
从 chatbot 到 Agent,大模型以「缸中之脑」为起点,正在悄然进化出属于自己的四肢百骸。
但在 Agent 应用狂飙突进的同时,各种安全事故也层出不穷。初具雏形的 Agent 应用,正在急切呼唤一个更聪明、更可靠的「原生大脑」。
爆改基模结构,开启 AI 模型「Agent 原生」时代
Agent 时代,由于外部工具和任务重试需求等因素的介入,令上下文长度相比 coding、chatbot 等应用场景,迎来了一轮暴涨。同时,用户对即时性也有了更高的要求。相比 chatbot 时代,吐字比阅读速度快的基本诉求,等待 Agent 工具交付结果的时间,必须被进一步压缩。
所以,上一个时代的 Reasoning 模型,已经不能再适应本时代的需求。一个好的 Agent 原生模型,在推理成本、速度和智能水平三个层面,都必须再次迎来进化。
基于此,阶跃星辰新上线的 Step 3.5 Flash,可谓「多快好省」:
为了满足 Agent 时代的诉求,Step 3.5 Flash 从基础模型层面,就采用了十分独特的结构设计。作为一款旗舰级语言推理模型,它并未盲目追逐模型尺寸,而是选择了稀疏混合专家(MoE)架构。总参数量为 1960 亿,每次推理仅激活约 110 亿参数。
同时,Step 3.5 Flash,将传统的 Linear Attention(线性注意力机制),打散为滑动窗口注意力(SWA)+ 全局注意力(Full Attention)3:1 的混合架构。如果要找个比喻的话,这种结构,十分接近推理小说的阅读体验:大部分注意力依旧集中在当前段落附近的文本,但当一个伏笔回收时,几章之前埋下的剧情钩子,仍然能快速的浮现出来。
最后,在模型技术层面,Step 3.5 Flash 还使用了 MTP-3「多 token 并行预测」机制。
如果说传统大模型,是一个词接一个词的“文字接龙”,那么 MTP-3,就像是先打草稿,再深入润色。在 Transformer 主干之后,MTP-3 会附加一个专用的预测网络层,让模型根据当前上下文同时推断多个未来 token 的概率分布。这样的设计,在保证因果一致性的前提下,实现了多 token 的并行推理。
架构精巧,推理速度可达每秒 350 个 token
多方加持下,Step 3.5 Flash 拥有了高达 256K 的超长上下文,和十分夸张的推理速度。在单请求代码类任务上,Step 3.5 Flash 最高推理速度可达每秒 350 个 token,确保了复杂 Agent 任务的低延迟响应。
和它的名字一样,「快」,是 Step 3.5 Flash 最显著的特点。但速度不能以牺牲智力为代价。在推理速度狂飙突进的同时,它的逻辑能力,同样不容小觑。
在例行刷榜环节当中,Step 3.5 Flash 拿下了 AIME 2025(美国数学邀请赛)97.3 分; IMOAnswerBench(国际奥林匹克数学基准测试)85.4 分;HMMT 2025(哈佛 - 麻省理工数学竞赛) 96.2 分的好成绩。
与国内顶级开源模型相比,上述项目得分,Step 3.5 Flash 均为第一。
缩放定律似乎暗示我们,模型的能力,直接和尺寸挂钩。但 Step 3.5 Flash 用事实证明,合适尺寸 + 充分的后训练,完全可以兼顾速度与效率,得到一个精致、且有强逻辑内核的大模型。
抛弃「规模迷信」的背后,是阶跃星辰对大模型的独特理解:模型应该凝缩「逻辑」,而非用超大规模,简单地对文本模式死记硬背。
「高智商」,才是硬道理
这种认知的回报,在真实世界的任务当中体现的尤为明显:coding 榜单当中,Step 3.5 Flash 拿下了 Terminal-Bench 2.0(终端任务自动化),和 LiveCodeBench-V6(实时编码调试)国内开源第一的好成绩,整体测试水平属于全球第一梯队。
Agent 相关的测试项目更是手到擒来:τ²-Bench(多步任务规划)88.2 分 ;xbench-DeepSearch(深度搜索与信息整合)54 分,均为国内开源模型第一。BrowseComp(网页浏览与上下文管理) 69 分,实现了对海外御三家模型的成功反超。
更大的认可,来自 AI 社群:在真实世界任务中,Step 3.5 Flash 以高达 167 Tokens/s 的推理速度,发布首日,即进入全球知名 AI 模型聚合平台 OpenRouter “Fastest Models”速度榜前列。
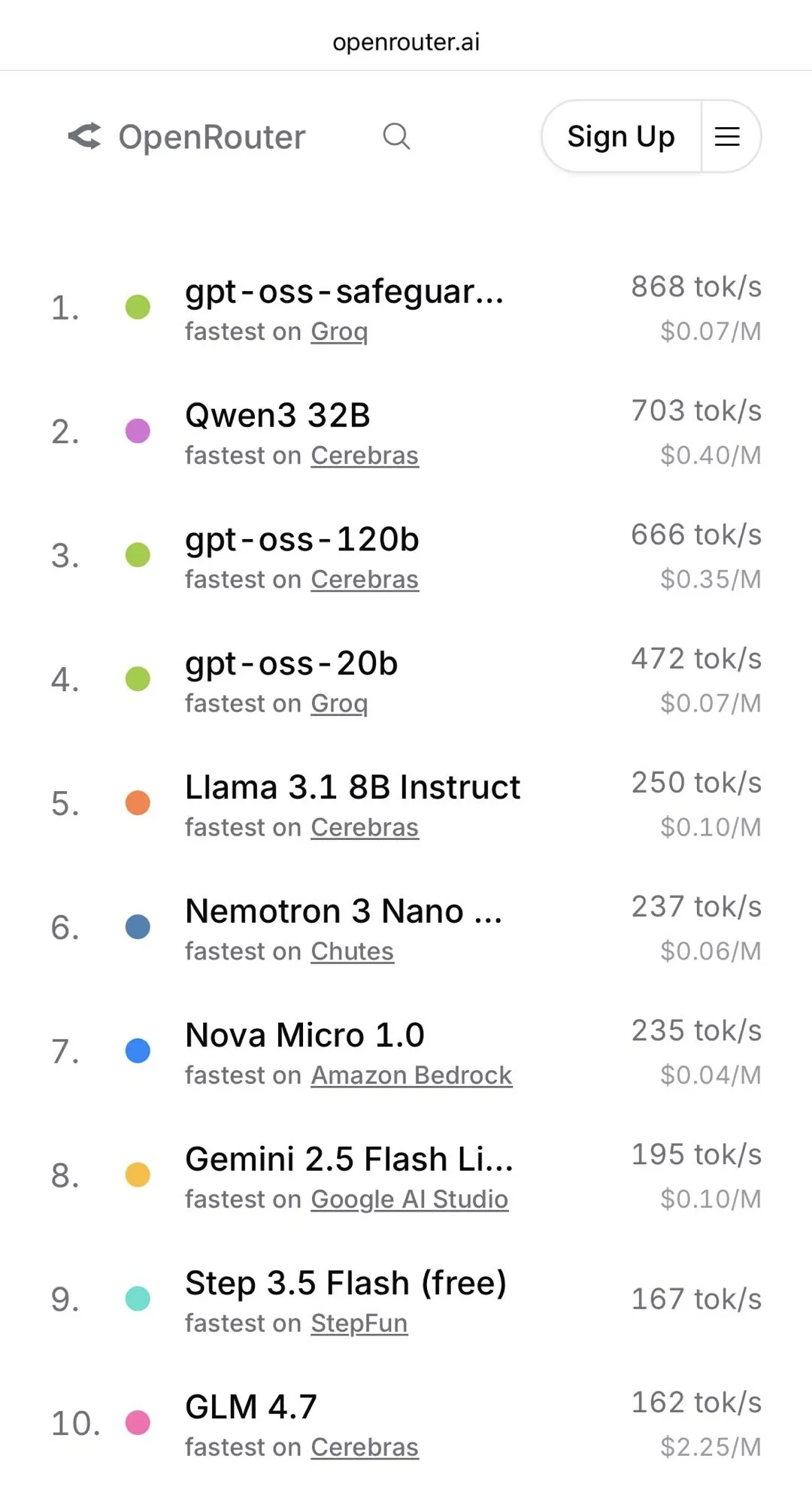
发布 2 天,登顶 OpenRouter 全球趋势榜(Trending)榜单。
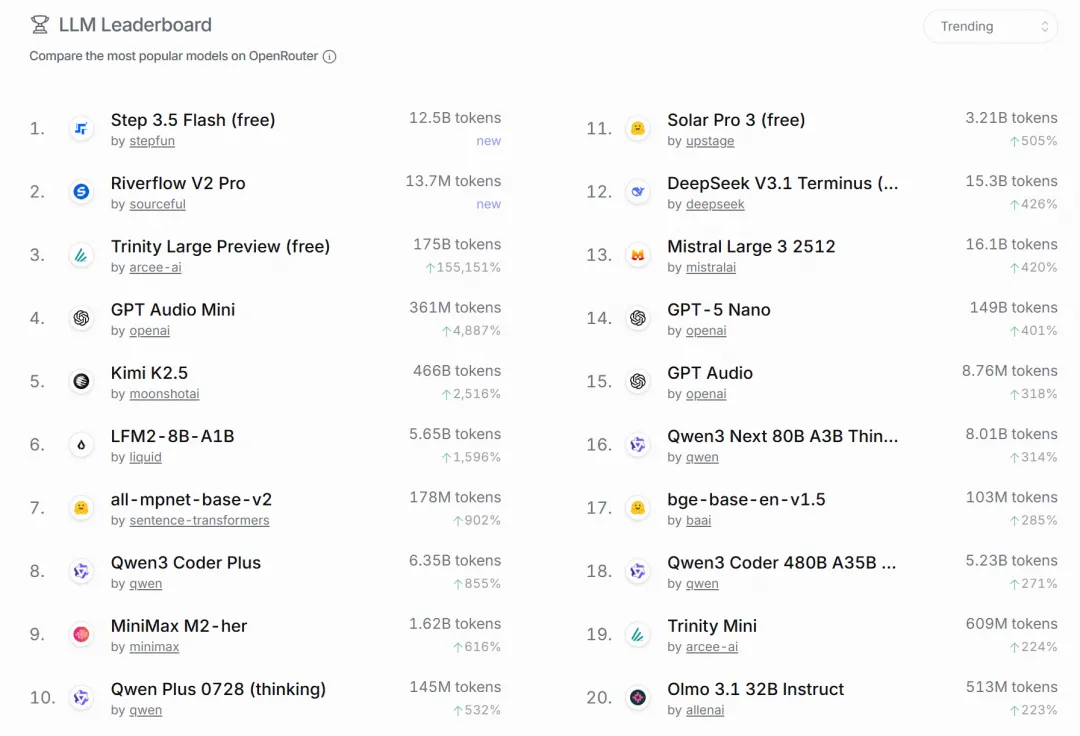
作为汇聚了 OpenAI、Anthropic、Google 等主流模型的 API 平台,OpenRouter 的全球趋势榜单,实时反映着开发者在实际应用中的模型偏好与付费选择。此次登顶,意味着 Step 3.5 Flash 在真实任务当中的表现,已收获了全球 AI 开发者的积极认可。
Reddit、X 等平台上也有不少用户,对 Step 3.5 Flash 的表现给出了很高的评价:多语言混用时切换自然,很少出现同尺寸模型身上常见的「夹杂」情况;行事稳定可靠,幻觉率极低,且对自身的能力边界有着清晰的认知,不会为了强行接话而编造答案。


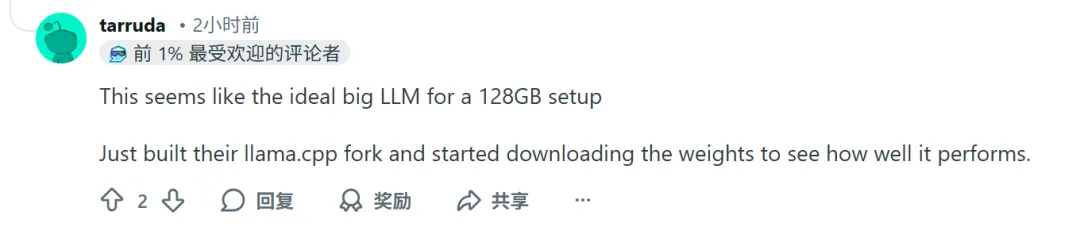
而这一切,都发生在一台 128G 内存、M3 Max 芯片的 mac 电脑上。
本地 Agent,从此平权
据社区反馈,借助 llama.cpp,Step 3.5 Flash 在 mac 平台上的推理速度极佳。平均速度 35 tokens/ 秒,约为该平台理论最大效率的 70%。
某种程度上,这是阶跃星辰 CTO 朱亦博「私心」的结果:他希望这个模型,能支持 4-bit 量化后,运行在 128GB 内存的 MacBook 上。
但 Step 3.5 Flash 最终发布时的支持范围远不止于此:云服务层面,包括华为昇腾、沐曦股份、壁仞科技、燧原科技、天数智芯、阿里平头哥等在内的多家芯片厂商,均已率先完成了对 Step 3.5 Flash 的适配工作。同时,经过 4-bit 量化以后,Step 3.5 Flash 也支持在 NVIDIA DGX Spark、Apple M3/M4 Max 以及 AMD AI Max+ 395 等主流个人 AI 终端上,进行本地部署——同时依然保持着 256K context 的超长上下文能力。
朱亦博在博客文章里不无自豪地表示,这是你在 128GB 内存的 Macbook 和 DGX Spark 上,用 4-bit 畅快跑 256K context 的最强模型,没有之一。
AI 模型的又一个「中国时刻」?
在过去的一年中,来自中国的开源模型,用更低的获取门槛、推理成本和打平的性能,一举击碎了“超大规模 + 闭源 = 先进”的行业迷信,无数 AI 应用因此涌现,也将大模型竞争,重新拉回了效率与架构创新的主航道。
现在,国内几家 AI 公司动作频频、传闻不断,今年大模型领域的「春节档」,注定热闹非常。而最近发布的 Step 3.5 Flash,或许正悄然复刻又一个 AI 领域的「中国时刻」——高性能、低门槛、新范式。只是这一次,范式转移的焦点,从“推理模型”转向了更具颠覆性的“Agent 原生(开源)基座模型”。
当行业还在用稠密模型硬扛 Agent 场景时,它用 1960 亿总参数、仅 110 亿激活参数的精巧架构,同时解决了 Agent 时代的三大死结——超长上下文下的低延迟响应、复杂任务中的高幻觉风险、以及终端设备上的本地化部署。
当海外巨头将 Agent 能力锁死在云端 API 时,Step 3.5 Flash,让 256K 上下文的 Agent 大脑,跑在 128GB 内存的 MacBook 上——这是对 AI 权力结构的重构:Agent 的智能不应被云厂商垄断,开发者理应拥有在终端侧构建私有化 Agent 工作流的自由。
这种“终端平权”逻辑,恰是此前中国 AI 大模型引领的范式转移,在新环境下进一步的延续与深化:从模型获取的平权,进阶到 Agent 能力的平权。
历史从不重复,但常常押韵。如果说之前的国产大模型,打破的是“对规模和闭源的迷信”,那么 Step 3.5 Flash 正在击碎的,就是“速度与智能不可兼得”的新迷信。当行业还在用“参数量”“榜单分数”这类旧范式衡量模型价值时,Step 3.5 Flash 已用 OpenRouter 趋势榜登顶、Reddit 开发者自发安利、多芯片厂商 Day 0 适配的事实证明:真正的范式转移,永远始于真实世界中,解决真实诉求的能力。
我们或许正站在 Agent 时代的分水岭上:过去一年,市场狂热追逐 Agent 应用层的“四肢百骸”,却忽略了为其注入灵魂的“原生大脑”。而 Step 3.5 Flash 的此时此刻,又恰似 2025 年春节的彼时彼刻——尽管暂时被 Agent 应用的喧嚣浪潮所掩盖,但历史终将被证明,在 Agent 时代,是阶跃星辰,完成了一次基础设施层,最关键的范式跃迁。




