
4 月 15 日-16 日,由 InfoQ 主办的 DIVE 全球基础软件创新大会通过云上展厅的形式成功召开。在腾讯云基础软件创新实践专场,来自腾讯云的大数据专家工程师于华丽带来了主题为《一份数据满足所有数据场景?腾讯云数据湖解决方案及 DLC 核心技术介绍》的演讲,以下为主要内容。
大家好,我是于华丽,来自腾讯大数据,很高兴跟大家一起探讨当前大数据最火的方向——数据湖。
我先抛出一个问题:有没有可能只有一份数据就满足所有大数据场景?我们带着这个问题以及对这个问题的疑问和各自心里的答案,开始今天的思想碰撞吧。
在分享前,我先做个简单的自我介绍。我叫于华丽,毕业于复旦大学数学系,拥有近十年的大数据和公有云结合经验,基于亚马逊云科技/阿里云/腾讯云/华为云打造云原生湖仓数据平台。2020 年加入腾讯,全面负责腾讯云数据湖产品 DLC 的内核架构研发。
今天主要和大家分享四部分内容:
首先是开篇提出的问题:有没有可能只有一份数据就满足所有大数据场景?
第二部分是腾讯云数据湖解决方案以及腾讯云数据湖产品 DLC 的技术内核。
第三部分是总结腾讯内部和客户对接过程中的新一代数仓建模思路。
第四部分是介绍 DLC 的应用案例。
只有一份数据就能满足所有大数据场景?
前面说了那么多,大家还记不记得我们最初提出的问题:一份数据能不能满足所有的大数据数据场景?
在回答这个问题之前,我们先了解下这个问题是怎么产生的。
DB 太卷了。数据库种类繁多,有 300 多种,AP 引擎更如雨后春笋,在如今的科技时代百家争鸣,包括 Hive/Spark/Presto/impala/ck/Doris 等等。
基于这个背景,我们做数据架构的时候就应该考虑很重要的一个原则——single source of truth,这个原则有几个好处:减少维护复杂度,防止数据一致性问题,节约成本。
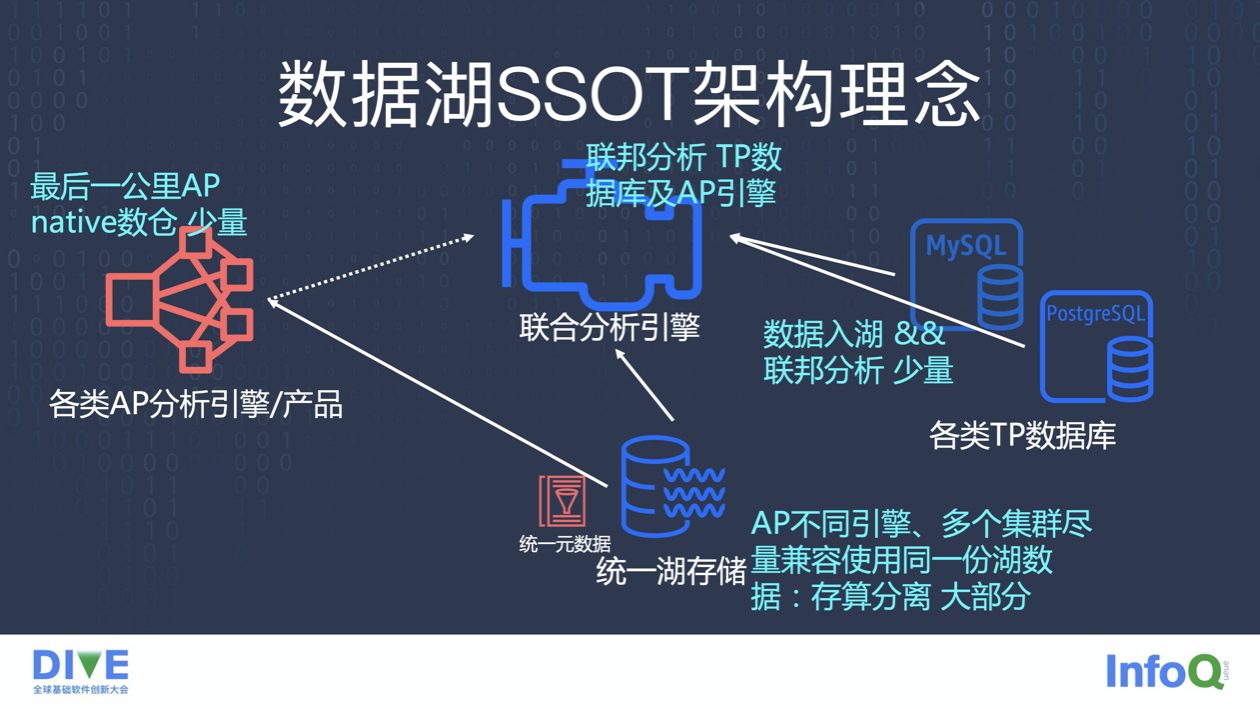
于是,我们提出了数据湖 SSOT 架构理念:
1、80%的湖数据,存算分离、不同 AP 引擎,不同集群尽量兼容、使用同一份湖数据
2、10% TP 数据库,量级不大不影响在线服务的情况下,直接联邦分析。海量、历史数据入湖。
3、10% 最后一公里的大宽表、结果数据可以考虑独立的仓存储,追求极致性能毫秒级分析。
4、数仓数据也要跟湖数据联动,数仓兼容湖数据,或者联邦分析。
在数据湖 SSOT 架构下,数据几乎可以做到 1 份数据满足几乎所有大数据分析场景。
腾讯云数据湖解决方案
基于数据湖 SSOT 架构理念,我们结合腾讯云的各个大数据产品,推出了腾讯云数据湖解决方案,来帮助落地数据湖架构。
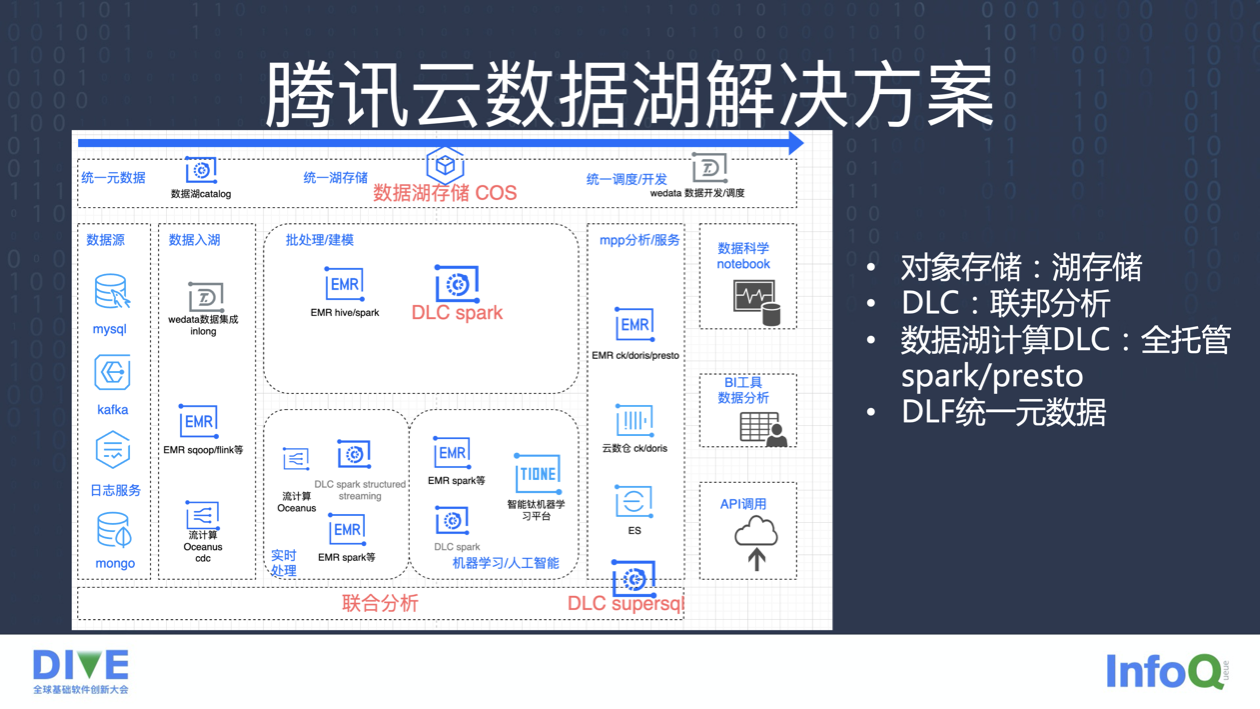
1、在批处理、实时处理、AI、mpp 分析各个主要场景下,各个引擎尽量用同一份数据湖数据,可以看到在不同场景下有各种不同的产品供选择,当然即使同一个产品也会有多个集群,传统架构下很难整合多个产品的优势建设功能覆盖完善的数据平台。
2、在追求毫秒级分析的场景下,大宽表、结果数据可以导入到 mpp 数仓 ClickHouse/Doris 完成最后一公里的分析。
3、TP 数据库、数仓数据、湖数据可以通过 DLC 联邦分析功能。
腾讯云 DLC 技术架构
接下来分享下,DLC 到底是什么,以及它的技术架构。
腾讯云 DLC 是 DataLake Compute 的缩写,它一方面充当数据湖解决方案的粘合剂,应用在湖管理、元数据管理、联邦计算;另一方面补充了云上全托管的产品形态,用户免运维、几乎不需要有大数据相关背景,就可以几分钟内快速构建数据湖架构。
DLC 技术架构,有两个底层架构理念:适应云原生、KISS 原则(Keep It Simple, Stupid)。适应云原生具体包括 eks/tke,元数据主存 tdsql,各个服务的多租户支持和隔离等等。KISS 体现在几个方面,presto local cache,dlc shuffle manager,统一语法模块等等。
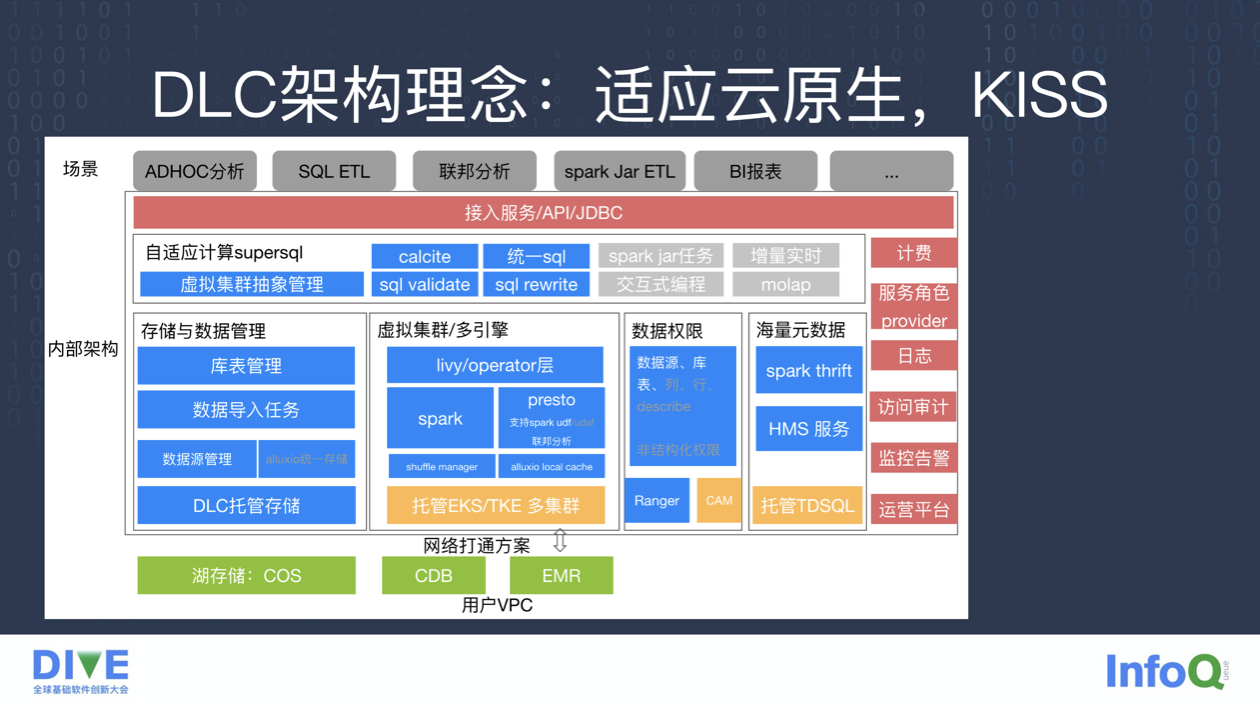
具体来看,我们在统一接入层服务提供云 API、JDBC、Hmsclient 等对外服务,SQL 入口是腾讯 SuperSQL 的统一 SQL 服务,进行了权限、validate 等操作,以及虚拟集群的管理和路由。
下面是 DLC 的数据管理、计算集群、数据权限和元数据管理。最后与用户 cos、cdb、emr 的数据打通。通过内核架构支持,SQL etl/mpp SQL 分析/联邦分析等场景,接下来逐步完成 Spark jar/AI 的迭代和升级。
稳定性、性能与成本
接下来,和大家分享下 DLC 的技术内核稳定性、性能相关技术,以及成本。
稳定性
稳定性相关技术优化主要分为三部分:Iceberg、弹性不稳定、DLC spark shuffle manager。
Iceberg:Iceberg 作为 table format 解决了对象存储最终一致性,导致的任务频繁失败问题。
弹性不稳定:弹性计算相对于传统固定集群带来很多问题,比如冷启动慢,hpa 过程中数据倾斜,甚至是资源不足的情况,我们在后面成本相关会仔细提到 DLC 的弹性模型。
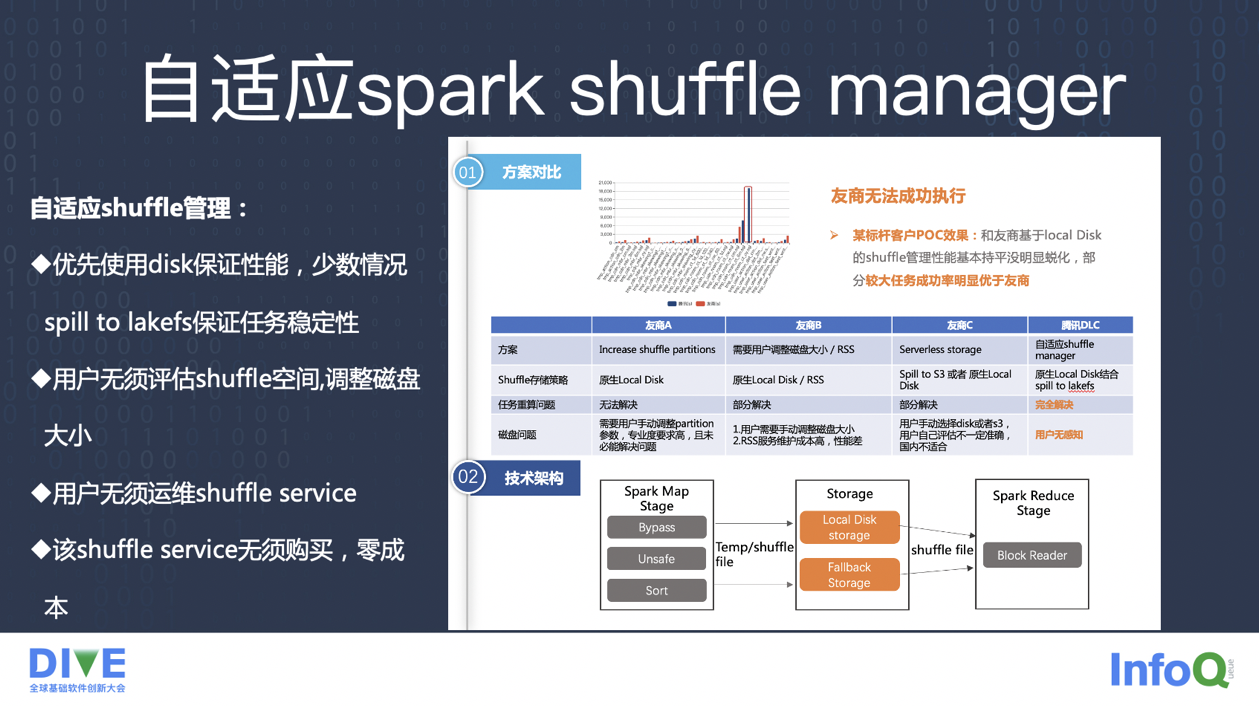
DLC spark shuffle manager:腾讯开源了 firestorm 来解决内部海量数据的 shuffle 问题,在 DLC 场景下,我们进行精简改造,推出了适应云原生场景下的 DLC spark shuffle manager。本质逻辑是保证大部分任务都能利用本地磁盘完成高性能的 shuffle,少数情况 spill to lakefs 保证任务稳定性。这样有几个好处,一是无需评估 shuffle 空间,调整磁盘大小,二是无需运维 shuffle service 及承担成本,三是无需购买,几乎零成本。
在这儿给喜欢钻研的同学留一个小问题:Spark 都有哪些过程会需要落磁盘呢?
性能
性能在提高人效方面日益重要,各个层出不穷的 AP 引擎也几乎主要在提升交互响应的性能。
DLC 在性能方面有很多架构技术方面的考量,先简单提几个点:Spark SQL 共享 Spark Context,Spark Thrift Server 问题的症结在于 Server 本身又是 Driver,因此稳定性存在很大问题,DLC 在这方面用的 livy+livy session 背后的 Spark Context 共享,在有一定并发情况下,又通过子集群来隔离。
在海量元数据的存储和 hms 响应性能提升方面,DLC 也有自己的考量,采用了腾讯云的 TDSQL/重新设计范式来满足海量元数据的响应性能。在 DLC 的托管存储表下,运用 iceberg hidden 。
性能相关第一个点就是通过提供 presto 加速 SQL + Hive/Spark udf 的分析性能:
因为常驻共享及 push based 内存 shuffle,presto 往往在小数据量下有着不错的表现。但是因为 presto 语法和 udf 与 hive/spark 的差异往往迁移试错成本很高,DLC 统一 SQL 语法,几乎还是 Spark/Hive 的语法,presto hive/spark udf wrapper。两个手段解决了 presto 的迁移问题,几乎对用户无感。
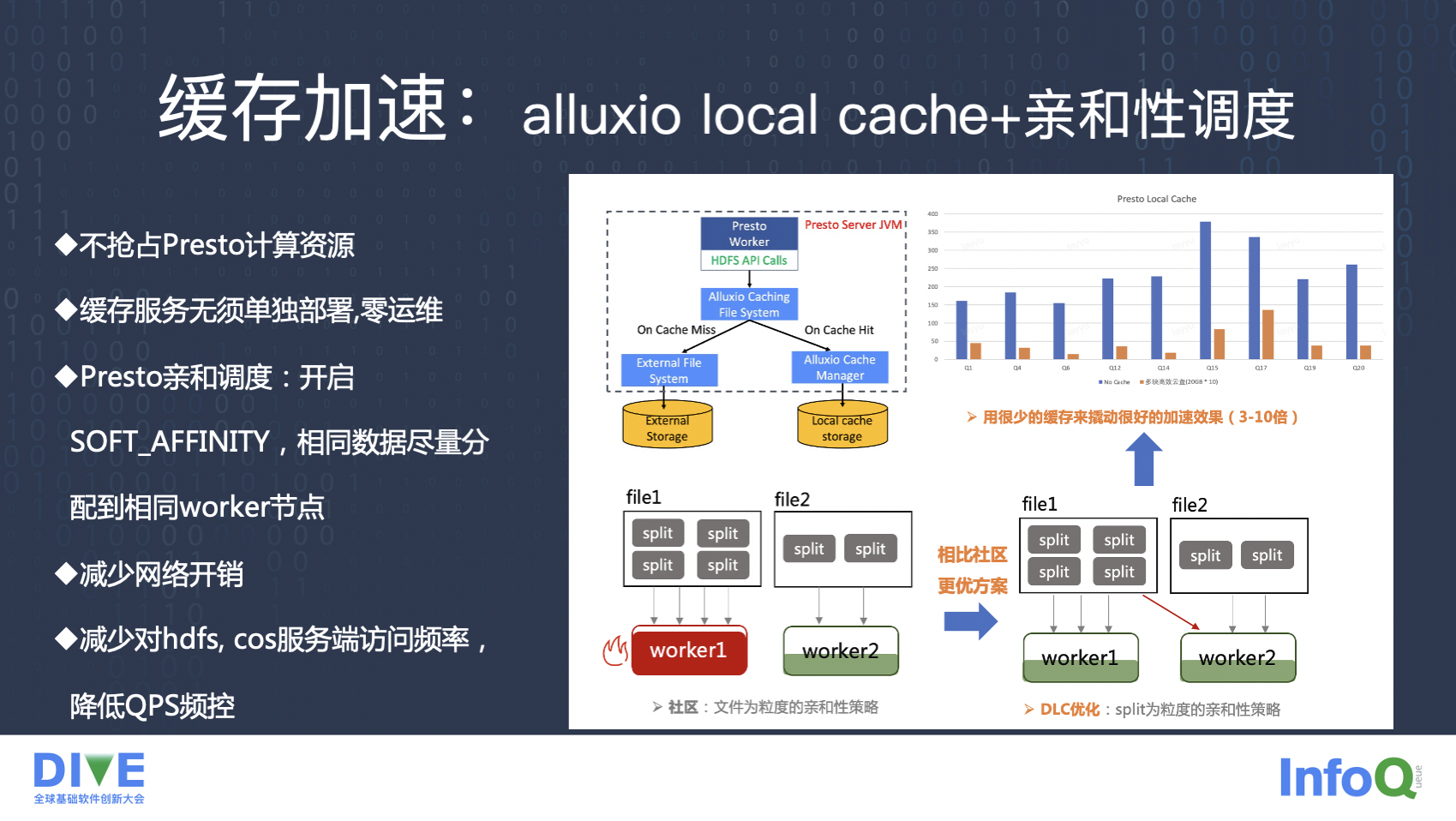
同时,Allxio 也是当下最热的数据湖加速技术,腾讯云也即将推出 Allxio 相关的产品。
在 DLC 侧,我们秉承了适应云原生和 KISS 的架构原则,上线了免运维、无需额外费用的 Allxio local cache。local cache 免去了 Allxio 服务的部署和维护,不抢占用户 presto 的计算资源。同时我们也有一些改进,hash 算法导致的数据倾斜,一致性 hash、split 级别的 hash 等等。
成本
首先我来讲下湖存储的优势,然后再介绍下 DLC 的虚拟集群弹性模型。
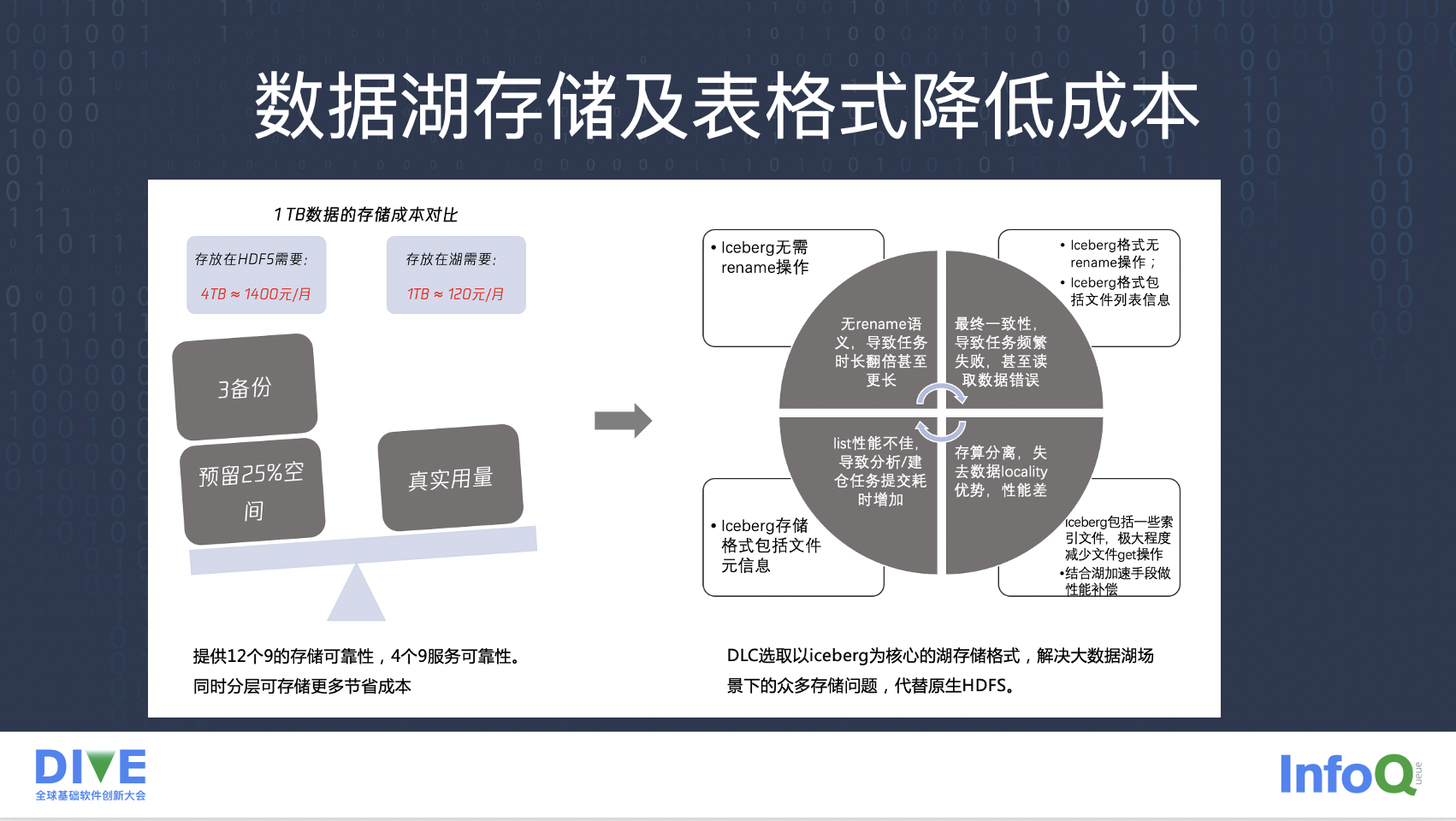
首先是存储成本。用对象存储作为湖存储相比 hdfs 来说,存储性价比得到了 10x 的提升:
1、hdfs 的三备份 vs cos 的 ec。
2、预留空间 vs 按量计费。
3、hdfs 的运维成本。
4、对象存储的归档和智能存储分层。
5、cos 作为存储产品提供的高 sla 和存储可靠性。
但是对象存储在降低成本的同时也带来了问题,比如对象存储没有 rename 语义等四个问题。采用 Iceberg 表格式来解决,相比直接 Hive 表,计算成本也得到了极大的降低
计算成本方面,重点介绍下 DLC 的虚拟集群弹性模型。

上图右侧的 Spark,交互式/SQL 都是类似的。我们以子集群为弹性的最小单位,保证子集群的资源整体可用情况下的弹性,子集群多个 query 共享 spark context。
这样带来的好处是:
能很好的降低延迟,减少拉机器,进程初始化,链接初始化的时间,提升性能。
子集群规模稳定,减少了频繁扩缩造成的任务稳定性差和弹性导致的数据倾斜。
能够提供不错的成本降低。
数据湖趋势下的数仓建模新思路
接下来,我们把数据湖在腾讯落地过程中总结出的数据建模也分享给大家。目标还是能够提升分析性能和降低存储计算成本。
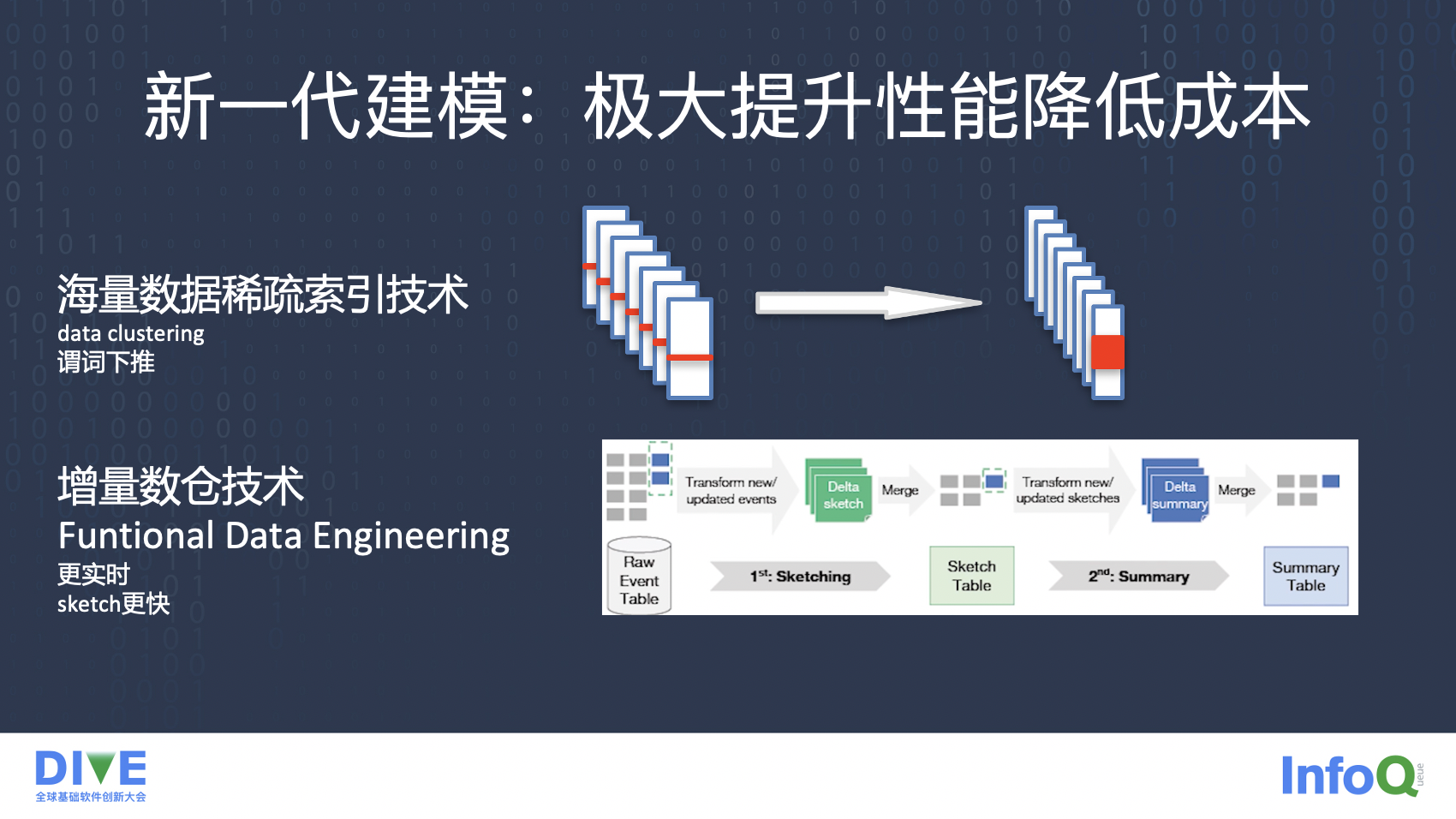
第一个是海量数据下的稀疏索引技术,如上图所示,构建大宽表或者 dwd 详情层,我们把高基维的相关数据的靠近存放,能够利用引擎的谓词下推技术大大加速分析性能,并且提高压缩比率降低存储成本,同时也可以减少单纯的主题层的数据抽取,更好应用 ssot 一份数据满足尽可能多的场景。
第二个是增量数仓技术:底层逻辑是 funtional data engineerging,也可以叫函数式数据工程,不再维护滚动表这类有状态的数仓建模障碍,而是把 uv 标量进行向量化,以空间换时间,在数据量不大的聚合计算层表有很好的效果,能够极大的提升数仓的构建性能和分析性能。
DLC 应用案例

这个是某电商直播平台基于 DLC 构建混合大数据架构,充分利用了 DLC 的 Spark 批处理和交互式分析,计算性能提升,成本节约,运维成本大幅度降低。
腾讯数据湖能力也在内部大规模落地,接入团队超过 80,其中微信视频号、小程序等业务均百亿千亿级别落地。同时我们拥有近百人的研发团队支持,其中大量的业界顶尖技术专家,包括了 spark livy alluxio 等开源项目的 PMC,presto/calcite committer,为 DLC 的稳定/高性能/易用/低成本保驾护航。
总结
最后总结下今天的分享,用三个词来总结:SSOT、KISS、新一代建模。
1、首先是 SSOT,如何做到一份数据尽可能满足所有场景,有三个原则。我们根据这三个原则提出了腾讯云上以 DLC 为核心的数据湖解决方案。
2、其次是 KISS,还记得我们留的一个思考问题吗,Spark 都会有哪些过程和场景需要数据落到磁盘呢?
3、最后是新一代建模:稀疏索引来解决 dwd 和大宽表的分析性能,增量数仓来改造聚合层的分析实时性和性能。
以上就是我今天的分享,谢谢大家。




