
“Flink 已经成为全球范围内实时流计算的事实标准。”用这句话来描绘 Flink 在当前大数据技术领域的地位并不为过。
虽然大数据领域的技术和潮流方向在不断发生改变,但是 Flink 一直处于核心驱动的位置。从流式计算引擎的兴起,到流批一体在企业内部的落地,再到为实现端到端全链路的实时化分析能力而走向舞台中央的流式数仓,Flink 均在其中扮演着重要的角色。
以上每个过程的推进和实现都并不容易,Flink 到底是如何做到的?其背后的推动力是什么?凭什么受到全球企业和开发者的青睐?带着这些问题,InfoQ 有幸采访到了 Apache Flink 中文社区发起人、阿里巴巴开源大数据平台负责人王峰(莫问),以期深度了解 Flink 从实时流计算引擎到全球化落地的演进历程。
流式计算引擎的纷争:Flink 靠什么打破瓶颈期?
在 Flink 诞生之前,大数据领域的计算框架不在少数,先后出现的 Hadoop 和 Spark 已是业界的主流选择。
彼时,专为批处理而生的 Hadoop,在实时数据处理方面存在着明显不足。在此背景下,Spark 推出了流计算解决方案——Spark Streaming。但由于 Spark 不是一款纯流式计算引擎,所以其在动态调整、事物机制、延迟性、吞吐量等方面的表现也并不亮眼。直到 Flink 出现以后,才提供了一个真正的流引擎,将 Streaming 计算和状态存储进行有机融合,在框架层支持整个流计算状态的精准数据一致性,填补了大数据市场的空白。
时至今日,Flink 已经成为全球范围内被广泛使用的开源大数据计算引擎。但据 InfoQ 了解,即便是这样一款性能优秀的流计算引擎,其在一开始的推广阶段也曾陷入瓶颈。这背后,一方面是市场需求所致,早在七八年前,大多数企业对于数据处理的实效性需求还未大规模显露;另一方面是受学习门槛的影响,当时大数据处理领域的通用语言是 SQL,而早期开发 Flink 需要通过 DataStream 的 API 写 Java 代码,学习门槛过高成为了 Flink 陷入推广瓶颈的核心因素之一。
那么,在未经大规模验证的情况下,Flink 到底是如何走向公众视野的?“阿里其实是在其他企业还没有需求的时候,就已经把 Flink 打磨好了。”王峰在接受 InfoQ 采访时回忆道。
相比于其他没有实时化计算需求的企业,阿里在业务量方面走得比较靠前。尤其是在双 11 这类特殊的业务场景下,对数据做实时的收集、分析、处理成为强需求。当时,阿里的商品数据处理就经常需要面对增量和全量两套不同的业务流程问题,如何用一套统一的大数据引擎技术,在各种不同的场景下提供支持,成为阿里面临的技术挑战。
于是,阿里在 2015 年启动了对 Flink 的调研,决定用 Flink 做一个统一的、通用的大数据引擎作为未来的选型,并在 2016 年首次将 Flink 应用在了双 11 搜索推荐场景中。
但正如前文所言,阿里在使用阶段也发现了 Flink 在稳定性、易用性等方面的不足。基于此,阿里也开启了对 Flink 的优化之路,在内部建立起了一个 Flink 的分支——Blink,实现了 Flink 流批一体架构的高度融合,含统一 Flink SQL、统一 SQL 架构以及与 Hive 生态系统集成。在 2019 年,阿里将内部积累的 Blink SQL 贡献给了 Flink 社区,将 Blink 中比较通用的部分悉数回馈给 Flink 社区,贡献了超过一百万行代码,这其中包括 Runtime、SQL、PyFlink 以及 ML Pipeline。
历经阿里庞大业务量洗礼的 Blink,对 Flink SQL 产生了深远的影响,不仅推动了 Flink SQL 的发展,使其比以前快了 10 倍,还把 Flink SQL 塑造成了如今我们看到的样子。此外,阿里云还在 2019 年收购了 Flink 母公司 Data Artisans(更名 Ververica),并推出了全球统一的 Flink 企业版平台——Ververica Platform。
由此也能看出,Flink 能够在 2019 年将 GitHub 上的 Star 数量翻了一倍,这样的数据波动绝非偶然,很大程度是阿里在背后推动。
从计算引擎到流批一体和流式数仓:Flink 从项目成为“标准”
如果说 2019 年仅仅是阿里向 Flink 全球化社区迈出的一小步,那么至此以后,阿里便一直在推动着 Flink 全球化社区的发展。据统计,阿里 /Ververica 主导了 211 个 Flink 核心设计提案,贡献了 Flink 70%+ 的核心改进。
在 2020 年,社区一共发布了 Flink 1.10 & 1.11 & 1.12 三个大版本,对 Flink 流批一体架构做了重要的升级和落地;在 2021 年,推出的 Flink Remote Shuffle 项目,解决了 Flink 大规模批处理作业的稳定性问题。这两年间,Flink 在持续优化流计算核心能力的同时,还在逐步推进流批一体的技术理念。
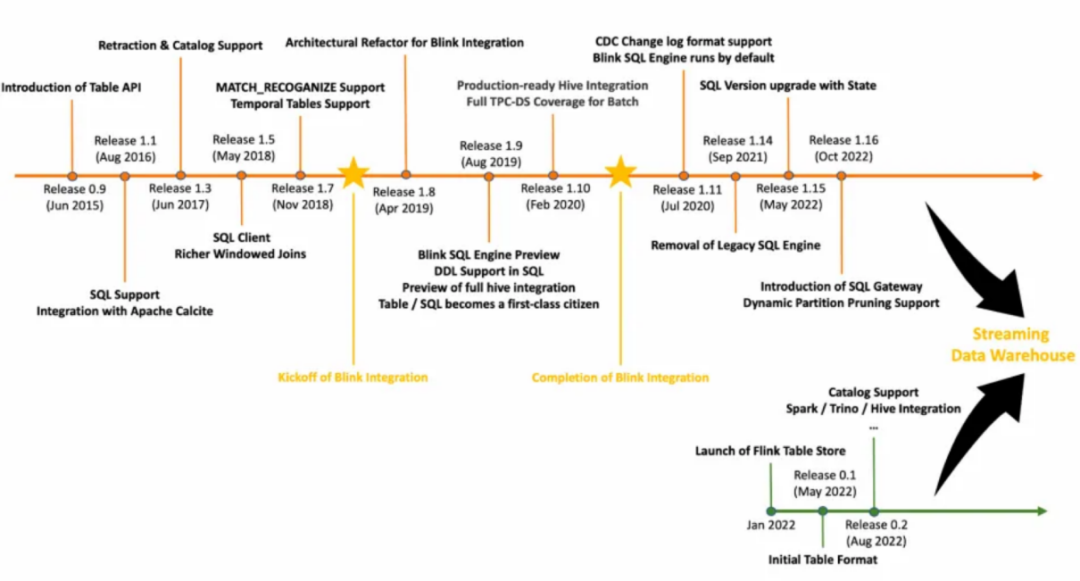
直到 2022 年,我们在 Flink Forward Asia 2021 看到了 Flink 的下一步发展方向——流式数仓,即让整个数仓的数据全实时地流动起来,且是以纯流的方式而不是微批的方式流动。为了实现流批一体的存储能力,Flink 社区还在去年推出了全新子项目 Table Store(近期已升级为 Apache 孵化项目 Paimon)。本文,我们不对流式数仓过多赘述,在 InfoQ 发布的 《Apache Flink 不止于计算,数仓架构或兴起新一轮变革》 中已有详尽解读。
但回溯 2019 年 -2022 年 Flink 的版本迭代情况可以看出,Flink 的迭代速度相对比较快,基本每三到四个月就会发布一个大版本。动作频频的背后,我们也在好奇,阿里为何总能洞察到大数据行业的真实需求?其背后的迭代思路来自何处?关于这个问题,王峰总结“实践经验 + 理论洞察”是两个关键要素。
众所周知,阿里是 Flink 的早期实践者,在丰富业务形态与庞大业务量的驱动下,阿里内部对实时化计算的要求越来越高,这也就倒逼 Flink 的良性发展和沉淀。例如,在 2020 年,阿里巴巴首次在双 11 最核心的天猫营销活动分析大屏场景中落地 Flink 流批一体;在 2021 年双 11 中,Flink 承载的实时计算峰值达到了每秒 40 亿条记录,数据体量也达到 7 TB 每秒...... 正是在阿里大规模应用 Flink 的实战经验之下,真实的业务需求能够帮助 Flink 做输入,并反哺 Flink 全球化社区向前发展。
然而,只有业务场景这一个要素并不足够,Flink 的每次迭代能够顺应大数据行业的发展需求,还离不开阿里在全球化方面的全局洞察。据统计,阿里联合 Ververica 已累计培养了近 70 位 Flink 核心贡献者(含项目管理委员会 PMC 成员和活跃贡献者 committer),占比超 70%。因此,阿里在推动 Flink 的发展过程中,其技术视野并不会只聚焦在国内,对标国外头部大数据公司的技术理念促使 Flink 的每次规划都更具前瞻性。
总体而言,我们发现,无论是持续强化流计算引擎,还是推动流批一体技术理念的落地应用,亦或是提出流式数仓的新目标,Flink 核心特色其实一直都没有改变,其本质都是基于 Streaming 这个核心理念进行持续强化。
这也就不难理解,Flink 如今能够成为大数据实时计算业界事实标准,与其在一条赛道保持专注是密不可分的。“开源项目只有做到业界的头部才有生存空间,Flink 就是要成为全球范围内最好的流式计算引擎。”王峰在采访中进一步补充道。
开源之余,Flink 的全球化落地之路
基于全球化的开源理念,Flink 吸引了全球开发者的加入,截至目前已经积累了超过 1600 名开发者为 Flink 社区做贡献,2022 年又新增加了 200 多名开发者。在下载量方面,Flink 在 2022 年再创新高,月度峰值的下载量最高已经突破 1400 万次。
不仅于此,Flink 还吸引了全球企业的应用落地,Apple、Capital One、eBay、Ericsson 等全球知名公司都在使用 Flink 处理实时数据。而这样的实践,又反推整个项目不断更新迭代,进而发展得更好。从某种程度来讲,Flink 其实为我们展现了一个全球化开源项目应该有的良性循环。
目前,阿里巴巴不仅是 Flink 最大的贡献者和使用者,还基于 Apache Flink 推出了实时计算 Flink 云产品和全球统一的 Flink 企业版平台 Ververica Platform,在政务、金融、制造、零售、交通出行、传媒、游戏、科技等行业大规模应用,帮助上千家全球企业更高效地进行实时业务升级。
根据不完全统计,使用 Flink 的非互联网企业占比已超过 30%。而通过这组数据,我们的一个明显感知是,实时化计算已经从早期只能被少数互联网企业玩转,逐渐演变成一种更为普适化的技术。
正如王峰在采访时所说:“如果大多数企业都不会用、用不起,大数据技术永远只能高高在上,很难再往下发展。”如何持续降低大数据的使用门槛以及使用成本,已经成为业界的共识,而从 Flink 在非互联网企业的加速普及中,我们已经看到了阿里取得的阶段性成果。
谈及 Flink 全球化运作的后续规划,王峰提到,接下来迭代商业化产品会沿着两条路径来走,以满足国内外企业的不同需求。
“在帮助上千家全球企业高效地进行实时业务升级的过程中,能够发现国内、国外企业在使用 Flink 商业化版本的关注点也有所不同。”
例如,国内企业更加关注运行成本,以及使用 Flink 云产品以后能否提供服务支持等等,后续实时计算 Flink 版会着重从软硬一体结合的角度来降低成本;反观国外企业,他们更加关注 Ververica Platform 的产品力,即产品的用户体验、安全性、易用性等方面是不是做得足够好。据王峰透露,Ververica Platform 预计在 4 月份会推出云中立的特性,让企业不仅能在阿里云上运行 Flink,还可以在 AWS、Azure、Google Cloud 等公有云上使用。
除此之外,前文提到的 Flink Table Store 子项目也迎来新动态。近期,阿里已经将其独立孵化成 Apache 的顶级项目 Paimon,并且会开放对接 Spark、Presto/Trino、StarRocks/Doris 等主流的计算引擎,目的便是为了让用户通过一套存储实现数据的更新、分析等等。
从上述释放的信号我们能够感受到,阿里不仅在技术生态方面具备了全球化的发展态势,伴随着云中立特性的补充以及独立子项目的孵化,Flink 商业生态、开源生态的全球化也将得到进一步的完善。
写在最后
Flink 能够成为全球范围内被广泛使用的开源大数据计算引擎,不仅靠阿里一家的努力,同时需要更多开发者与企业的参与、共建。据统计,Flink 全球化社区已经有超过 20 万开发者关注、超过 100 家国内外知名公司参与代码贡献。在如此庞大的用户和开发者生态之中,有 45% 是来自于中国的开发者,这足以体现中国开发者对 Flink 全球化社区的推动作用。
今后,我们也很乐于看到在阿里的持续引领下,Flink 全球化社区能够在实时计算层面有更大的突破。




