
近日,有网友在社交媒体发帖称,在开发 UI 时检查腾讯 Codebuddy 改写的内容,发现有一串广告写进去了:往函数里面赋值了一个极速电竞 APP。“忍不了了,直接卸载”该网友说道。
此外,还有网友在字节 Trae 国内版也发现了 bug,生成结果会随机出现“极”字,如果让模型自动修改,则会直接把上下的代码删除。
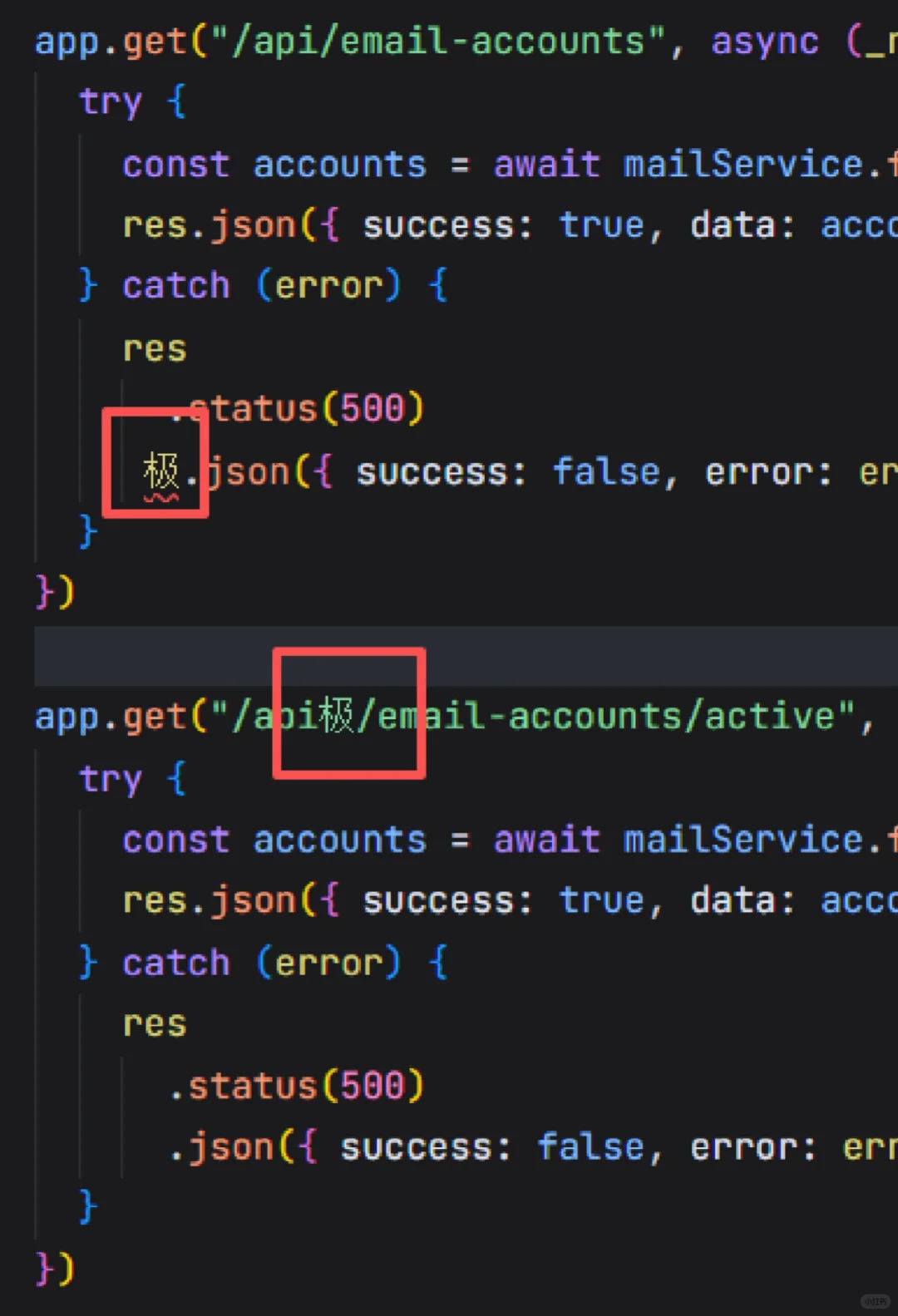
随后,发现 Codebuddy 问题的网友在评论区表示,“是 DeepSeek 模型引入的 bug,腾讯已经把问题上报了,后续会修复。”
无论是 Codebuddy 还是 Trae,出现问题的根源都指向了 DeepSeek 最新的 V3.1。
实际上,一天前,开发者 notdba 就在 Reddit 上表示,其用 DeepSeek V3.1 做了一些测试,发现该模型会在完全意想不到的地方生成以下 token:
" extreme"(id:15075)"极"(id:2577,简体中文中的“极”)"極"(id:16411,繁体中文中的“極”)
“一开始我以为是因为我用了极端的 IQ1_S 量化,或者是 imatrix 校准数据集里的某些边缘情况导致的。但后来我用 Fireworks 提供的 FP8 全精度模型测试时,也出现了同样的问题。”notdba 表示,这些极端 token 还会不断地在其他出乎意料的地方以第二或第三选择的形式出现。
示例 1:(本地 ik_llama.cpp,参数 top_k=1,temperature=1)
预期输出:time.Second
实际输出:time.Se极
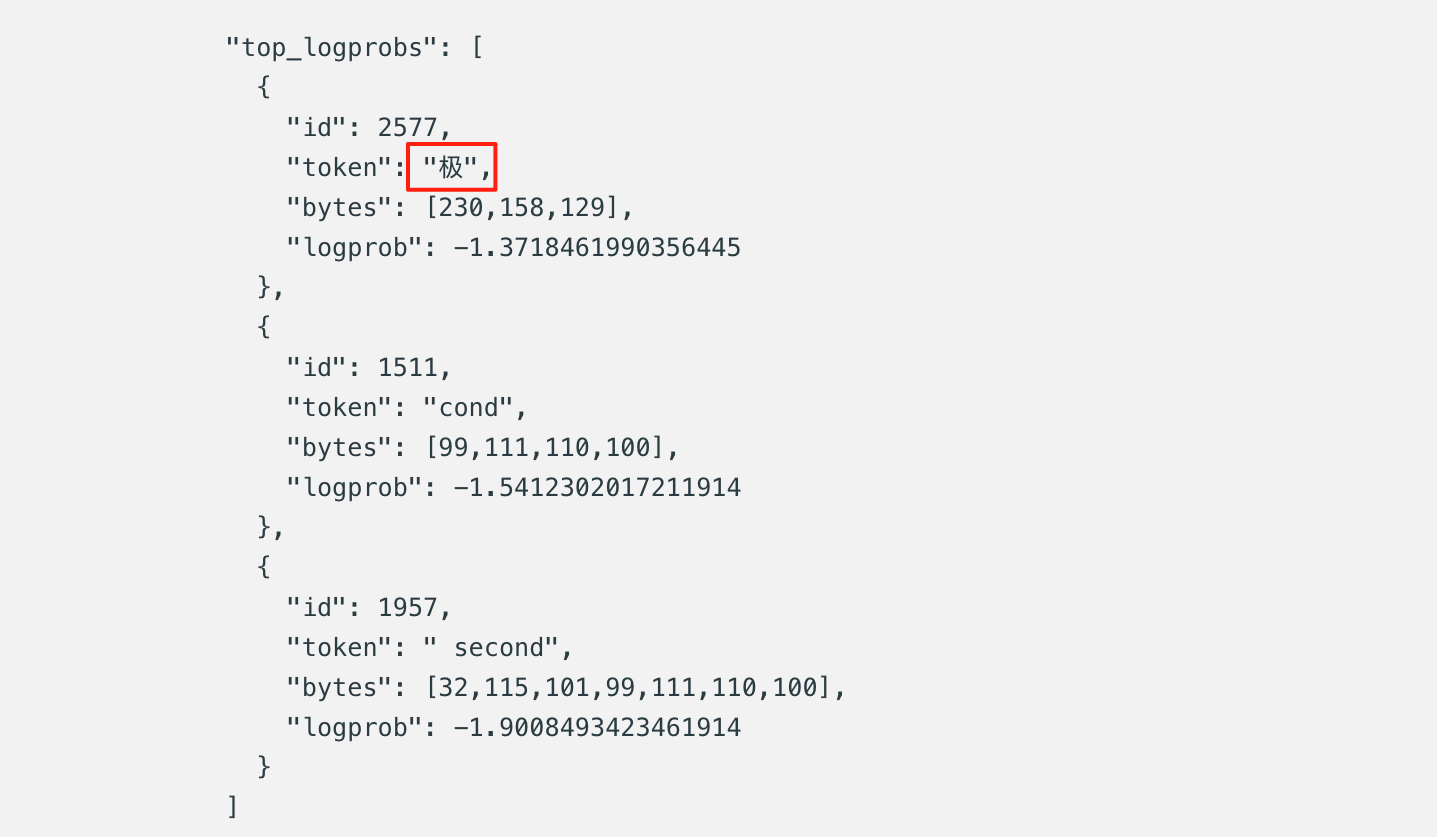
示例 2:(本地 ik_llama.cpp,参数 top_k=1,temperature=1)
预期输出:time.Second
实际输出:time.Se extreme

示例 3:(Fireworks,参数 top_k=1,temperature=1)
预期输出:V1
实际输出:V极

有网友则表示,“我使用 DeepSeek 的官方 API 完成了两个 Claude Code 项目,没有遇到这个问题。有趣的是,使用 DeepInfra 或 Akash Chat 的 API 也没有出现这个问题。”
经众多网友实测,官方网页/API 能复现该 bug,概率不高,但多试几次就能出来。第三方平台上的复现率非常高。同时,如果将错误搀入的字符“极”字改为其他的字符,则官方 API 出问题概率下降,但像 VolcEngine API 出问题的概率仍很高。
这一 bug 也被广大网友戏称为“极你太美”事件。截至发稿前,DeepSeek 未作出任何回应。
网友:找到真正的“锅”了
“之前用腾讯元宝调用 DeepSeek R1 生成代码的时候也会把一些字符转换成‘极’,当时还以为是腾讯的锅。”还有网友表示,“DeepSeek 一直有这个问题,只是以前出现的概率低。”
网友琪洛在知乎上表示,V3-0324 也有遇到过类似的问题,会输出一个极其逆天的「极速赛车开奖直播」字符串,在连续输出长数组(例如参数量较大的工具调用时)概率较大。“怀疑可能数据没洗干净,即便重新训了 base 这个问题还是留下了。”

还有网友称,“使用 R1 0528 的时候就遇到了很多次,我观察到的现象更离谱,会在代码里面插入‘极客园’,而且遇到不止一次。”
实际上,在 4 月份时就有开发者在 Github 提交了这个 bug,开发者“icewool”表示该问题已经在多个版本的 sglang、vllm 和腾讯元宝上进行了验证,并猜测可能是 DeepSeek-V3-0324 模型权重或分词器存在问题。
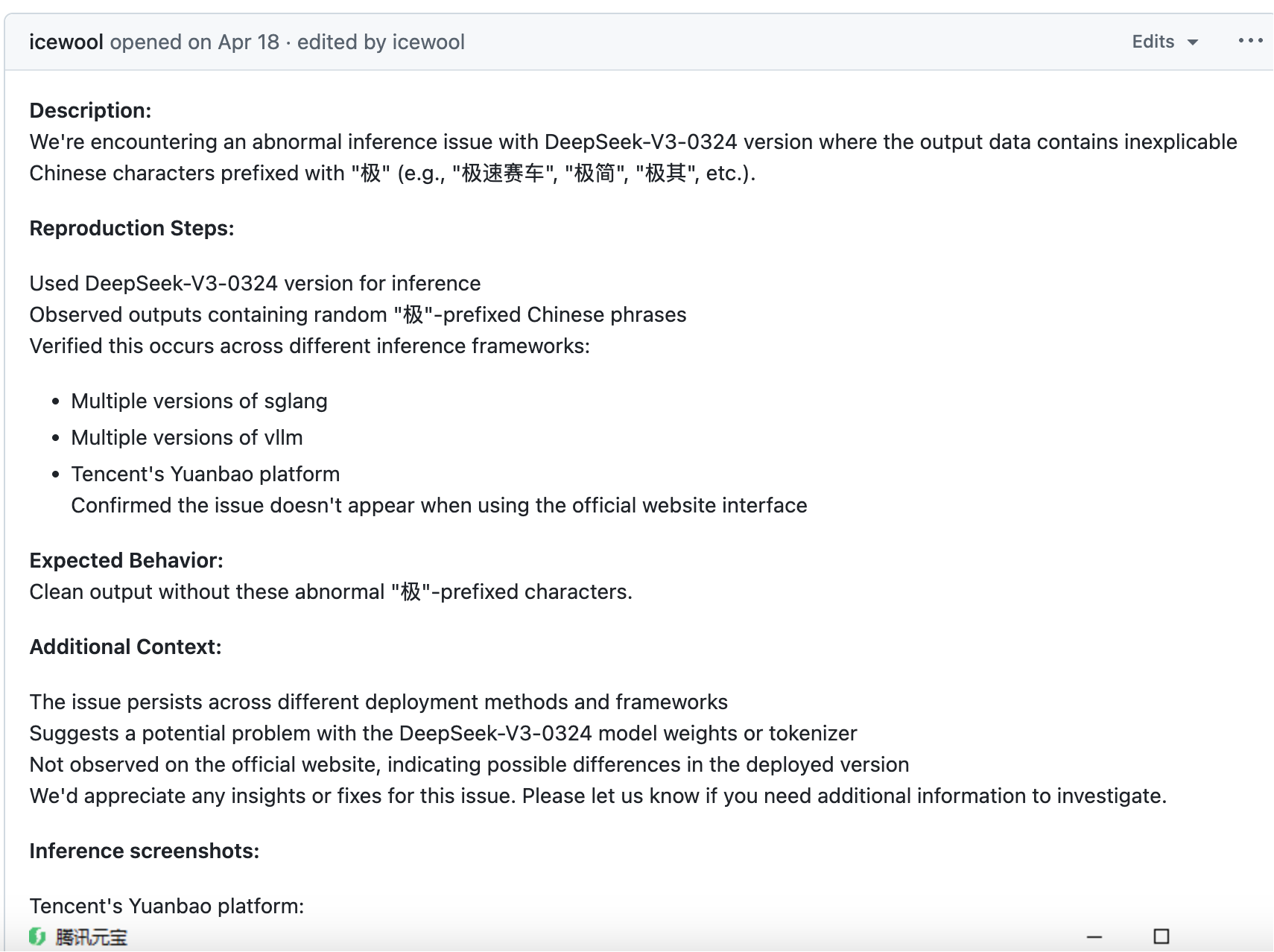
两天前,该开发者再次请求官方解决问题。从提出问题至今,只有机器人会出来提示:此问题已被自动标记为过期,因为最近没有新的活动。
另外根据网友们的反馈,不只是 DeepSeek 模型出现了这个问题。
在 notdba 帖子下,有开发者评论称,“在 v3.1 版本中也遇到了一些严重的代码混合问题。不仅仅是你说的那个 token,它总是在响应中生成其他语言的单词(通常是中文)。Gemini 也出现过这个问题,但情况更糟。我喜欢 DeepSeek 的回应,它消息灵通且非常有帮助,但这确实是一个令人讨厌的问题。”
“Grok 也有类似问题,我遇到过几次。”有网友表示。
此外,notdba 还补充道,“最近的 Qwen3 235B A22B Instruct 2507 和 Qwen3 Coder 30B A3B Instruct 也表现出同样的问题,可能和 DeepSeek V3 0324 处于同一阶段。与此同时,Qwen3 Coder 480B A35B Instruct 只有在被严重量化后才出现同样的问题。看起来这两个实验室可能使用了相同的被污染数据。GLM 4.5 没有受到影响。”
各种找原因,是数据问题?
关于 DeepSeek V3.1 出现这一 bug 的原因,总的来说目前大家主要有三种猜测:
Token 连续性假说:认为 FP8 量化或者混合精度训练导致“极”的 Token ID 2577 和省略号的 ID 2576 混淆
数据污染假说:认为预训练或 SFT 遭受了数据污染
MTP(Multi Token Prediction)问题:认为推理框架出现了问题
香港大学计算机科学硕士“爱学习的乔同学”在知乎上表示,他研究之后发现问题没有那么简单,甚至这个问题在 Claude 4 身上都出现过,只不过表现形式不同。Claude 4 是在中文上下文很长的时候,突然蹦出几个英文单词。
乔同学首先排除了 Token 连续性假设。“Token 连续性假说站不住脚,因为不管是 FP8、NF4 还是混合精度训练,都不会改变向量或矩阵的大小或形状,只会改变矩阵或向量内部元素的数值。ID 相邻的两个 token,向量表示是完全不同的,所以量化这个过程并不会让这两个向量变得完全相同,更不会出现泄漏,因为泄漏就意味着矩阵的形状发生了改变,这从量化的原理上是完全说不通的。”
其次,对于很多人的例子中除了输出“极”之外,还会附带输出“极客园”或“极速赛车”这类词,他表示这可以说基本是预训练的问题。“不管有没有开 MTP,在预训练的时候任务都是根据当前的输入预测下一个词,MTP 只是多预测了几个。”
预训练都是在互联网上进行训练的。乔同学自己搜索后表示,“极客”和“极速”的搜索指数差不多,这时就会出现两种情况:大模型输出“极”之后,接下来选到了“客”,然后再下一个词,由于“博客园”出现的次数也很多,所以“客”之后下一个 Token 有很大概率选到“园”,最终组成了“极客园”。另一种情况就是选到了“速”,那么同样由于“极速赛车”出现的频率很高,所以“速”下一个词大概率是“赛”,然后以此类推,出现“极速赛车”。这也就是为什么会出现“极”字后面跟着一串无关的词语。
当然,这无法解释部分 Case 在“极”后面输出了正常的代码,只替换了“极”这个字。例如这个 Case 将逗号预测成了“极”。

为什么偏偏是“极”,而不是其它的 Token?乔同学猜测这大概率与 SFT 阶段有关。
DeepSeek 的 SFT 数据部分来源于自监督的合成数据。如果原始模型生成的合成数据有问题,那么 SFT 出来的模型就会有问题。报告中提到,SFT 的推理数据正是几乎所有 Case 出现的数学和代码领域的数据。也就是说,所谓最开始的 DeepSeek-R1(年初版本)可能就已经出现了“极”的问题。
而负责生成合成数据的 DeepSeek-R1 是基于 R1-Zero 训练出来的,因此“极”这一 BUG 非常有可能是在 R1-Zero 中出现,然后跟随合成数据训练到了今年年初的 DeepSeek-R1 模型中,然后进一步蒸馏成了 DeepSeek V3 0324 版本,这个 BUG 始终存在,没有消除。“至于为什么是‘极’而不是其他的字符,这个只能解释为是 R1-Zero 强化学习之后得出的偶然现象。”
也有开发者认为这是蒸馏“传染”造成的。
知乎答主“hzwer 黄哲威”表示自己用小模型 + 开源数据蒸馏 R1 的时候也见到过类似 bug。其解释道:大模型做编程题的时候会有一种恶性 pattern,是枚举数列,比如说“素数表 2,3,5,7… ”无限枚举。R1-0528 会在枚举一段后停下来,变成 “素数表 2,3,5,7 … 997,极长的列表”。这个极字经常出现在大量恶性重复之后,切回正常的推理过程。也有“90000000...0000 极大的数字” 这种,在 thinking 末尾循环出不来的时候,会见到突然蹦出一个极字然后 终止,触发率千分之一。
“我肉眼看了很多 R1 输出发现的(其实不是很大工作量,只要把 R1 超长的 response 拿出来扫几眼,就能看出很多问题了,还有大面积空白字符,一直 But + 短句重复,或者到 thinking 末尾出的英文字都破碎的各种问题)。我认为,原本是 sft 数据合成甚至是构造预训练数据的时候没洗干净引入了‘极长的数组’这种怪东西(从 R1 的行为看,似乎大量使用了 RAG 方法来造难题的解答),然后 RL 的时候模型直接把这个字当某种终止符或者语言切换标记使用了。如果 R1 迭代的时候没洗干净数据,模型自蒸馏传染到正常的输出过程里也正常。”黄哲威表示。
昵称为“AI 解码师”的开发者也认为,这并非架构缺陷,而是训练数据和蒸馏链条里遗留下来的瑕疵。“这说明 DeepSeek 在迭代过程中,部分数据合成环节没有完全净化,或者在 RAG 构造难题时,残留了特定的标记词;更可能的是,模型把‘极’当成边界 token 来使用,这种行为和我们理解的自然语言生成是有差距的。”
“AI 解码师”认为这背后反映了一个更深层次的问题:大模型并不是在真正理解语言,而是在学习数据分布里的统计规律。如果训练数据中混入了“极长的数组”这种模式,模型就可能把它当成一种“隐含的指令”,而不是单纯的自然语言。
他提醒,随着自蒸馏链条越来越长,数据瑕疵会被多次放大,并最终“污染”正常输出。未来在做对齐或蒸馏时,不能仅靠 RL 去兜底,还需要在数据合成 → 预训练 → SFT → RLHF 的整个链条中,建立更严格的监控和清洗机制。
不过,他认为,这种“极”现象很有研究价值,“它像是一种无意间暴露出的模型内部符号学痕迹。如果有能力去追踪这些 token 的来源和扩散路径,可能会对理解大模型如何在语料噪声中形成‘伪语言规则’带来新的思路。”
“这就是开源的好处,有问题大家一起找,找到了大家一起来改啊。”还有乐观的网友说道。
参考链接:
https://github.com/deepseek-ai/DeepSeek-V3/issues/849




