
如果不是 2016 年,AI 在围棋上大放异彩,关于高性能存储的故事本不会这么复杂——它应该是一场玩家数量极其有限的牌局,由英特尔、IBM、DataDirect Networks、WEKA 等寥寥几家头部玩家轮流坐庄。
这个牌局不欢迎生面孔,即使偶有例外,大概也会是像 Nutanix 一般——其 CEO 先后供职于 VMware 、博通、思科,算是“老朋友的新爱好”。
通常情况下,你很难在“存储”这般重要的事情上,获取大客户的信任。相对于其他赛道而言,存储领域对“后起之秀”更加不友好。
但 AI 好似一条巨型“鲶鱼”,搅混了高性能存储的水。
AI 兴起前,高性能存储的目标客户,以“超算中心”为主。时间一过 2016 年,这个市场就变成了由云计算、AI 公司、超算中心等客户构成的复合型市场。等到 2022 年,生成式 AI 兴起后,情况变得更加复杂。
今天,有许多创业公司专攻面向 AI 的文件存储系统,并且获得了挑战“存储巨头”们的机会。
这是为什么 MLCommons 社区和焱融科技这家公司,在近期吸引了如此之多的关注——
前者作为人工智能工程联盟,在 AI 工程相关的基准测试方面,颇有公信力。今年,MLCommons 围绕其核心的 MLPerf Training 基准测试套件,发起了一个面向 AI 存储场景的横向性能测试,叫做 MLPerf® Storage v1.0 ,吸引了众多在国际上“有头有脸”的存储厂商参加。
后者则是这套测试里,唯一一个参加了全部测试项目的国产厂商,且成绩相当不错,足以和“领头羊”DDN(DataDirect Network)掰掰手腕。
看起来,一个诞生于 2016 年前后,性能堪比 DDN 的中国玩家已经上桌了。但是,对于所有关注 AI 存储的企业和开发者来说,这次测试内含哪些信息,该如何解读?焱融科技又做对了什么?
MLCommons 的测试靠谱吗?
这首先取决于 MLPerf® Storage v1.0 本身,相对于 IO 500 这样的老牌榜单,在专业度和公信力层面表现如何。
至少从 MLCommons 社区的董事会名单来看,MLPerf 的专业度是有保障的——里面既有来自英伟达、英特尔、谷歌的 AI 业务高管,也有来自哈佛的教授,以及来自 Facebook 的 AI 研究员,可谓背景雄厚。
这也给 MLCommons 带来了额外好处:成熟的开源文化和独到的技术能力。以 MLPerf® Storage v1.0 为例,MLPerf 可以通过 CPU 来完美模拟 GPU 活动,你甚至可以选择是针对 A100 进行测试,还是 H100 进行测试。不需要大量的真实物理资源来完成压测,这是 MLPerf® Storage v1.0 能成功推出的关键。
从结果来看,多家存储公司参加了这次测试。既包括老牌企业 DDN、Nutanix,也包括 WEKA、Hammerspace 这类新兴明星企业,以及 simplyblock 这般成立仅两年的初创企业,在国内,则有焱融科技、华为、浪潮、JuiceFS 等多家公司参加。
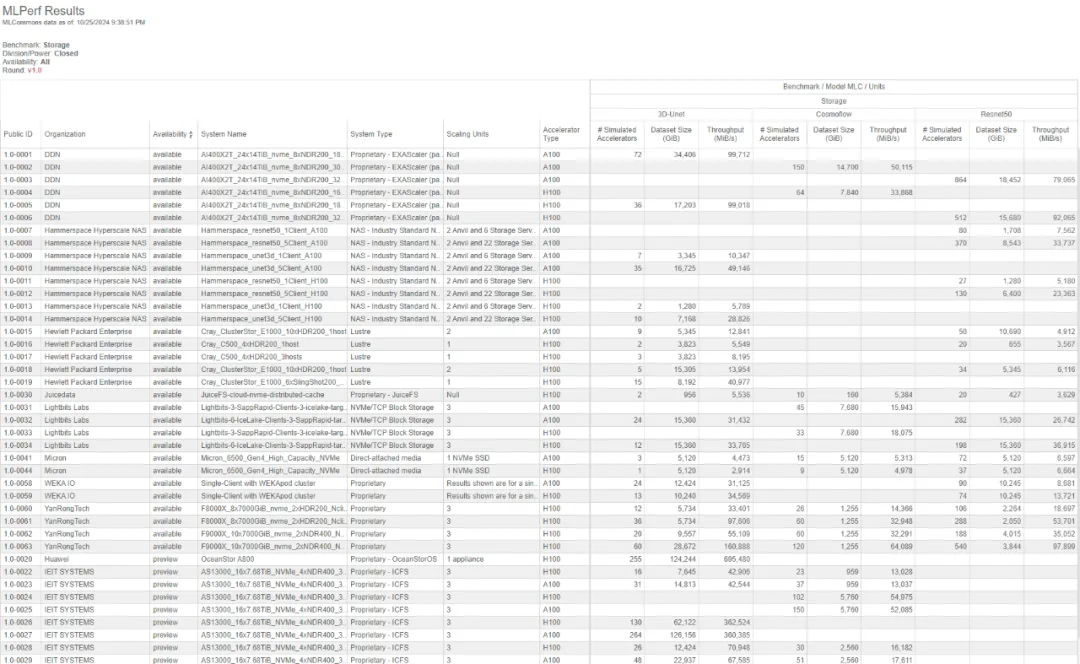
而具体的测试方法,有着浓厚的、来自生成式 AI 的“时代特色”:根据存储服务场景的不同,MLCommons 在两个不同的测试版本上,分别选用了四款模型:3D U-Net(图像分割、医学类)、ResNet-50(图像分类,仅 v1.0 版本)、 CosmoFlow (宇宙学参数预测,仅 v1.0 版本)和 BERT-large(语言处理,仅 v0.5 版本),用以测试不同场景下的存储性能。
拿 1.0 版本来说,3D U-Net、ResNet-50、CosmoFlow 不但覆盖了常见的 AI 存储场景,也对存储设备的性能提出了不同要求。这三个模型的单个样本大小,分别是 150MB、150K、2MB,基本覆盖了不同标准下的“大文件”、“小文件”,考验的是厂商在不同场景下的性能调校,以及对元数据的处理策略。
更进一步,MLCommons 要求在 3D U-Net、ResNet-50 的测试中,AU(加速器利用率)必须大于 90%;CosmoFlow 测试的 AU 必须大于 70%。若 AU 一旦低于此值,说明存储性能不足以支撑 GPU 高效运行,即被认定为低效存储,花费太多时间在网络等开销上。
在整个测试过程中,MLPerf® Storage v1.0 会不断增加 ACC(虚拟加速器,也就是模拟 GPU)的数量,直到 AU 低于 90% 或 70%,。最终输出三项数据用作最终比对,分别是:被测机器支持的 ACC(虚拟加速器)总数、测试数据集大小、吞吐速率。
所有测试数据都会被公示,参评的厂商互相审校,交叉提问,只有关于测试成绩的提问全部被“Close”掉,才算做最终测试完成,保证了测试的公正合理。
当然,MLPerf® Storage v1.0 也存在一些问题,其核心是对测试场景的覆盖不够完整。比如缺少对大参数量级的模型的测试,从 3D U-Net 到 BERT-large,参数量级都很小;此外,测试只模拟模型对训练数据的访问,没有测试重新加载模型,或者写 CheckPoint 时,表现出来的存储峰值性能。
另外从 MLCommons 官方公布的结果来看,你很难直接得出一个厂商维度的综合成绩和排名。因为官方只公布了各厂商所提供机器的测试结果,而每台机器配置不同,价格不同,所以数据差异也较大。
我们只能结合存储市场的实际选型情况做自主推测:三项测试数据中,“ACC 总数”这项数据更为关键。至于数据集大小,其实可以忽略——测试数据集的大小,会被设定为测试机器内存的五倍,用以防止参与测试的厂商提前缓存训练数据。
综合来看,MLCommons 真正想展示给公众的数据是两个维度的数据:
某厂商的一套存储系统,能支撑的虚拟 GPU 是多少颗,吞吐速度如何;
该存储系统里的单个计算节点,能支撑的虚拟 GPU 是多少颗,吞吐速度如何;
但出于某些原因,社区没有将测试结果,细化到这个层面,也导致各家公关口径的成绩大相径庭。
比如 DDN 选择计算单闪存可以支撑的虚拟 GPU 数量。在这种算法下,DDN 排名第一,排名第二的是国产厂商——焱融科技。
但闪存数量通常不是一套存储系统的性能瓶颈,整体的网络开销才是。且各家产品架构不同,闪存数量,并不是存储设备在性能方面的通用单位。通过计算单闪存平均支持的 ACC 数量来做排名,无疑有失偏颇。
相比较之下,焱融科技以计算节点为单位衡量存储性能,泛用性更强。分布式训练集群场景,焱融存储在所有三个模型的测试中,能够支撑的每个计算节点平均 ACC 数量和存储带宽性能排名第一,排名第二的则是来自美国的独角兽 WEKA。
抛开计算方法层面的分歧,排名靠前的厂商大致有哪些,其实已经明确了——当下,虽然不能说,像焱融科技这般的国产存储厂商,已经完成了对老牌国外存储厂商的追赶和反超,但在部分垂直场景的存储技术上,“国货”和“洋货”确实已经可以同台竞技,甚至战而胜之。
“国货”的崛起逻辑
当然,对于国内厂商而言,技术实力很关键,但并不是全部。
这种来自国际权威组织的公开测试,与其说是一场“同台竞技”,不如说是一次宝贵的宣传机会。毕竟在硬科技领域,国内企业往往长于技术,短于生态和营销,几乎已经形成某种刻板印象。
好在,AI 技术的爆发,将市场拉回了某种混沌态,客户的需求几乎年年都在变,这是创业公司更为适应的生存环境——相较于传统巨头们,他们更灵活,也更有侵略性。
早期 AI 客户往往扎根于计算机视觉、自然语言理解等领域,对存储的要求与性能强相关,且主要考察“读”能力,对“写”能力要求不高。而到了大语言模型兴起后,对“写”能力的要求大幅提升。同时,为了保证模型训练、微调等环节的业务连续性,大模型要经常写 CheckPoint,这进一步增加了存储设备的“写”压力。
无论是 CV、NLP,还是大语言模型,对于存储设备而言,都是进行大文件读写。等到多模态能力在生成式 AI 中得到普及,图片和视频切片,形成了海量的小文件。对存储厂商而言,技术难度进一步上升。
“国货”的机会,也恰恰是在这些挑战中诞生的。
相比于存储大厂,新兴企业,尤其是国内的新兴企业,通常更加专注,比如焱融科技,只关注 AI 场景下的分布式文件存储。
此外,国产化替代仍然在进行中。生成式 AI 的发展,和新质生产力相关政策的出炉,不断刺激着国内分布式存储行业的发展。
单从市场层面看,“国货”在存储领域对“洋货”形成替代,实际上也是必然的。
首先存储直接影响业务的连续性和稳定性,一旦发生故障,相关技术团队需要立刻到位。这对于外企而言,显然有些困难。
其次,国内厂商对客户的定制化要求,包容度足够高,愿意配合客户进行一些架构上的探索,这更符合国内甲方企业的实际诉求。
最大的优势,还是在产业链层面。据业内人士透露,在闪存选 QLC,网络解决方案选 RoCE 的情况下,国内有不少上游厂商可供存储厂商选择,对比国外企业,大概会有 20% 的成本节省,从而表现的在终端售价上更有竞争力。
这是为什么,成立还不到十年的焱融科技,今时可以在 MLCommons 举办的测评中,和已经成立 26 年的 DDN 打擂台。
跳出舒适区
与上述判断相符的是,售卖存储设备的外企,在中国,仍处于长达十年的持续衰退中。以至于有研究机构,围绕国内市场做竞争力象限图时,DDN 这样企业的位置,已经从右上角(领导者)跌入左下角(专精者)。
这既给国内企业留出了充足的发展空间,同时也意味着,未来的增长故事不会发生在国内,而是发生在海外。有研究机构预测,到 2031 年,北美地区的软件定义存储市场预计增长到 380 亿美元以上,亚太地区预计增长至 275 亿美元以上,中国地区预计占到其中 33.7% 的份额。
类似 MLPerf® Storage v1.0、IO 500 这样的测试和榜单,对于国内企业而言,今后会变得更加重要。
焱融科技对此认知十分清醒。焱融科技 CTO 张文涛透露,对于六月底开始的 MLPerf® Storage v1.0,焱融科技实际上在 4 月就开始测试了。由于早期不知道同台竞技的企业有哪些,只能尽量逼近自身产品的极限值。
同时,今天的存储厂商每谈成一单生意,要解决的不光是性能问题,也是产品问题和服务支持问题。
大模型超长的训练周期以及其特殊的业务流程,要求存储厂商的产品,不仅性能够强,在产品设计和服务支持方面也要跟得上。
这是为什么焱融科技投入人力开发了 Dataload 智能数据加载功能——多云、混合云架构是过去几年间,国内最主要的云构建策略,而以 Dataload 为核心的解决方案,可以激活历史数据的价值,打通对象存储与文件存储,实现多云间的数据流转,消除性能瓶颈。
这其实是市场对产品提出的新要求。
成立于 2016 年前后的存储企业,即将迈过十周年的门槛,变得不再年轻。而随生成式 AI 的发展而诞生的新兴存储企业,正逐步进入市场主流视野。
曾经的“少壮派”们,如今面临着向上从巨头手中抢市场,向下严守基本盘的空前竞争压力。能否走出舒适区,将成为后续发展的关键一步。




