
今天,英伟达发布了亮眼的财报:季度收入创纪录为 393 亿美元,环比增长 12%,同比增长 78%;季度数据中心收入创纪录为 356 亿美元,环比增长 16%,同比增长 93%;全年收入创纪录为 1305 亿美元,同比增长 114%。
不过,这样的成绩并没有带动英伟达股价大涨,反而在财报披露后却出现了剧烈波动。英伟达分析师电话会议结束,英伟达股价转而下跌 0.12%。
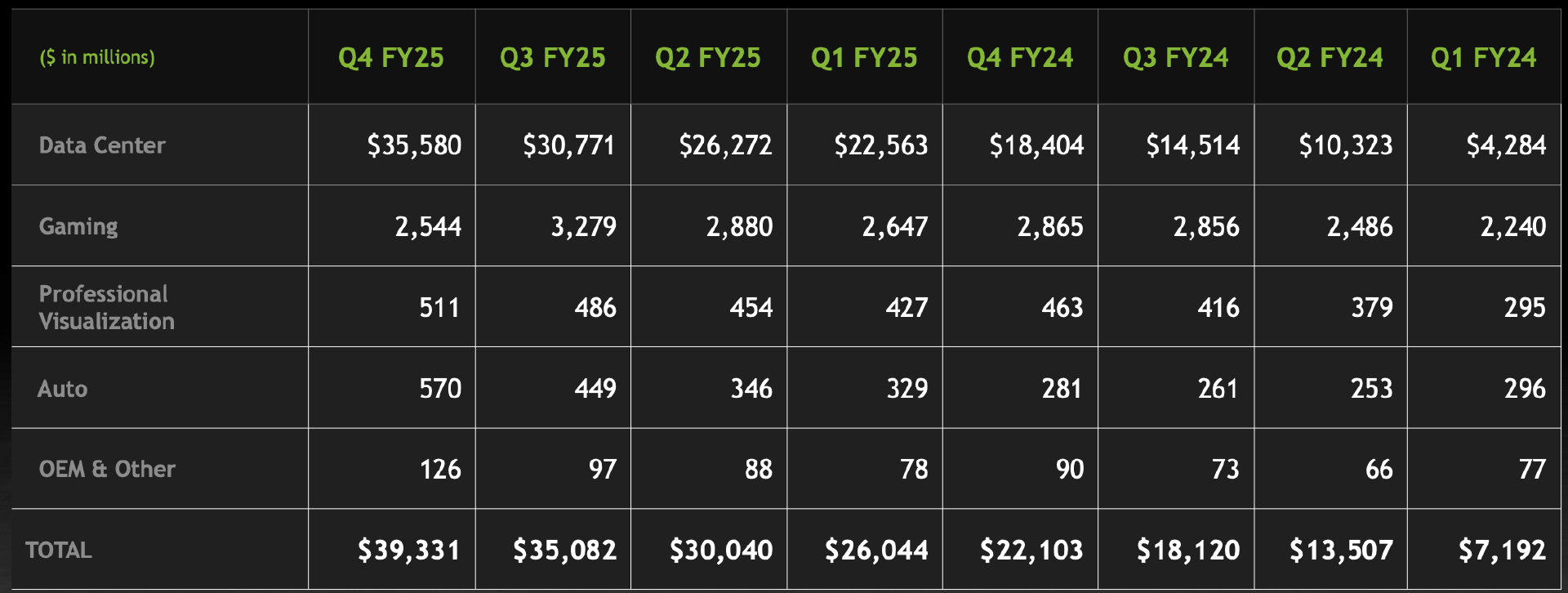
数据中心业务稳居收入大头,得益于英伟达 Hopper GPU 计算平台和 InfiniBand 的出货量增加。在第四季度收入创下 356 亿美元的纪录,比上一季度增长 16%,比去年同期增长 93%。全年收入增长 142%,达到了创纪录的 1152 亿美元。据悉,目前全球 TOP500 的超级计算机榜单上,超过 75%的系统由英伟达技术提供支持。云服务提供商 AWS、CoreWeave、Google Cloud Platform(GCP)、Microsoft Azure 和 Oracle Cloud Infrastructure(OCI)采购英伟达 GB200,以对日益增长的 AI 客户需求。英伟达将作为投资 5000 亿美元的“星际之门”的关键技术合作伙伴。
游戏与 AI PC 业务方面,第四季度游戏收入为 25 亿美元,比上一季度下降 22%,比去年同期下降 11%。全年收入增长 9%,达到了 114 亿美元,得益于 RTX 40 系列 GPU 的热销。英伟达推出采用 Blackwell 架构的 RTX™ 50 系列显卡,其中 5090 和 5080 相比上一代产品提供最高 2 倍的性能提升。NVIDIA DLSS 4 具备多帧生成和图像质量增强功能,发布时已有 75 款游戏和应用支持,NVIDIA Reflex 2 可以将 PC 延迟降低最多 75%。
专业可视化方面,第四季度收入为 5.11 亿美元,环比增长 5%,同比增长 10%。全年收入增长 21%,达到了 19 亿美元。英伟达发布个人 AI 超级计算机 NVIDIA Project DIGITS,为全球的 AI 研究人员、数据科学家和学生提供访问英伟达 Grace™ Blackwell 平台的强大计算能力。
汽车和机器人业务方面,第四季度汽车业务营收达 5.7 亿美元,环比增长 27%,同比增长 103%;全年营收增长 55%至 17 亿美元。英伟达与丰田、现代汽车达成合作,推出 NVIDIA Cosmos™平台,已被机器人及汽车企业 1X、Agile Robots、Waabi、Uber 等采用,发布 NVIDIA Jetson Orin Nano™ Super,其生成式 AI 性能最高提升 1.7 倍。
英伟达创始人兼首席执行官黄仁勋表示:“Blackwell 的需求非常强劲,因为推理 AI 为计算能力增加了另一个缩放定律——增加用于训练的计算能让模型更聪明,增加用于长时间思考的计算会让答案更智能。”
Blackwell 是英伟达去年发布的“历史上最强大”GPU 架构,支持万亿参数规模的 AI 模型训练和推理。黄仁勋表示,Blackwell 架构为推理 AI 设计,推理性能比 Hopper 提升 25 倍,成本降低 20 倍。他进一步确认,Blackwell 系列芯片的供应链问题已完全解决,供应问题不曾妨碍到下一次训练和后续产品的研发。
此外,黄仁勋透露,Blackwell Ultra 计划于 2025 年下半年发布,将带来新的网络、内存和处理器等改进。CFO 指出,一旦 Blackwell 增产,利润将有所改善,并预计到 2025 年年底,利润率将在 70%-80%区间的中部。然而,他强调目前的首要任务是向客户交付尽可能多的产品。

得益于 R1 推理模型,全球计算需求在加速增长
今年 1 月,中国初创 AI 公司 DeepSeek 发布的开源模型 R1 震撼全球——在极低的训练成本下,该模型展现出不逊于 ChatGPT 的顶级性能。这一消息一度引发市场震动,导致英伟达股价单日暴跌 17%。尽管过去一个月内英伟达股价已回升至高位,但市场对训练效率的提升可能影响其长期增长轨迹的担忧依然挥之不去。
这份财报所覆盖的时间(截至 1 月 26 日前的三个月)恰巧与 DeepSeek 震撼市场的日子(1 月 27 日)错开,从财报数据本身看不出 DeepSeek 给英伟达带来的业绩影响,但在财报电话会议上,DeepSeek 无疑是一个无法回避的议题。
对于 DeepSeek 对英伟达的影响,黄仁勋提到,因为 OpenAI o3、DeepSeek R1 和 Grok 3 这些新兴推理模型的兴起,大家的推理需求正在加速增长。
并且长时间推理(long-thinking reasoning AI)每个任务所需的计算量可能是一次性推理(one-shot inference)的 100 倍。
人工智能正在从感知和生成式 AI 进化到推理 AI。计算量越大,模型“思考”得越多,答案就越智能。像 OpenAI o3、DeepSeek R1 和 Grok 3 这样的推理模型正采用推理时间缩放(Inference-Time Scaling)。推理模型的计算需求可能是传统模型的 100 倍,而未来的推理模型可能需要更大规模的计算资源。
“DeepSeek R1 的出现点燃了全球的热情。这是一项出色的创新,但更重要的是,它开源了一个世界级的推理 AI 模型。”
如今,几乎所有 AI 开发者都在使用 R1,或者借鉴其链式思维(Chain of Thought)和强化学习(Reinforcement Learning)等技术来提升模型性能。目前有三条缩放定律在推动 AI 计算需求的增长。AI 的传统缩放定律依然有效,基础模型(Foundation Models)正在不断增强,并融入多模态能力,预训练规模仍在持续扩大。但这已经不再足够。AI 计算需求正向两个新维度扩展。首先是后训练缩放(Post-Training Scaling),包括强化学习(Reinforcement Learning)、微调(Fine-Tuning)和模型蒸馏(Model Distillation),其计算需求比单纯的预训练高出数个数量级。其次是推理时间缩放,在这一过程中,单次查询的计算需求可能达到传统推理的 100 倍。
“这仅仅是个开始!”黄仁勋强调,“我们预计下一代模型可能会基于模拟和搜索技术,计算量需求将是现在的数千倍,甚至有望达到数十万倍、数百万倍。”
“有些模型是自回归模型,有些是基于扩散模型,各不相同。有时我们希望看到数据中心具备强大的综合推理能力,有时又需要其具备紧凑的特性,因此很难确定数据中心的最佳配置。这也就是为什么英伟达的架构如此受市场欢迎,因为我们能运行各种模型。”
DeepSeek 的开源进一步巩固英伟达的领先地位?!
在财报电话会议上,黄仁勋提到,中国市场的占比与此前几个季度大致相同,基本保持稳定。
但根据昨天路透社的消息,由于对 DeepSeek 低成本 AI 模型的需求激增,中国企业正在加大对英伟达 H20 人工智能芯片的采购。其中,两位知情人士指出,自上个月 DeepSeek 进入全球公众视野以来,腾讯、阿里巴巴和字节跳动的 H20 订单“显著增长”。
最近几天,DeepSeek 开源了针对英伟达进行优化的一系列代码库,包括 FlashMLA、DeepEP、DeepGEMM、DualPipe 和 EPLB,涉及 Hopper GPU、FP8 精度计算、MoE(Mixture of Experts)、并行策略等关键技术。
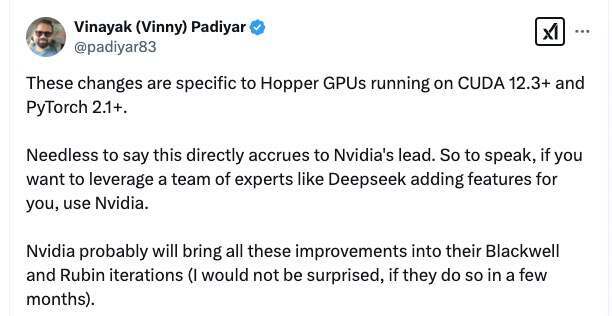
曾参与构建 OpenAI 首个 GPU 集群的Vinayak昨天发表的评论则揭示了一个深层逻辑——DeepSeek 开源的优化方案实质上巩固了英伟达的技术壁垒:“毫无疑问,这将进一步巩固英伟达的领先地位。换句话说,如果你想要像 DeepSeek 这样的专家团队为你优化功能,那就选择英伟达。英伟达很可能会在接下来的 Blackwell 和 Rubin 迭代中引入这些改进(如果他们在未来几个月内这么做了,我一点也不会感到意外)。”
有趣的是,不仅仅是目前开源的这些优化,在 V3 模型论文中,DeepSeek 甚至在技术层面向英伟达提出的具体改进建议:
其一是累加精度升级。通过实验发现,英伟达 Tensor Core 当前累加精度(34 位以下)难以满足 FP8 训练的误差控制需求。DeepSeek 建议增加累加精度或动态调整位宽,以平衡效率与精度。这一改进若能实现,将显著提升低精度训练可靠性。
“我们的实验发现,Tensor Core 在进行符号扩展右移后,仅保留每个尾数乘积的最高 14 位,并截断超出范围的位数。然而,例如,为了在 32 次 FP8×FP8 乘法累加中获得精确的 FP32 结果,至少需要 34 位精度。因此,我们建议未来的芯片设计在 Tensor Core 中增加累加精度,以支持全精度累加,或者根据训练和推理算法的精度要求选择合适的累加位宽。此方法能够在保持计算效率的同时,将误差控制在可接受范围内。”
其二是在线量化流程优化。DeepSeek 开发了一种基于 Tile(子块)和 Block(块级)的量化方法,可以在数据集中动态调整特定位宽下的数值范围。而目前英伟达仅支持张量级别的量化。DeepSeek 希望英伟达的架构师阅读其论文,并看到该方法的优势。
其三是矩阵运算融合创新。DeepSeek 还希望 GPU 厂商将矩阵转置操作与 GEMM(通用矩阵乘法)运算融合,从而进一步减少内存操作,优化量化工作流。
未来,DeepSeek 和英伟达是否能更深层次的合作,比如共同研发新技术,现在还不好说。但至少目前,DeepSeek 通过模型优化释放了中端芯片的潜力,而英伟达则借助生态反馈增强了硬件的竞争力。
参考链接:




