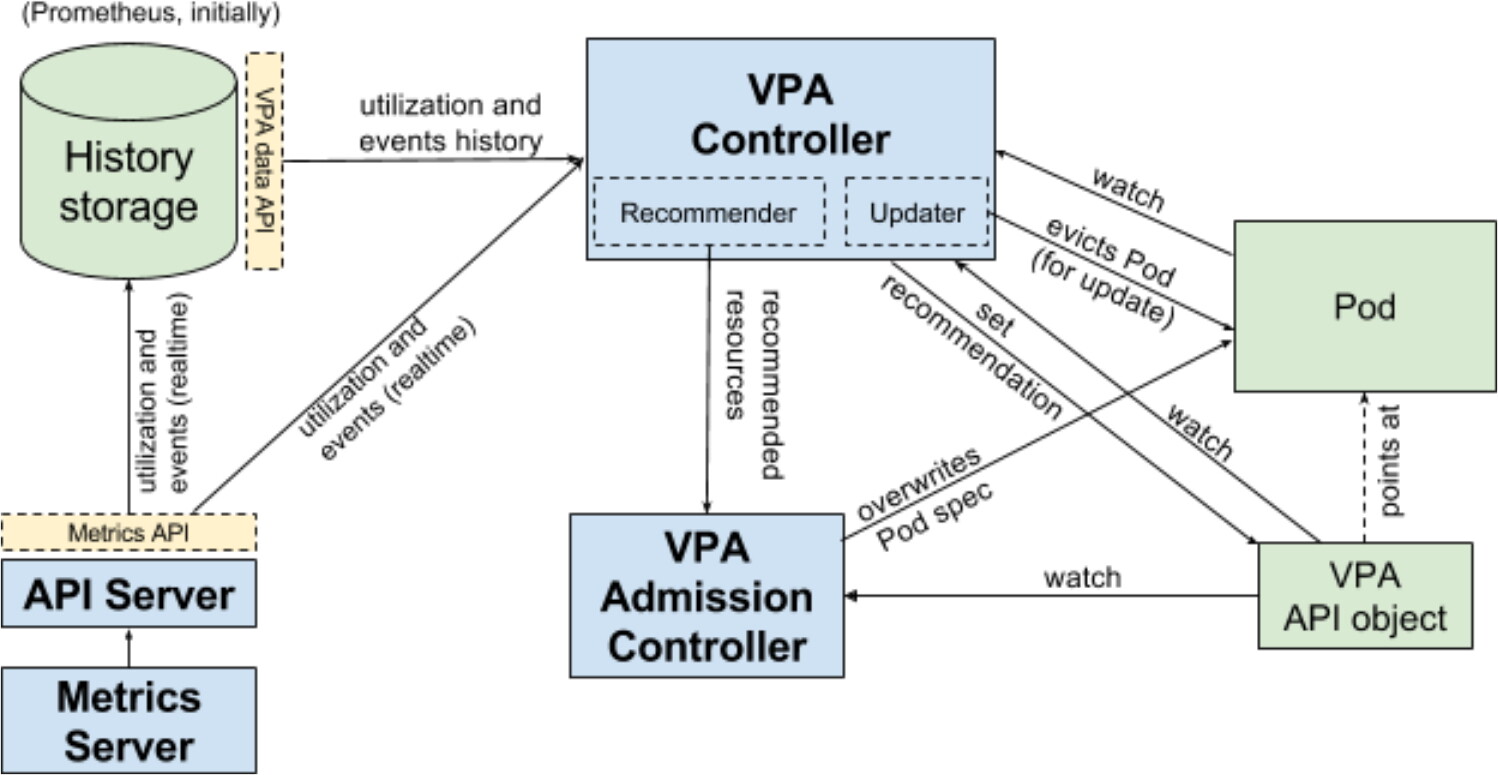
VPA 引入了一种新型的 API 资源:VerticalPodAutoscaler。它由匹配 Pod 的标签选择器、资源策略(控制 VPA 如何计算资源)、更新策略(控制如何将更改应用于 Pod)和推荐的 Pod 资源(输出字段)组成。
VPA Recommender 监视所有 Pod,不断为它们计算新的推荐资源,并将推荐值存储在 VPA 对象中。它使用来自 Metrics Server 的集群中所有 Pod 的利用率和 OOM 事件。后文会对该组件进行详细的分析。
所有 Pod 创建请求都通过 VPA Admission Controller。如果 Pod 与任何 VerticalPodAutoscaler 对象匹配,准入控制器将使用 VPA 推荐器提供的推荐覆盖 Pod 中容器的资源。如果 Recommender 不可用,它会回退到 VPA 对象中缓存的推荐。
VPA Updater 是负责 Pod 实时更新的组件。如果 Pod 在 "Auto" 模式下使用 VPA,则 Updater 可以决定使用推荐器资源对其进行更新。在 最小可行版本(MVP,Minimum Viable Product) 中,这只是通过驱逐 Pod 以便使用新资源重新创建它来实现的。这种方法要求 Pod 属于一个 controller(如 deployment,或其他一些能够重新创建 pod 的控制器)。由于该种方式会造成 pod 的重启以及重新调度,对服务入侵较大,因此原地(in-place)更新也是 VPA 应用中各大厂商都会进行优化的部分。
History Storage 是一个存储组件(如 Prometheus),它使用来自 API Server 的利用率信息和 OOM(与推荐器相同的数据)并将其持久存储。Recommender 可以利用该组件在启动时初始化其状态。它可以由任意数据库支持。
Recommender 设计理念
VPA 控制容器的 Resource Requests 值(内存和 CPU)。在当前的可用版本中,它总是将 Limit 设置为无穷大。 目前 Request 值的计算是基于对同一组控制器下的所有 pod 中具有相同名称的容器的当前和先前运行的分析来计算的。
推荐模型 (MVP) 假设内存和 CPU 利用率是独立的随机变量,其分布等于过去 N 天观察到的变量(推荐值为 N=8 以捕获每周峰值)。未来更高级的模型可能会尝试检测趋势、周期性和其他与时间相关的模式。
对于 CPU,目标是将容器使用率超过请求的高百分比(例如 95%)时的时间部分保持在某个阈值(例如 1% 的时间)以下。在此模型中,“CPU 使用率”被定义为在短时间间隔内测量的平均使用率。测量间隔越短,针对尖峰、延迟敏感的工作负载的建议质量就越高。最小合理分辨率为 1/min,推荐为 1/sec。
对于内存,目标是将特定时间窗口内容器使用率超过请求的概率保持在某个阈值以下(例如,24 小时内低于 1%)。窗口必须很长(≥ 24 小时)以确保由 OOM 引起的驱逐不会明显影响 (a) 服务应用程序的可用性 (b) 批处理计算的进度(更高级的模型可以允许用户指定 SLO 来控制它)。
下文将针对 VPA Recommender 核心组件、功能扩展、性能调优、理论基础、业界应用等对该资源推荐组件进行深度解析。
2. Recommender 流程解读
Recommender 是 VPA 的主要组成部分。它负责计算推荐资源。在启动时,Recommender 从 History Storage 中获取所有 Pod 的历史资源利用率(无论它们是否使用 VPA)以及 Pod OOM 事件的历史记录。它聚合这些数据并将其保存在内存中。
在正常操作期间,Recommender 通过 Metrics Server 的 Metrics API 获取资源利用率和新事件的实时更新。此外,它还监视集群中的所有 Pod 和所有 VPA 对象。对于与某个 VPA 选择器(Label Selector)匹配的每个 Pod,推荐器计算推荐资源并在 VPA 对象上设置推荐。
一个 VPA 对象有一组推荐值(Recommendation),因此用户应该使用一个 VPA 来控制具有相似资源使用模式的 Pod,通常是一组副本或单个工作负载的分片,例如 Deployment\StatefulSet\DaemonSet 等。
2.1 主要流程
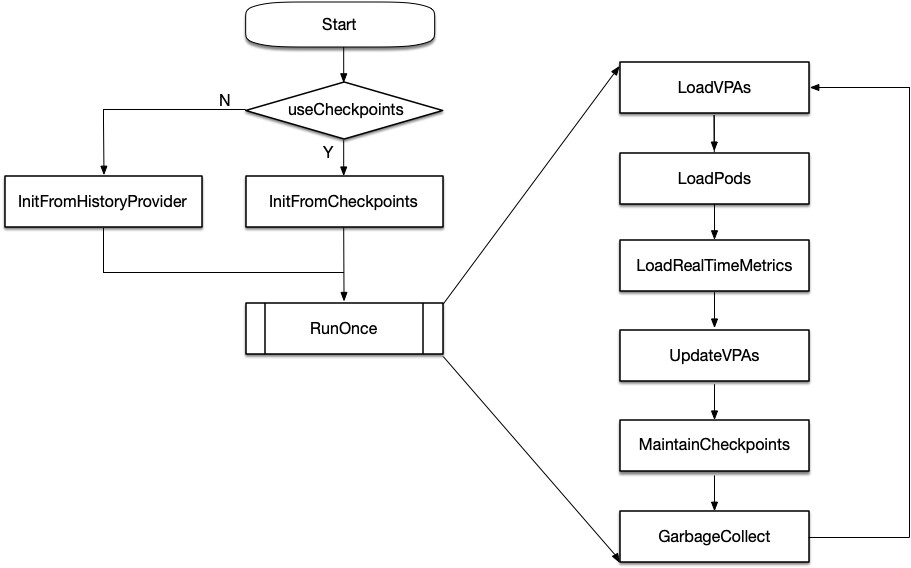
Recommender 启动时的数据来源:
一是 VPA checkpoint,借助 ClusterStateFeeder 接口的 InitFromCheckpoints 方法将历史的 VPA checkpoint 加载至内存。
二是 prometheus,需要配置 prometheus 采集 k8s metrics-server 上报的 cpu、memory 资源使用情况,再通过 prometheus client 借助 ClusterStateFeeder 接口的 InitFromHistoryProvider 方法加载至内存。除此之外,历史 Pod 的标签也需要从 prometheus 采集。
随后,Recommender 由一个定时器启动(默认周期为 1min),分别执行 RunOnce 与健康检查两个步骤。 其中我们主要关注 RunOnce 方法,在一个运行周期内,Recommender 分别执行了如下 6 个步骤:
LoadVPAs:将 VPA 对象加载至 ClusterState
LoadPods:LoadPods 将 Pods 对象加载至 ClusterState
LoadRealTimeMetrics:将 metrics server 聚合后的容器资源使用情况加载至 ClusterState
UpdateVPAs:以半衰指数直方图为输入,计算 cpu/memory 资源推荐值,并更新到 k8s 集群中 VPA 的 status 字段
MaintainCheckpoints:将推荐模型使用的半衰指数直方图备份至 VPA checkpoint
GarbageCollect:回收内存中无用数据,保证 Recommender 不占用过多的内存和 VPA 推荐值的新鲜度
2.2 核心数据结构 ClusterState
ClusterState 是 Recommender 核心数据结构,保存 kubernetes 集群所有与 Pod 垂直扩缩(VPA)相关的运行信息,例如 pods, containers, VPA 等资源对象,以及聚合后的资源使用率(如 CPU 和 memory)和事件(如容器 OOM)等。即 VPA Recommender 推荐算法的所有输入都保存在这个数据结构中。
type ClusterState struct { // 集群中所有Pod状态 Pods map[PodID]*PodState // 集群中所有VPA对象 Vpas map[VpaID]*Vpa // 集群中还未有推荐值的VPA,以及第一次观察到推荐值缺失或有相应warning日志记录的时间 EmptyVPAs map[VpaID]time.Time // 观察到的所有VPA,用以记录是否需要更新状态 ObservedVpas []*vpa_types.VerticalPodAutoscaler // 所有容器聚合后的aggregateContainerState存储位置 aggregateStateMap aggregateContainerStatesMap // 所有Pod和容器的label set集合,可作为recommender本地cache减少对API server 的压力 labelSetMap labelSetMap}涉及到的关键类图如下:
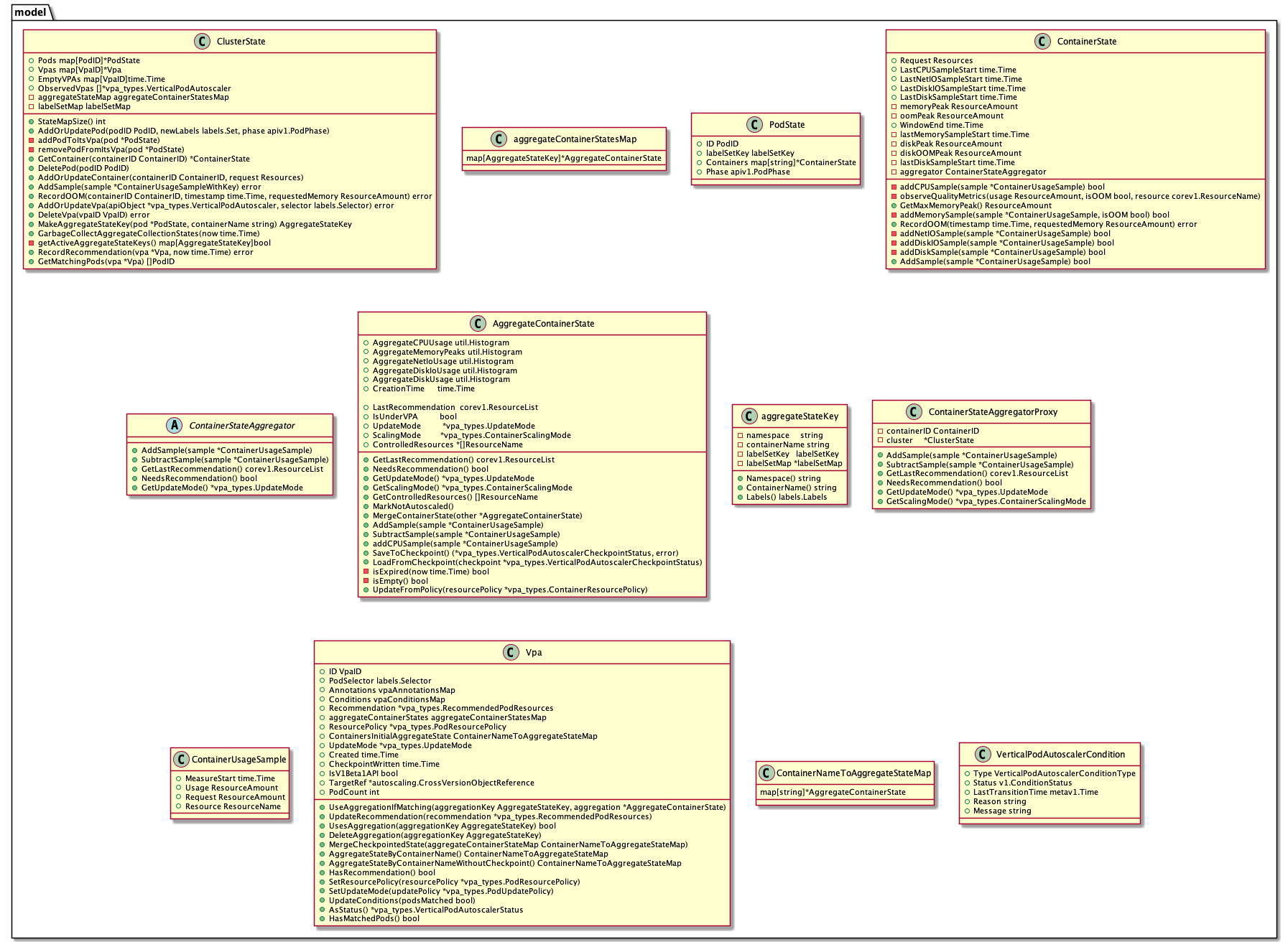
2.3 加载 VPA 与 Pods
(1) LoadVPAs
LoadVPAs 中 Recommender 将 VPA 对象加载至 ClusterState。
VPA 的 targetRef 记录 VPA 针对的 workload 类型、workload 名称以及 APIVersion。Recommender 需要获取对应 workload 的 ownerReference,判断相应 controller 是否为“顶层”controller。若不是,将不会为 VPA 计算推荐值。同时,Recommender 还需获取 workload 的 selector,作为 VPA 筛选 container 的 Selector,同时建立 Workload-Pod-Container 间的映射关系。
(2)LoadPods
LoadPods 将 Pods 对象加载至 ClusterState。Recommender 基于 client-go 初始化了一个 PodLister,每次 List 集群中全部 Pod,进一步获取所有 Pod 的 Spec 信息和 Labels。ClusterState 使用给定的 PodID 更新对应 Pod 状态。若某个 VPA 对象的 Selector 和 Pod Labels 匹配,则为对应的 VPA 和 pod、Container 建立关联。pod 的标签发生变化时,ClusterState 将会更新 VPA 和 Pod、Container 的关联。 需要注意的是,基于 Label 的映射方法无法避免多个 VPA 对象匹配了同一个 Pod。在实践中,我们在 kubernetes 集群中起了一个名为 workload-monitor 的定时任务,定期为集群中新增 workload 创建 VPA,回收 workload 不存在的 VPA,保证同一时间只有一个 VPA 对象匹配同一个 Pod。
2.4 加载实时指标数据
LoadRealTimeMetric 将 metrics server 聚合后的容器资源使用情况加载至 ClusterState,默认从 metrics server 获取容器资源使用监控数据。这和 HPA 控制器(Horizontal Pod Autoscaler)是一致的。
聚合后的容器资源使用率保存在 aggregateContainerStatesMap 这个结构体中,本质上是一个 key-value 结构的 Map。其中 Key 的接口方法定义如下
type AggregateStateKey interface { Namespace() string ContainerName() string Labels() labels.Labels}重要结构体:AggregateContainerState
VPA Recommender 以命名空间 ns、容器名 ContainerName、标签 labels 为 key,对采集到的容器资源使用率样本进行聚合。聚合后的数据结构为 AggregateContainerState,定义如下。同时,AggregateContainerState 也可作为计算资源推荐值的输入。
AggregateContainerState 使用半衰指数直方图统计容器对于 CPU 和 Memory 的资源使用分布。半衰指数直方图是 Recommender 推荐算法的核心。后续章节将针对此本部分进行详细解读。
OOM 处理
Recommender 通过 watch 机制监听集群中 Pod 驱逐事件。在发生 OOM(out of memory)事件时,Recommender 认为当前容器对 memory 资源实际需求是超出观测到的使用量的,利用下列公式估计容器对 memory 资源实际需求。方法是将 OOM 事件转换为内存使用样本来建模,将“安全边际”乘数 (“safety margin” multiplier ) 应用于最后一次观察到的使用情况,即选择 OOMMinBumpUp 和 OOMBumpUpRatio 计算后较大的结果,以避免 VPA 推荐值过小,从而造成容器反复 OOM。
$$memoryNeeded = max\left( {memoryUsed + 100MB,memoryUsed*1.2} \right)$$
2.5 更新 VPA
UpdateVPAs 中 Recommender 以半衰指数直方图为输入,计算 cpu/memory 资源推荐值,并更新到 VPA 的 status 中。
estimator
资源推荐值的计算逻辑部分是通过 estimator 实现的,ResourceEstimator 接口提供从 AggregateContainerState 计算推荐值的方法,默认条件下只考虑 CPU 和内存,如下所示:
type ResourceEstimator interface { GetResourceEstimation(s *model.AggregateContainerState) model.Resources}Recommender 提供如下数个 estimator,如 constEstimator,percentileEstimator, marginEstimator, minResourcesEstimator, confidenceMultiplier 等,通过匿名组合的方式组合多个 Estimator 实现复杂的计算逻辑。recommender 中各个 estimator 作用如下:
constEstimator 返回一个不可修改的固定值作为推荐值
percentileEstimator 根据提供的百分位数计算直方图的百分位数
marginEstimator 将推荐值乘以一个“安全边际系数”
minResourcesEstimator 通过设置一个全局最小值,以防止推荐值过小
confidenceMultiplier 基于 AggregateContainerState 第一个和最后一个数据样本间隔天数计算置信度指标
计算推荐值
百分位数 percentile 是将随机变量的概率分布范围分为几个等份的数值点。半衰指数直方图计算百分位数方法与普通直方图方法相同。例如,针对 VPA 推荐值的 lowerBound、target、upperBound,相应百分位数分别为 50%、90%、95%。以 CPU 为例,假设从 AggregateContainerState 中的半衰指数直方图计算出 90%分位数推荐值为 base90,50%分位数推荐值为 base50,95%分位数推荐值为 base95,相应 pod 内容器个数为 N,Recommender 最终给出的推荐值为:
$$Target = max\left( {base90*\left( {1 + safetyMarginFraction} \right),podMinCPUMillicores*0.001*1.0/N} \right)$$
$$Target = max\left( {base90*\left( {1 + safetyMarginFraction} \right),podMinCPUMillicores*0.001*1.0/N} \right)$$
$$LowerBound = max\left( {base50*\left( {1 + 1/history - length - in - days} \right),podMinCPUMillicores*0.001*1.0/N} \right)$$
$$UpperBound = max(base95*\left( {1 + 0.001/history - length - in - days{)^ - }2,podMinCPUMillicores*0.001*1.0/N} \right)$$
针对 Target、LowerBound、UpperBound,根据 VPA 为每个容器指定 ContainerResourcePolicy 进一步处理,防止推荐值过大或过小。
VPA 为每个容器定义了 ContainerResourcePolicy,用以控制容器垂直伸缩模式、资源推荐值允许的最大和最小范围、可调整的资源等,定义如下所示:
type ContainerResourcePolicy struct { // 容器名称 ContainerName string `json:"containerName,omitempty" protobuf:"bytes,1,opt,name=containerName"` // 是否垂直伸缩,包括Auto和Off两种 Mode *ContainerScalingMode `json:"mode,omitempty" protobuf:"bytes,2,opt,name=mode"` // 资源推荐允许的最小值 MinAllowed v1.ResourceList `json:"minAllowed,omitempty" protobuf:"bytes,3,rep,name=minAllowed,casttype=ResourceList,castkey=ResourceName"` // 资源推荐允许的最大值 MaxAllowed v1.ResourceList `json:"maxAllowed,omitempty" protobuf:"bytes,4,rep,name=maxAllowed,casttype=ResourceList,castkey=ResourceName"` // 指定VPA可控制容器哪些资源,默认为CPU和Memory ControlledResources *[]v1.ResourceName `json:"controlledResources,omitempty" patchStrategy:"merge" protobuf:"bytes,5,rep,name=controlledResources"` // 指定VPA可对哪些值做垂直伸缩,包括RequestsAndLimits和RequestsOnly,默认为RequestsAndLimits ControlledValues *ContainerControlledValues `json:"controlledValues,omitempty" protobuf:"bytes,6,rep,name=controlledValues"`}2.6 更新检查点与垃圾回收
(1) MaintainCheckpoints 维护检查点
RunOnce 第五步为 MaintainCheckpoints,即维护集群中 VPA 检查点
func (r *recommender) MaintainCheckpoints(ctx context.Context, minCheckpointsPerRun int) { now := time.Now() if r.useCheckpoints { if err := r.checkpointWriter.StoreCheckpoints(ctx, now, minCheckpointsPerRun); err != nil { klog.Warningf("Failed to store checkpoints. Reason: %+v", err) } if time.Now().Sub(r.lastCheckpointGC) > r.checkpointsGCInterval { r.lastCheckpointGC = now r.clusterStateFeeder.GarbageCollectCheckpoints() } }}recommender 使用的半衰指数直方图支持保存和载入 checkpoint,如 referenceTimestamp、每个 bucket 的权重,总权重等。同时保存为相应的 k8s VerticalPodAutoscalerCheckpoint CRD 资源对象。 Recommder 定期将 CheckPoint(检查点)写入 k8s API server,同时回收已失效的旧 CheckPoint。如果有非常多的 CheckPoint 需要写入,MaintainCheckpoints 每次保证至少默认写入 10 个。在不超时前提下(1min),MaintainCheckpoints 尽可能写入更多的 CheckPoint,直到所有的 CheckPoint 都被写入或更新。同时,MaintainCheckpoints 同时会删除 kubernetes 集群中没有匹配任何 VPA 的 Checkpoint。
(2) GarbageCollect
RunOnce 中最后一个步骤为 GarbageCollect,这一步中 recommender 尝试回收内存中无用数据,如下。
func (r *recommender) GarbageCollect() { gcTime := time.Now() if gcTime.Sub(r.lastAggregateContainerStateGC) > AggregateContainerStateGCInterval { r.clusterState.GarbageCollectAggregateCollectionStates(gcTime) r.lastAggregateContainerStateGC = gcTime }}ClusterState 同时支持 GarbageCollect,移除过期的 AggregateContainerState,以保证 Recommender 不占用过多的内存和 VPA 推荐值的新鲜度。判断 AggregateContainerState 是否过期的依据如下:
AggregateContainerState 中没有数据样本且没有活跃的 Pod 能够贡献 cpu/memory 资源使用样本
AggregateContainerState 中上一个数据样本太老(默认为 8 天前)无法给出有意义的资源推荐值
AggregateContainerState 中没有数据样本且创建于 8 天前
满足上述任意一条,相应的 AggregateContainerState 将被移除。
3. 滑动窗口与半衰指数直方图
3.1 滑动窗口模型在 VPA Recommender 中的应用
(1)直方图
Recommender 的资源推荐算法主要受 Google moving window 推荐器的启发,假设 CPU 和 Memory 消耗是独立的随机变量,其分布等于过去 N 天观察到的变量分布(推荐值为 N=8 以捕获每周业务容器峰值)。Recommender 组件获取资源消耗实时数据,存到相应资源对象 CheckPoint 中。CheckPoint CRD 资源本质上是一个直方图。根据直方图分布比计算容器资源推荐值,使 CPU 和 Memory 资源消耗量低于该推荐值的部分占总体时间的比重保持在某个阈值以上。
Recommender 中直方图定义如下:
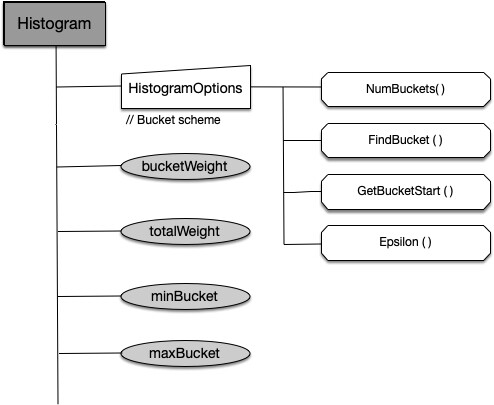
在 pkg/recommender/util/histogram.go 中定义了直方图统一对外提供的接口,如下所示:
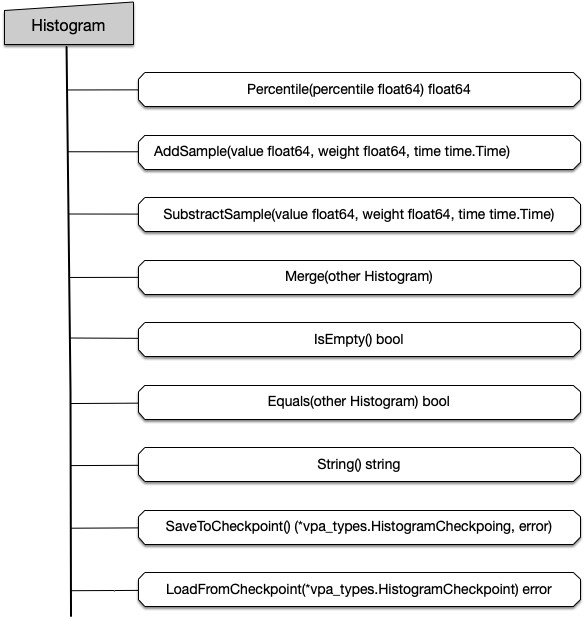
(2) 指数直方图
指数直方图中每个桶的大小以指数速率逐步提升,假设首个桶大小为 firstBucketSize,第 n 个桶大小计算方式为:
$$firstBucketSize*\left( {1 + ratio + rati{o^2} + ... + rati{o^(}n - 1} \right)) = firstBucketSize*\left( {rati{o^n} - 1} \right)/\left( {ratio - 1} \right)numBucket = int\left( {math.Ceil\left( {log\left( {ratio,maxValue*\left( {ratio - 1} \right)/firstBucketSize + 1} \right)} \right)} \right) + 1$$
以 CPU/Memory 为例,Recommender 中指数直方图表示范围如下:
(3) 半衰期和权重系数
半衰指数直方图在上述基础上增加了半衰期和样本“年龄”的参考时间,定义如下:
type decayingHistogram struct { histogram // 半衰期. halfLife time.Duration // 决定样本相对”年龄“的参考时间,总是半衰期的倍数. referenceTimestamp time.Time}Recommender 从 metrics server 或 prometheus 中获取带权重的样本数据,如 container 维度的 CPU、Memory 资源使用等。为每个样本数据权重乘上指数2^((sampleTime - referenceTimestamp) / halfLife),以保证较新的样本被赋予更高的权重,而较老的样本随时间推移权重逐步衰减。默认情况下,每 24h 为一个半衰期,即每经过 24h,直方图中所有样本的权重(重要性)衰减为原来的一半。
由于直方图中数据样本只有相对权重更为重要,因此样本“年龄”的参考时间可以随时调整。事实上,当指数过大时,referenceTimestamp 就需要向前调整,以避免浮点乘法计算时向上溢出。
针对 CPU 和 Memory 资源使用数据,AggregateContainerState 实现了不同的处理逻辑。例如向半衰指数直方图导入数据时,CPU 使用量样本对应的权重是基于容器 CPU request 值确定的。当 CPU request 增加时,对应的权重也随之增加。旧的样本数据权重将相对减少,有助于推荐模型快速应对 CPU 使用“尖刺”问题,减缓 CPU“饥饿等待”几率。而 Memory 使用量样本对应的权重固定为 1.0。由于内存为不可压缩资源,Recommender 划分了 memory 使用量统计窗口,默认为 24h。在当前窗口内只关注资源使用量峰值,添加到对应的半衰指数直方图中。同时这也表示,针对 memory 每 24h Recommender 中只保存一个采样点。
3.2 场景延伸:不同半衰期对推荐值的影响
在 VPA Recommender CPU 和 Memory 推荐模型中,半衰期设置会严重影响到容器预测指标与真实指标的拟合度,例如半衰期设置较长可能导致指标预测值偏向于平直,这种情况更倾向于反应容器长周期的资源利用率情况,半衰期设置较短可能导致指标预测值偏向于波峰波谷明显,这种情况更倾向于反应容器短周期的资源利用率情况。总结来说,不同长度的半衰期配置适用于不同的场景:
半衰期较长的指标预测比较适合私用云场景下的用户资源申请量推荐、动态调度、垂直伸缩等场景,这些场景的特点是基于指标预测值完成一次决策后应用负载在较长时间内保持稳定;
半衰期较短的指标预测比较适合私用云场景下的在离线混部等场景,这些场景的特点是系统对应用负载指标数据的波峰波谷比较敏感,期望通过削峰填谷来实现降本增效;
短半衰期引入的问题:
原生的 Vpa Recommender 在部署时是一个中心单体结构,它会对集群中全量的 pod 进行指标预测,并更新至 vpa status 资源中。半衰期长度的设置可能诱发性能瓶颈,例如较短的半衰期设置会导致短周期内大量 vpa status 状态的变更,这些变更会更新至 etcd 中,此时有可能会给 apiserver 和 etcd 带来较大的压力。
指标预测值拟合有以下设计要点:
在实践中,我们采取以下措施缓解半衰期长度设置带来的性能问题:
拉长 VPA Recommender 执行周期(recommender-interval);
限制 VPA Recommender 的 qps(kube-api-qps);
4. Recommender 实践
4.1 指标扩展
作为私有云的 kubernetes 团队,在实际的 kubernetes 集群资源管控与运营过程中,除了 CPU 和 Memory 之外,我们也会对容器的磁盘 IO、网络 IO 等指标有较多的关注,在内部自研的资源调度与运营组件中基于容器多种维度的指标进行指标决策。一般意义上,容器原始的监控指标表现出较强的抖动特征,难以为我们需要的指标决策提供直接的能力支持,VPA Recommender 的特色的 CPU 和 Memory 资源预测能力为这种场景提供了一个可选项,我们可以方便地基于 VPA Recommender 进行扩展,实现磁盘 IO 和网络 IO 等资源利用情况的预测。
原生 Recommender 采用 metrics server 采用监控数据源,实际资源推荐也只能仅限于 cpu 和 memory,扩展性不高。 我们使用 prometheus 替代 metrics server 作为监控数据源,既包括 cAdvisor 提供的 cpu/memory resource 监控数据,也可以灵活的添加一些 extended resource 使用指标监控,如 ephemeral-storage、hostPath,或 Disk I/O、Net I/O 等。
下面将以上文介绍的指数直方图添加指标与指标配置两个重要流程进行介绍我们是对复杂指标进行扩展的。
流程一:添加指标
VPA Recommender 对 CPU 和 Memory 资源的推荐目标有稍许差异:
对于 CPU, 目标是保证容器使用的 CPU 超过容器请求的 CPU 资源的高百分比(如 95%)时间低于某个特定的阈值(例如,保证只有 1%的时间内容器的 CPU 使用高于请求的 CPU 资源的 95%)。
对于内存,目标是保证在特定时间窗口内容器使用的内存超过容器请求的内存资源的概率低于某个阈值(例如,在 24 小时内低于 1%)。
关键问题:
在实际工程实现中,容器 CPU 指标数据加入指数直方图时的 bucket 权重基于容器的 CPU 申请量进行设置以快速应对 CPU 使用率尖刺问题,容器 Memory 指标数据加入指数直方图会综合考虑特定时间窗口内容器的 Memory 利用率峰值以降低 OOM 风险。对于磁盘 IO 和网络 IO 而言,kubernetes 系统未将它们作为可申请的资源类型来进行设计,且这些资源无需考虑诸如 OOM 之类的系统风险,因此这些指标数据加入指数直方图的流程设计与 CPU 和 Memory 会有稍许不同。
扩展指标数据加入指数直方图的流程设计有以下几个要点:
磁盘 IO 和网络 IO 等扩展指标数据从 prometheus 获取;
磁盘 IO 和网络 IO 等扩展指标类型定义于 apis types 中,其中磁盘 IO 和网络 IO 分别包含读 IO 和写 IO 类型;
磁盘 IO 和网络 IO 等扩展指标加入指数直方图时的 bucket 权重设置与 Memory 设置相同,同为 1;
与 CPU 类似,磁盘 IO 和网络 IO 等扩展指标的 lastSampleStart、firstSampleStart、totalSamplesCount 信息同样对置信度计算有较大影响,我们使用字典保存这些信息;
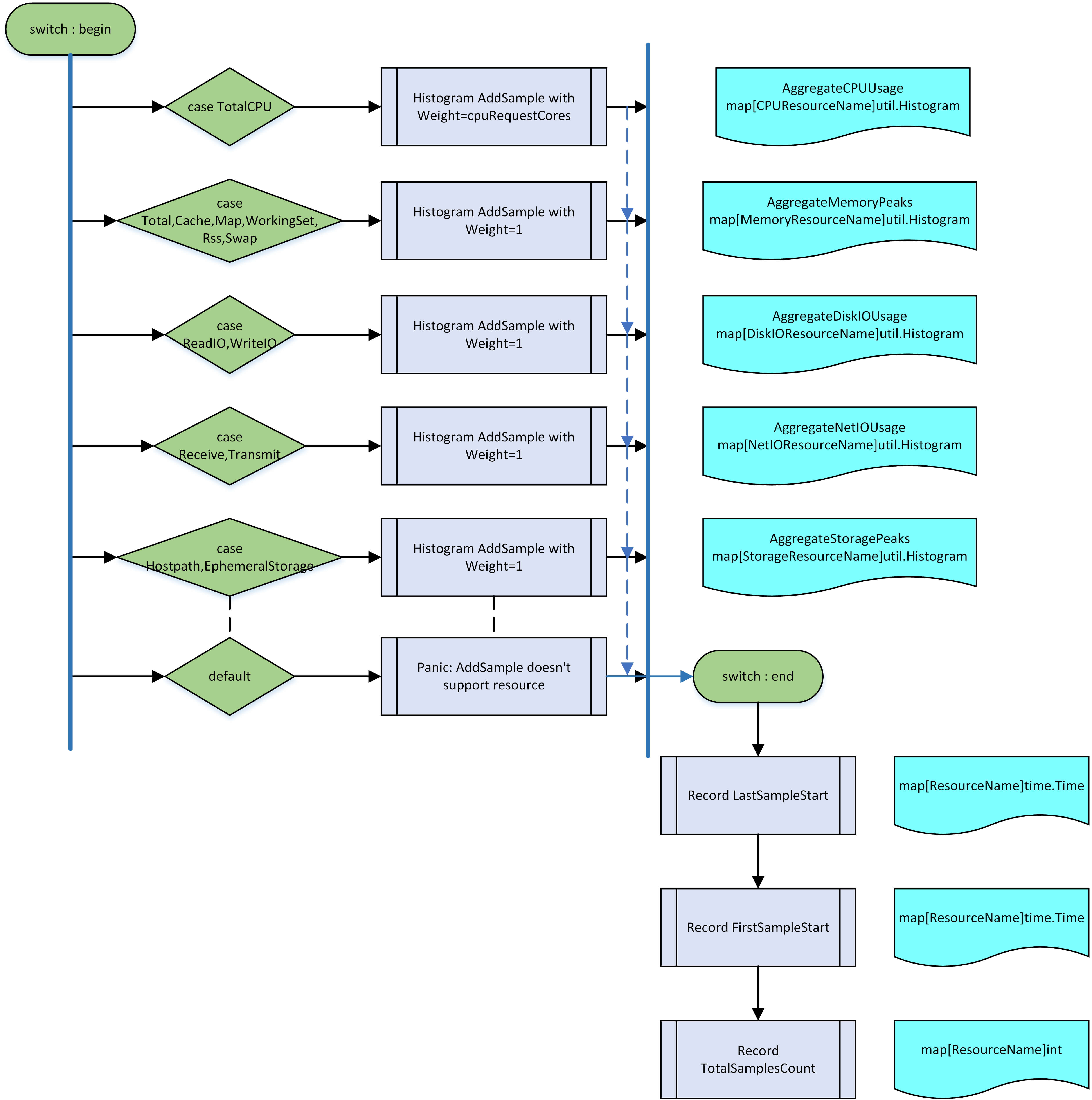
流程二:指标配置
关键问题:
VPA Recommender 的推荐模型将 CPU 和 Memory 作为独立的随机变量进行考虑,它们的分布等于在过去 N 天中观察到的分布。在进行指标扩展时,我们同样将磁盘 IO 和网络 IO 等扩展指标作为独立的随机变量进行考虑。
与 VPA 原生的 CPU 和 Memory 指标不同,磁盘 IO 和网络 IO 等扩展指标往往分属于不同的指标维度,不同的指标维度下又有不同的具体指标,而且不同的指标维度之间有较大的差异,相同的指标维度之内有较强的相关性,因此在模型设计上我们倾向于以下原则:
单个扩展指标维度内的具体指标使用相同的配置项。
直方图配置项有以下几个要点:
直方图配置项中新增额外的磁盘 IO 和网络 IO 等扩展指标项配置信息,如半衰期等;
直方图配置项中新增的扩展指标项信息以指标维度为单位进行设置,后续扩展指标预测时不同的指标维度下的具体指标使用指定的指标维度的配置项,下图中 apa 为我们扩展 VPA 后的自定义资源(k8s crd)名称。

4.2 性能优化
优化一:冷启动内存占用问题
在实践中我们发现,Recommender 冷启动时需从 prometheus 加载历史资源使用监控数据,往往短时间内需要占用过多的内存。分析后发现,Recommender 默认加载 8 天的监控数据,耗时较长。历史监控数据 ClusterHistory 经聚合后以半衰指数直方图形式保存在 ClusterState 数据结构中,无用内存被 golang 垃圾回收机制回收,此时内存占用才会恢复至正常值。 在 10000+容器的 kubernetes 集群中,内存占用峰值为数十 GB。此外由于经常发生超时错误重试,冷启动时间至少需要 40~50 分钟左右。
我们优化了这部分逻辑,按时间进行切片采集 prometheus 监控数据(默认每次加载 12h 的监控数据),聚合后依次保存在直方图中。这里我们未采用并行方式的原因有二:一是 Recommender 的半衰指数直方图并非并发安全的;二是我们不希望给集群的 prometheus 带来太大的并发压力。但调整后仍能观察到一些性能提升,其中 Recommender 内存占用峰值降为数 GB。通过缓解查询 prometheus 超时重试现象,冷启动时间缩短为 10~15 分钟左右。
优化二:VPA 更新性能瓶颈
对于某些负载较为稳定的服务,VPA 推荐值并非在每个 RunOnce 周期都需要更新。在原生实现中,判断 VPA 是否需要更新依据是前后两次推荐值是否完全相等。
由于 VPA 推荐值针对 CPU 单位为毫核(即为 CPU core 的 1/1000),而针对 Memory 单位为 byte。根据推荐模型计算公式,每次 RunOnce 周期内推荐值基本不可能完全相等,结果是 kubernetes 集群内每个 VPA 对象在每个 recommender RunOnce 周期内都需要更新,在大规模集群中将会给 API server 造成比较大的压力。在我们测试场景下,千级别负载,每轮至少更新百余+vpa,在默认的更新周期内(1 分钟),原生 Recommender 无法完成全部 vpa 的更新,此种情况导致大量 vpa 更新累积,进而影响加载最新 Metrics 的频率,最终导致 vpa 推荐值无法实时更新。
针对上述情况,我们增大了 VPA 的更新粒度,若相邻两个周期内推荐值 diff 在 CPU 0.1core 或 Memory 100MB 以上,才会去更新相应的 VPA。同时不改变原始 Recommender 计算的推荐值。在我们测试场景下,千级别负载,每轮更新 vpa 的值由百降低至几十/十几,得到了数量级的降低,在默认的更新周期内(1 分钟)可以正常完成更新,保证了 vpa 推荐值的准确性。
优化三:非原生负载资源缓存问题
针对 k8s 原生 workload 例如 DaemonSet, Deployment, ReplicaSet, StatefulSet, ReplicationController, Job, CronJob 等,Recommender 内置并在启动时初始化相应的 client-go informer。而针对非 k8s 原生的自定义 workload,需要直接从 API Server 处获取,这在大规模 kubernete 集群中给 API Server 非常大的压力。社区通过给自定义 workload 资源增加一种 scale 子资源,同时增加相应 controllerFetcher 和 controllerCache 解决这个问题。
VPA 检查点垃圾回收问题导致 VPA 中存储过期数据
此外,我们还发现虽然在 MaintainCheckpoints 步骤中,会删除 kubernetes 集群中没有匹配任何 VPA 的 Checkpoint。 但原生 Recommender 不会删除 VPA 存在但对应 container 不存在的 Checkpoint。
用户重新发布 workload 存在删除现有 container 的可能性,我们修复了相关逻辑,回收了该部分实际已不存在的容器, 防止部分 Checkpoint 既脱离了 Recommender 管理,也无法删除的情况(该情况最终会导致 VPA 中显示了已经被删除了的 container 信息),提升了 VPA 的可用性。
5. 业界应用
Autopilot
Autopilot 是 Google 在内部云上的自动缩放工具。Google 使用 Autopilot 自动配置资源,同时调整作业中的并发任务数(水平缩放)和单个任务的 CPU/内存限制(垂直缩放)。提升资源利用率,同时保证服务质量。
Autopilot 主要使用两种算法用于垂直伸缩:第一种依赖于历史用量的指数平滑滑动窗口;第二种基于从强化学习借用的算法,从多个滑动窗口算法中为每个任务选择历史数据表现最佳的算法。本质上说,Autopilot 的算法是基于滑动时间窗口的。这和 VPA Recommender 推荐算法也是相似的。
Autopilot 使用 5 分钟作为一个滑动窗口,每个滑动窗口内使用直方图记录任务的资源使用。对于 CPU 每 1 秒包含一个使用样本数据。而对于 memory,Autopilot 仅关注 5 分钟窗口内的使用峰值,以减少 OOM。这个 Recommender 推荐算法是相似的。不同之处在于,VPA Recommender 每 1 分钟从 metrics server 获取一次 cpu/memory 的样本数据,且对于 memory 的统计时间窗口为 24h,即仅关注 24h 内的使用峰值。
为实现推荐值随着资源使用量的增加而迅速增加,但在使用量减少后缓慢减少,以避免对任务负载暂时下降时的过快响应。Autopilot 使用指数衰减权重对资源使用样本进行加权。每个样本数据权重等于负载 b[k],即样本落在直方图的第 k 个 bin 的值(边界值)。这和 VPA Recommender 稍有不同(recommender 中样本的权重等于对应资源如 cpu/memory 的 request 值)。但都能达到对负载尖峰平滑响应的效果。
此外,Autopilot 使用的半衰指数直方图,CPU 的权重半衰期为 12 小时,memory 的权重半衰期为 48 小时。这和 VPA Recommender 推荐算法也是相似的,但 VPA Recommender 对于 cpu/memory 的半衰期默认为 8 天。
Autopilot 根据半衰指数直方图的百分位数 Pj 计算推荐值,这和 VPA Recommender 也是相同的。对于 CPU,不同类型作业的百分位数如下:
批处理作业:50%,认为批处理作业可以承受一定的 CPU 压制而正常运行
服务作业:根据负载对延迟的敏感度分别为 95%或 90% 对于内存,Autopilot 根据作业对 OOM 的容忍度使用不同的百分位数,划分为中等、低、最低三个类型,如下:
50%或 60%适用于 OOM 容错中等的作业
98%适用于 OOM 容错低的作业
100%适用于 OOM 容错最低的作业
而在 VPA Recommender 中,推荐值分为 UpperBound、Target、LowerBound,对应半衰指数直方图的百分位数分别为 95%、90%、50%。VPA 根据 lowerBound 和 upperBound 决定 pod 是否需要被更新。若 pod 资源请求低于 lowerBound 或者高于 upperBound,VPA 驱逐该 pod 并通过 Admission Controller 修改它的 request 为 target 推荐值。
VPA 在云厂商中的应用
由于 k8s VPA 当前版仍不支持原地更新,对业务入侵较大。在实际工业界应用中,各大容器云厂商针对 VPA 的优化主要集中在 pod request 值热更新这个方向,涉及的技术包括但不限于负载(Deployment/Statefulset 等)维度资源 request 热更新、节点维度 Kubelet 资源限制(Cgroup 等)热更新等,例如阿里云、腾讯云内部都有相应的应用。由于本篇文章主要关注点在 VPA 资源预测组件,相关技术不在本文介绍范围内,在此不赘述。
此外,针对 VPA Recommender 组件,也有利用滑动窗口模型,复用该组件以实现短周期资源预测功能。如腾讯云中的在离线混部组件 Caelus,就有在已有 pod 和容器资源使用画像基础上,借助 VPA 推荐算法,增加节点资源使用画像。即对每个节点上所有在线业务的实际资源使用量进行预测,同时动态调整上报的扩展资源数量,该部分扩展资源将提供给混部的离线业务使用。
作者介绍:
王丽婧 搜狗资深高级开发工程师,主要关注领域为云原生场景下的资源管理。
程振京 搜狗开发工程师,主要关注领域为云原生场景下的调度、GPU 管理 。
刘云飞 搜狗开发工程师,主要关注领域为云原生场景下的调度、存储。
刘建 搜狗资深架构师,搜狗容器云平台负责人,目前主要关注领域为云原生。




