
Lyft 将其机器学习平台 LyftLearn 重构为一个混合系统:将离线工作负载迁移至AWS SageMaker,同时继续使用Kubernetes处理在线模型推理。该决策在运维复杂度最高的环节采用托管服务,在控制权至关重要的环节保留自定义基础设施,这样为统一平台战略提供了一种务实的替代方案。
Lyft 的工程师将负责训练和批处理任务的 LyftLearn Compute 迁移到了AWS SageMaker,从而消除了此前耗费大量工程精力的后台监控服务、集群自动扩缩容难题以及最终一致性状态管理的问题。而负责实时推理的 LyftLearn Serving 则保留在Kubernetes上,因为 Lyft 现有的架构已能在此场景下提供所需的性能,并与内部工具链深度集成。
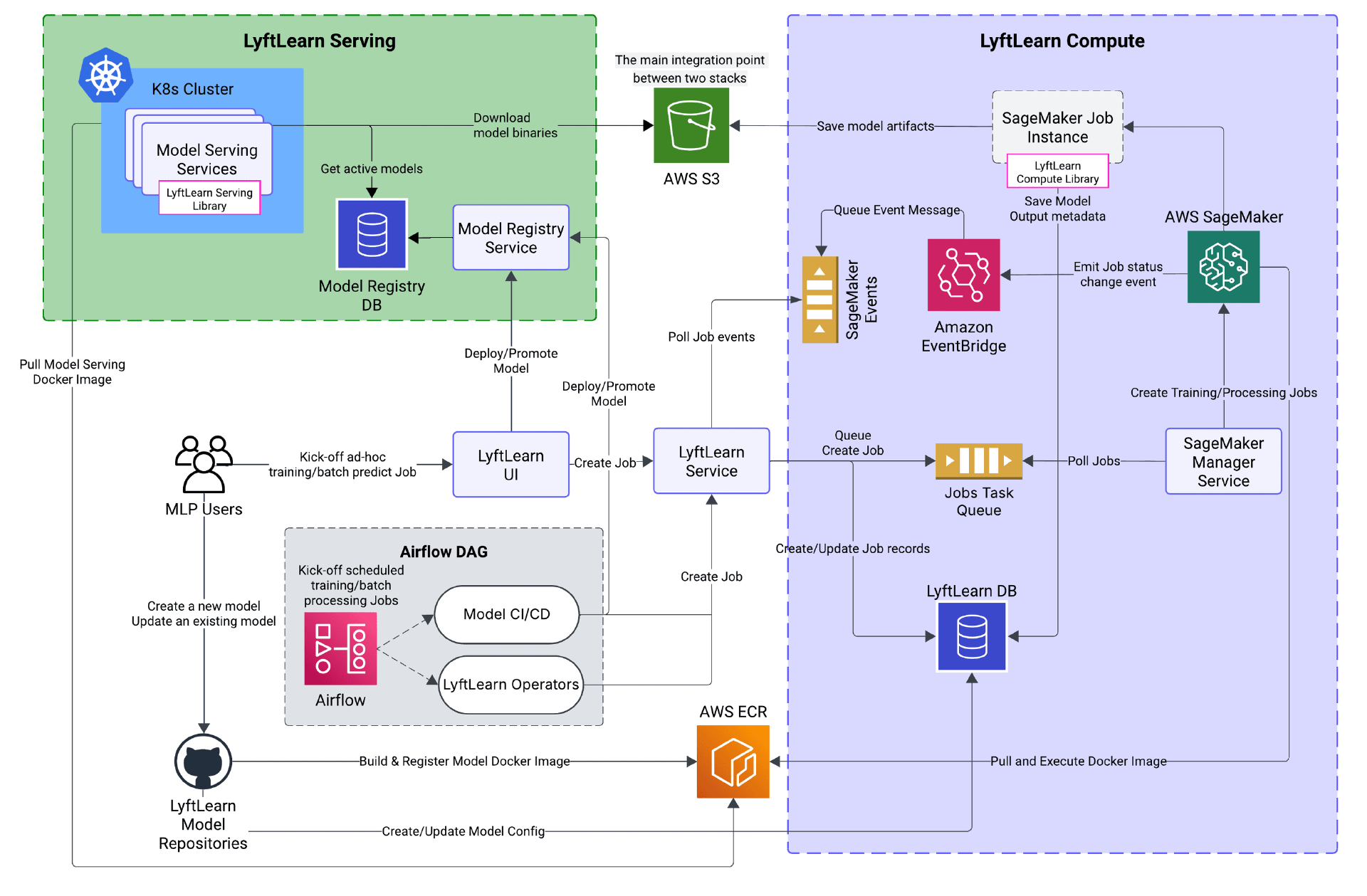
LyftLearn 混合架构的高层示意图(来源)
作者Yaroslav Yatsiuk解释了这一决策的核心原因:
我们选择 SageMaker 进行训练,是因为维护自定义的批处理计算基础设施消耗了本可用于提升 ML 平台核心能力的工程资源。而我们保留了自建的推理基础设施,因为它提供了我们需要的成本效益和精细控制。
LyftLearn 每天支持数亿次预测,涵盖派单优化、定价和欺诈检测等场景,每天运行数千个训练任务,服务于数百名数据科学家和机器学习工程师。该平台最初完全构建在 Kubernetes 之上,但随着规模扩大,运维复杂性也随之激增。每新增一项 ML 能力都需要定制编排逻辑,而 Kubernetes 状态与平台数据库之间的同步则依赖多个监控服务,以处理乱序事件和容器状态转换。
对于离线工作负载,SageMaker 的托管基础设施直接解决了上述痛点:AWS EventBridge和SQS以事件驱动的状态管理取代了原有的监控架构,按需资源分配则消除了闲置集群带来的成本。不过,此次迁移要求对现有 ML 代码保持完全兼容。
为此,Lyft 构建了跨平台的 Docker 镜像,在 SageMaker 中复现了 Kubernetes 的运行时环境,透明地处理凭证注入、指标收集和配置管理。针对每 15 分钟重训一次的低延迟工作负载,团队采用了Seekable OCI(SOCI),实现了与 Kubernetes 相当的启动速度。
最具挑战性的部分在于Spark在 SageMaker Studio 与 EKS 集群之间所需的双向通信。SageMaker 默认网络策略会阻止 Spark 执行器向 Notebook Driver 发起的入站连接。Lyft 与 AWS 合作,在其 Studio Domains 中启用了自定义网络配置,从而在不影响性能的前提下解决了该问题。
迁移以“逐个仓库推进”的方式部署,新旧基础设施并行运行,仅需极少的配置变更。通过兼容层,用于 SageMaker 训练的同一个 Docker 镜像也可直接在 Kubernetes 中用于模型服务,彻底消除了训练-推理不一致的问题。Lyft 报告称,迁移后基础设施事故显著减少,工程团队得以将更多精力投入到平台功能开发中。Yatsiuk 总结说:
优秀的平台工程,不在于你运行的技术栈是什么,而在于你隐藏了多少复杂性,以及你释放了多少开发效能。
原文链接:
Lyft Rearchitects ML Platform with Hybrid AWS SageMaker-Kubernetes Approach




