
一年前,ZDNet 与谷歌大脑总监 Jeff Dean谈到了该公司如何使用人工智能来推进定制芯片的内部开发,从而加快软件开发。Dean 指出,在有些情况下,与人类相比,人工智能的深度学习能够更好地决定如何在芯片中布置电路。
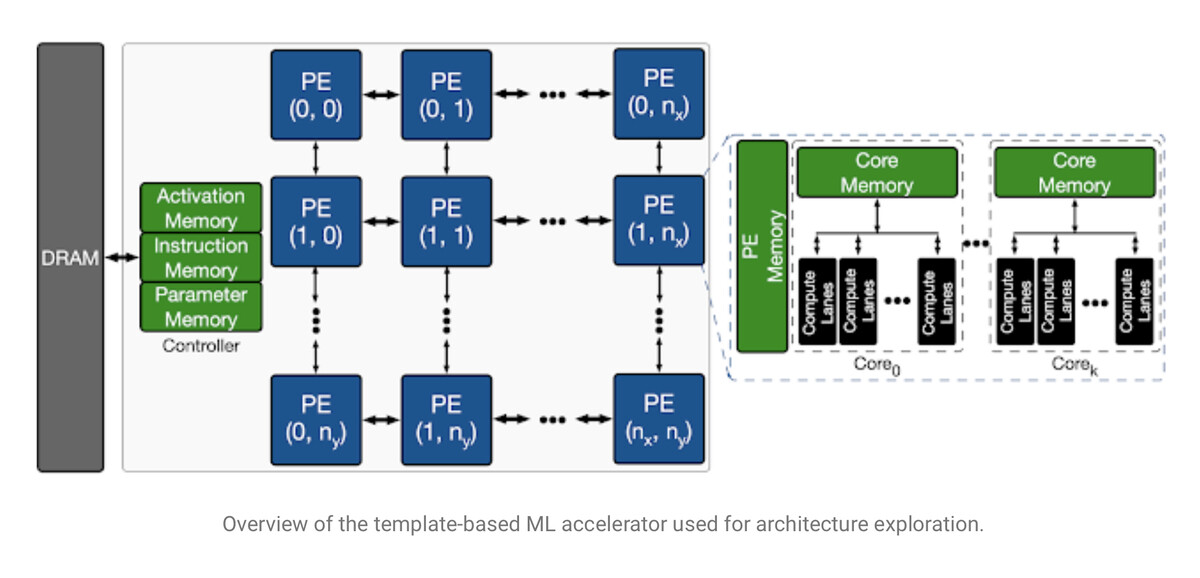
人工智能加速器芯片的所谓搜索空间,意味着芯片的结构必须优化功能模块。很多人工智能芯片的特点是拥有用于大量简单数学运算的并行、相同的处理器单元,这里称为“PE”,用于执行大量的矢量矩阵乘法运算,而这些运算是神经网络处理的主要工作。
上个月,谷歌在 arXiv 文件服务器上发布了一篇题为《Apollo:可迁移架构探索》(Apollo: Transferable Architecture Exploration)的论文,并由主要作者 Amir Yazdanbakhsh 发表了一篇博文,公开展示了其中一个名为 Apollo 的研究项目。Apollo 是一项很有意义的进展,它超越了 Dean 一年前在国际固态电路研讨会(International Solid State Circuits Conference)上的正式演讲以及在 ZDNet 上的发言中所暗示的含义。
从 Dean 当时提供的例子来看,机器学习可以被用来做一些低级的设计决定,也就是所谓的“位置和路线”。芯片设计者利用软件来确定构成芯片操作的电路布局,在位置和路线上,与建筑物的平面图设计相似。相反,在 Apollo 项目中,更多的是 Yazdanbakhsh 和他的同事所谓的“架构探索”,而非建筑物的平面图设计。
芯片的架构是设计芯片的功能元素,它们如何相互作用,以及软件程序员应该如何获取这些功能元素。例如,典型的英特尔 x86 处理器有一定数量的片内存储器、专用的算术逻辑单元和一些寄存器等等。这些部分的组合方式,赋予了所谓英特尔架构的意义。
当被问及 Dean 的描述时,Yazdanbakhsh 通过电子邮件对 ZDNet 说:“我将看到我们的工作和位置路线项目是正交且互补的。”在谈到康奈尔大学 Christopher Batten 的演讲时,他对此解释道:“架构探索远远高于计算栈中的位置和路线。”
Yazdanbakhsh 说:“我相信,在架构探索方面,还有更大的性能提升空间。”他和他的同事把 Apollo 称为“第一个可迁移的架构探索基础设施”,它是第一个可以在不同芯片上工作的程序,它对可能的芯片架构的探索能力越强,就越能把学到的东西迁移到每一个新的任务中。
Yazdanbakhsh 和团队正在开发的芯片本身就是用于人工智能的芯片,即人工智能加速器芯片。它与英伟达 A100 “Ampere” GPU、Cerebras Systems 的 WSE 芯片以及现在上市的许多其他初创公司的芯片属于同一类。所以,使用人工智能设计芯片来运行人工智能,就是一种“对称性”。
考虑到设计人工智能芯片的任务,Apollo 项目所探索的架构适合运行神经网络。它意味着大量的线性代数,大量的简单的数学单元,执行矩阵乘法和结果的求和。
该团队定义这一挑战是为了找出这些数学模块的适当组合,以适应给定的人工智能任务。他们选择了一项相当简单的人工智能任务,一种叫做 MobileNet 的卷积神经网络,它是一种资源高效网络,由谷歌的 Andrew G. Howard 和他的同事在2017 年推出。另外,他们还利用内部设计的几个网络来测试工作负载,如对象检测和语义分割等任务。这样的话,目标就变成了:芯片的架构有哪些合适的参数,使得芯片能够满足给定的神经网络任务的某些标准,比如速度?
该搜索涉及到超过 4.52 亿个参数的排序,包括要使用多少数学单元(称为处理器元素),以及有多少参数内存和激活内存最适合给定模型。
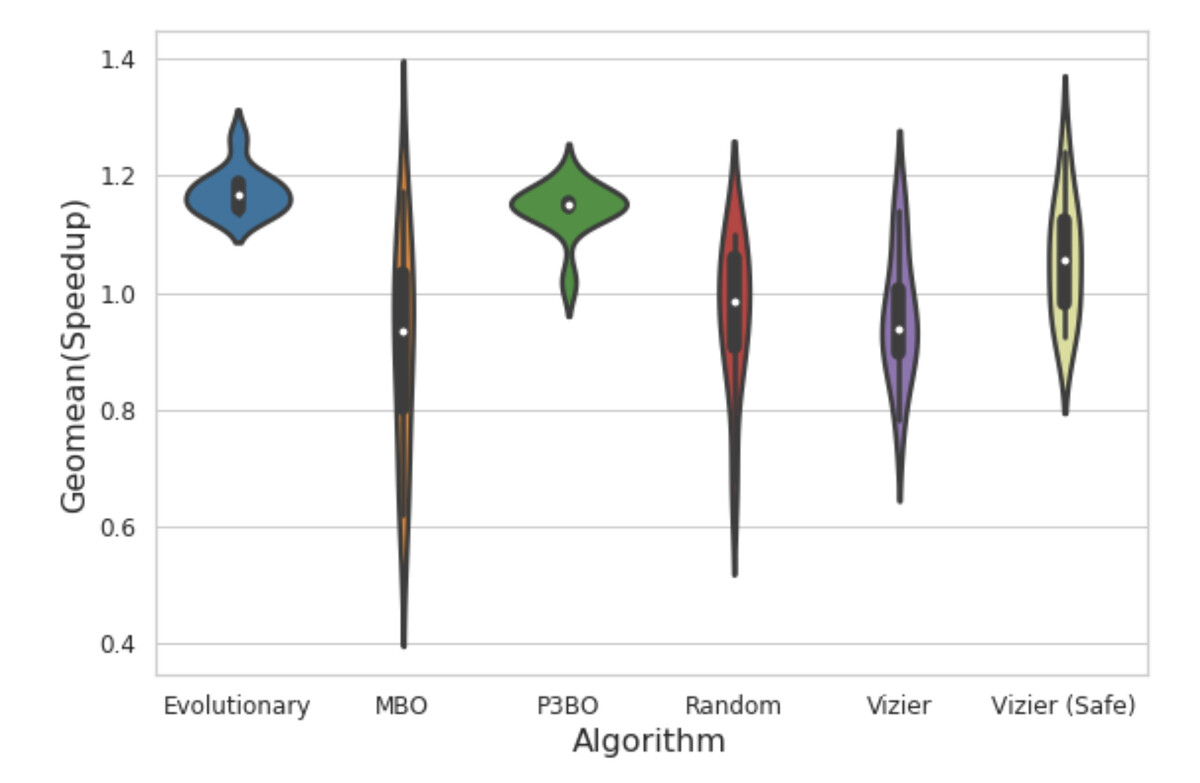
Apollo 的优势在于,它可以将各种已有的优化方法结合起来,并观察它们如何叠加来优化新颖的芯片设计架构。这张小提琴图展示了相对的结果。
译注:小提琴图(Violin Plot)是用来展示多组数据的分布状态以及概率密度。这种图表结合了箱形图和密度图的特征,主要用来显示数据的分布形状。跟箱形图类似,但是在密度层面展示更好。在数据量非常大不方便一个一个展示的时候小提琴图特别适用。
Apollo 是一种框架,它可以使用文献中开发的各种方法进行所谓的黑盒优化,它可以根据特定的工作负载调整这些方法,并比较每种方法在解决目标方面的表现。
Yazdanbakhsh 和他的同事们用一些优化方法来实现另一种对称性,它实际上是为开发神经网络架构而设计的。它们包括谷歌的 QuocV. Le 及其同事在 2019 年开发的所谓进化方法;基于模型的强化学习,以及由谷歌的 Christof Angermueller 等人开发的所谓基于群体的方法的集成,目的是“设计” DNA 序列;以及一种贝叶斯优化方法。
这样,Apollo 就包含了令人愉悦的对称性的主要层次,它把神经网络设计与生物合成设计的方法结合起来,从而设计出可反过来用于神经网络设计与生物合成的电路。
将所有这些优化进行比较,这也是 Apollo 框架的亮点。其存在的根本原因是要有条理地运用各种不同的方法,并确定哪些方法最有效。Apollo 测试的结果详细说明了进化和基于模型的方法如何优于随机选择和其他方法。
但是 Apollo 最显著的发现是,运行这些优化方法可以让过程比暴力搜索更加高效。举例来说,他们比较了基于群体的集合方法和他们称为体系结构方法的解决方案集的半穷举搜索。Yazdanbakhsh 和他的同事发现,基于群体的方法可以找到使用电路来折衷的解决方案,比如计算和内存,这通常需要了解特定领域的知识。因为基于群体的方法是一种学习型方法,所以它可以找到半穷尽式搜索所不能找到的解决方案:
P3BO(基于群集的黑盒优化)实际上是 在 3K 样本的搜索空间中找到一个比半穷举法稍好的设计。我们发现这个设计使用了一个很小的内存(3MB)来支持更多的 计算单元。它使用了视觉工作负载的计算密集型特性,这是最初的半穷尽式搜索空间没有包含的特性。研究结果表明,半穷尽式算法需要人工搜索空间工程,而基于学习的优化算法利用了较大的搜索空间,减少了人工工作。
因此, Apollo 可以计算出芯片设计中各种优化方法的表现。但是,它还可以做得更多,即运行所谓的迁移学习,以展示如何反过来改进这些优化方法。
为了改进芯片的设计点,如最大芯片尺寸(以毫米为单位),通过运行优化策略,这些实验的结果可以作为输入反馈给后续的优化方法。Apollo 团队发现,各种优化方法都是通过利用初始(或种子)优化方法的最优结果来改进它们在面积受限电路设计等任务中的性能。
这一切都要靠为 MobileNet 或任何其他网络或工作负载设计芯片这一事实来支持,因为设计过程限制了特定工作负载的适用性。事实上,作者之一 Berkin Akin 曾帮助开发过 MobileNet 的一个版本 MobileNet Edge,他曾指出,优化是芯片优化和神经网络优化的产物。
“神经网络架构必须了解目标硬件架构,从而优化整体系统性能和能效。”Akin 去年与同事 Suyog Gupta 在一篇论文中写道。
“问题很好,”Akin 在电子邮件中回答。“那得看情况了。”
Akin 说, Apollo 也许可以满足给定的工作负载,但是芯片和神经网络之间的协同优化,将来也会带来其他好处。
Akin 的答复全文如下:
我们针对给定的固定神经网络模型套件设计了硬件,当然也有一些用例。在硬件目标应用领域,这些模型可能是已经被高度优化的代表性工作负载的一部分,也可能是用户定制的加速器所需要的。本课题就是要解决这个问题,我们使用机器学习来为给定的工作负载组合寻找最佳硬件架构。当然,在某些情况下,硬件设计和神经网络体系结构可以灵活地联合优化。实际上,我们在这种联合协同优化方面已经取得了一些进展,我们希望能够做出更好的权衡……
最终结论是,即使芯片设计受到人工智能的新工作负载的影响,但芯片设计的新过程也可能对神经网络的设计产生可测量的影响,而且这种辩证关系可能在今后几年中以有趣的方式发展。
作者介绍:
Tiernan Ray,毕业于普林斯顿大学,从事技术和商业报道超过 24 年。现为 Barron 技术编辑,为 Tech Trader 博客撰写每日市场报道。曾供职于彭博社、SmartMoney 和 ComputerLetter,报道科技领域的风险投资。
原文链接:
https://www.zdnet.com/article/googles-deep-learning-finds-a-critical-path-in-ai-chips/




