
我要先声明通常的基准测试警告:42% 的加速是在我的计算机上运行程序的数据时测量的,所以大家对这个数字请持保留态度。
这个 Go 程序是做什么的?
codeowners 是一个 Go 程序,它根据 GitHub CODEOWNERS 文件中定义的一系列规则,打印出存储库中每个文件的所有者。可能有这样的规则:所有以 .go 结尾的文件都归 @gophers 团队所有,或者 docs/ 目录下的所有文件都归 @docs 团队所有。
当考虑一个给定的路径时,最后匹配的规则获胜。一个简单但天真的匹配算法会向后迭代每条路径的规则,当找到匹配时就会停止。智能算法确实存在,但那是以后的事了。Ruleset.Match 函数如下所示:
type Ruleset []Rulefunc (r Ruleset) Match(path string) (*Rule, error) { for i := len(r) - 1; i >= 0; i-- { rule := r[i] match, err := rule.Match(path) if match || err != nil { return &rule, err } } return nil, nil}用 pprof 和 flamegraph 查找“slow bits”
当在一个中等规模的存储库中运行该工具时,它的运行速度有点慢:
$ hyperfine codeownersBenchmark 1: codeowners Time (mean ± σ): 4.221 s ± 0.089 s [User: 5.862 s, System: 0.248 s] Range (min … max): 4.141 s … 4.358 s 10 runs为了了解程序将时间花在哪里,我用 pprof 记录了一个 CPU 配置文件。你可以通过将以下代码片段添加到 main 函数的顶部来获得生成的 CPU 配置文件:
pprofFile, pprofErr := os.Create("cpu.pprof")if pprofErr != nil { log.Fatal(pprofErr)}pprof.StartCPUProfile(pprofFile)defer pprof.StopCPUProfile()题外话:我经常使用 pprof,所以我将这段代码保存为 vscode 代码片段。我只要输入 pprof,点击 tab,就会出现这个代码片段。
Go 附带了一个方便的交互式配置文件可视化工具。通过运行以下命令,然后导航到页面顶部菜单中的火焰图视图,将配置文件可视化为火焰图。
$ go tool pprof -http=":8000" ./codeowners ./cpu.pprof正如我所料,大部分时间都花在了 Match 函数上。CODEOWNERS 模式被编译成正则表达式,Match 函数的大部分时间都花在 Go 的正则表达式引擎中。但是我也注意到,很多时间都花在了分配和回收内存上。下面的火焰图中的紫色块与模式 gc|malloc 相匹配,你可以看到它们在总体上表示程序执行时间的一个有意义的部分。
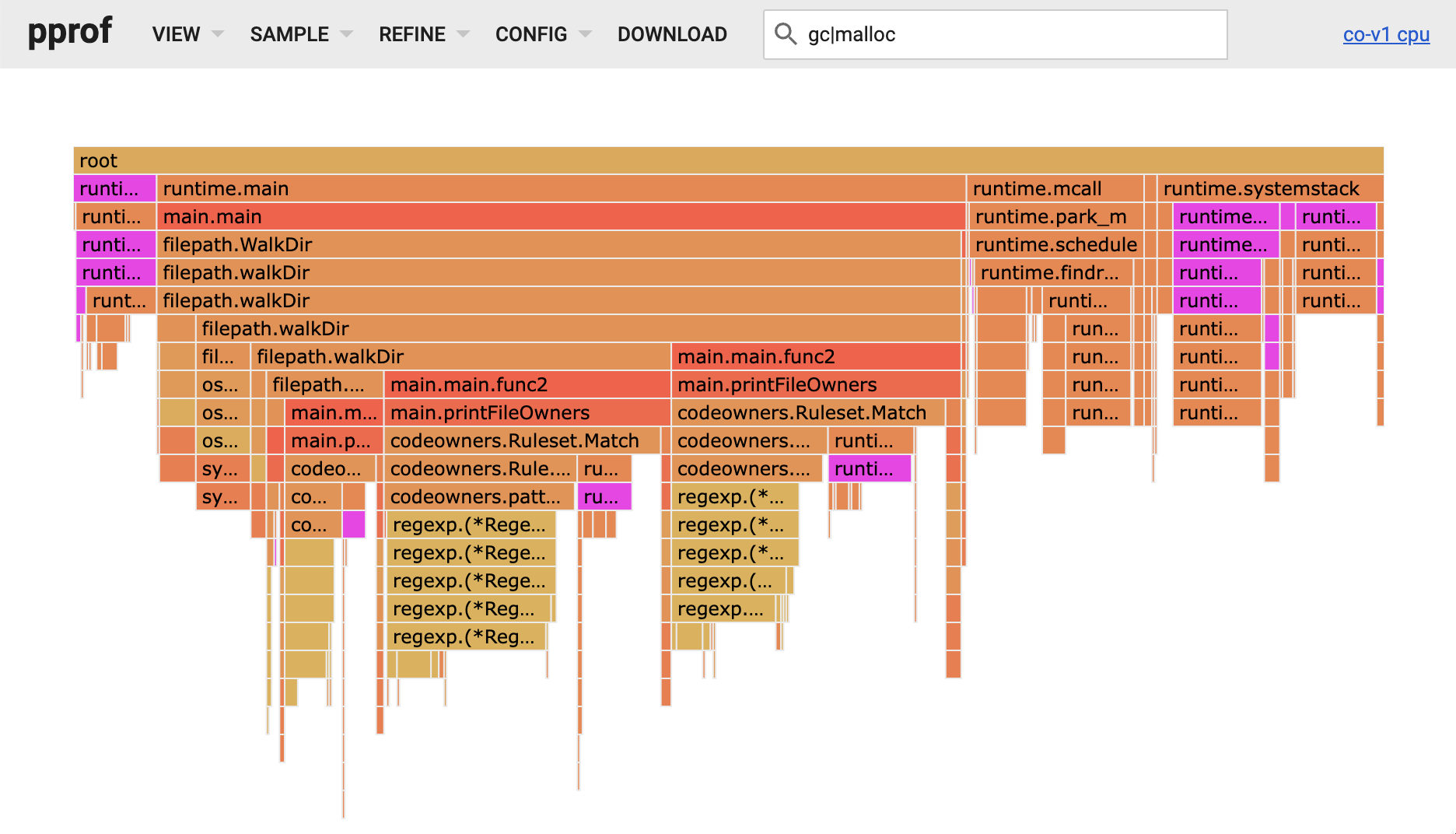
使用逃逸分析跟踪搜寻堆分配
因此,让我们看看是否有任何分配可以消除,以减少 GC 的压力和在 malloc 花费的时间。
Go 编译器使用一种叫做逃逸分析(escape analysis)的技术来计算出何时需要在堆上驻留一些内存。假设一个函数初始化了一个结构,然后返回一个指向它的指针。如果该结构是在堆栈中分配的,那么一旦函数返回,并且相应的堆栈框架失效,返回的指针就会失效。在这种情况下,Go 编译器将确定该指针已经“逃离”了函数,并将该结构移至堆中。
你可以通过向 go build 传递 -gcflags=-m 来看到这些决定:
$ go build -gcflags=-m *.go 2>&1 | grep codeowners.go./codeowners.go:82:18: inlining call to os.IsNotExist./codeowners.go:71:28: inlining call to filepath.Join./codeowners.go:52:19: inlining call to os.Open./codeowners.go:131:6: can inline Rule.Match./codeowners.go:108:27: inlining call to Rule.Match./codeowners.go:126:6: can inline Rule.RawPattern./codeowners.go:155:6: can inline Owner.String./codeowners.go:92:29: ... argument does not escape./codeowners.go:96:33: string(output) escapes to heap./codeowners.go:80:17: leaking param: path./codeowners.go:70:31: []string{...} does not escape./codeowners.go:71:28: ... argument does not escape./codeowners.go:51:15: leaking param: path./codeowners.go:105:7: leaking param content: r./codeowners.go:105:24: leaking param: path./codeowners.go:107:3: moved to heap: rule./codeowners.go:126:7: leaking param: r to result ~r0 level=0./codeowners.go:131:7: leaking param: r./codeowners.go:131:21: leaking param: path./codeowners.go:155:7: leaking param: o to result ~r0 level=0./codeowners.go:159:13: "@" + o.Value escapes to heap输出有点嘈杂,但你可以忽略其中的大部分。由于我们正在寻找分配,“move to heap”是我们应该关注的短语。回顾上面的 Match 代码,Rule 结构被存储在 Ruleset 片中,我们可以确信它已经在堆中了。由于返回的是一个指向规则的指针,所以不需要额外的分配。
然后我看到了--通过分配 rule := r[i],我们将堆中分配的 Rule 从片中复制到堆栈中,然后通过返回 &rule,我们创建了一个指向结构副本的(逃逸)指针。幸运的是,解决这个问题很容易。我们只需要将 & 号往上移一点,这样我们就引用了片中的结构,而不是复制它:
func (r Ruleset) Match(path string) (*Rule, error) { for i := len(r) - 1; i >= 0; i-- {- rule := r[i]+ rule := &r[i] match, err := rule.Match(path) if match || err != nil {- return &rule, err+ return rule, err } } return nil, nil }我确实考虑过另外两种方法:
将 Ruleset 从 []Rule 更改为 []*Rule,这意味着我们不再需要显式引用该规则。
返回 Rule 而不是 *Rule。这仍然会复制 Rule,但它应该保留在堆栈上,而不是移动到堆上。
然而,由于此方法是公共 API 的一部分,这两种方法都会导致一个重大的变化。
无论如何,在做了这个修改之后,我们可以通过从编译器获得一个新的跟踪并将其与旧的跟踪进行比较来看看它是否达到了预期的效果:
$ diff trace-a trace-b14a15> ./codeowners.go:105:7: leaking param: r to result ~r0 level=016d16< ./codeowners.go:107:3: moved to heap: rule成功了!分配消失了。现在让我们看看删除一个堆分配会如何影响性能:
$ hyperfine ./codeowners-a ./codeowners-bBenchmark 1: ./codeowners-a Time (mean ± σ): 4.146 s ± 0.003 s [User: 5.809 s, System: 0.249 s] Range (min … max): 4.139 s … 4.149 s 10 runsBenchmark 2: ./codeowners-b Time (mean ± σ): 2.435 s ± 0.029 s [User: 2.424 s, System: 0.026 s] Range (min … max): 2.413 s … 2.516 s 10 runsSummary ./codeowners-b ran 1.70 ± 0.02 times faster than ./codeowners-a由于该分配是针对匹配的每一条路径进行的,因此在这种情况下,删除它会获得 1.7 倍的速度提升(这意味着它的运行速度要快 42%)。对一个字符的变化来说还不错。
作者简介:
Harry,在 GitHub 工作,负责领导团队为开发人员开发安全产品。Dependabot 共同创始人之一。
原文链接:
https://hmarr.com/blog/go-allocation-hunting/#circle=on
推荐阅读:




