
2026 年,智能体将在企业级应用中取得哪些实质性突破?点击下载《2026 年 AI 与数据发展预测》白皮书,获悉专家一手前瞻,抢先拥抱新的工作方式!
现代数据架构越来越要求事务型与分析型工作负载能够无缝共存。PostgreSQL 仍然是事务型应用的核心基础设施——支撑电商订单处理、实时库存系统以及面向客户的 API——而 Snowflake 则是所有分析型数据与 AI 的基础平台。挑战在于:如何让数据在这两个系统之间双向可靠流动,同时将延迟与运维开销降到最低。
历史上,要打通 OLTP 与 OLAP 系统,需要拼接外部 ETL 工具、管理云存储桶、配置 IAM 角色,并维护脆弱的 CDC 数据管道。团队花在基础设施“打通”上的时间,往往超过从数据中产生价值的时间。
本文的目标是探索如何利用 Snowflake 的一些最新创新能力,在 Postgres 与 Snowflake 之间支持五种关键的数据流动模式。如下所示:

有哪些变化?
近期 Snowflake 的一些产品能力显著简化了这一问题:
Snowflake Postgres(PuPr):一种完全托管的 PostgreSQL 服务,原生运行在 Snowflake 生态系统中。它消除了外部 PostgreSQL 托管的需求,同时与 Snowflake 数据平台实现一流集成;
pg_lake(PuPr):PostgreSQL 的扩展能力,允许在 Postgres 内直接创建 Apache Iceberg 表。在 Postgres 中写入的数据,可以通过共享 Iceberg 元数据被 Snowflake 直接查询——无需文件导出、无需中转存储、无需 ETL 管道;
pg_incremental(PuPr):用于调度式增量同步的扩展组件。与 pg_lake 结合使用时,可以实现轻量级 CDC,只同步发生变化的数据行;
Snowflake 托管 Iceberg 存储(PuPr):Postgres 管理的 Iceberg 表使用 Snowflake 内部存储,并通过托管凭证访问。无需外部 S3、无需 IAM、无需存储集成配置;
Openflow(正式发布):Snowflake 的托管数据集成平台(基于 Apache NiFi 构建),提供预置的 CDC 连接能力,包括基于 PostgreSQL WAL 的变更捕获,以及通过 Snowpipe Streaming 进行数据传输。
这些能力共同构建了一个完整的数据流动能力体系——从简单的批量加载,到实时 CDC——全部在一个统一平台内完成。
本文中的所有模式都使用 ORDERS 表作为示例数据源。该表模拟典型电商订单生命周期,约 28,000 行数据。本例中数据来源于 SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.Orders。
CREATE TABLE cdc_demo.orders ( order_id BIGINT PRIMARY KEY, customer_id BIGINT, order_status VARCHAR(1), total_price DECIMAL(15,2), order_date DATE, order_priority VARCHAR(15), clerk VARCHAR(15), ship_priority INTEGER, comment VARCHAR(79), created_at TIMESTAMP DEFAULT NOW(), updated_at TIMESTAMP DEFAULT NOW());模式 1:批量数据流动 —— Postgres 到 Snowflake
业务场景:某零售公司在 PostgreSQL 电商系统中全天处理订单。每天夜间,分析团队需要在 Snowflake 中获取所有订单的完整快照,用于报表分析、需求预测以及财务对账;
技术方案:在 Postgres 中创建 Iceberg 表。“USING Iceberg”子句允许 pg_lake 在 Postgres 内创建并写入 Iceberg 表。然后通过 INSERT/SELECT 将订单数据写入该表。
在 Snowflake 侧,创建目录集成(Catalog Integration)后再创建 Iceberg 表。这些操作属于元数据层操作,不涉及实际数据搬运。当 Iceberg 表创建完成后,即可在 Snowflake 中直接查询。
步骤 1:在 Postgres 中启用 pg_lake
-- Connect to Snowflake Postgres instanceCREATE EXTENSION IF NOT EXISTS pg_lake CASCADE;步骤 2:创建 Iceberg 表并批量加载数据
-- Create an Iceberg table and bulk load all orders into itCREATE TABLE cdc_demo.orders_iceberg ( order_id BIGINT, customer_id BIGINT, order_status VARCHAR(1), total_price DECIMAL(15,2), order_date DATE, order_priority VARCHAR(15), clerk VARCHAR(15), ship_priority INTEGER, comment VARCHAR(79), created_at TIMESTAMP, updated_at TIMESTAMP) USING iceberg;-- Bulk load from the source tableINSERT INTO cdc_demo.orders_icebergSELECT * FROM cdc_demo.orders;步骤 3:在 Snowflake 中创建目录集成
-- In Snowflake: create a catalog integration pointing to the Postgres instanceCREATE OR REPLACE CATALOG INTEGRATION pg_orders_catalog CATALOG_SOURCE = SNOWFLAKE_POSTGRES TABLE_FORMAT = ICEBERG CATALOG_NAMESPACE = 'cdc_demo' REST_CONFIG = ( POSTGRES_INSTANCE = 'Snowflake_Postgres_Demo' CATALOG_NAME = 'postgres' ACCESS_DELEGATION_MODE = VENDED_CREDENTIALS ) ENABLED = TRUE;步骤 4:在 Snowflake 创建 Iceberg 表
-- Create the Snowflake Iceberg table referencing the Postgres-managed Iceberg dataCREATE OR REPLACE ICEBERG TABLE orders_iceberg CATALOG = 'pg_orders_catalog' CATALOG_TABLE_NAME = 'orders_iceberg' CATALOG_NAMESPACE = 'cdc_demo' AUTO_REFRESH = TRUE;步骤 5:查询验证数据
SELECT COUNT(*) FROM orders_iceberg;SELECT order_status, COUNT(*), SUM(total_price) AS total_revenueFROM orders_icebergGROUP BY order_status;模式 2:批量数据流动 —— Snowflake 到 Postgres
业务场景:数据科学团队在 Snowflake 中构建订单优先级预测模型,结果需要回写到 Postgres,使业务系统能够实时展示预测结果;
技术方案:在 Snowflake 中生成结果表后,将数据写入 stage(Parquet 文件)。Postgres 从 stage 拉取数据并写入本地表。

步骤 1:创建存储集成
-- In Snowflake: create a storage integration for the Postgres managed storageCREATE OR REPLACE STORAGE INTEGRATION pg_stage_integration TYPE = POSTGRES_INTERNAL_STORAGE POSTGRES_INSTANCE = 'Snowflake_Postgres_Demo';-- Create a stage using this integrationCREATE OR REPLACE STAGE pg_orders_stage RELATIVE_URL = '/orders_export' STORAGE_INTEGRATION = pg_stage_integration;步骤 2:导出数据到 stage
COPY INTO @pg_orders_stage/orders_bulk_FROM ( SELECT order_id, customer_id, order_status, total_price, order_date, order_priority, clerk, ship_priority, comment FROM orders_iceberg)FILE_FORMAT = (TYPE = PARQUET)HEADER = TRUEOVERWRITE = TRUE;步骤 3:Postgres 读取数据
-- On Postgres: create the destination tableCREATE TABLE cdc_demo.orders_from_snowflake ( order_id BIGINT PRIMARY KEY, customer_id BIGINT, order_status VARCHAR(1), total_price DECIMAL(15,2), order_date DATE, order_priority VARCHAR(15), clerk VARCHAR(15), ship_priority INTEGER, comment VARCHAR(79));-- Load the Parquet files from the stage into the Postgres tableCOPY cdc_demo.orders_from_snowflakeFROM '@STAGE/orders_export/orders_bulk_*.parquet';步骤 4:查询验证
SELECT COUNT(*) FROM cdc_demo.orders_from_snowflake;-- Returns: 28,373SELECT order_status, COUNT(*)FROM cdc_demo.orders_from_snowflakeGROUP BY order_status;模式 3:CDC —— 从 Postgres 到 Snowflake
业务场景:一个电商应用持续处理新订单、更新订单状态(已发货、已送达、已退货)以及取消订单。分析团队需要在几分钟内将这些变化同步到 Snowflake,而不是等待数小时,以支持展示订单履约指标与营收追踪的实时仪表盘;
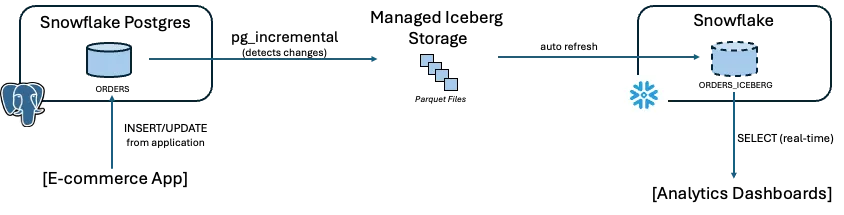
技术方案:这代表典型的 OLTP → OLAP 模式,即在源数据库中检测数据变更,并将其传递到分析系统。在该模式中,Postgres 源表上的插入与更新操作会被捕获。系统每分钟检测一次变更,并将其写入 Iceberg 表。在 Snowflake 侧,会创建 catalog integration 和 Iceberg 表,并通过每分钟一次的 REFRESH 进行轮询,从而使最新变更可以被查询访问。
步骤 1:在 Postgres 上启用 pg_incremental 和 pg_cron
CREATE EXTENSION IF NOT EXISTS pg_cron;CREATE EXTENSION IF NOT EXISTS pg_incremental CASCADE;步骤 2:创建 Iceberg 目标表并执行初始批量加载
-- Create an Iceberg table for CDC dataCREATE TABLE cdc_demo.orders_iceberg_cdc ( order_id BIGINT, customer_id BIGINT, order_status VARCHAR(1), total_price DECIMAL(15,2), order_date DATE, order_priority VARCHAR(15), clerk VARCHAR(15), ship_priority INTEGER, comment VARCHAR(79), updated_at TIMESTAMP) USING iceberg;-- Initial bulk load of current dataINSERT INTO cdc_demo.orders_iceberg_cdcSELECT order_id, customer_id, order_status, total_price, order_date, order_priority, clerk, ship_priority, comment, updated_atFROM cdc_demo.orders;步骤 3:创建时间间隔 pipeline,用于检测并同步变更
-- Create a pg_incremental pipeline that runs every minute-- Uses the updated_at column to detect rows modified within each time intervalSELECT incremental.create_time_interval_pipeline( 'sync_orders_cdc', '1 minute'::interval, 'INSERT INTO cdc_demo.orders_iceberg_cdc SELECT order_id, customer_id, order_status, total_price, order_date, order_priority, clerk, ship_priority, comment, updated_at FROM cdc_demo.orders WHERE updated_at >= $1 AND updated_at < $2', source_table_name := 'cdc_demo.orders'::regclass, schedule := '* * * * *');该 pipeline 会自动执行以下操作:
每分钟通过 pg_cron 运行一次;
检测 updated_at 落在当前时间区间内的行;
将发生变化的数据追加写入 Iceberg 表;
维护高水位线(last_processed_time),以实现高效处理;
可以通过 CALL incremental.execute_pipeline('sync_orders_cdc') 手动触发。
步骤 4:在 Snowflake 中创建 Iceberg 表并启用自动刷新
-- On Snowflake: create Iceberg table referencing the CDC Iceberg dataCREATE OR REPLACE ICEBERG TABLE orders_iceberg_cdc CATALOG = 'pg_orders_catalog' CATALOG_TABLE_NAME = 'orders_iceberg_cdc' CATALOG_NAMESPACE = 'cdc_demo' AUTO_REFRESH = TRUE;-- Configure polling frequency (how often Snowflake checks for new Iceberg snapshots)ALTER CATALOG INTEGRATION pg_orders_catalog SET REFRESH_INTERVAL_SECONDS = 60;步骤 5:在 Postgres 中模拟数据变更
-- On Postgres: simulate order changesUPDATE cdc_demo.ordersSET order_status = 'X', total_price = 1.00, updated_at = NOW()WHERE order_id IN (SELECT order_id FROM cdc_demo.orders LIMIT 3);INSERT INTO cdc_demo.orders (order_id, customer_id, order_status, total_price, order_date, order_priority, clerk, ship_priority, comment, created_at, updated_at)VALUES (9999999, 30016, 'N', 999.99, CURRENT_DATE, '1-URGENT', 'Clerk#000000001', 0, 'Test CDC order', NOW(), NOW());-- Manually trigger the pipeline (or wait for pg_cron to run it)CALL incremental.execute_pipeline('sync_orders_cdc');步骤 6:在 Snowflake 中查询 / 验证数据
-- On Snowflake (after auto-refresh or manual refresh):ALTER ICEBERG TABLE orders_iceberg_cdc REFRESH;SELECT * FROM orders_iceberg_cdc WHERE order_id = 9999999;-- Returns the newly inserted order模式 4:CDC —— 从 Snowflake 到 Postgres
业务场景:一个集中式定价引擎在 Snowflake 中重新计算订单优先级,并基于库存水平、需求预测以及促销活动进行动态价格调整。这些重新计算后的结果需要回流到生产环境的 Postgres 数据库,从而使履约系统能够据此进行订单路由;
技术方案:在该场景中,我们使用 STREAM 来检测 Snowflake 中 ORDERS_ENRICHED 表的变更。该 STREAM 会在 TASK 中被引用,并且该 TASK 每 5 分钟触发一次,将变更数据复制到 stage 中并以 Parquet 文件形式存储。在 Postgres 端,这些变更会被 COPY 到 staging 表中,并最终通过 INSERT、UPDATE 或 DELETE 的方式应用到目标表。

步骤 1:在 Snowflake 中创建源表并启用变更追踪
-- Create a table in Snowflake that the pricing engine updatesCREATE OR REPLACE TABLE orders_enriched ( order_id NUMBER(38,0) PRIMARY KEY, customer_id NUMBER(38,0), order_status VARCHAR(1), total_price NUMBER(15,2), order_date DATE, order_priority VARCHAR(15), clerk VARCHAR(15), ship_priority NUMBER(38,0), comment VARCHAR(79), updated_at TIMESTAMP_NTZ DEFAULT CURRENT_TIMESTAMP());-- Populate with initial dataINSERT INTO orders_enrichedSELECT order_id, customer_id, order_status, total_price, order_date, order_priority, clerk, ship_priority, comment, CURRENT_TIMESTAMP()FROM orders_iceberg;-- Create a stream to capture changesCREATE OR REPLACE STREAM orders_enriched_stream ON TABLE orders_enriched SHOW_INITIAL_ROWS = FALSE;步骤 2:创建一个将变更导出到 Postgres stage 的任务
-- Create a task that runs every 5 minutes when changes are detectedCREATE OR REPLACE TASK export_order_changes_to_pg WAREHOUSE = COMPUTE_WH SCHEDULE = '5 MINUTE' WHEN SYSTEM$STREAM_HAS_DATA('orders_enriched_stream')AS COPY INTO @pg_orders_stage/cdc_changes/changes_ FROM ( SELECT order_id, customer_id, order_status, total_price, order_date, order_priority, clerk, ship_priority, comment, METADATA$ACTION AS change_action, METADATA$ISUPDATE AS is_update, updated_at FROM orders_enriched_stream ) FILE_FORMAT = (TYPE = PARQUET) OVERWRITE = TRUE;-- Resume the taskALTER TASK export_order_changes_to_pg RESUME;步骤 3:将变更数据加载到 Postgres
-- On Postgres: create a staging table for incoming changesCREATE TABLE cdc_demo.orders_changes_staging ( order_id BIGINT, customer_id BIGINT, order_status VARCHAR(1), total_price DECIMAL(15,2), order_date DATE, order_priority VARCHAR(15), clerk VARCHAR(15), ship_priority INTEGER, comment VARCHAR(79), change_action TEXT, is_update BOOLEAN, updated_at TIMESTAMP);-- Load changes from the stageCOPY cdc_demo.orders_changes_stagingFROM '@STAGE/orders_export/cdc_changes/changes_*.parquet';-- Apply changes using UPSERT logic (INSERT ... ON CONFLICT)INSERT INTO cdc_demo.orders_from_snowflake (order_id, customer_id, order_status, total_price, order_date, order_priority, clerk, ship_priority, comment)SELECT order_id, customer_id, order_status, total_price, order_date, order_priority, clerk, ship_priority, commentFROM cdc_demo.orders_changes_stagingWHERE change_action = 'INSERT'ON CONFLICT (order_id) DO UPDATE SET customer_id = EXCLUDED.customer_id, order_status = EXCLUDED.order_status, total_price = EXCLUDED.total_price, order_date = EXCLUDED.order_date, order_priority = EXCLUDED.order_priority, clerk = EXCLUDED.clerk, ship_priority = EXCLUDED.ship_priority, comment = EXCLUDED.comment;-- Handle true deletes (not part of an update pair)DELETE FROM cdc_demo.orders_from_snowflakeWHERE order_id IN ( SELECT order_id FROM cdc_demo.orders_changes_staging WHERE change_action = 'DELETE' AND is_update = FALSE);-- Clean up stagingTRUNCATE cdc_demo.orders_changes_staging;模式 5:Openflow CDC —— 从 Postgres 到 Snowflake
业务场景:一个高吞吐量的订单处理系统需要亚秒级的 CDC 延迟,并且要求具备 exactly-once 交付保障。该系统每秒处理数千笔事务,任何数据丢失或重复都会影响财务报告的准确性;
技术方案:Snowflake Openflow 基于 Apache NiFi 构建,并提供连接器,可以针对源系统(本例为 Postgres)执行基于 WAL 的 CDC,该连接器称为 CaptureChangePostgreSQL。变更数据可以通过其他 Openflow 处理器进行转换、过滤与增强处理,随后通过 Snowpipe Streaming 推送到 Snowflake。这是从 Postgres 向 Snowflake 处理数据变更时延迟最低的方案。
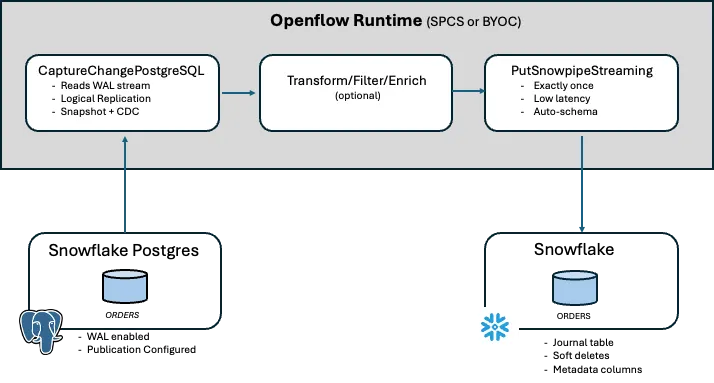
CaptureChangePostgreSQL 通过逻辑复制连接 PostgreSQL 实例。它会创建一个复制槽(replication slot),对配置的表执行初始快照,然后持续读取 WAL(Write-Ahead Log,预写日志)流中的所有 INSERT、UPDATE 和 DELETE 操作;
Transform / Filter(可选处理器)可以对记录进行重组、过滤特定事件、添加计算字段,或将不同类型的变更路由到不同的目标端;
PutSnowpipeStreaming 通过 Snowpipe Streaming 的高性能架构,将记录直接写入 Snowflake 表。它通过 offset token 跟踪实现 exactly-once 交付,并且数据在摄取后数秒内即可被查询。
核心能力:
近实时延迟:端到端交付以秒计,而不是分钟;
Exactly-once 语义:内置 offset 追踪机制可防止重复与数据丢失;
Schema 演进:自动适配源端 schema 的变化;
软删除:被删除的行会标记为 _SNOWFLAKE_DELETED = TRUE,从而保留审计历史;
Journal 表:保留完整变更历史,用于合规与回放;
无需自定义代码:通过 Openflow 参数实现完全声明式配置。
整体总结
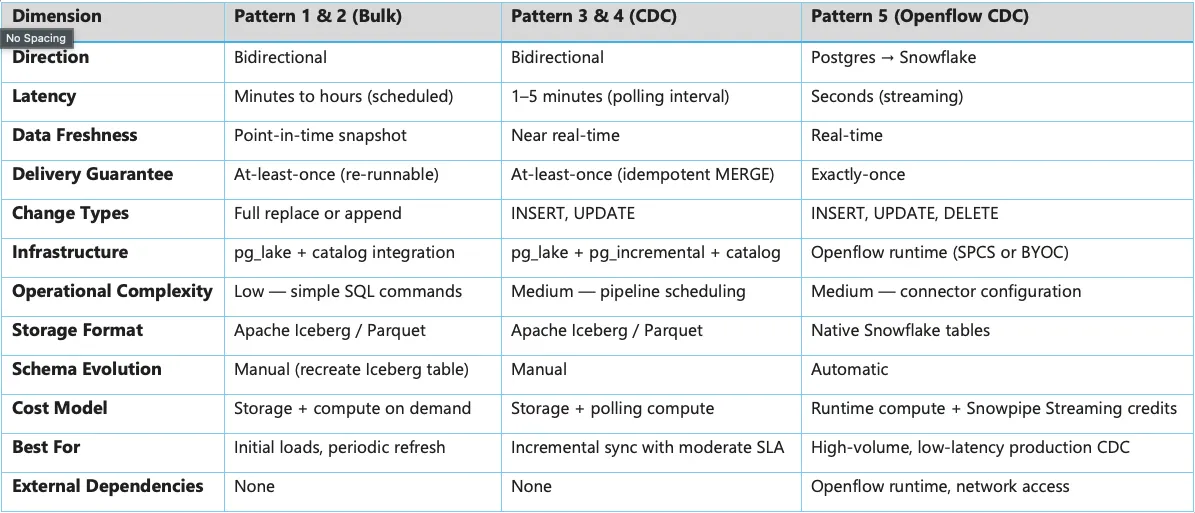
在了解了这 5 种模式之后,下面将从多个维度对其进行对比总结,以帮助你在不同场景下选择最合适的方案:
结论
Snowflake + Snowflake Postgres 生态系统如今提供了完整的数据流动模式谱系——从使用 pg_lake 和 Iceberg 的简单批量加载,到通过 Openflow 实现的实时 CDC——全部都在一个统一平台内完成。
共享的 Iceberg 存储模型消除了传统架构中管理外部存储、IAM 策略以及文件格式所带来的复杂性,而 Openflow 则为需要亚秒级延迟的工作负载提供生产级 CDC 能力。
选择上:
批量模式适用于追求简单性与成本效率的场景;
pg_incremental CDC 适用于在较少基础设施投入下平衡数据新鲜度的场景;
Openflow 适用于关键任务级实时数据管道。
最终采用哪种模式,取决于你的延迟需求、数据规模以及对运维复杂度的容忍程度——借助这些工具,你不再被限制在单一方案之中。
点击链接立即报名注册:Ascent - Snowflake Platform Training - China,更多 Snowflake 精彩活动请关注专区。




