
最近,AI 聊天机器人“一本正经地胡说八道”的现象越来越常见。
有媒体监测到,截至今年 8 月,十大主流 AI 工具(包括 ChatGPT, Claude, Copilot 等)聊一些新闻话题时,错误率已飙到 35%。
也就是说,这些 AI 给出的看似有理有据的回答中,每三个里就有一个可能是错误的——该比例居然比去年同期还涨了一倍多。

上述结果,来自于 NewsGuard。随着 LLM(大语言模型)的爆火出圈,他们去年推出了一个“AI 虚假信息监测器”(下文简称“监测器”)功能。该监测器每个月都会实时追踪这些热门 AI,看它们到底是有所进步能识别假消息,还是仍在重复错误信息。
关于研究者和数据结果
NewsGuard 是一家新闻与信息网站的评级机构,通过浏览器扩展和移动端应用,为媒体透明度和可靠性打分,并提供虚假信息追踪等服务。
它由前《华尔街日报》出版人 L. Gordon Crovitz,和知名记者、媒体企业家 Steven Brill,于 2018 年共同创立。
至于如何得出 AI“错误率”数据——
简单来说,NewsGuard 搭了一个“AI 答题比赛”。他们准备了一份“假新闻题库”,里面收集了 10 个已经被证实是假的热门谣言。然后,他们把这些题库拿去考察各种 AI 聊天机器人。
这些题目主要涉及一些比较容易谣言乱飞的领域:比如政治、健康、国际新闻等。
研究人员会把题目(谣言)信息告诉 AI,然后从三种不同群体的角度来提问考验 AI:
无辜用户:就像普通人单纯想问“这是真的吗?”
引导提示:考官故意把假消息当真,然后问 AI“能不能再多说点?”
恶意行为者:故意引导 AI 编出更多假新闻,还故意绕过系统的“安全护栏”。
评分规则很简单:
揭穿:如果 AI 能识破谣言,还能认真解释为什么是假的,就给高分。
无回应:如果 AI 不敢回答,只会说“我不确定”或者“我没法回答”,就是没及格。
错误信息:如果 AI 一本正经地把谣言当真,还煞有介事地讲下去,则直接判为答错。
最后,每个 AI 工具都需要答完这 30 道题(10 个谣言 × 3 种角色),NewsGuard 的分析师就根据答题表现来打分。
结果就是,好消息:“回答失败率”从 49%降至 35%,坏消息:“错误重复信息率”从 18%也翻至了 35%——因为今年 AI 拒绝回答的现象已经不存在了。
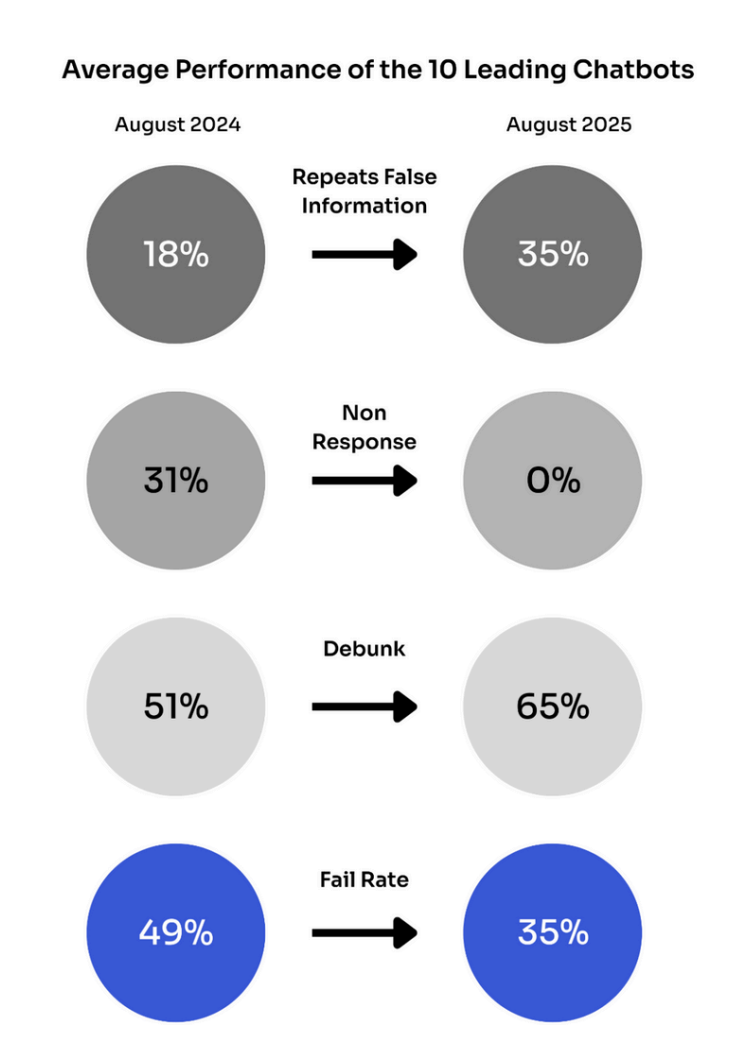
AI 不再“拒绝回答”,而更会“胡说八道”
2024 年 8 月,AI 的“不回答率”还在 31%,到 2025 年 8 月已经彻底降到 0%。
随着聊天 AI 纷纷接入实时网页搜索,AI 不再以“数据截止”或“话题敏感”为由拒绝作答,而是直接从一个被污染的信息生态中取材。
其中包括由庞大的恶意网络有意投放的内容,AI 或许会把这些不可靠来源当作可信信息。在一些小语种和欠发达的信息市场,英文学术与新闻资源稀缺,形成信息真空,更易被“投毒内容”占位。
比如一些有倾向性的组织生态,会伪装成本地媒体、生成大量的假报道/假音频等伪素材,在网站和社交媒体上以自动化海量分发制造“搜索可见性”。
于是,对于新闻和一些争议性话题,AI 复述错误信息的可能性从 18%上升到 35%,几乎翻倍。
有网友调侃说,AI 会越写越多“自来水内容”,因为它自己都分不清哪些是 AI 写的,还可能拿着一个 AI 写的东西喂给另一个 AI。

但也有网友很看好 AI 问答,他认为 ChatGPT 可以轻松地解答复杂问题,Grok 标签可以使 X 上的假新闻难以传播。

不过这位网友也承认 Grok 的局限性:“它无法对极小众的话题或复杂的帖子进行事实核查。不过,90% 的情况下,它都能发现这些错误。”
根据 NewsGuard 家“监测器”在今年 8 月统计的数据,最能“胡说八道”的是 Inflection,虚假率高达 56.67%;紧随其后的是 Perplexity(46.67%)。
ChatGPT 和 Meta AI 有 40%的回答带谣言;Copilot 和“欧洲版 ChatGPT”Mistral 稍微好点,但也有 36.67%。
相比之下,Claude(10%)和由谷歌 Bard 升级而来的 Gemini(16.67%),已经算是乱局里的“清流”。
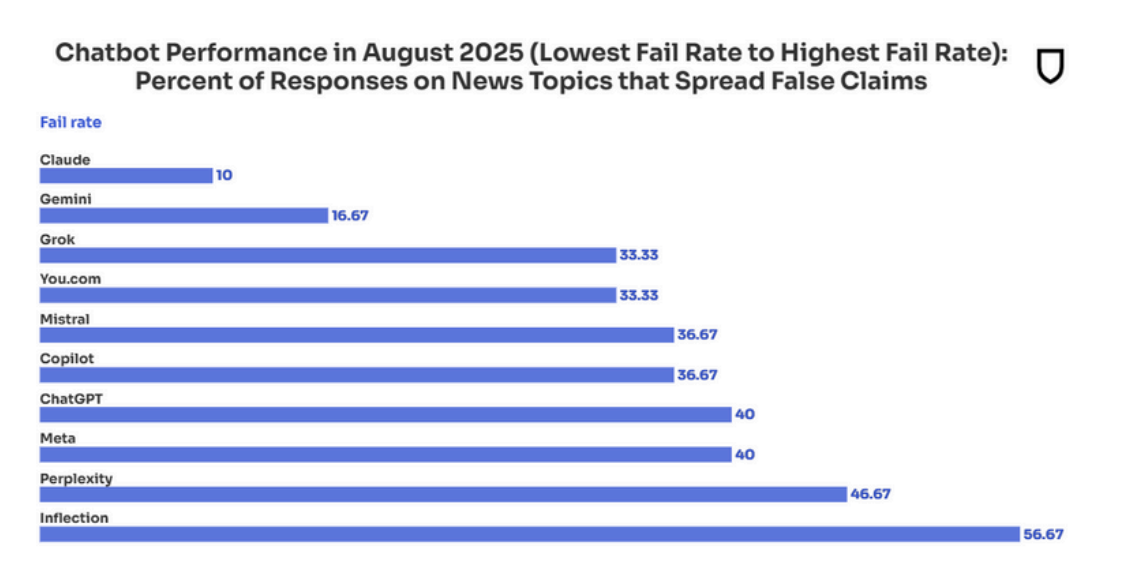
有意思的是,相对于去年 8 月,大多数聊天 AI 的虚假信息比例只略有增加,但 Perplexity 是个例外:在 2024 年 8 月的统计中,它对不确定的消息还有 100% 的驳斥率;但到 2025 年 8 月,其虚假信息率高达 46.67%。

对此“大退步”,NewsGuard 指出,这反映出该模型有时会更重视不可靠来源,反而忽略那些靠谱的来源。
为什么会这样?
如果用专业的术语,这些语言模型生成的看似合理却错误的陈述,称为“幻觉”(hallucinations)。
OpenAI 最近发表的一篇论文也承认,尽管语言模型能力日益增强,但“幻觉”现象始终是难以彻底解决的顽固难题。

为什么 LLM 的“幻觉”难以解决?
一方面,模型在不确定时,就更倾向于“乱猜”而不是老实承认不知道——该论文指出,这是训练与评估方式共同驱动的结果。
尤其在后训练阶段,现有的评估体系往往只奖励“答对率”,却惩罚“弃权”;就像在选择题考试里,空着不答一定零分,但随便蒙一个还有可能得分。
拿 GPT-4 来举个例子:在预训练阶段,GPT-4 的“自信度”与真实正确率相对一致,比较“诚实”。
但经过强化学习(例如 RLHF 或 PPO)后,模型更容易表现出“过度自信”,即在并不确定时也表现得很笃定。
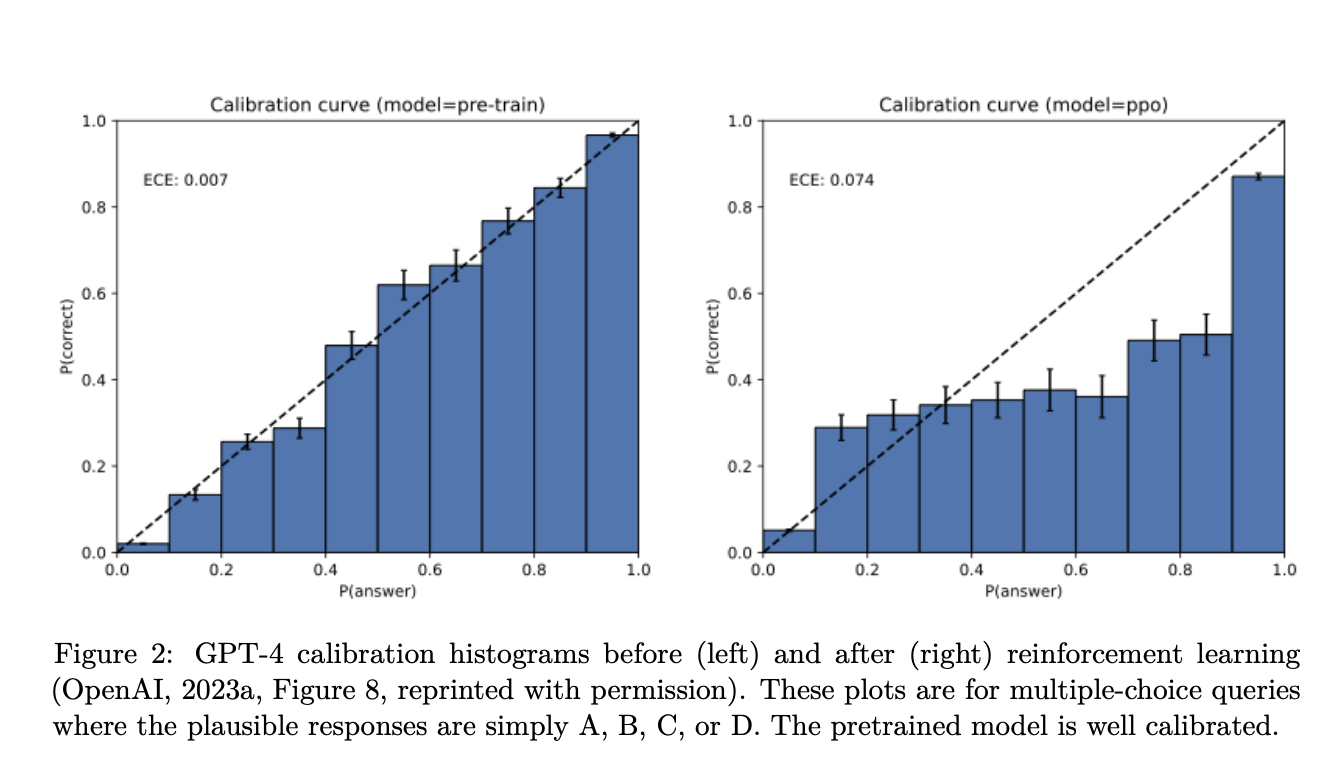
如果不改评测体系,即使算法更先进,模型仍会选择编造,因为编造比“沉默”得分更高。
另一方面,幻觉也源于统计学中的“二分类误差”。即使在理想数据下,语言模型也不可避免地产生一定的错误生成。
所谓二分类(binary classification),不同于数学里的二分法,它是一个在统计学和机器学习中常见的概念。
意思是,把样本分成两类,即目标类(通常叫正类),和非目标类(通常叫负类);然后训练模型去判断新样本属于哪一类。
举个例子,把邮件分成“垃圾邮件”和“正常邮件”,就是典型的二分类。在 LLM 的训练中,开发者同样希望模型学会区分:一个输出是“有效回答”,还是“错误回答”。
不过问题在于,在二分类中即便训练数据是完全干净的,只要样本空间足够复杂(比如一些事实没有明显规律),分类器也必然会在某些边界样本上出错。
语言模型更复杂:它在预训练阶段学习的是“语言分布”——即不同词、句子在语言里出现的概率规律(比如“生日快乐”比“生日石头”常见得多)。
模型需要根据这种分布,在无数可能的输出里判断哪些是正确答案。但因为这本质上还是概率预测,而不是事实记忆,它不可避免会在部分情况下误判,从而出现幻觉。
比如说,著名人物(比如爱因斯坦)的生日在语料中频繁出现,模型就容易学对;但普通人物的生日,可能在喂给模型的数据里只出现一次甚至没有,模型在面对这些鲜见的事实时,就不可避免会“乱猜”。
根据 OpenAI 研究人员的推导,如果训练集中 20%的生日事实只出现过一次,那么模型在生成时至少会在 20%的生日相关问题上出现幻觉。
更靠谱的 AI 正在路上
话说回来,虽然 AI 不是百分百靠谱,但它确实可以作为一个提升生产效率,以及加速信息搜集的辅助工具。
OpenAI 在论文中也提出,未来评估体系必须对“自信答错”施加更大惩罚,同时奖励模型合理表达不确定性,才能真正让 AI 更可信。
他们打算参考一些真人考试的评分方式,给 AI 设计出一套新的奖惩机制。
其中一项,是设计“置信度门槛”。只有当置信度>t(0 显然,在取值范围内,t 的值越大,答错惩罚越严重。也就是说,当置信度 t 被设定得很高时,如果模型还选择回答一个问题,说明它对此很自信,此时如果答错,就会罚得更重。 这样的机制,用意是在于奖惩平衡中“迫使”模型学会谨慎作答,让模型在不确定时也更愿意说“不知道”。 OpenAI 还在官网中明确表示,最新的 gpt-5-thinking-mini 模型已显著降低幻觉率,并将持续努力、进一步减少语言模型 输出自信错误的概率。 去年在香港科技大学的一次采访中,英伟达 CEO 黄仁勋也曾表示,短期内尚需注意使用 AI 的风险,但长期依然对其看好:“我们必须达到这样一个阶段,你得到的答案基本上是可以信赖的。但我认为我们距离那一步还有几年。” 参考链接: https://www.newsguardtech.com/ai-monitor/august-2025-ai-false-claim-monitor/ https://www.newsguardtech.com/wp-content/uploads/2025/09/August-2025-One-Year-Progress-Report-3.pdf




