
最近,Pinterest公开了其内部编排框架 Hadoop Control Center(HCC)。他们使用这个框架来自动化其大规模 Hadoop 集群的扩展和迁移,解决了在亚马逊云科技云上管理数十个YARN集群中的数千个节点时面临的运营复杂性和限制。
历史上,Pinterest 为其 Hadoop 基础设施维护固定大小的自动扩展组(ASG)。这种配置虽然安全,但实际上把自动扩展给禁用了。手动调整集群大小,特别是缩减,需要通过 Terraform 进行,而且需要大量的人工干预。这个过程会涉及安全地排空和退役节点等复杂的操作,同时还要避免对使用MapReduce、Spark和Flink的批处理工作负载造成干扰。整个过程既耗时又容易出错,常常导致基础设施重复和资源浪费。
HCC 的引入将这种手动工作流转变为一个完全自动化的系统,可以实时管理 Hadoop 集群大小调整和节点迁移。现在,操作员可以通过一个统一的命令行界面请求进行扩展操作。在后台,HCC 与亚马逊云科技的服务和 Hadoop 组件协调交互,确保节点安全退役、数据完整性和服务连续性。
HCC 的核心是分布在 Pinterest 虚拟私有云(VPC)中的一个 manager-worker 架构。每个 VPC 运行一个管理节点,它缓存集群状态并将操作委托给工作节点。这些工作节点与一个名为 Hadoop 管理器类(HMC)的自定义组件交互,该组件协调节点的逐步退役和扩展。HMC 通过 JMX 监控关键集群指标,更新配置文件,调用亚马逊云科技的 API,并调度内部线程以处理排空、终止和清理操作。
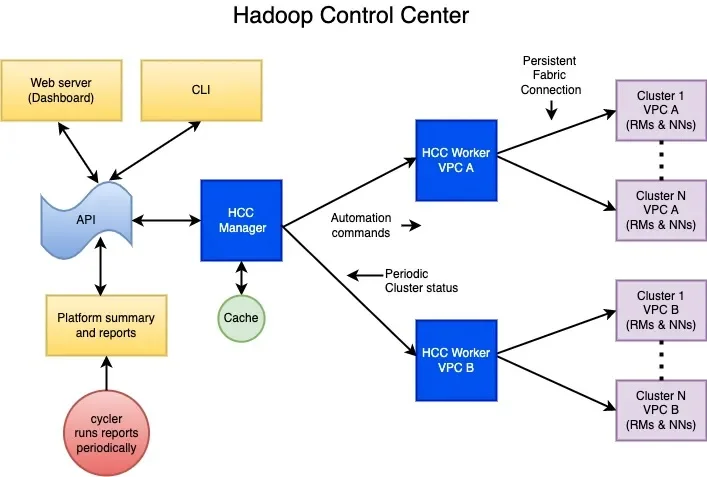
HCC 逻辑架构
HCC 的一个关键特性是能够在原地升级期间安全地迁移节点。Pinterest 工程师不是部署使用新配置的并行绿色集群,而是使用更新后的实例类型启动一个 ASG 或是启动一个AMI,并允许 HCC 将这些新节点整合到现有的集群中。然后,HCC 开始从旧的 ASG 中排空数据和工作负载,监控 Shuffle 和 HDFS 复制完成,并以受控的方式移除退役实例。这种方法可以最小化成本,避免基础设施重复,并且不需要每次迁移时重新配置容量或 IP 空间。
此外,该系统在实例级别管理 ASG 缩减保护,确保亚马逊云科技云不会随机终止尚未准备好移除的 Hadoop 节点。成功退役后,HCC 会将节点从集群中移除,并更新相关的 Terraform 变量,以便保持配置一致性,并避免在将来的基础设施变更中出现漂移。
虽然 HCC 显著提高了运营效率,但 Pinterest 还在设法扩展其能力。他们计划添加自修复功能,用于处理亚马逊云科技云检测到的不健康节点,启用基于操作系统年龄或 AMI 版本的生命周期轮换,并整合亚马逊云科技的事件触发器以实现更智能的节点管理。这些增强旨在提升 Pinterest Hadoop 基础设施的自主性和弹性。
转向 HCC 使 Pinterest 能够按需扩展其数据处理平台,降低人为错误的风险,并安全地执行原地迁移,最小化停机时间或对应用程序的影响。随着云中数据基础设施动态性和弹性的日益增加,Pinterest 的方法为用现代自动化原理管理 Hadoop 等有状态系统提供了一个令人信服的蓝图。
另一家科技巨头 Uber介绍了他们将庞大的基于 Hadoop 的批处理分析技术栈转移到 Google Cloud Platform 的分阶段策略。该技术栈管理着高达艾字节的数据和数万台服务器。最初,Uber 将核心组件迁移到了基于 GCP 的基础架构即服务上,为的是尽可能地减少复制本地环境可能造成的干扰。随后,团队按计划逐步采用了 Dataproc、BigQuery 和 Google Cloud Storage 等托管服务,以及 Spark、Hive 和 Presto 的云原生抽象和反向兼容代理。Uber 的分层方法将对客户端的影响降到了最低,同时在云中启用了一个可扩展的现代化弹性平台。
这两个案例凸显了一个共同的范式:通过精心设计的编排、复制和兼容性工具,大规模 Hadoop 系统可以安全地迁移或现代化,并且停机时间最小化。
声明:本文为 InfoQ 翻译,未经许可禁止转载。
原文链接:
https://www.infoq.com/news/2025/07/pinterest-hadoop-cluster/




