
谷歌刚刚发布了 Magika 1.0 版本,这是其开源文件类型检测系统的一次重大重写。新版本引入了 AI 技术,以支持更广泛的文件类型,并使用 Rust 实现以获得更高的性能和安全性。
Magika 1.0 支持的文件类型数量已超过 200 种,相比此前基于 Python 的版本(约 100 种)实现了显著提升。
谷歌指出,新增的许多文件类型都是此前难以识别的、较为专业的文本类格式,包括 Dockerfile、TOML、HCL、Bazel 文件等。Magika 1.0 还能够区分使用 Swift、Kotlin、TypeScript、Dart、WebAssembly 以及 Zig 编写的源代码文件。此外,它也支持数据科学领域常见的文件类型,例如 Jupyter Notebook、NumPy 数组、PyTorch 模型、ONNX 文件等。
除了覆盖更广的文件类型范围外,Magika 1.0 还提供了细粒度更高的识别能力,能够区分过去常被归为一类的相似格式,例如 TypeScript 与 JavaScript、C++ 与 C、TSV 与 CSV 等。
为了让工具能够识别如此多样的格式,谷歌的工程师们构建了一个规模庞大的文件格式样本数据集,用于训练专用的 AI 模型,其数据规模本身就构成了一项挑战:
我们的训练数据集在未压缩状态下增长到了 3TB 以上,这对处理流程提出了很高的效率要求。为此,我们使用了近期发布的 SedPack 数据集库。该工具允许在训练过程中将大规模数据集直接流式传输并解压到内存中,从而绕过潜在的 I/O 瓶颈,使整个过程成为可能。
与此同时,一些较新的、遗留的或高度专业化的格式在数据集中明显样本不足。谷歌通过 Gemini 来解决这一问题,利用其“将现有代码和其他结构化文件从一种格式转换为另一种格式”,生成高质量的合成训练数据。
谷歌表示,Magika 在平均精确率和召回率上都达到了约 99%,在文本类内容的识别上的表现明显优于现有方案。
Magika 1.0 的另一项重要优势在于其核心系统被完全重写:采用 Rust 实现,在最大化性能的同时提升了内存安全性。这个基于 Rust 的新引擎是 Magika 命令行工具的核心,使其能够在单个 CPU 上每秒扫描数百个文件:
借助高性能的 ONNX 运行时进行模型推理,以及使用 Tokio 实现异步并行处理,Magika 可以在单核 CPU 上每秒识别数百个文件,并在现代多核处理器上轻松扩展到每秒数千个文件。
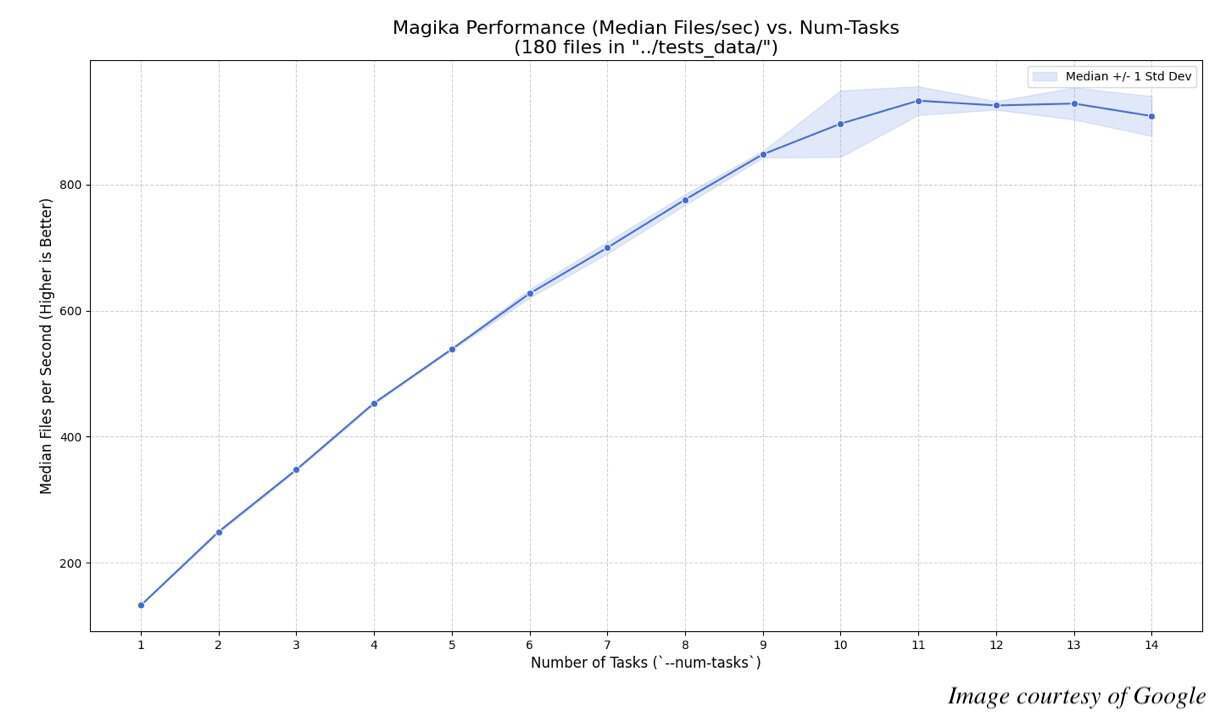
根据谷歌的基准测试结果,这种方案使得在一台 MacBook Pro (M4) 上几乎可以达到每秒处理 1,000 个文件的速度。Reddit 用户 robertknight2 对该工作流的解释是:
在这个流程中,Rust 负责从文件中提取特征向量,只使用内容的一小部分,并通过基于 Tokio 的循环来驱动扫描过程。而基于这些特征预测文件类型的机器学习推理,则是由 ONNX 运行时使用 C++ 实现的(通过 ort crate 调用)。
该工具在首次加载模型时会产生一次性的性能开销,但之后每个文件的处理时间约为 5 毫秒,而且推理时间几乎不随文件大小变化。
尽管有人对 Rust 的采用持保留态度,但 X 用户 Caleb Maclennan 指出,“在需要通过启发式方式猜测如何处理输入的场景下,其安全的影响使得 Rust 成为一个很好的选择”。另一位用户 Mazzarito 补充道:
当文件扩展名缺失,或者在文件上传等场景下扩展名不可信时,这类程序其实非常有价值。文件类型本质上只是约定俗成的规则——而除了尝试用相应的解码器去读取文件之外,并不存在一种标准的方法可以确定文件的真实类型。
你可以通过执行以下命令来安装 Magika 的命令行工具:
curl -LsSf https://securityresearch.google/magika/install.sh | sh
或者通过安装包含 CLI 工具的 Python 包来使用:
pipx install magika
原文链接:
https://www.infoq.com/news/2025/12/magika-rust-file-type-detector/




