
Anthropic 发布了一份工程事故复盘报告,针对六周以来用户反馈的 Claude Code 相关投诉作出情况说明。
用户反馈的症状差异极大,具体取决于他们使用 Claude Code 的时段和功能。究其原因,2026 年 3 月至 4 月期间,三个互不相关的产品层变更陆续上线,每个变更都按照各自的时间表影响了不同的流量切片。API 接口与底层模型权重均未受到影响。截至 4 月 20 日(v2.1.116),这三个问题已全部修复,Anthropic 也已为所有订阅用户重置了使用额度。
第一个是推理强度降级。3 月 4 日,Anthropic 将 Claude Code 的默认推理强度从高等级调整为中等等级,以此解决长时间思考期间界面卡顿的问题。官方坦言这是一次“错误的权衡”。不少用户反馈 Claude Code 智能表现有所下降,即便界面优化后强度设置选项更加醒目,但多数用户依旧沿用中等默认档位。这个改动已于 4 月 7 日回滚,目前所有模型默认启用高等级或极高等级推理强度。
第二个是一个缓存漏洞,该问题会逐步清空模型自身的推理过程。3 月 26 日,Anthropic 上线了一项优化功能,用于清理闲置时长超一小时的思考片段,这类会话原本就会出现完全缓存未命中的情况。但一处漏洞导致清除操作在会话剩余时间内的每一轮都触发,而非仅触发一次。Claude 虽能正常继续运行,却会逐渐遗忘自身选用当前处理方式的缘由。
Claude Code 团队的 Boris Cherny 在 Hacker News 上解释,极端情况下,若用户上下文包含 90 万词元且会话闲置一小时,发送下一条消息时会出现完全缓存未命中,消耗大量速率限制额度,对 Pro 用户影响尤为明显。他们为降低这一成本而推出的修复方案正是引入该漏洞的直接原因。该问题已于 4 月 10 日修复。
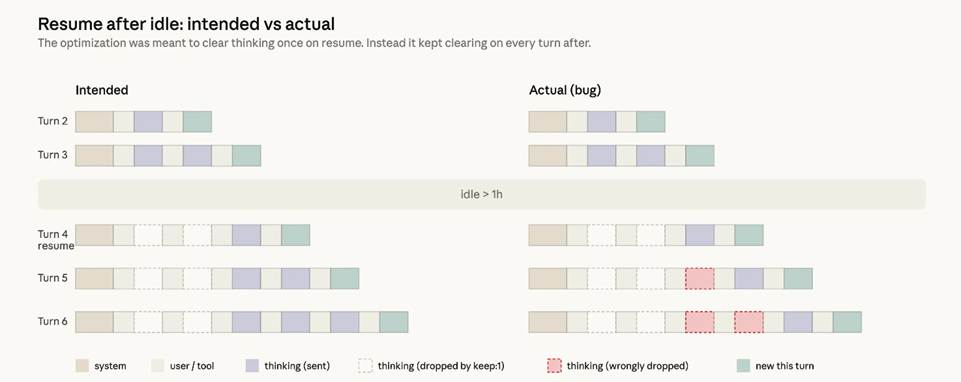
(该缓存漏洞会在每轮交互后清除 Claude 的推理历史,而非仅清除一次。来源:Anthropic 博客文章)
第三个问题是 4 月 16 日随 Opus 4.7 同步上线的系统提示词调整。Anthropic 新增了字数限制规则,要求模型将工具调用间隔的文本控制在 25 词以内,同时把最终回复控制在 100 词以内。这个改动历经数周内部测试,未发现功能异常后正式发布。后续开展的大范围对照实验显示,Opus 4.6 与 4.7 版本的整体输出质量均下降 3%,此次调整已于 4 月 20 日回滚。
调查得出了一项关于 AI 辅助调试的有趣发现。Anthropic 使用自家代码审查工具对引发故障的拉取请求进行了回溯测试。在提供充足代码库上下文信息的情况下,Opus 4.7 成功发现了缓存漏洞,而 Opus 4.6 却未能识别。目前官方正为代码审查工具增加对额外仓库上下文的支持,以防同类问题再次发生。
Hacker News 相关讨论帖依旧热度高涨。部分网友称赞 Anthropic 发布了详尽的事故复盘报告,也有不少人对其背后的根本初衷持质疑态度。一位评论者质疑清理闲置会话上下文是否真的只是为了延迟降低:
无非只有两种可能:要么他们确实认为对于已经长时间闲置的会话,牺牲输出质量来降低延迟是值得的;要么实际情况是他们想最大限度压缩闲置会话的使用成本,而“降低延迟”不过是一个顺理成章的借口。
还有人指出系统提示词调整在对外沟通层面存在问题:
先用旧版系统提示词得出基准测试结果,又在用户毫不知情的前提下改动提示词,这种做法难免让人觉得存在欺骗性。官方至少应当告知用户系统提示词已做出调整。
《财富》杂志的报道指出,部分用户因 Anthropic 最初的回应刻意营造出一切并无异常的态度感觉遭到了情感误导。Anthropic 告诉《财富》杂志,“算力是整个行业的制约因素”,并表示正通过与亚马逊和谷歌扩大合作伙伴关系来扩展算力容量。
在 Reddit 平台上,有用户指出了一个复盘报告未提及的问题:子智能体向 Haiku 模型委派任务。Claude Code 比用户预想的更频繁地将任务委派给更便宜的 Haiku 模型,而该行为仅能在详细日志中查到。有评论者着重点明了这一做法在自动化工作流程中潜藏的风险:
在交互式使用场景中,质量下降是显而易见的,你还能中途及时纠正。但在自动化流水线中,它们要到执行完三个任务后才会暴露出来,排查难度更大。
对于在 CI 或自动化工作流中运行 Claude Code 的团队而言,暗中将任务委派给轻量模型是 Anthropic 此次查明的三个问题之外的另一类质量隐患。
另一位 Reddit 用户证实,即使在 Anthropic 宣布回滚后,字数限制相关指令仍保留在系统提示词中。该用户构建了一个前置工具钩子脚本,在每次 Write、Edit 和 Agent 工具调用前触发,以应对五种特定的故障模式。该用户解释道:
模型的系统提示词加上训练奖励造成了这五种故障模式:“简短凝练”导致跳过重读原始资料,“不要叙述思考过程”导致跳过能暴露不匹配情况的验证性叙述,在生成衍生内容前没有结构性重读关卡,读取工具的“不要重读”指导与这类问题场景完全相悖,以及训练强化“合理且自信”而非“与原始资料匹配”。
这个变通方案有效提升了输出质量,也印证了复盘报告里的判断:字数限制相关调整正是造成质量下将的原因。
这一普适性工程经验适用于所有围绕 AI 模型进行产品迭代优化的团队。Anthropic 此次内部评审与试用没能发现这三个问题,原因在于内部人员使用的版本与正式公开版存在差异,缓存漏洞仅会在老旧会话这类特定场景下触发,同时原有评测体系覆盖面不足,无法测出提示词调整造成的 3% 质量下降。对于后续的优化,Anthropic 提出多项整改举措:安排更多内部人员使用完全一致的公开正式版本,每次调整系统提示词都进行覆盖全模型的大范围评测,延长浸泡测试周期、采用灰度渐进式发布,同时对系统提示词的修改执行更严格的版本管控。
Stella Laurenzo 在 GitHub 上发布了一份独立审计报告,分析了 6852 个 Claude Code 会话文件、17871 个思考片段和 234760 次工具调用。她的发现,Claude 的工作模式正从优先查阅研究转变为优先直接编辑,推理深度出现明显可量化下滑。尽管这份报告里并非所有观点都能在官方复盘报告中得到证实,但其中指出的各类问题表现和 Anthropic 查明的三项诱因高度契合。
查看英文原文:https://www.infoq.com/news/2026/05/anthropic-claude-code-postmortem/




