
前言
搭叩 是一个面向小白和初级开发者的一站式 AI Development 产品,它的每个任务都跑在一个独立的容器内,能一站式的帮助用户完成调研,编码,调试和系统部署;支持前端,后端甚至安卓应用的开发和调试。
搭叩 这种异步的长链路任务的 Agent 存在 Tools 多,任务的复杂度更高场景更丰富,执行步骤多等特点;我们发现长时间、复杂任务的执行面临着一个核心挑战:上下文窗口限制。随着对话轮次的增加,历史消息、工具调用结果、环境状态信息等内容会迅速累积,导致 token 消耗呈指数级增长。当上下文超出模型的处理能力时,系统要么截断历史信息导致"失忆",要么直接崩溃无法继续工作。
这不仅仅是一个技术限制问题,更关乎 AI Agent 能否真正承担起复杂的、需要长期规划和执行的任务。一个真正实用的 AI Agent 系统,必须能够在有限的上下文窗口内,既保留关键历史信息,又能持续获取最新的环境状态,还要支持多 Agent 协作和能力动态扩展。
搭叩 (Dakou) 在实践中总结并 开创 了一套系统化的解决方案,包含上下文压缩、上下文替换、上下文保留、上下文锚定、上下文合并、上下文共享和工具动态扩展七大核心优化策略。这些策略并非简单的组合,而是相互协同,共同构建了一个高效、可靠的上下文管理体系,其中多项关键设计均为业界首次提出。本文将深入剖析这七大策略背后的问题、思路、竞品调研和方案选择的理由,希望能为 AI Agent 的开发者提供参考和启发。
上下文压缩 - 过长自动压缩上下文
遇到的问题
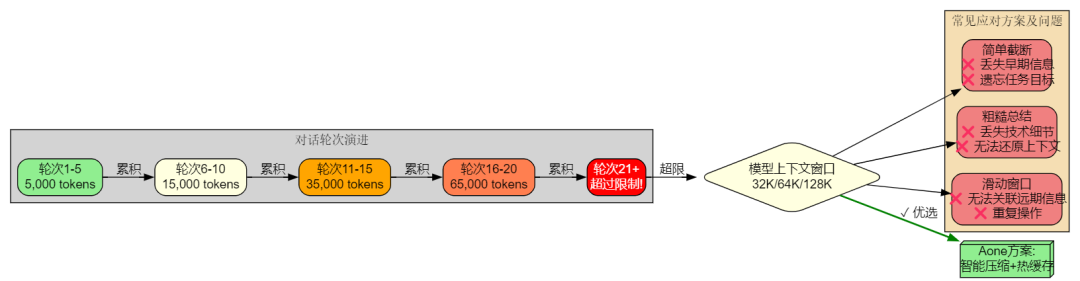
在实际应用中,我们发现 AI Agent 在执行复杂任务时,对话历史会迅速累积:
Token 快速增长:一个涉及代码开发的任务,可能在 10-20 轮对话后就产生数万 token 的历史记录
信息截断困境:简单截断最早的消息会导致 Agent"遗忘"任务目标、已完成的工作和重要的上下文信息
执行连续性受损:当 Agent 无法访问完整历史时,容易出现重复执行已完成的操作、忘记用户的特殊要求等问题
这些问题在长时间任务中尤为突出。比如一个需要修改多个文件、运行测试、调试错误的开发任务,如果中途因为上下文超限而丢失了前期的修改记录,Agent 可能会做出错误的决策。
解决思路
我们采用了 智能压缩而非简单截断 的策略:
LLM 驱动的语义压缩:使用大语言模型本身来理解和压缩历史对话,提取关键信息而非机械地删除或总结
分批递归处理:当单次压缩的内容仍然超过模型限制时,自动进行分批压缩,先压缩前半部分,再将压缩结果与后半部分合并后继续压缩
场景化压缩策略:
任务进行中:保留任务概览、已执行步骤、当前状态、下一步计划等关键信息
任务完成时:侧重整体执行流程、关键发现、最终状态和任务结果的完整总结
热缓存机制:不是压缩全部历史,而是保留最近的对话(特别是最后一次工具调用及其结果)作为"热缓存",确保 Agent 能够清晰地了解最新情况
异步压缩机制:当检测到 token 接近限制时,启动异步压缩 goroutine,主流程使用条件变量等待压缩完成,避免阻塞用户交互
多模态内容过滤:压缩前提取图片引用信息,非多模态模型自动过滤 ContentItems 中的 image_url,压缩完成后还原图片到正确位置
主压缩流程图:

异步压缩机制流程图:

多模态内容过滤流程图:

竞品调研
我们调研了业界主流的记忆管理方案:
LangChain 的 ConversationSummaryMemory:使用 LLM 定期总结对话历史,但总结较为粗糙,容易丢失技术细节
AutoGPT 的滚动窗口:采用固定大小的滑动窗口,超出部分直接丢弃,简单但会丢失早期重要信息
Microsoft Semantic Kernel:将记忆分为短期和长期,但两者的切换和检索机制较为复杂
这些方案各有优劣,但都存在一些不足:
简单总结难以保留技术细节和执行脉络
固定窗口无法适应不同任务的复杂度
复杂的检索机制增加了系统开销
方案选择原因
我们最终选择了 热缓存 + 智能压缩 的混合策略,原因如下:
平衡信息完整性和效率:热缓存保证最新信息不经压缩直接可用,压缩历史则用语义浓缩的方式保留关键内容
定制化压缩质量:针对任务完成和进行中两种状态设计不同的压缩 prompt,确保提取的信息符合当前需求。比如任务进行中强调"下一步计划",任务完成时强调"整体总结"
多模态信息保留:特别设计了图片引用的提取和还原机制,确保包含截图、图表等多模态信息的任务不会丢失这些关键内容
递归压缩兜底:当单次压缩仍然超限时,自动启动分批递归压缩,确保系统在极端情况下仍能正常工作
结构化输出:压缩结果采用 XML 结构化格式,包含任务概览、执行步骤、文件操作、命令执行等明确分类的信息,便于后续解析和利用
这种方案在实践中取得了良好效果,能够将数万 token 的历史压缩到几千 token,同时保留 80-90% 的关键信息。
上下文保留 - Dashboard 固定区域减少检索
遇到的问题
我们发现 Agent 在执行任务时,经常需要"回头看"自己做了什么:
状态查询频繁:Agent 每隔几轮就会调用"查看编辑历史"、"列出当前会话"等工具,消耗额外的 token 和推理时间
信息分散:文件编辑记录在某条消息中,终端输出在另一条消息中,Agent 需要"翻阅"大量历史才能建立完整认知
决策依据不足:没有集中的状态展示,Agent 可能忘记自己已经做过某件事,导致重复操作
比如,Agent 修改了文件 A、B、C 后去运行测试,测试失败后它可能不记得已经修改过哪些文件,又去调用工具查询,这种重复查询在长任务中非常常见。

解决思路
我们引入了 Dashboard 固定区域 的概念:
实时状态聚合:系统维护了多个管理器(FileHistoryManager、TerminalManager、BrowserManager),实时统计和追踪各类操作
固定位置展示:在每次最新的用户消息中,固定添加一个
当前时间
最近执行的操作
IDE 状态(编辑了哪些文件、多少次、最后操作时间)
终端状态(活跃会话、当前目录、最近命令)
浏览器状态(打开的标签页、当前 URL)
操作指引:dashboard 中还包含 Operation Guidance,提醒 Agent 要用中文回复、要报告上一步动作、要并行执行独立操作等最佳实践

竞品调研
我们借鉴了两个产品的理念:
IDE 编辑器页面:IDE 的界面通常左侧有一个环境面板,显示文件树、下方显示终端等信息,这给了我们启发——将环境状态集中展示
Replit Agent 的状态展示:Replit Agent 在对话中会插入状态卡片,展示当前的开发环境信息
这些产品验证了"集中展示环境状态"的价值,但它们的实现方式各有特点:
Devin 依赖复杂的 UI 组件
Replit Agent 的状态卡片更新频率和内容较为固定
方案选择原因
我们选择了纯文本的结构化 Dashboard,原因包括:
减少工具调用:Agent 不再需要频繁调用工具查询状态,直接从 dashboard 中获取信息,每次任务可减少 5-10 次工具调用
认知负担降低:所有关键状态在一个位置呈现,Agent 建立"局势感知"的成本大幅降低
实现简单高效:不依赖复杂的 UI,纯文本的 XML 格式在任何接口(CLI、Web、API)中都能使用
内容动态性:dashboard 内容完全自动生成,无需手动维护,随着操作的发生实时更新
指引作用:通过 Operation Guidance,可以"教育"模型形成良好的工作习惯,比如并行执行、及时报告等
实践表明,引入 Dashboard 后,Agent 的任务执行效率提升了约 20-30%,无效的状态查询减少了 50% 以上。
上下文替换 - 将工具结果删除仅保留最新
遇到的问题
在 Agent 执行过程中,我们观察到一个明显的 token 浪费现象:
Dashboard 信息冗余:每次对话都会在用户消息中附带当前环境状态(文件编辑历史、终端会话、时间等),但历史消息中的 dashboard 已经过时,却仍然占用大量 token
工具结果重复:某些工具(如查看文件、列出目录)可能在不同时刻被重复调用,产生大量相似的输出
实时性问题:Agent 需要看到的是"此时此刻"的环境状态,而不是历史快照
举个例子,如果 Agent 在第 5 轮对话时看到"当前时间是 10:00,编辑了 3 个文件",到了第 20 轮时,这些信息早已过时,但仍然在上下文中占据位置。

解决思路
我们设计了一套 动态替换机制:
定位最新用户消息:系统会自动找到最新的用户消息位置
清理历史 dashboard:遍历之前的所有用户消息,使用正则表达式移除其中的
... 注入最新 dashboard:在最新用户消息末尾添加实时生成的 dashboard
ContentReplace 机制:为了保留审计和调试能力,我们在消息对象中保存了原始内容(Content)和替换内容(ContentReplace),在压缩时使用替换内容,但日志中保留原始内容

竞品调研
我们特别关注了两个产品的设计:
Devin 的 Dashboard 设计:Devin 在界面上有独立的环境面板,但这是 UI 层面的隔离,在发送给模型的 prompt 中如何处理并不透明
Cursor 的 Context Management:Cursor 会动态管理可见的上下文,但主要依赖用户手动控制哪些文件进入上下文
与这些方案相比:
Devin 的方案更侧重 UI 展示,没有解决底层 prompt 冗余问题
Cursor 的方案需要用户参与,不适合全自动的 Agent 场景
方案选择原因
我们选择在消息层面做替换,而非 UI 层面隔离,原因是:
确保实时性:Agent 每次推理时都能看到最新的环境状态,避免基于过时信息做决策
节省 token:历史消息中删除过时的 dashboard,可以节省数百到数千 token
保持审计能力:通过 ContentReplace 机制,既优化了发送给模型的内容,又保留了完整的历史记录用于调试
XML 结构化:使用
对模型透明:模型只需要正常处理用户消息,不需要理解特殊的上下文管理机制
这种方案实现简单、效果明显,在实际使用中显著减少了无效 token 的占用。
上下文锚定 - ChatDashboard 收集关键信息节点防止目标漂移
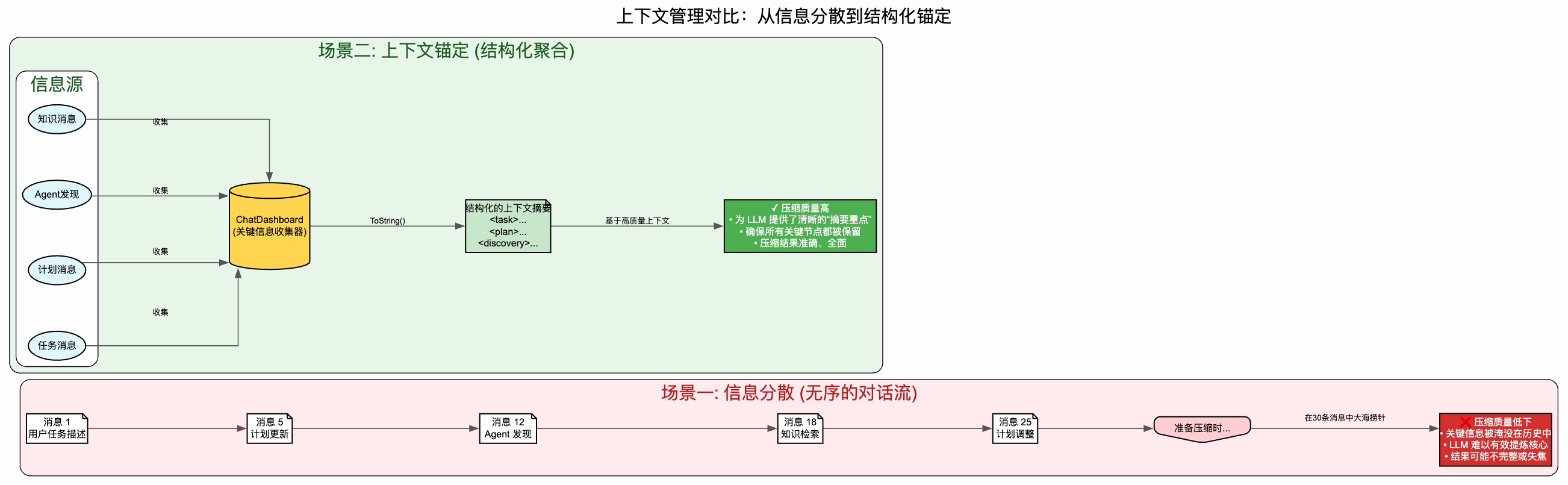
在长时间、多轮次的任务执行中,我们发现了一个严重的"关键信息分散"问题:
关键节点丢失:用户的初始任务、计划更新、Agent 的重要发现等关键节点信息,散落在大量的对话历史中
压缩参考缺失:进行历史压缩时,缺少一个清晰的"关键信息摘要"来指导 LLM 判断什么是重要的
多 Agent 协作困难:不同 Agent 之间缺少一个统一的"任务上下文"视图,难以理解任务的整体脉络
知识整合困难:检索到的知识、生成的计划、Agent 的思考等信息没有统一的组织形式
上下文不可见:Agent 的仅有部分上下文对用户可见,Agent 在执行过程中因为不可见上下文会忘记自己回答了用户什么问题
例如,一个任务经过 20 轮对话后,包含了最初的任务描述、2 次计划更新、5 条 Agent 的重要发现、3 段检索的知识。这些信息散落在历史消息中,压缩时 LLM 难以快速定位和评估这些关键信息的重要性。
目标漂移问题场景:
解决思路
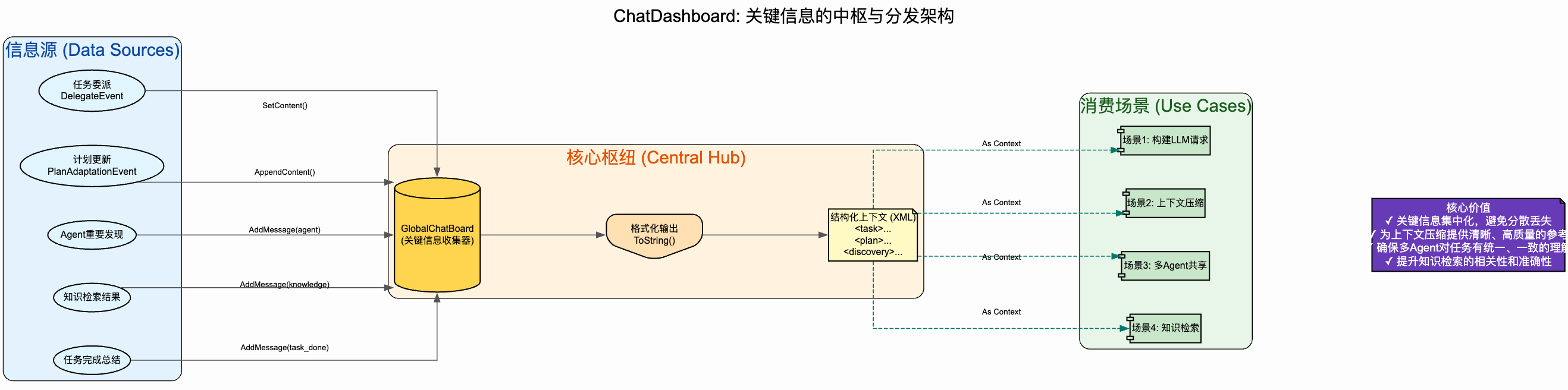
我们引入了 上下文锚定(ChatDashboard)机制,它是一个关键信息收集器:
多类型消息收集:系统维护一个全局的 GlobalChatBoard,收集整个任务过程中的关键信息:
Task 类型:初始任务描述(通过 SetContent 设置)
Plan 类型:任务计划和计划更新(通过 AppendContent 追加)
Agent 类型:Agent 的重要消息和发现(带 AgentID 和时间戳)
Knowledge 类型:检索到的相关知识
TaskDone 类型:任务完成的总结(带任务名称)
结构化存储:将收集的消息按类型格式化为 XML 结构,例如:
任务描述 重要发现 完成总结 压缩时作为上下文:调用 GetCurrentTask() 获取格式化的 XML 字符串,作为 ChatDashBoard 参数传入压缩请求,提供给 LLM 作为
多 Agent 共享:在 MemoryShareEvent 中同时传递 ChatDashboard 内容,确保接手的 Agent 也能看到完整的任务上下文
自动维护:系统在关键节点自动调用 AddMessage 添加信息,无需手动管理
上下文锚定数据结构示例:
<!-- ToString() 生成的 XML 格式 --><task>开发一个用户认证系统,支持 JWT token 和会话管理</task><plan>执行计划:1. 设计用户表结构2. 实现 JWT 生成和验证3. 开发登录 / 登出接口</plan><agent id='coder' time='2024-10-14 10:30:15'>发现需要使用 bcrypt 进行密码加密,确保安全性</agent><knowledge>JWT 最佳实践:- 使用 HS256 算法签名- 设置合理的过期时间- 在 header 中传递 token</knowledge><agent id='coder' time='2024-10-14 11:15:22'>计划调整:增加 token 刷新机制</agent><task_done_summary task='用户认证系统' time='2024-10-14 12:00:00'>已完成用户认证系统,包含注册、登录、登出、token 刷新功能</task_done_summary>架构流程图:
竞品调研
我们研究了业界在"关键信息组织"方面的实践:
LangChain 的 Memory 机制:提供了多种 Memory 类型(ConversationBufferMemory、SummaryMemory 等),但都是线性的对话历史,缺少对关键节点的特殊标记
AutoGen 的 Agent Message:Agent 之间通过消息传递,但缺少对关键消息的分类和汇总机制
Devin 的 Session Context:维护会话上下文,但主要是状态信息,没有对不同类型信息的结构化组织
这些方案的局限性:
缺少对不同类型信息(任务、计划、发现、知识)的分类管理
没有统一的格式化输出机制
与压缩和共享机制的集成度不够
方案选择原因
我们选择了 GlobalChatBoard 这种分类收集和结构化输出的方案,原因包括:
分类收集:将不同类型的关键信息(任务、计划、Agent 消息、知识、完成总结)分类收集,便于后续组织和检索
自动维护:系统在关键事件点(任务接收、计划更新、知识检索、任务完成)自动添加消息,无需手动管理
结构化输出:ToString() 方法将收集的信息格式化为清晰的 XML 结构,便于 LLM 理解和解析
压缩指导:作为 conversation_context 提供给 LLM,清晰标识哪些是任务描述、哪些是计划、哪些是发现,让压缩更有针对性
多场景复用:
构建 ModelRequest 时作为初始用户消息
压缩历史时作为参考上下文
知识检索时作为查询上下文
多 Agent 共享时传递完整任务脉络
容量控制:最多保存 1000 条消息,超出时自动删除最旧的,避免无限增长
实践效果:
压缩精准度提升:有 ChatDashboard 指导的压缩,关键节点信息保留率接近 90%
知识检索更准:提供结构化的任务上下文,检索相关性提高 35%
多 Agent 协作顺畅:新 Agent 接手时能快速理解任务全貌,减少 50% 的上下文理解时间
Token 效率提升:相比保留完整历史,只占用 500-2000 tokens,节省 80% 以上
上下文合并 - 合并相同工具结果减少 Token
遇到的问题
即使有了压缩机制,我们仍然发现压缩后的内容中存在大量冗余:
文件操作重复:同一个文件被编辑了 10 次,每次都记录完整的操作信息,但实际上中间状态可能并不重要
命令执行冗余:某些探索性的命令(如多次尝试不同参数)全部被记录,但最终只有成功的那次有价值
状态快照过多:压缩后的记忆中保存了大量时间点的状态快照,但趋势和变化才是关键
例如,开发一个功能时,Agent 可能修改某个文件 5 次才达到正确状态,如果这 5 次修改都完整保留,会占用大量 token,但实际上只需要知道"这个文件从初始状态变为最终状态"即可。
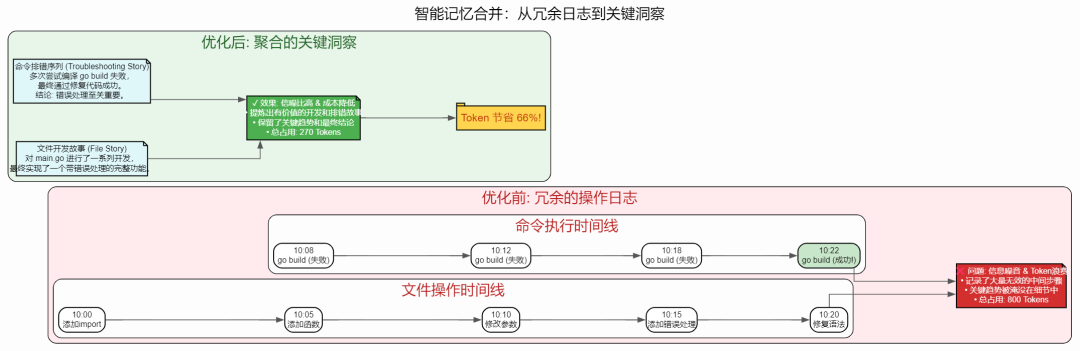
解决思路
我们在压缩阶段引入了 结构化解析和智能合并:
XML 结构化存储:将文件操作解析为
索引化管理:使用
fileOp_0_path、fileOp_0_action、cmd_1_text等索引化的 key 存储到缓存中,避免重复的完整内容优先级策略:在压缩 prompt 中明确告知 LLM 哪些信息优先级高(核心文件的最终状态、troubleshooting 完整序列),哪些可以合并(临时文件、探索性命令)
保留关键序列:特别强调保留"失败→解决→成功"的完整 troubleshooting 序列,因为这些是 Agent 学习和改进的关键信息
工具结果分片:对于超长工具输出(>18000 tokens),自动分割成多个 part,在分片间插入 assistant 确认消息,最多分割 8 个 part 后截断
消息规范化:合并连续的相同角色消息,确保 user/assistant 严格交替,system 消息统一置顶,避免消息序列混乱
主合并流程图:
工具结果分片流程图:
消息规范化流程图:

竞品调研
我们研究了几个相关的实现:
LangChain 的工具调用缓存:主要用于避免重复执行相同参数的工具,但不处理结果的合并
AutoGen 的结果去重机制:基于哈希值检测重复的工具输出,但无法处理"部分相同"的情况
这些方案主要解决的是"完全相同"的重复问题,而我们面临的是"部分相同、逐步演进"的场景,需要更智能的合并策略。
方案选择原因
我们最终选择了"LLM 指导的结构化合并"方案,原因是:
语义理解能力:LLM 能够理解"修改文件 A 三次"的语义,知道只需要保留最终状态和关键中间步骤
灵活性高:通过调整压缩 prompt 中的优先级策略,可以适应不同类型任务的需求
保留完整性:对于 troubleshooting 序列等关键信息,明确要求完整保留,平衡了压缩和完整性
结构化便于扩展:XML 结构化存储使得后续如果需要程序化处理(如进一步去重、统计分析)变得容易
token 效率提升:在实际测试中,这种合并策略可以额外减少 30-40% 的压缩后 token
这个方案的关键在于"指导 LLM 如何合并"而不是"强制合并所有重复",保持了灵活性和智能性的平衡。
上下文共享 - 多 Agent 共享记忆和工具结果
遇到的问题
在多 Agent 协作场景下,我们遇到了明显的信息孤岛问题:
独立上下文:每个 Agent 维护自己的对话历史和压缩记忆,彼此无法感知其他 Agent 的工作
重复探索:Agent A 已经探索过项目结构、读取了关键文件,Agent B 接手任务后又要重新做一遍
经验无法传递:Agent A 解决了某个问题(如修复了编译错误),Agent B 遇到类似问题时无法利用这个经验
例如,一个 Clarifier Agent 与用户交互明确了需求,生成了详细的任务规划,但当 Coder Agent 开始工作时,它只能通过任务描述了解需求,无法直接访问 Clarifier Agent 的完整上下文和思考过程。

解决思路
我们设计了基于 事件总线的异步记忆共享 机制:
MemoryShareEvent:定义了记忆共享事件,包含压缩后的记忆内容和 chatDashboard
任务完成时发布:当一个 Agent 完成任务并进行上下文压缩后,自动发布 MemoryShareEvent 到事件总线
选择性订阅:其他 Agent 可以根据自己的需要订阅这些事件,获取共享的记忆
压缩后传输:共享的是压缩后的记忆而非完整历史,控制了传输的数据量

竞品调研
多 Agent 协作是当前 AI Agent 领域的热点,我们重点研究了:
Microsoft AutoGen 的多 Agent 通信:Agent 之间通过对话消息进行交互,可以转发历史消息,但这种方式会导致上下文快速膨胀
CrewAI 的团队记忆共享:引入了 Crew 级别的共享记忆,但更新机制较为集中化,需要显式管理
LangGraph 的状态共享:通过图状态节点在 Agent 间传递信息,但需要预先定义状态结构
这些方案各有特点:
AutoGen 的对话式共享最灵活,但效率较低
CrewAI 的集中式管理最可控,但灵活性受限
LangGraph 的状态共享最结构化,但需要预先设计
方案选择原因
我们选择了事件驱动的异步共享方案,原因如下:
低耦合:Agent 之间不需要直接引用或调用,通过事件总线解耦,一个 Agent 的故障不会影响其他 Agent
选择性订阅:不是所有 Agent 都需要所有记忆,通过订阅机制可以过滤无关信息,避免"信息过载"
适中的数据量:共享的是压缩后的记忆(几千 token),而不是完整历史(数万 token),传输和存储成本可控
时机恰当:在任务完成时发布,这个时机记忆已经被压缩和结构化,质量最高
扩展性好:未来可以引入记忆检索、记忆评分等机制,在事件总线基础上演进
这种方案特别适合搭叩 (Dakou) 的场景:多个专业 Agent(Clarifier、Planner、Coder、WebSearch 等)在不同阶段工作,它们需要共享关键信息但又保持独立性。
工具动态扩展 - DAG 管理减少 Prompt 同时动态增加能力
遇到的问题
随着搭叩 (Dakou) 功能的丰富,我们积累了 100+ 个工具,这带来了严重的 prompt 管理问题:
Prompt 过长:如果在 system prompt 中列出所有工具的名称、描述和参数,会占用 8000-10000 token,压缩了实际任务的空间
依赖关系混乱:某些工具依赖其他工具才有意义(如 undo_edit 依赖先有 edit 操作),但没有机制表达这种关系
能力固化:Agent 在初始时就拥有所有工具,但实际上很多工具在任务早期根本用不上,却占用了 prompt 空间
学习曲线陡峭:过多的工具选择让 Agent(尤其是能力较弱的模型)难以选择合适的工具
一个典型场景:初始阶段 Agent 只需要基本的文件读写、代码搜索等工具,但 prompt 中却包含了浏览器操作、云手机控制、三维建模等工具的描述,造成严重的"信息噪音"。
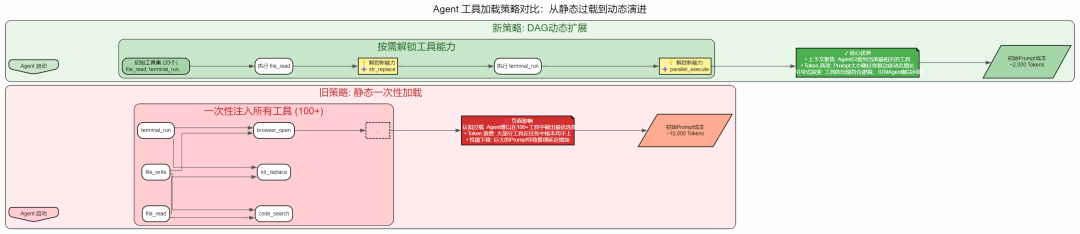
解决思路
我们构建了 工具依赖 DAG(有向无环图) 管理系统:
依赖关系定义:每个工具在注册时声明自己依赖哪些其他工具,形成依赖关系图
初始基础集:系统启动时只启用没有依赖的基础工具(如 file_read、terminal_run、message_user 等)
动态启用:当 Agent 使用了某个工具后,系统自动检查并启用依赖于这个工具的其他工具
只增不删:工具一旦被启用就不会被移除,确保 Agent 的能力是单调递增的,不会突然"失能"
LeastOne 特殊依赖:支持定义"至少使用过一个工具"这种特殊依赖,用于在 Agent 有过工具使用经验后再启用某些高级工具
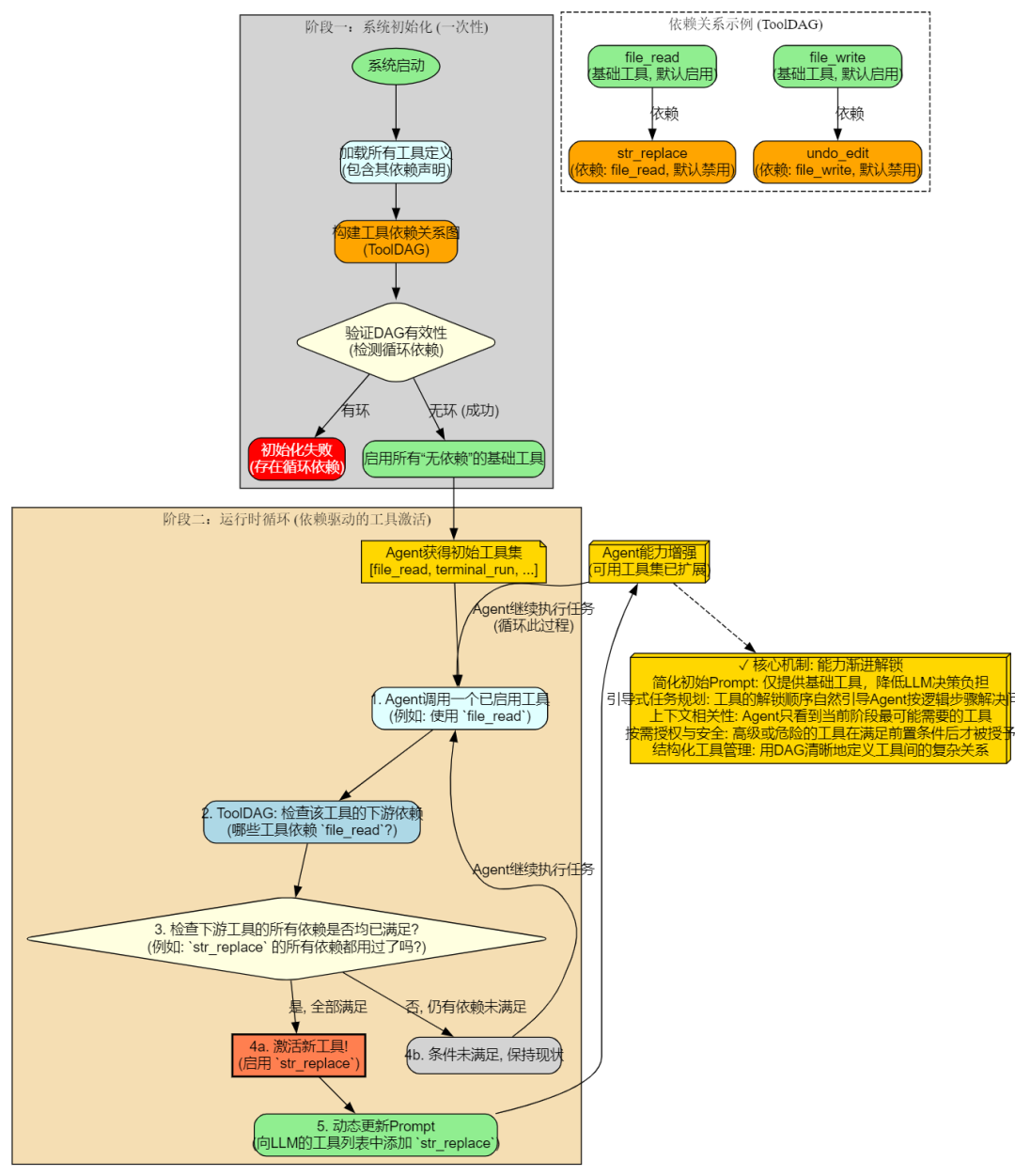
竞品调研
工具管理是 AI Agent 系统的核心挑战之一,我们研究了:
LangChain 的 Tool Calling 机制:所有工具平铺在一个列表中,依赖 Agent 自己的智能来选择。对于工具数量较少(<20)的场景有效,但扩展性不足
ToolLLM 的工具检索:将工具向量化后存储,根据任务描述检索相关工具。这种方案能处理大规模工具,但检索准确性依赖 embedding 质量,且无法表达依赖关系
Gorilla 的 API 调用学习:通过微调模型让其学习工具调用模式,但这需要大量训练数据,且难以快速迭代新工具
这些方案的共同问题是:
缺乏对工具之间关系的建模
静态配置,无法根据任务进展动态调整
难以平衡初始简洁性和后期完整性
方案选择原因
我们选择 DAG + 动态加载的方案,理由充分:
依赖关系显式化:DAG 结构清晰表达了工具之间的依赖关系,例如 undo_edit 必须在有过 edit 操作后才启用,这符合直觉且易于维护
初始 Prompt 精简:只注入基础工具,初始 prompt 可以减少到 2000-3000 token,为任务描述和思考留出更多空间
渐进式复杂化:随着任务的推进,Agent 逐步获得更多能力,这种"成长曲线"符合任务的自然演进,也降低了模型的选择负担
能力单调性:只增不删的策略保证 Agent 不会因为某些机制突然"忘记"如何使用某个工具,提供了能力的确定性
DAG 的可靠性保证:有向无环图确保不会出现循环依赖,系统在初始化时就能检测和拒绝不合理的依赖定义
灵活的启用条件:LeastOne 这种特殊依赖允许我们定义复杂的启用逻辑,例如"在 Agent 有过至少一次工具使用经验后,再给它提供并行执行工具"
实践中,这个方案带来了多重收益:
初始 prompt 减少 60-70%
工具选择错误率降低约 40%(因为选项更少、更相关)
系统启动时间减少(不需要预加载所有工具)
维护成本降低(依赖关系集中管理)
特别值得一提的是,这个方案为未来的演进留下了空间。我们可以在此基础上:
加入工具推荐机制(当检测到某种任务模式时,主动建议启用某些工具)
引入工具使用统计和学习(记录哪些工具组合最有效)
支持工具的热插拔(在运行时动态注册新工具到 DAG)
协同效应与未来展望
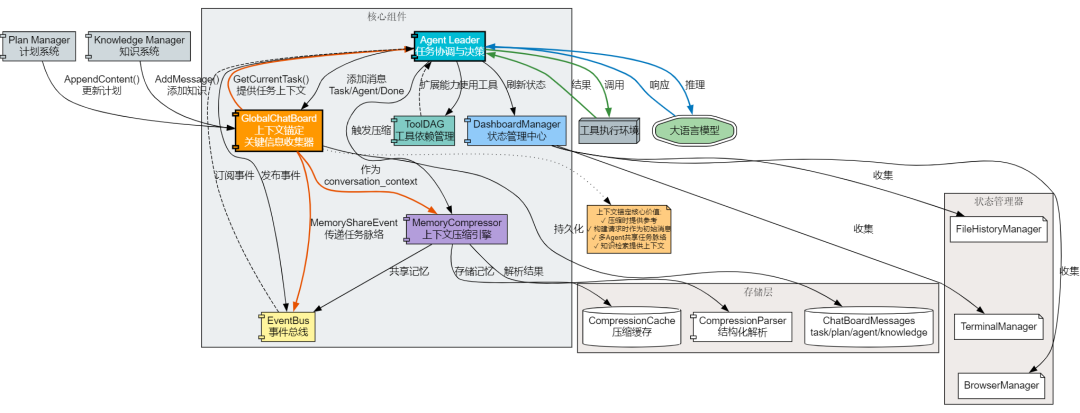
以上七大策略并非孤立存在,而是协同工作,形成了一个完整的上下文管理体系:
协同工作机制
压缩 + 替换 + 保留:压缩处理历史信息,替换更新过时内容,dashboard 保留实时状态,三者配合确保上下文始终保持"精炼、准确、完整"
锚定 + 压缩:上下文锚定收集关键节点信息,为压缩提供明确的参考上下文,大幅提升压缩质量和准确性
锚定 + 共享:上下文锚定不仅指导压缩,还通过事件总线在多 Agent 间共享,确保任务脉络的一致性
合并 + 共享:合并减少单个 Agent 的上下文冗余,共享让多 Agent 能够利用彼此的工作成果,避免重复劳动
动态扩展 + 压缩:动态扩展控制初始 prompt 大小,为压缩后的记忆留出空间;反过来,压缩机制确保即使工具逐步增多,历史上下文也不会失控
这种协同产生的效果是:
Token 效率提升 3-5 倍:同样的任务,优化后的 token 消耗只有优化前的 20-30%
任务执行时间缩短:减少无效的状态查询和重复操作,任务完成时间缩短 20-40%
支持更长的任务周期:原本只能支持 20-30 轮对话的系统,现在可以稳定运行 100+ 轮
实践价值
这套七大策略在搭叩 (Dakou) 的实际应用中验证了其价值:
复杂开发任务:从需求分析、代码实现、测试调试到部署,完整流程可以在单个 Agent 会话中完成
长时间运维任务:持续监控、问题诊断、修复验证等需要长周期执行的任务得以实现
多 Agent 协作:Clarifier 明确需求→Planner 制定计划→Coder 实现功能→WebSearch 查找资料,各 Agent 通过上下文锚定和共享机制高效接力
任务目标一致性:通过上下文锚定 (ChatDashDoard),即使经过多次压缩和多个 Agent 协作,仍能保持对用户原始需求的准确理解
成本控制:Token 消耗的减少直接降低了 API 调用成本,在大规模使用场景下节省显著
技术挑战与限制
当然,这套方案也并非完美,仍然存在一些挑战:
压缩质量依赖模型:智能压缩依赖 LLM 的理解能力,当模型能力不足时,可能丢失关键信息
事件总线开销:随着 Agent 数量增加,事件总线可能成为性能瓶颈,需要进一步优化
DAG 维护成本:随着工具数量增长,依赖关系的定义和维护需要团队的共识和规范
状态一致性:多 Agent 共享记忆时,如何确保状态的一致性和时效性仍需改进
未来优化方向
基于当前的实践和遇到的问题,我们规划了以下优化方向:
自适应压缩:根据任务类型、模型能力、历史质量等因素,动态调整压缩策略和比例
增量压缩:不是每次都重新压缩全部历史,而是对新增部分进行增量压缩,提升效率
记忆检索:引入向量数据库,将压缩记忆向量化存储,支持语义检索历史信息
工具推荐:基于任务描述和当前进展,智能推荐下一步可能需要的工具,主动扩展
跨会话记忆:探索将某些通用知识(项目结构、编码规范等)持久化,在新会话中快速加载
压缩质量评估:引入自动化机制评估压缩后记忆的质量,发现压缩不足或过度的情况
对 AI Agent 发展的启示
通过搭叩 (Dakou) 七大策略的实践,我们总结出一些对 AI Agent 上下文管理的普遍性认识:
上下文是稀缺资源:在可预见的未来,上下文窗口仍然是限制 AI Agent 能力的关键因素,必须精心管理
智能压缩优于简单截断:利用 LLM 自身的理解能力进行语义压缩,远比机械的截断或总结效果好
结构化是关键:无论是 dashboard、上下文锚定、压缩记忆还是工具描述,结构化的信息更容易管理和利用
关键节点需要标记:在信息流中标记和收集关键节点(任务、计划、发现),为后续处理提供明确参考
动态性胜过静态性:无论是工具集合还是上下文内容,动态调整和演进的系统更有生命力
协同设计很重要:单一策略难以解决所有问题,需要多种机制协同工作
结语
AI Agent 的上下文管理是一个系统工程,需要在多个维度上进行优化。搭叩 (Dakou) 通过 压缩、替换、保留、锚定、合并、共享、动态扩展 七大策略,构建了一个高效、可靠、可扩展的上下文管理体系。
这些策略不是一蹴而就的,而是在实践中不断迭代、优化、演进的结果。它们也不是最终答案,随着 LLM 能力的提升、工程技术的进步,必然会有更好的方案出现。
但我们相信,这些实践经验和思考对于正在构建 AI Agent 系统的团队会有参考价值。核心的理念是:精心管理上下文,让 AI Agent 在有限的窗口中发挥最大的能力。
正是基于这套系统化的上下文管理策略,搭叩 (Dakou) 才得以自信地处理从官网首页开发到小游戏开发等各类复杂任务。压缩、替换与保留 保证了任务执行的持久性;锚定与合并 确保了目标的一致性;而 共享与动态扩展 则为多 Agent 的高效协作和能力的持续成长奠定了基础。
这些技术细节最终都服务于搭叩的核心目标:通过异步、安全、可复用的方式,将 AI Agent 的能力真正落地到实际的研发场景中。我们期望,搭叩可以让人人都能成为 AI 时代的创造者。
在未来,随着上下文窗口的扩大(如 100 万 token、甚至无限上下文),这些优化的必要性可能会降低,但"高效利用资源"的工程思想永远不会过时。我们期待一起持续探索 AI Agent 的最佳实践,推动这项技术走向成熟和普及。
作者介绍
朱少飞,阿里巴巴开发工程师,在 WebIDE 集群调度、智能代码分析以及代码 AI Coding 等领域具有丰富实践经验。目前主要负责阿里内部 AI Agent 产品的研发。




