
今日,DeepSeek-V4-Pro 1.6T 旗舰模型(1.86 万亿参数)及 DeepSeek-V4-Flash 284B 高效模型(2840 亿)正式发布。由智源研究院牵头研发的众智 FlagOS 第一时间对两个“巨无霸”模型进行全量适配,已经完成 DeepSeek-V4-Flash 在 8 款以上 AI 芯片上的全量适配与推理部署,包括海光、沐曦、华为昇腾、摩尔线程(FP8)、昆仑芯、平头哥真武、天数、英伟达(FP8)等芯片。FlagOS 同时正在推进 DeepSeek-V4-Pro 模型在多个芯片的迁移适配,后续即将开源。
首先完成在八款芯片适配的 DeepSeek-V4-Flash 采用混合专家(MoE)架构,总参数量 284B,激活参数仅 13B,支持 100 万 token 上下文长度。该模型在架构上引入了混合注意力机制(结合压缩稀疏注意力 CSA 与高度压缩注意力 HCA,大幅提升长上下文效率)、流形约束超连接(mHC,增强跨层 信号传播稳定性)以及 Muon 优化器(加速收敛、提升训练稳定性)。预训练数据超过 32Ttoken,后训练采用两阶段范式——先通过 SFT 和 GRPO 强化学习独立培养领域专家,再通过在线策略蒸馏将多领域能力统一整合到单一模型中。在最大推理力度模式(Flash-Max)下,给予更大思考预算使其推理能力可接近 Pro 版本水平;受限于参数规模,在纯知识类任务和最复杂的 Agent 工作流上略逊于 Pro。
围绕 DeepSeek-V4-Flash 多芯适配,此次 FlagOS 系统软件技术栈突破了三大关键技术:FlagGems 全算子替代(实现多芯片统一适配)、为 o-group 采用独立张量并行策略解锁更多低显存场景、以及“FP4+FP8 混合精度”的原生权重到 FP8/BF16 的精度路径转换。当下国内出货的 AI 芯片,都没有 FP4 的支持。英伟达也只有在 Blackwell 及之后的高端芯片才支持 FP4。这三项关键技术,使得 DeepSeekV4 能够在当前各种厂商的主流 AI 芯片上稳定运行,而非仅限于支持 FP4 和大显存的少数高端 AI 加速卡。
三大技术突破:为什么对支持多种 AI 芯片十分重要
突破一:FlagGems 提供支持 8 种以上芯片的全算子替代——真正意义上的跨芯方案
本次 DeepSeek-V4-Flash 的适配,FlagGems 实现了模型推理链路中全部算子的替代。这意味着:
彻底脱离 CUDA 算子依赖:DeepSeek-V4-Flash 的 MoE 专家调度、Attention 计算、RMSNorm、TopK 路由等全部核心计算模块,均由 FlagGems 基于 Triton/Triton-TLE 语言重新实现,不调用任何 cuDNN/cuBLAS 等 NVIDIA 私有库。
无需芯片厂商逐一适配:传统模式下,每款新模型上线,芯片厂商需要投入工程团队做算子适配。现在通过 FlagGems+FlagTree 编译器的组合,新模型的算子可以直接编译到多款芯片后端,芯片厂商不需要做任何额外工作。
新算子即时可用:DeepSeek-V4-Flash 引入的新计算模式(如 o-group 相关的分组路由机制),FlagGems 已经实现了对应的新算子,并通过 FlagTree 编译器统一编译到所有支持的芯片后端。
FlagGems 作为全球最大的 Triton 单一算子库,已拥有超过 400 个大模型常用算子,并已正式进入 PyTorch 基金会生态合作项目。在 40 个主流模型上,推理任务算子覆盖度达到 90%~100%,完整支持 DeepSeek-V4-Flash 的全部计算需求。
突破二:为 o-group 采用独立并行策略——解除张量并行最多单机 8 卡限制
DeepSeek-V4-Flash 为了进一步降低计算开销采用了分组输出投影技术(Grouped Output Projection),配置为 o-group=8,这导致在传统的张量并行时候,最多切 8 份。而当前一些主流国产芯片的单卡显存为 32GB 或 64GB,尤其在 BF16 格式情况下,需要张量并行大于 8 份才能放的下。
为了解除这个限制,FlagOS 专门针对 o-groups 进行了单独张量并行策略设计和实现,确保 o-groups 切分不超过 8 份的前提下,能够让模型其他部分还采用经典的张量并行策略,并且实现超过 8 份的切分。通过不同的张量并行策略组合,能够实现多于 8 台设备的张量并行运行。
FlagOS 团队对 o-group 张量并行改动包括:
独立的并行策略:独立于已有的张量并行通信组之外,为 o-group 单独构建所需要的张量并行通信组,确保其他模型结构张量并行切分超过 8 的情况下,o-group 的张量并行在 8 以内。
参数转换调整:对 o-group 相关的参数,也进行了对应单独的张量并行切分处理,以确保在新的独立张量并行策略下,也能够被正确加载。
覆盖面扩展:这一优化能够将 DeepSeek-V4-Flash 在单独采用张量并行策略下,将可运行芯片范围从"仅限单机 80GB 以上显存的个别高端卡"扩展到"多机 64GB/32GB 的更多主流国产芯片",包括海光、沐曦、天数智芯等厂商的主力产品线。
突破三:从“FP4+FP8 混合精度” 到 BF16 的精度转换——打通主流芯片的计算路径
DeepSeek-V4-Flash 模型发布时首次采用 FP4+FP8 混合精度,该精度只有在 Blackwell 及之后的英伟达最新硬件上才有支持,但当前所有国内非英伟达 AI 芯片都未能支持,只有摩尔线程原生支持了 FP8,其余依然以 BF16 为主。
FlagOS 完成了从 FP4 到 BF16 的完整精度转换:
权重反量化:将 FP4 量化权重转换为 BF16 格式。这不是简单的类型转换,而是需要根据 DeepSeek 的量化方案进行逆量化计算,确保数值精度。
计算路径重建:FP4 和 BF16 在底层计算上有本质差异——FP4 的动态范围更窄,累加精度、溢出处理策略均不同。FlagOS 对推理链路中的 GEMM、Attention、MoE 路由等关键计算节点逐一适配了 BF16 路径。
精度对齐验证:经过标准评测集验证,BF16 版本与 FP4 原生版本在核心能力指标上保持对齐,确保精度转换不引入业务层面的效果损失。
本次,FlagOS 推出了 FP8 和 BF16 两种适配版本,让 DeepSeek-V4-Flash 不再是“只有最新 NVIDIA 卡才能跑”的模型,而是真正可以部署在 FP8 及 BF16 生态的主流国产芯片上。
FlagGems 开源高性能新算子全面支持 DeepSeek-V4-Flash
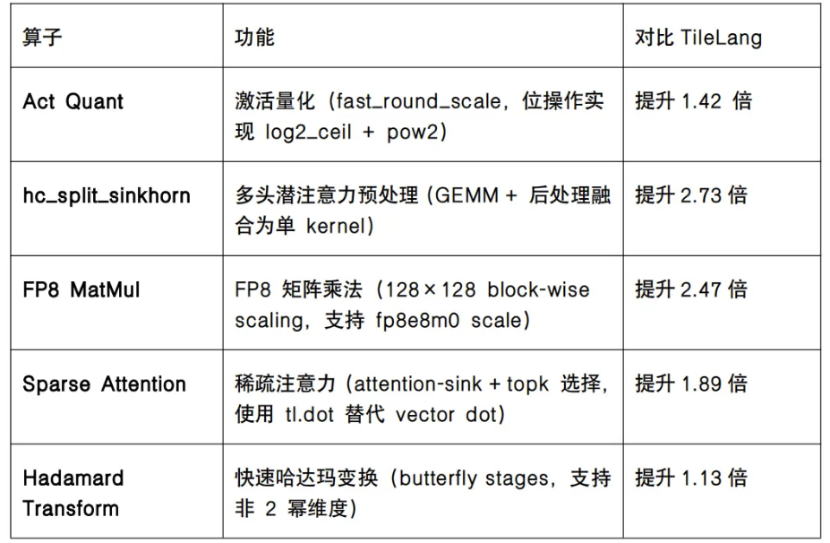
本次新发布的 DeepSeek-V4-Flash 共有大约 67 个算子,FlagGems 已全量支持。新支持了 Act Quant、hc_split_sinkhorn、FP8 MatMul、Sparse Attention、Hadamard Transform 等 5 个新算子,实现了对 DeepSeek-V4-Flash 的全面支持,也为跨芯适配打下重要基础。
FlagGems 支持 DeepSeek-V4-Flash 新算子的性能对比
为了支持更多 AI 芯片的使用,FlagOS 对 DeepSeek-V4-Flash 中使用的新算子使用 Triton 语言进行重新实现,基于 FlagTree 统一编译器,性能全部超过原生性能。
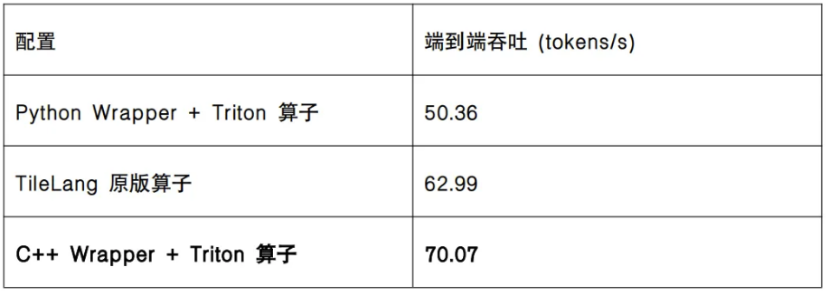
C++ Wrapper 技术是 FlagOS 技术社区专门为提升基于 Triton 语言的算子内核调用效率而打造的技术。目前已经支持了该技术的芯片包括华为昇腾、寒武纪、摩尔线程、平头哥真武、及英伟达等。使用了 C++ Wrapper 技术,在普通的 Transformers 框架下,可以显著提升使用了 Triton 算子的模型的端到端效率,实现跨芯普适、和高效推理的双重目标。通过端到端效果评测(NV H20,DeepSeek-V4-Flash FP8),C++ Wrapper + Triton 比 TileLang 快 11%,比 Python Wrapper 版快 39%。
开发者体验优化:“发布即多芯” + “极简部署”
1. 核心能力与原生版本对齐
经 GPQA_Diamond、AIME 等权威评测集验证,FlagOS 适配后的 DeepSeek-V4-Flash,在语言理解、复杂推理、代码生成、数学计算等核心能力上,与 CUDA 原生版本对齐,可放心应用于金融、教育、政企服务、代码开发等场景,无需担心适配导致业务效果折损。
评测数据:
注:本测试结果仅用于对迁移前(Nvidia-Origin)和迁移后(-FlagOS)版本的互相对齐验证,并不代表 DeepSeek 模型的官方性能,DeepSeek 模型的官方性能以 DeepSeek 官方公布数据为准。
2. 极简部署:开箱即用,底层优化无感知
FlagOS 将核心算子库、编译器等技术组件前置内置到 DeepSeek-V4-Flash 代码框架中,开发者加载模型时,底层优化代码自动生效,无需手动添加任何 FlagOS 初始化代码。同时,基于 FlagRelease 直接提供了多芯片版本的 DeepSeek-V4-Flash-FlagOS 模型版本,标准化 Docker 镜像 + 一键加速命令,解决了开发者最头疼的环境配置、效果对齐、性能优化等问题。




