
Netflix推出Upper,这是一个统一的领域建模框架,内置于其统一数据架构(UDA)中,旨在标准化其不断扩展的内容工程系统中的领域定义。以前,各团队独立维护自己的领域模型,这意味着需要为每对系统构建定制化的转换方案。Upper 的引入提供了一个一致的概念层。随着公司业务拓展至现场活动、游戏、广告及全球内容制作等领域,该平台将为工程团队提供有力的支持。
Upper 基于W3C标准(如用于概念图表示的RDF和用于验证的SHACL),实现了数据生态系统中“一次建模,处处表示”的原则。Upper 通过键控实体(keyed entities)、它们的属性以及跨领域边界的关系来组织概念。建模语法和验证结构的设计旨在确保定义演进过程中的一致性。键控概念可以单调扩展,允许添加新属性或关系,而无需修改现有定义,允许领域随时间扩展而不破坏现有模型。
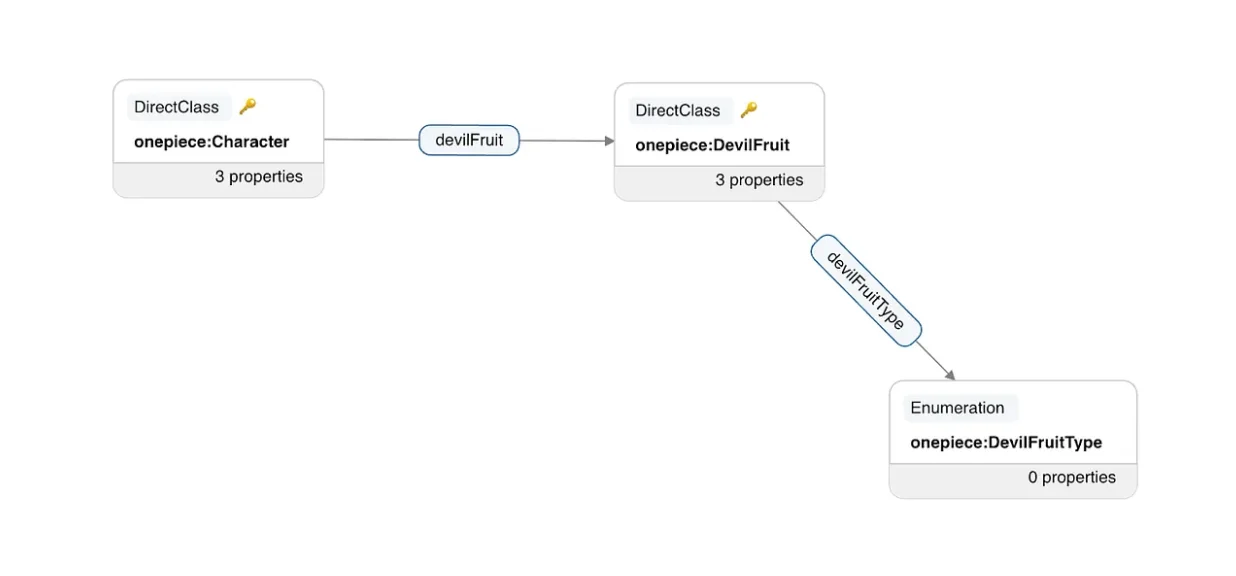
OnePiece 领域模型的图形表示(图片来源:Netflix技术博客)
正如 Netflix 首席工程师Alexandre Bertails所提到的:
Upper 旨在通过四个基础属性实现自我引导:自描述(定义了领域模型是什么)、自引用(将自己建模为一个领域)、自管理(根据自己的规则进行验证)以及联合(对修改关闭,对扩展开放)。这种自我管理的基础促成了支持 UDA 扩展的治理链。
UDA 采用了一个命名图优先的信息模型,其中每个命名图均遵循知识图谱内的管理模型。知识图谱包含三个组成部分:领域模型、数据容器表示和映射关系,它们分别定义概念、定位数据容器并将概念与物理数据源相关联。该结构为整个图谱提供了模块化、解析和治理机制。
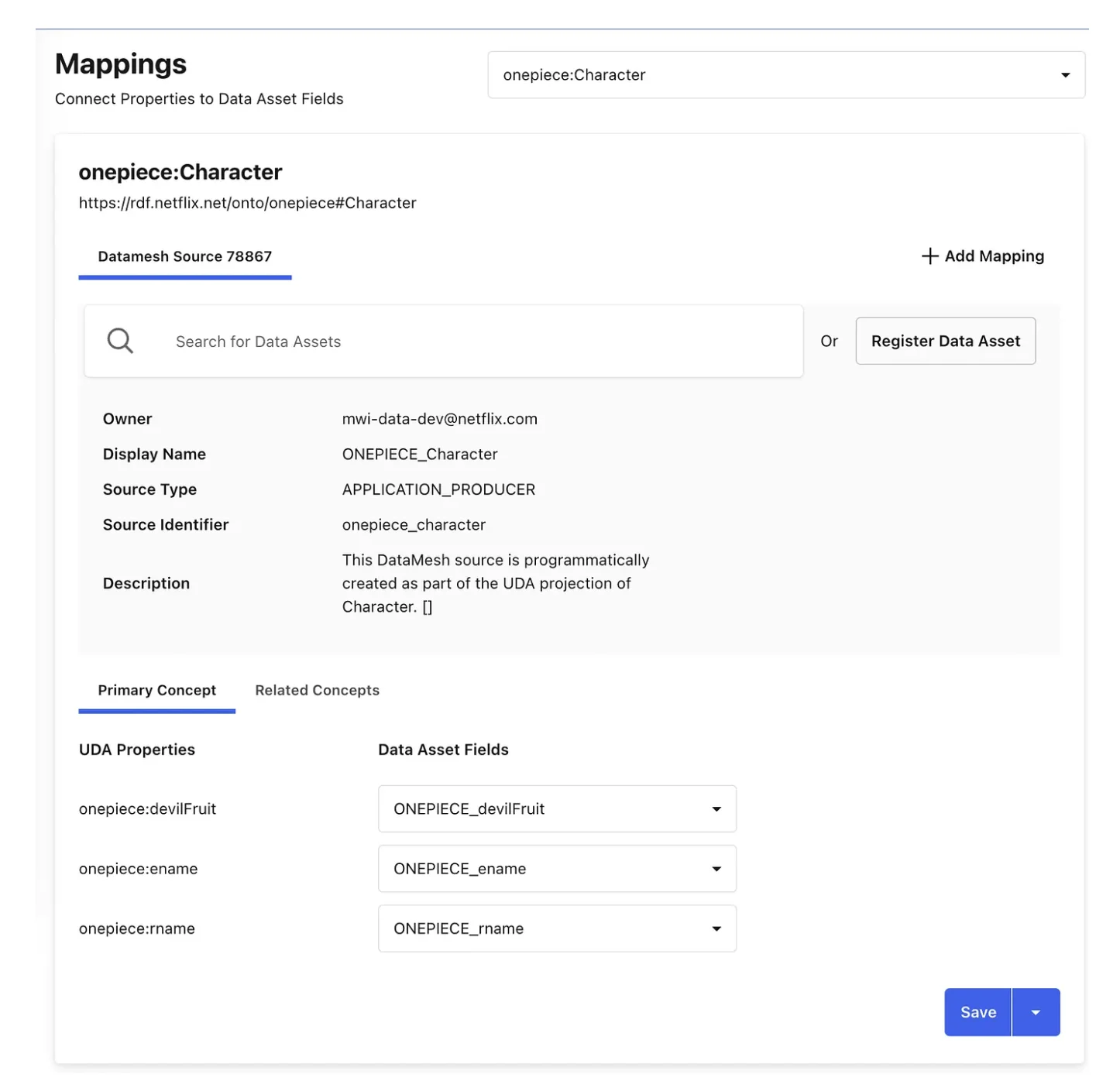
领域模型与数据网格源之间的映射(图片来源:Netflix技术博客)
在 UDA 底层,Upper 中定义的领域实体通过一个名为投影的过程转化为数据容器表示。投影会生成具体的技术工件,包括GraphQL模式、Avro记录、Apache Iceberg表、SQL模式和 Java 类型,下游系统可以消费这些工件。UDA 维护了概念定义和这些物理数据容器之间的显式映射,可以在模型演进过程中确保一致性。Netflix 工程师这样描述该方法:允许领域概念的变更自动传播至所有表示,无需人工更新,既支持工程工作流,也支持运营报告。
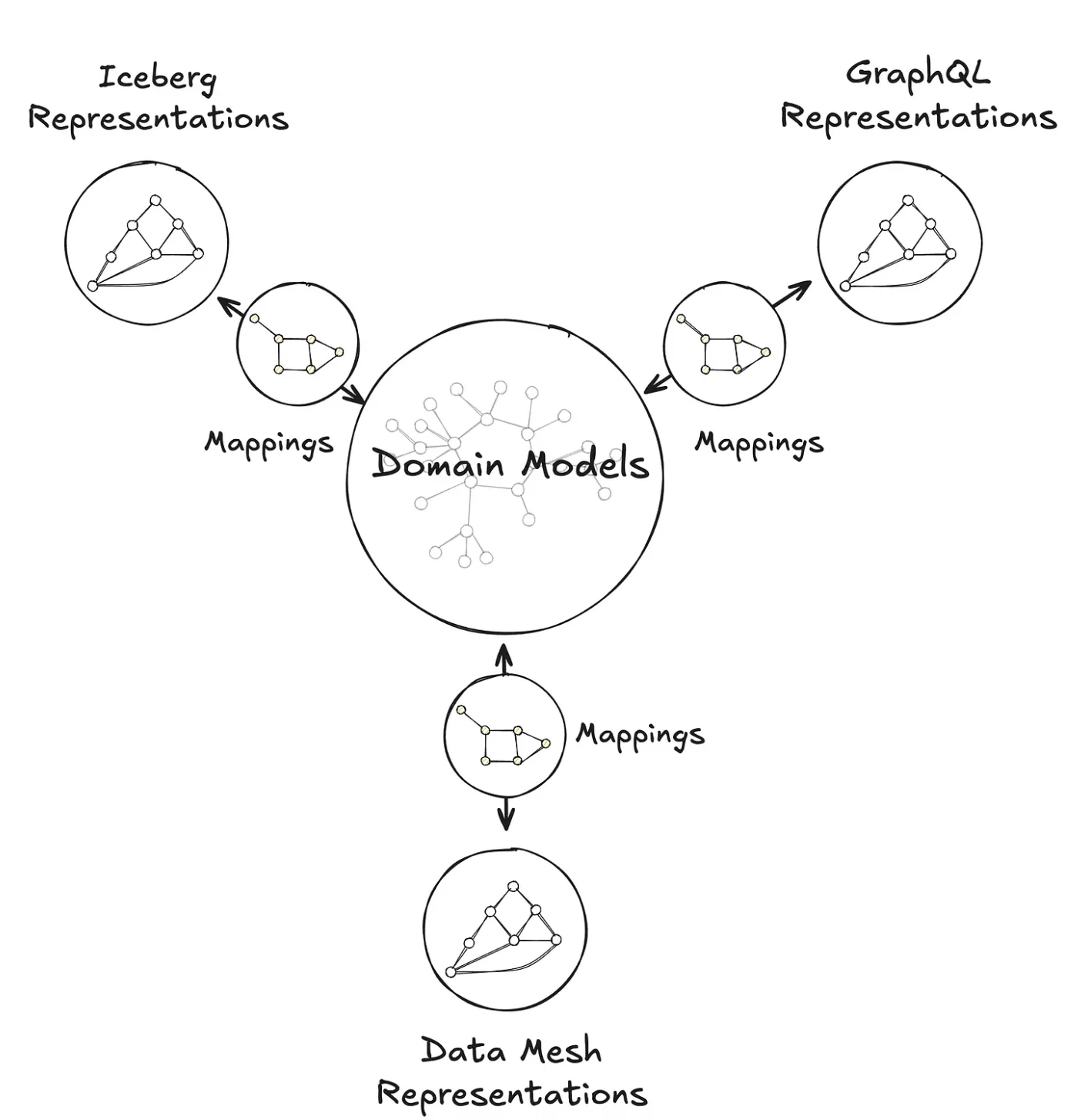
领域模型到数据容器的连接(图片来源:Netflix技术博客)
主要数据管理(PDM)和运营报告(Sphere)是最早采用 Upper 的两个团队。内容制作团队使用 UDA 跟踪资产摄取、审批和内容准备情况。广告与个性化团队利用知识图谱统一了营销活动、促销活动及定向元数据的定义,减少了人工核对工作,实现了自动化工作流生成。PDM 提供一个基于分类法的界面,使业务用户无需掌握本体语言即可浏览领域概念。Sphere 能从图谱中自动生成查询语句,最大限度地减少了手动连接的需求。
展望未来,Netflix 计划扩展 Upper 和 UDA 以支持额外的投影,如Protobuf/gRPC,物化实例数据知识图谱以供查询和分析,并解决Graph Search最初提出的挑战。Netflix 工程师致力于提升其不断扩展的内容与数据生态系统的可发现性、自动化程度及互操作性。
原文链接:
https://www.infoq.com/news/2025/12/netflix-upper-uda-architecture/




