
AI 时代正在重塑数据库的角色。过去,数据库主要为人类分析者提供报表与查询能力;而现在,越来越多的查询来自智能代理(Agent),它们会自动检索知识、过滤数据、组合多种信号,并将数据库作为“实时信息源”支撑推理与决策。
这一根本性变化,对数据库的检索能力提出了全新挑战。传统单一的搜索模式(无论是关键词还是向量搜索)已显不足,在应对复杂多模态的 Agent 查询时,往往在缺乏结果的全面性、语义的精确性以及流程的可控性。而这就要求数据库同时具备三种能力,将结构化分析、文本搜索和向量语义搜索集为一体,实现高效的混合搜索能力。特别是在以检索增强生成(RAG)为代表的应用中,混合搜索能力变得更为关键,已成为避免幻觉、提高相关性与保持实时性的基础能力。
1. 多系统拼接方案的痛点
为实现混合搜索的能力,许多系统采用“向量数据库 + 搜索数据库 + OLAP 数据库”组合式架构来支撑类似能力。然而,多系统拼接会带来一系列问题:
数据冗余与复杂 ETL:文本数据库、向量数据库与分析数据库分别持有不同格式的数据副本,任何更新都需要跨系统同步,导致延迟与运维成本上升。
查询链路长、延迟高:一次混合搜索需要多次跳转调用,例如先在向量库召回、再到搜索库过滤、最后进入 OLAP 聚合,成倍增加的链路延迟远高于单引擎执行。
难以保障一致性:数据按不同时间写入不同系统,搜索结果与结构化结果可能基于不同版本的数据,难以保障 Agent 逻辑稳定性。
调度无法统一:每个系统有独立的优化器,无法形成全局执行计划,也无法共享过滤、分区裁剪或索引下推。
这些问题共同形成所谓的“数据烟囱”效应,使本应一次完成的混合查询被迫拆成多段执行,不仅增加复杂度,也使其在 RAG、Agent、推荐等对延迟敏感的场景中无法真正落地。
2. HSAP:面向 AI 应用的混合搜索与分析处理
相对而言,Hybrid Search and Analytics Processing(HSAP) 是当下更优的解决方案。它能在同一引擎中同时处理结构化分析、全文搜索和向量搜索,并通过统一优化器调度协同执行。

在 HSAP 模型下,不同搜索方式不再彼此独立,共同参与完整的查询生命周期,满足语义广度、关键词精确匹配以及业务约束等多维需求。在实际执行中,HSAP 的查询流程通常呈现为简洁且高效的协同模式,流程如下:
A. 单次查询请求(Single Request)
用户仅需提交一次查询请求,该请求可同时包含文本检索、向量检索和复杂的结构化分析需求(过滤、聚合统计、排序等)。这些需求以统一的 SQL 表达,进入同一个执行计划。
B. 并行执行(Parallel Execution)
系统并行化处理两种搜索负载:
文本搜索通过倒排索引查询,完成关键词匹配和 BM25 排序召回
向量搜索通过 ANN 索引查询,完成语义相似度召回,其中结构化过滤作为前过滤(缩小候选数据量)或后过滤(对召回结果进一步筛选)统一参与执行
这种并行化和下推机制,使得整体延迟仅受限于最慢的单一搜索路径,而非多系统串联调用的链路延迟,从根本上提升了查询的效率。
C. 结果融合与分析(Result Fusion & Analytics)
各搜索路径生成 Top-K 结果后,系统利用 RRF 算法生成统一排序;随后依托 OLAP 引擎的分析处理能力,执行复杂的统计聚合与明细查询,直接返回完整的分析结果。
3. Apache Doris HSAP 的实现
HSAP 模型提供了理想的理论框架,而 Apache Doris 则是一个将其工程化落地的典范。Doris 通过统一的存储格式、执行引擎和 SQL 工作流,将结构化分析、倒排索引和向量索引三大能力整合为一个系统,实现了高效的混合搜索和实时分析能力。
而 Apache Doris HSAP 能力的实现并非一蹴而就,整体架构的演进分为三个阶段,如下所示。自 2.x 版本起奠定了基础,最终在 4.0 版本实现了融合检索,升级为文本与向量并重的混合搜索体系。接下来,我们将逐一介绍 Apache Doris HSAP 核心能力、最佳实践以及性能表现。

4. 基于倒排索引的高性能文本分析
文本搜索能力对于大型语言模型(LLM)是不可或缺的基石,从根本上决定了 LLM 应用的可靠性、准确性和实用性。Apache Doris 主要基于倒排索引实现了高性能的文本分析能力。
倒排索引基本原理是将文本拆分成词项(Term),并记录每个词项出现的文档。查询时无需逐行扫描,直接通过索引定位相关行号,将查询复杂度从 O(n) 下降到 O(log n) 级别。为了让搜索能力真正适配 AI Agent 的分析场景,Doris 对倒排索引进行了系统化的架构设计与工程优化。

在结构上:Doris 实现了外挂式索引结构,可将倒排索引与 segment 数据文件解耦,作为独立文件存储。这种结构更加灵活,可在已有表上直接新增倒排索引,无需重建数据和下线业务。并支持按需异步与增量式构建索引,有效避免对在线服务的冲击。此外,索引在 compaction 阶段可不按照数据重写,仅需对索引内容进行合并,减少分词带来的资源消耗。
在查询上:引入双层索引缓存体系,对象缓存减少文件 IO,查询缓存避免重复执行。同时优化了索引查询不回表策略,针对
COUNT统计或纯谓词过滤场景,当查询条件仅依赖倒排索引即可判定结果时,执行引擎将直接跳过数据文件(Data Segment)的读取与解压,仅通过索引文件完成计算,这样可将 I/O 开销降至最低,提升了聚合分析吞吐量。在存储上:为更好在性能与存储成本间取得平衡,Doris 引入了多种自适应压缩算法,对倒排索引的词典、倒排表、短语位置等信息进行压缩存储。
内置分词器及自定义分词:内置多种分词器,覆盖中英文、多语种 Unicode、ICU 国际化等主流语言;同时支持自定义分析器,可配置字符清洗、分词模式、停用词、拼音转换、大小写规整等能力。
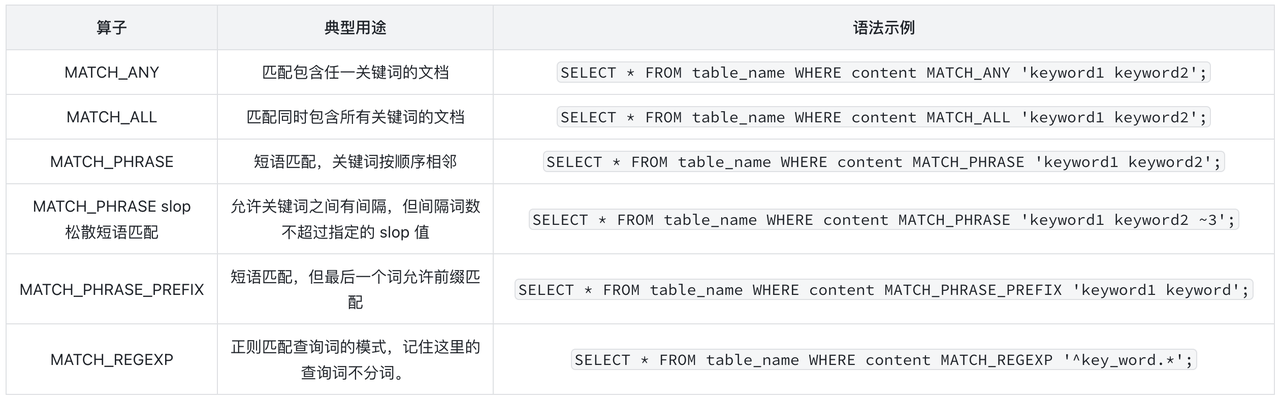
丰富的查询算子:在倒排索引的基础上,Doris 实现了完整的搜索算子体系,完整可见下图:
BM25 相关性打分:
BM25(Best Matching 25)是一种基于概率的文本相关性评分算法,广泛应用于全文搜索引擎中。Doris 4.0 版本引入 BM25,为倒排索引查询提供了相关性评分功能.BM25 可根据文档长度动态调整词频权重,在长文本、多字段检索场景下(如日志分析、文档检索),显著提升结果相关性与检索准确性。
在 Doris 这样的分布式架构下,BM25 打分流程有三个阶段。该流程对 Tablet 级 和 Segment 级分别统计,可有效保证稳定性。
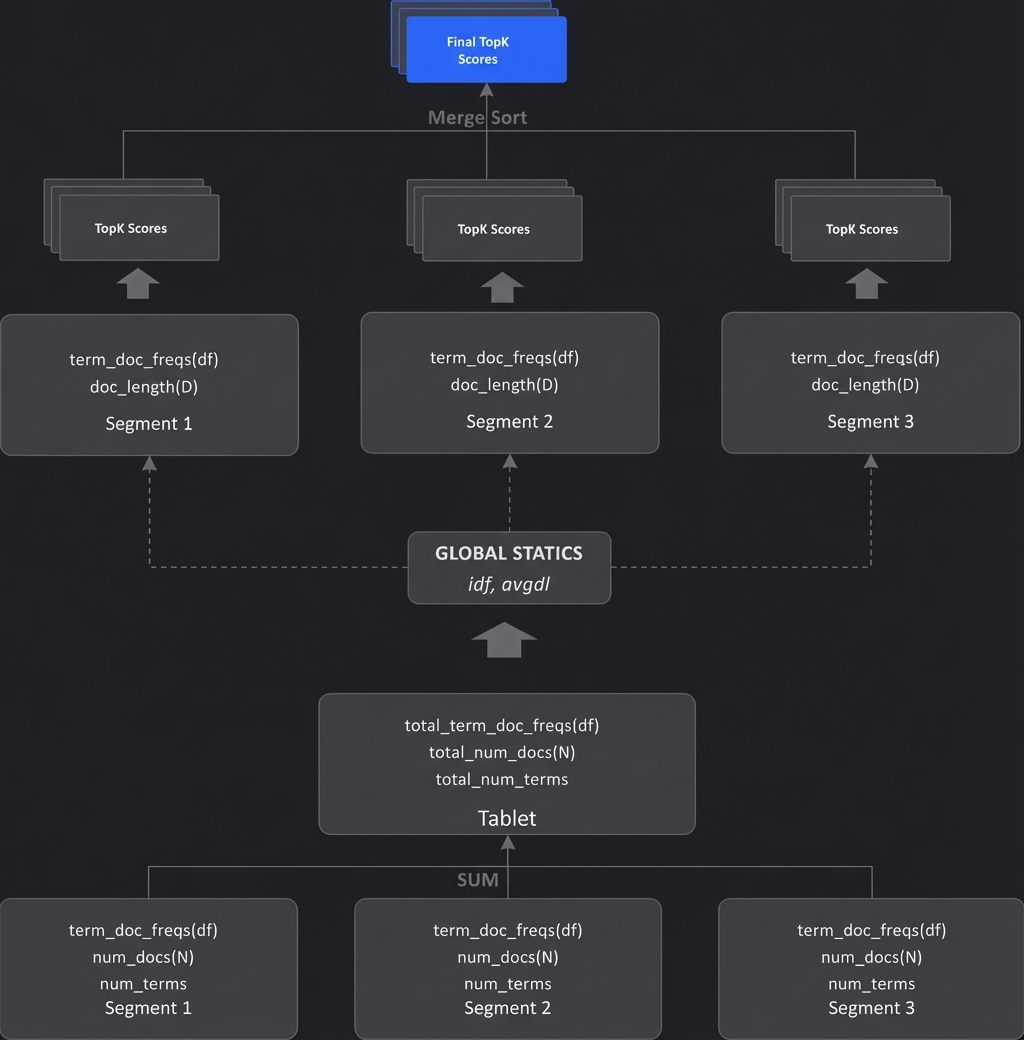
阶段 1:在 Tablet 级别执行,负责遍历所有 Segment 并收集 BM25 计算所需的全局元数据:
统计收集: 累加总文档数 (N) 和每个词项的全局文档频率 (f(qi,D))。
平均计算: 累加所有文档的总词数,计算出全局的平均文档长度 (avgdl)。
核心产出: 根据 N 和 f(qi,D)计算出每个查询词项的 全局 IDF 值。
阶段 2:在 Segment 级别执行,并行计算 BM25 分数并筛选 Top-K。
由于 BM25 的计算是文档独立的(一旦 IDF 确定,文档分数只依赖自身信息),每个 Segment 可以利用阶段 1 提供的全局统计信息,独立并行地完成打分和局部裁剪:
并行打分: 每个 Segment 使用全局 IDF ,结合自身的词频 (f(qi,D)) 和文档长度 (|D|),计算所有匹配文档的 BM25 分数。
局部裁剪: 在 Segment 内部直接执行 Top-K 筛选,只保 b 留和返回排名最高的文档 ID 和对应的分数,减少数据传输开销。
阶段 3:上层汇总,合并各 Segment 的 Top-K。查询的汇总节点(如 Backend 的聚合层)收集所有并行 Segment 返回的局部 Top-K 结果,进行全局归并排序,最终生成满足用户需求的 Top-K 结果集。
5. 基于 ANN 索引拓展 Doris 语义搜索
随着语义向量在 AI 与检索场景中的广泛使用,向量搜索逐渐成为数据库的基础能力。Doris 在 4.0 版本中将向量索引纳入其统一的索引架构,使向量搜索与结构化过滤、全文搜索在同一执行框架内协同工作,实现高效、可控、可扩展的语义搜索能力。
一般来说,向量索引的构建会消耗大量计算资源,尤其在亿级 Embedding 的场景中。而 Doris 的向量索引与倒排索引采用一体化架构,用户可以像处理倒排索引一样异步构建向量索引,最大限度降低对写入性能的影响。同时,调整向量索引构建参数时,用户可以轻松进行索引的删除与重建。
5.1 Doris 向量索引介绍
向量搜索通常需要在“召回率、查询延迟、构建开销”之间取得平衡,因此 Doris 内置了两类主流 ANN 索引:HNSW 与 IVF。
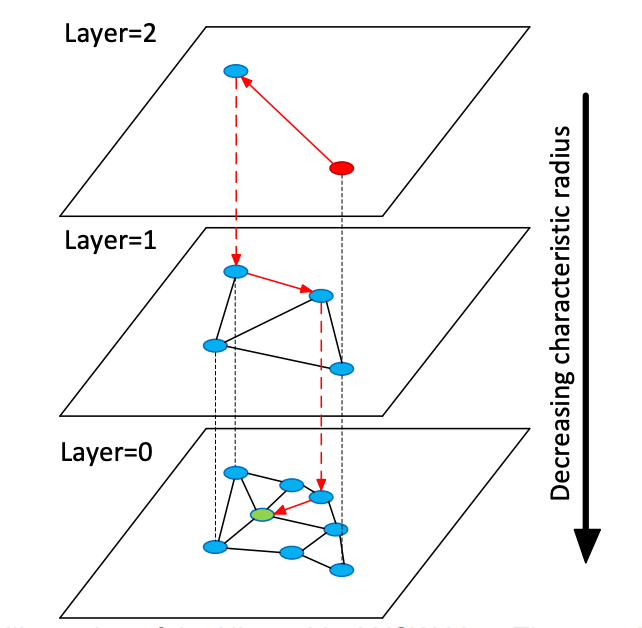
HNSW(Hierarchical Navigable Small World)基于分层图结构,能够在搜索时快速从稀疏层缩小范围,并在底层进行精细查找。其优势包括:高召回率,在语义检索中接近精确搜索效果;低延迟,查询复杂度接近 O(log n),适合大规模场景;可调节精度,通过
ef_search等参数动态控制召回率和延迟。HNSW 是业界应用最广泛的 ANN 索引,在 RAG、问答检索和相似度搜索等场景中至关重要。
IVF(Inverted File Index)通过聚类(如 k-means)将向量划分到不同分桶,仅在最相关的分桶中进行搜索。其构建速度快、资源占用低,适合百万至千万级的大规模向量库;可通过
nprobe控制召回率与查询速度的平衡。与 HNSW 相比,IVF 更适合于日志、埋点和商品向量等“规模大但查询精度可调”的场景。

5.2 支持多种向量查询模式
此外,Doris 支持多种高效向量查询模式,能够满足不同的搜索需求。下方将结合示例进行介绍:
A. Top-K 最近邻检索:支持 L2 距离与内积(Inner Product)两种相似度度量,快速找出与目标向量最相似的前 K 个结果。
SELECT id, inner_product_approximate(embedding,[0,11,77...]) as distance FROM sift_1M ORDER BY distance limit 10SELECT id, l2_distance_approximate(embedding,[0,11,77...]) as distance FROM sift_1M ORDER BY distance limit 10B. 近似范围查询(Range Search):支持对距离设置阈值条件,筛选出相似度在指定范围内的所有项。
SELECT count(*)FROM sift_1mWHERE l2_distance_approximate( embedding, [0,11,77,...]) > 300 C. 组合搜索:在同一条 SQL 中同时进行 ANN TopN 与 Range 条件过滤,返回满足范围约束的 TopN。
SELECT id, l2_distance_approximate( embedding, [0,11,77...]) as distFROM sift_1MWHERE l2_distance_approximate( embedding, [0,11,77...]) > 300ORDER BY dist limit 105.3 量化与编码机制
向量表示通常在维度和数据量上都非常庞大,带来了显著的计算和内存挑战,而量化与编码机制能够在性能、精度和成本之间达到最优平衡。目前 Doris 编码方式主要采用 FLAT 编码,HNSW 索引本身会占用较大内容,进行编码后必须全量驻留内存才能工作,尤其在超大规模数据集上易成为瓶颈。
对于该问题,量化可以很好的平衡。标量量化 SQ 通过压缩 FLOAT32 减少内存开销;乘积量化 PQ 通过分解高维向量并分别量化子向量来降低内存开销。
Doris 当前支持两种标量量化:INT8 与 INT4(SQ8 / SQ4),通过压缩 FLOAT32 减少内存开销。以 SQ8 为例:在 768 维的 Cohere-MEDIUM-1M 与 Cohere-LARGE-10M 数据集测试中,SQ8 可将索引大小压缩至 FLAT 的约 1/3。
Doris 也支持乘积量化, 通过分解高维向量并分别量化子向量来降低内存开销,PQ 量化可将索引大小压缩至 FLAT 的约 1/5 左右。需要注意的是在使用 PQ 时需要提供额外的参数(详见文档:https://doris.apache.org/zh-CN/docs/4.x/ai/vector-search/index-management)
6. HSAP 高效分析的关键
如果说上述能力是构成 HSAP 混合搜索能力的技术基础,那么如何让各模块高效的协同、运转也是一大核心所在。众所周知, Doris 一贯以实时、极速著称,那么 Doris 是如何提供高效混合搜索体验的呢?
6.1 前过滤性能优化
前过滤是混合检索常用的执行模型:先通过结构化谓词条件在大规模数据集中筛选候选行,然后对这些行进行相似度计算或打分。该模型的性能瓶颈在于:如果底层引擎无法支持海量数据的极速过滤,将会影响整体查询的效率。而 Doris 自身所具备的能力优势,能够很好的规避该问题。具体能力如下:
分区 / 分桶裁剪:从物理布局上缩小扫描范围。在查询计划生成阶段,优化器根据谓词条件自动完成分区与分桶裁剪,仅访问相关的 Tablet,从而减少每次查询需扫描的数据块,大幅降低系统负载。
索引加速过滤:Doris 采用多层索引体系,包括内置索引(zonemap、前缀索引以及排序键等)和二级索引(倒排索引、bloom filter 索引等),可在扫描前快速判定数据块是否命中查询条件,以跳过绝大多数无关数据。
Pipeline 与向量化执行模型:Doris 充分利用多核 CPU 并行和内存的局部性,在执行阶段提升算子吞吐与查询并发度,从根本上确保混合检索的高效执行。
6.2 虚拟列机制
在传统架构中,混合搜索中的文本搜索打分函数和向量搜索相似度计算函数会在上层聚合节点和下层扫描节点重复计算,而在 Doris 4.0 中创新性的引入虚拟列机制,优化了这一过程。
具体而言,FE 规划时将打分以及距离计算等函数映射为虚拟列,并将虚拟列的计算下推到扫描节点。扫描节点在索引过滤阶段直接计算这些虚拟列结果,并填充到最终结果中。在该过程中,上层仅需做结果融合与排序,显著降低 CPU 消耗与数据传输。
6.3 TopN 延迟物化
文本搜索打分函数和向量搜索相似度计算函数都是SELECT yyy FROM tableX ORDER BY xxx ASC/DESC LIMIT N 这种典型的 TopN 查询模式,当数据规模庞大时,传统执行方式需对全表数据进行扫描并排序,这会导致大量不必要的数据读取,引发读放大问题。
为解决这一问题,Doris 引入延迟物化机制,将 TopN 查询拆解为两阶段高效执行:第一阶段仅读取排序字段(columnA)与用于定位数据的主键 / 行标识,通过排序快速筛选出符合 LIMIT N 条件的目标行;第二阶段再基于行标识精准读取目标行的所有列数据。该方案能大幅削减非必要列的读取量,在宽表小 LIMIT 场景下,TopN 查询的执行效率有数十倍的提升。
7. 最佳实践
为了验证 Apache Doris 在真实业务数据上的混合搜索性能,我们基于公开的 Hacker News 数据集进行了性能测试。该数据集涵盖多维、文本和向量分析三种类型,是检验 Doris HSAP 统一引擎特性的权威样本。
测试方式
在 AWS 环境构建一个完整的端到端测试,从数据加载到 RRF 融合查询,完整验证 Doris 在语义搜索、文本搜索与结构化过滤三合一场景下的性能表现。
硬件环境
AWS EC2 实例:
m6i.8xlarge(32 vCPU,128 GiB 内存)单节点部署 Apache Doris 4.0.1 版本
数据集
数据源:Hacker News 公开数据集
数据规模:2874 万条记录
向量维度:384 维(由 all-MiniLM-L6-v2 模型生成)
字段类型举例:文本(
text,title)、结构化(time,post_score)、向量(vector)
7.1 建表与索引设计
Doris 允许在同一张表中定义倒排索引与向量索引,从而实现“文本 + 向量 + 结构化”查询的无缝结合。
CREATE TABLE hackernews ( id INT NOT NULL, text STRING, title STRING, vector ARRAY<FLOAT> NOT NULL, time DATETIME, post_score INT, dead TINYINT, deleted TINYINT, INDEX ann_vector (`vector`) USING ANN PROPERTIES ( "index_type"="hnsw", "metric_type"="l2_distance", "dim"="384", "quantizer"="flat", "ef_construction"="512" ), INDEX text_idx (`text`) USING INVERTED PROPERTIES("parser"="english", "support_phrase"="true"), INDEX title_idx (`title`) USING INVERTED PROPERTIES("parser"="english", "support_phrase"="true"))ENGINE=OLAPDUPLICATE KEY(`id`)DISTRIBUTED BY HASH(`id`) BUCKETS 4PROPERTIES("replication_num"="1");text,title字段用于全文搜索,创建英文分词类型的倒排索引vector字段用于 ANN 搜索,创建向量索引"index_type"="hnsw":采用 HNSW 算法。"dim"="384":必须与 all-MiniLM-L6-v2 模型输出维度严格一致。"quantizer"="flat":指定使用flat(浮点)进行量化,确保了最高的召回精度。在对内存占用更敏感的场景下,可替换为sq8(标量量化)。"ef_construction"="512":在索引构建阶段设置较高的搜索上界(512),意味着在构建时投入更多资源,以建立一个连接更充分、质量更高的图结构,从而为后续查询提供更高的召回率。
7.2 数据导入
使用 Doris INSERT INTO ... FROM local() 功能,直接从本地磁盘加载 Parquet 文件,实现数据导入。
INSERT INTO hackernewsSELECT id, doc_id, `text`, `vector`, CAST(`node_info` AS JSON) AS nodeinfo, metadata, CAST(`type` AS TINYINT), `by`, `time`, `title`, post_score, CAST(`dead` AS TINYINT), CAST(`deleted` AS TINYINT), `length`FROM local( "file_path" = "hackernews_part_1_of_1.parquet", "backend_id" = "1762257097281", -- 需替换为实际的 BE 节点 ID "format" = "parquet");7.3 RRF 融合查询
以下是一段 Doris 通过 SQL 实现 RRF 算法,将文本搜索和向量搜索的结果进行融合的示例查询。
WITH text_raw AS ( SELECT id, score() AS bm25 FROM hackernews WHERE (`text` MATCH_PHRASE 'hybird search' OR `title` MATCH_PHRASE 'hybird search') AND dead = 0 AND deleted = 0 ORDER BY score() DESC LIMIT 1000 ), vec_raw AS ( SELECT id, l2_distance_approximate(`vector`, [0.12, 0.08, ...]) AS dist FROM hackernews ORDER BY dist ASC LIMIT 1000 ), text_rank AS ( SELECT id, ROW_NUMBER() OVER (ORDER BY bm25 DESC) AS r_text FROM text_raw ), vec_rank AS ( SELECT id, ROW_NUMBER() OVER (ORDER BY dist ASC) AS r_vec FROM vec_raw ), fused AS ( SELECT id, SUM(1.0/(60 + rank)) AS rrf_score FROM ( SELECT id, r_text AS rank FROM text_rank UNION ALL SELECT id, r_vec AS rank FROM vec_rank ) t GROUP BY id ORDER BY rrf_score DESC LIMIT 20 )SELECT f.id, h.title, h.text, f.rrf_scoreFROM fused f JOIN hackernews h ON h.id = f.idORDER BY f.rrf_score DESC;执行流程说明:
并行召回:倒排索引与 ANN 索引分别执行 BM25 与 L2 距离召回
局部排序:各自计算内部排名
融合打分:执行 RRF 公式
1/(k+rank),融合文本与语义结果最终回表:仅对 Top-K 结果 JOIN 原表获取正文。
7.4 实际查询测试
在相同的环境下,正式对 Apache Doris 的混合搜索性能进行了测试。在这一测试中,使用了 hybrid search 作为关键词,进行了文本召回+向量召回+ RRF 融合。结果显示,查询延迟仅为 65.83 毫秒,体现了系统对复杂查询的高效处理能力。
==================================================================================================================================id | title | rrf_score | text_snippet ----------------------------------------------------------------------------------------------------------------------------------845652 | Google Bing Hybrid Search - badabingle | 0.026010 | beendonebefore: thenewguy: Sure it steals google an...2199216 | | 0.017510 | citricsquid:FYI DDG just uses the bing API and then ...2593213 | Ask HN:Why there's no Regular Expression search... | 0.016390 | bluegene: What's keeping Google/other search engines...6931880 | Introducing Advanced Search | 0.016390 | mecredis: 3038364 | Bing Using Adaptive Search | 0.016120 | brandignity: 1727739 | | 0.016120 | pavs:I think the name is the only thing that is wron...18453472 | AdaSearch: A Successive Elimination Approach to... | 0.015870 | jonbaer: 1727788 | | 0.015870 | epi0Bauqu:It's a hybrid engine. I do my own crawling...2390509 | Reinventing the classic search model | 0.015620 | justnearme: 2199325 | | 0.015380 | epi0Bauqu:FYI: no, actually we are a hybrid search e...26328758 | Brave buys a search engine, promises no trackin... | 0.015150 | samizdis: jerf: "The service will, eventually,...325246 | Future of Search Won’t Be Incremental | 0.015150 | qhoxie: 3067986 | Concept-Based Search - Enter the Interllective | 0.014920 | hendler: 3709259 | Google Search: Change is Coming | 0.014920 | Steveism: victork2: Well Google, a word of warning ...10009267 | Hulbee – A Safe, Smart, Innovative Search Engine | 0.014700 | doener: captaincrunch: My previous comment didn...1119177 | Elastic Search - You Know, for Search | 0.014700 | yungchin: 4485350 | | 0.014490 | ChuckMcM:Heh, perhaps.<p>DDG is a great product, we ...23476454 | | 0.014490 | Multicomp:AstroGrep! ronjouch: BareGrep! For live&#x...7381459 | HTML5 Incremental Search | 0.014280 | ultimatedelman: 4485488 | | 0.014280 | epi0Bauqu:Hmm, we're (DDG) not a search engine? Come...==================================================================================================================================结束语
综上所述,Apache Doris 在复杂、高维的混合搜索场景中的优异表现,充分证明其以在 AI 时代数据基础设施解决方案中占据一席之地。其统一的 HSAP 架构从根本上满足了 Agent 对多模态数据分析,应具备全面性、语义的精确性以及流程的可控性的需求。




