
刚刚,在拉斯维加斯 CES 2026 现场的聚光灯下,英伟达 CEO 黄仁勋在主题演讲中没有展示芯片,而是宣告了 AI 从理解语言走向改造物理世界的历史性转折。
英伟达系统性披露了其面向“物理 AI(Physical AI)”的最新技术路线图。从自动驾驶到通用机器人,从云端训练、仿真验证到现实世界部署,英伟达正试图以一套完整的全栈式计算与软件体系,推动 AI 从“看懂世界”走向“理解、推理并行动”。
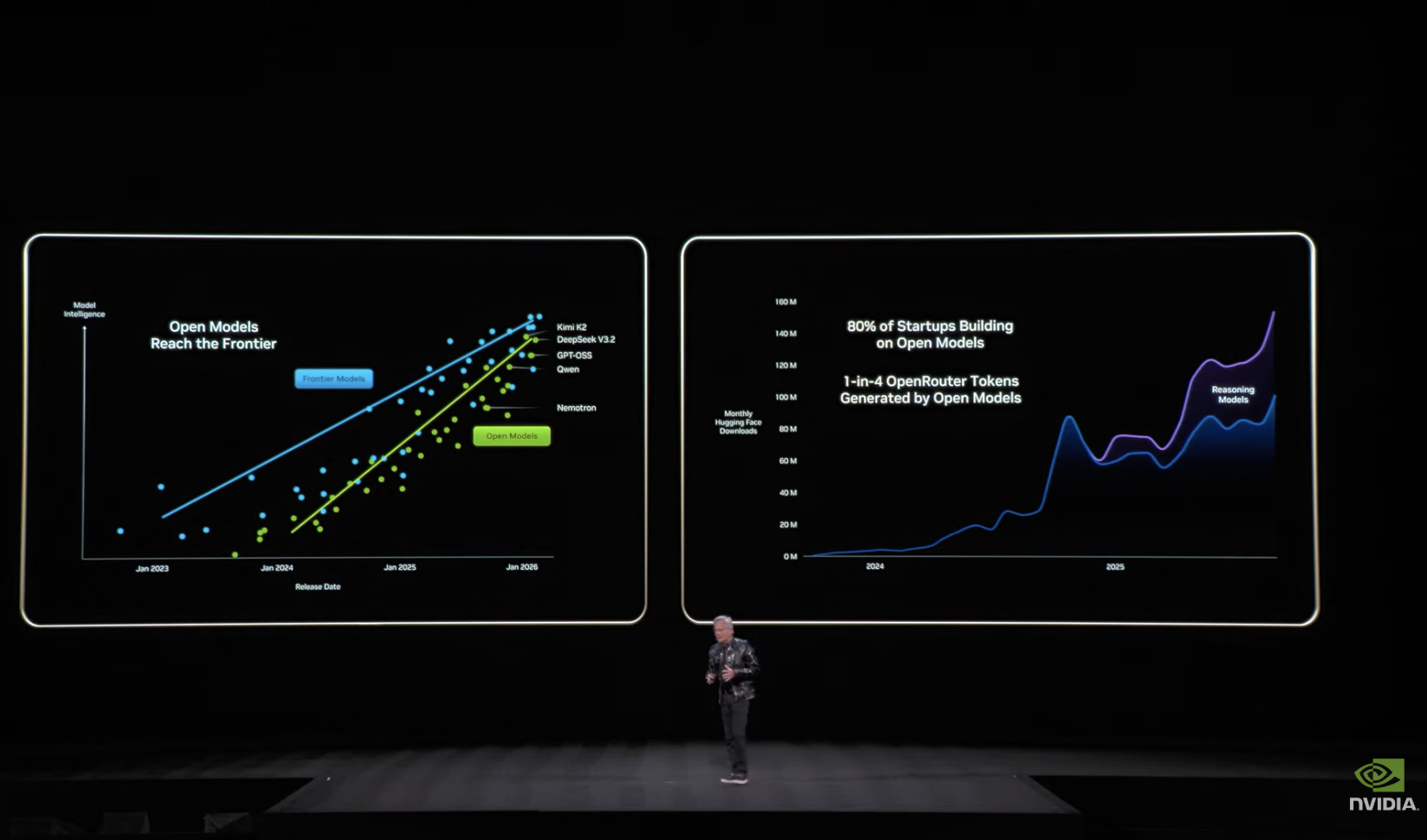
2025 年开源模型取得突破,但仍落后于先进模型约 6 个月
一开场,黄仁勋开宗明义地指出,当下的革命性转折在于“双重平台迁移”。一方面,计算的核心从传统 CPU 转向以 GPU 为核心的加速计算;另一方面,应用开发的基础正从预定规则代码转向以人工智能为基座。“你不再仅仅是编写软件,而是在训练它;应用程序也不再是预先编译好的静态代码,而是能理解语境、每一次都从头动态生成内容的全新实体。”他解释道。这两种根本性转变同时发生、相互交织,彻底重塑了计算的本质。
此次演讲正值新年之际,黄仁勋特别强调了 2025 年开源模型取得的关键突破。他表示,去年是不可思议的一年。感觉所有事情都在同时发生,首先要谈的是 Scaling Law 的进程。
2015 年,语言模型 BERT 为整个行业带来了巨变。2017 年 Transformer 架构诞生,但直到五年后才迎来 ChatGPT 的爆发时刻,它唤醒了世界对人工智能潜力的认知。而随后一年发生了更关键的事:首个具备推理能力的模型出现,它创造了“Test Time Scaling”这个革命性概念——这本质上是实时思考的能力。人工智能每个阶段都需要巨大算力支持,计算定律持续扩展,大语言模型不断进化。
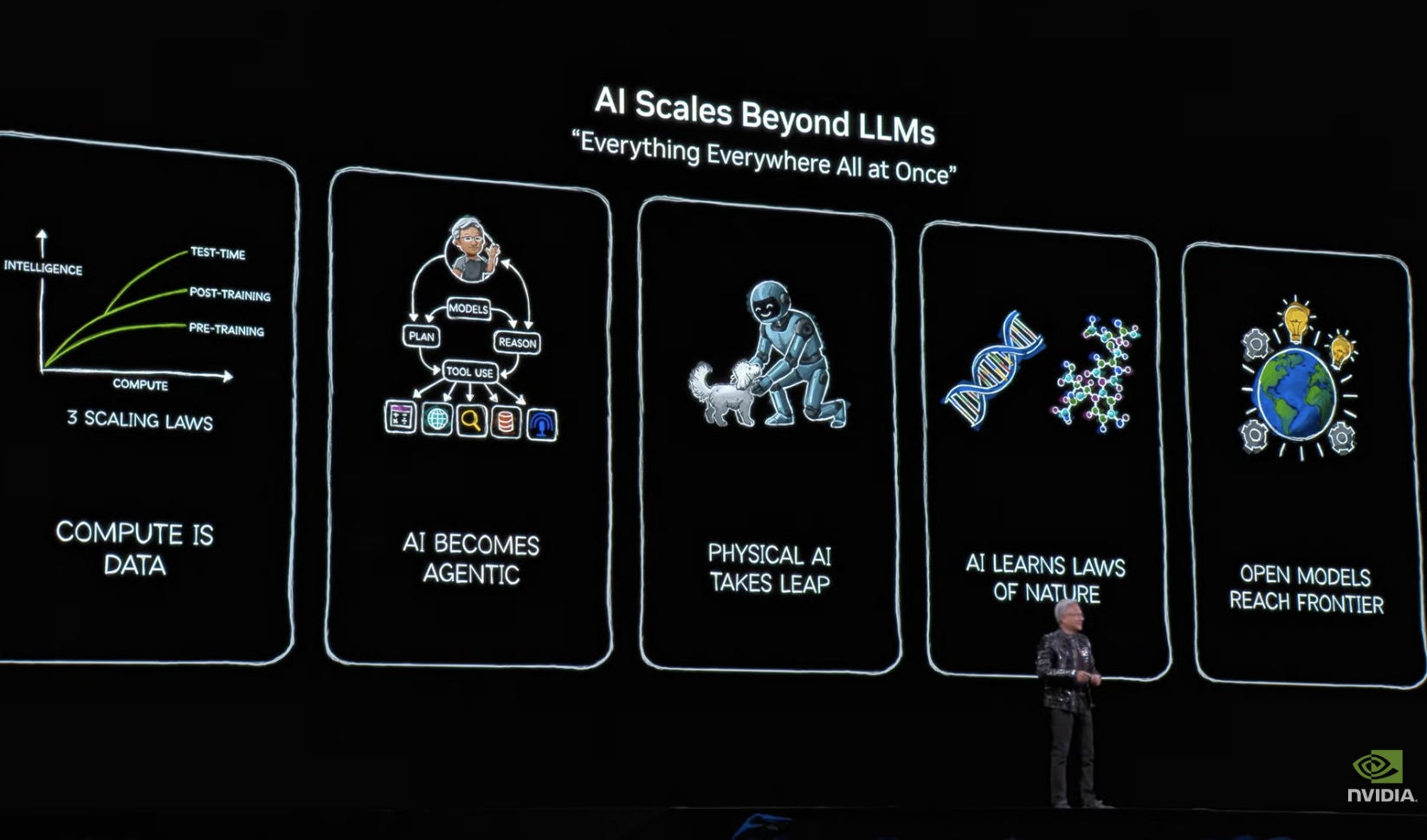
与此同时,2024 年另一个突破诞生:能自主思考的 Agent 系统开始出现,2025 年已渗透到各个角落。这些能推理、检索信息、做研究、使用工具、规划未来、模拟结果的智能体模型,突然开始解决极其重要的问题。黄仁勋还强调,自己尤其欣赏 Cursor 模型,它彻底改变了英伟达的软件开发方式。智能体系统即将从这里真正起飞。
当然还有其他类型的人工智能。我们知道大语言模型不是唯一的信息处理方式——宇宙中任何存在信息与结构之处,我们都能训练某种语言模型去理解信息及其表征,并将其转化为 AI。其中最重要的一类是物理 AI:既包括与物理世界交互的 AI,也包含理解物理定律的 AI 物理模型。
去年最关键的发展还包括开源模型的突破。当开源创新让全球每个企业、每个行业同时被激活时,人工智能才能真正无处不在。首个开源推理系统模型的出现震惊世界,彻底点燃了这场运动。黄仁勋强调:“如今各类开源模型系统遍布全球,且已触及技术前沿——虽仍落后尖端模型约六个月(原话是这样的:We now know that open models have also reached the frontier. Still solidly is six months behind the frontier models),但每半年就有更聪明的新模型涌现。正因如此,模型下载量呈现爆炸式增长,因为初创企业、大公司、研究者、学生乃至每个国家都希望参与这场 AI 革命。数字智能怎会让任何人掉队?开源模型正在重塑整个行业。”
英伟达数年前就预见到这种趋势,因此早前就开始建设自主运营的 AI 超级计算机 DGX Cloud。
但老黄这一行为让外界质疑其是否要进军云业务?他给出的答案是否定的,他补充道:
我们建造这些超级计算机本是为自用,如今已有价值数十亿美元的超级计算机在运行,以开发我们的开源模型。我对当前工作深感自豪——我们在蛋白质数字生物学领域的工作能让模型合成生成蛋白质;OpenFold3 能解析蛋白质结构;Evolve2 能理解生成多蛋白质体系;Earth2 是理解物理定律的 AI;ForecastNet 与 CORDiff 彻底改变了天气预报方式;NemoTriumph 作为首个混合 Transformer SSM 模型,能以极快速度进行长时间思考并给出智能回答;Cosmos 是理解世界运行机制的前沿开放世界基础模型;GROOT 是开放给世界的人形机器人系统模型。

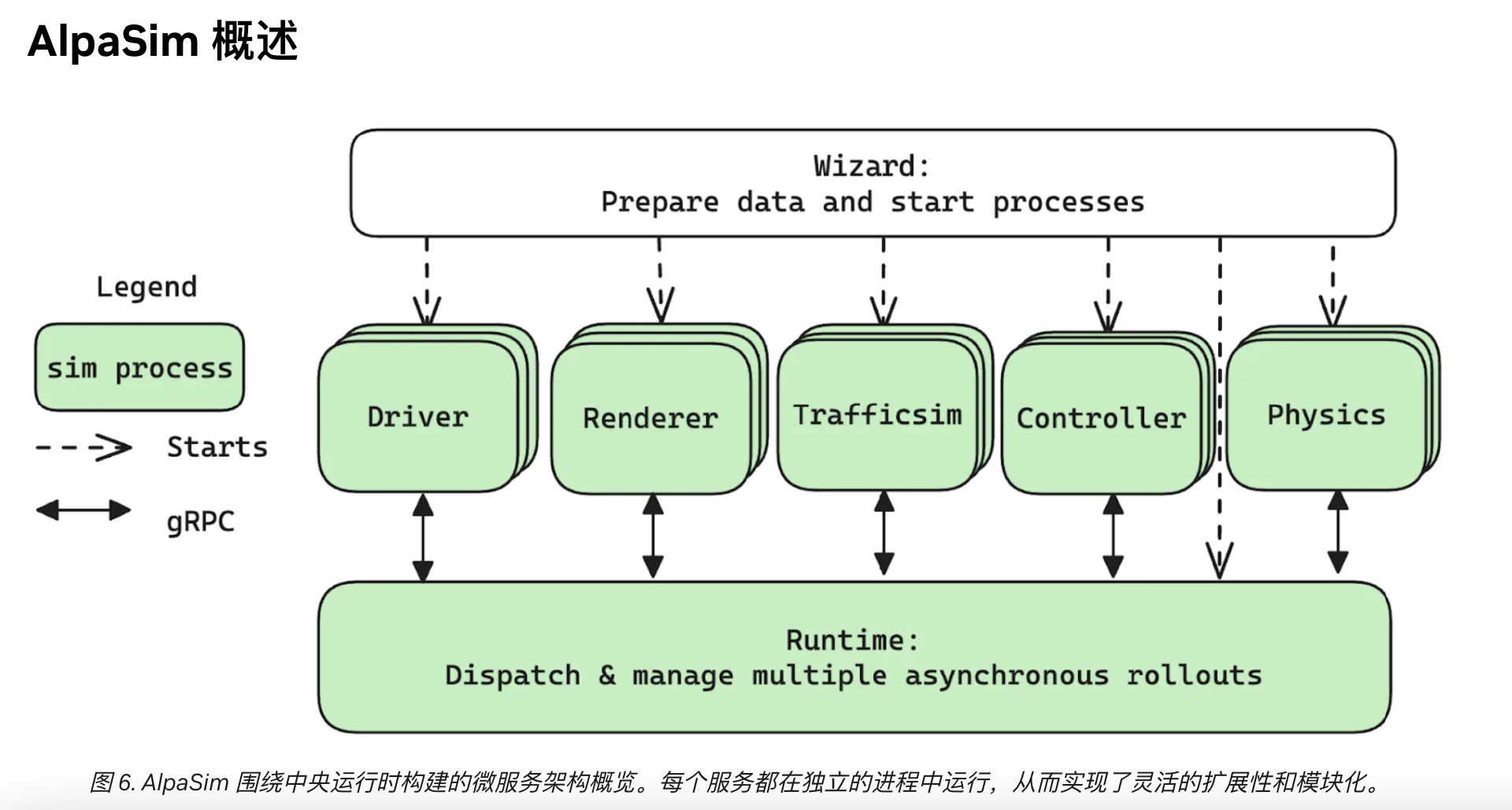
发布完全开源的 Alpusin 仿真框架
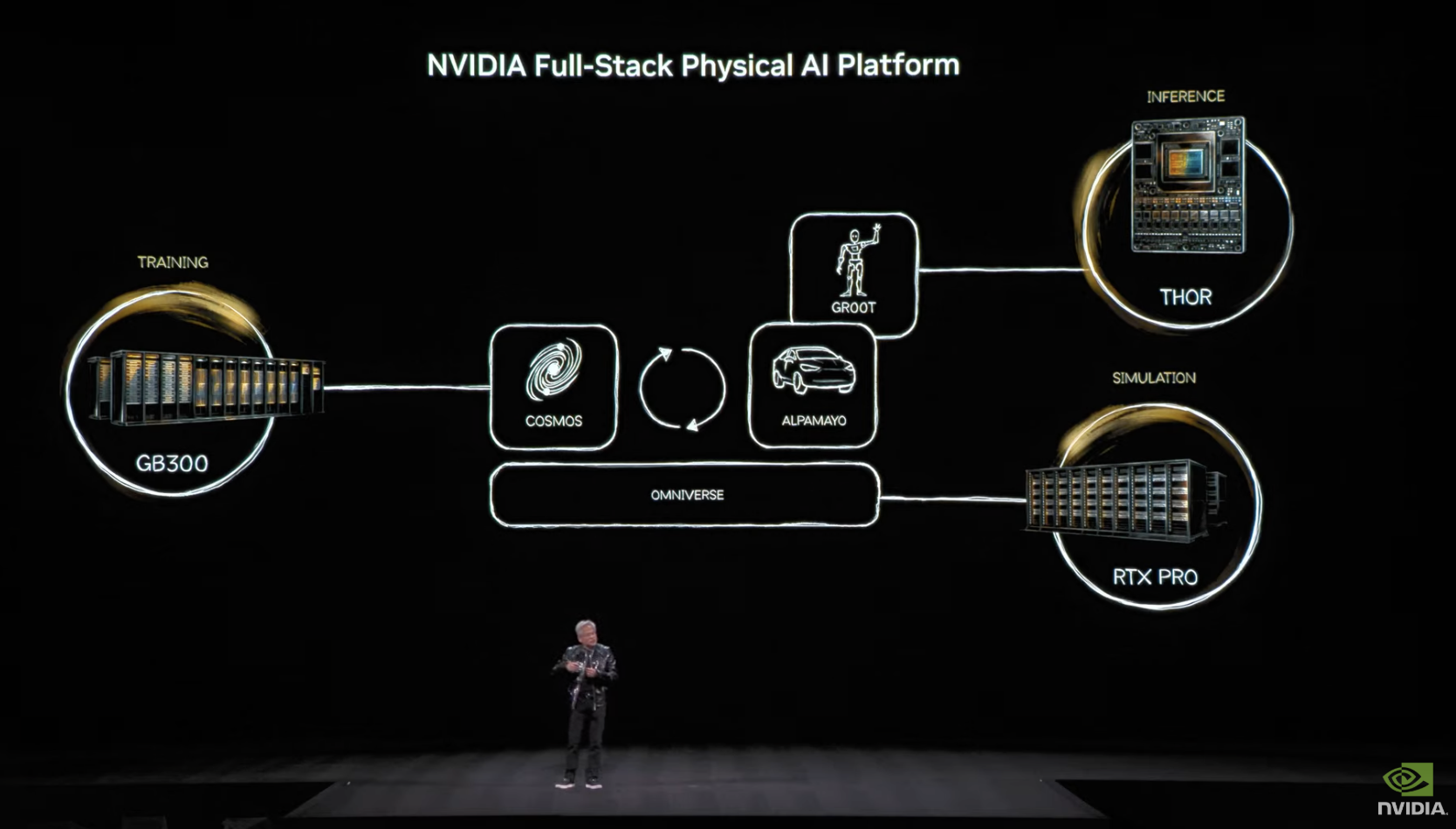
在此次发演讲之前,英伟达 Omniverse 与仿真技术副总裁 Rev Lebaredian 曾向媒体表示:构建物理 AI 需要三台计算机。英伟达将其定义为从边缘到云的全栈式专用加速系统,包括操作系统、库和应用。英伟达的独特之处在于同时构建了这三者:用 DGX 训练 AI 模型,通过 Omniverse 和 RTX 上的 Cosmos 来仿真、测试与验证模型,最后通过 AGX 将模型部署到现实世界。物理 AI 浪潮才刚刚开始,仅这两类计算机就为英伟达物理 AI 部门带来近万亿美元的机遇。
在黄仁勋的主题演讲中再次强调了 Rev Lebaredian 的观点。英伟达将物理 AI 模型分为三大系列:用于世界生成与理解的 Cosmos World 基础模型、通用机器人模型 GROOT,以及本次 CES 发布的全新系列——具备思考能力的自动驾驶模型 AlpaMayo。英伟达同时开源了模型、数据库、训练脚本及设计蓝图,助力生态系统开发者使用。
Cosmos 在对物理世界的理解上已与 GPT-40、Gemini 等顶级模型并驾齐驱,在物理推理和物理 AI 基准测试等关键评估中取得更高分数。这些模型下载量已突破 400 万次,正驱动着从制造、物流到医疗健康与出行等各行业的实际应用:日立集团正通过 Cosmos Reason 驱动的视觉 AI 智能体优化实时基础设施检测;Lem Surgical 利用 Cosmos Transfer 训练其机器人辅助复杂外科手术;Salesforce 运用 Cosmos Reason 分析机器人采集的视频数据以提升工作场所安全性;Telet 视觉智能平台借助 Cosmos Reason 加速工业自动化;Uber 则通过 Cosmos Reason 分析自动驾驶车辆在高速公路行人横穿等场景下的行为模式。

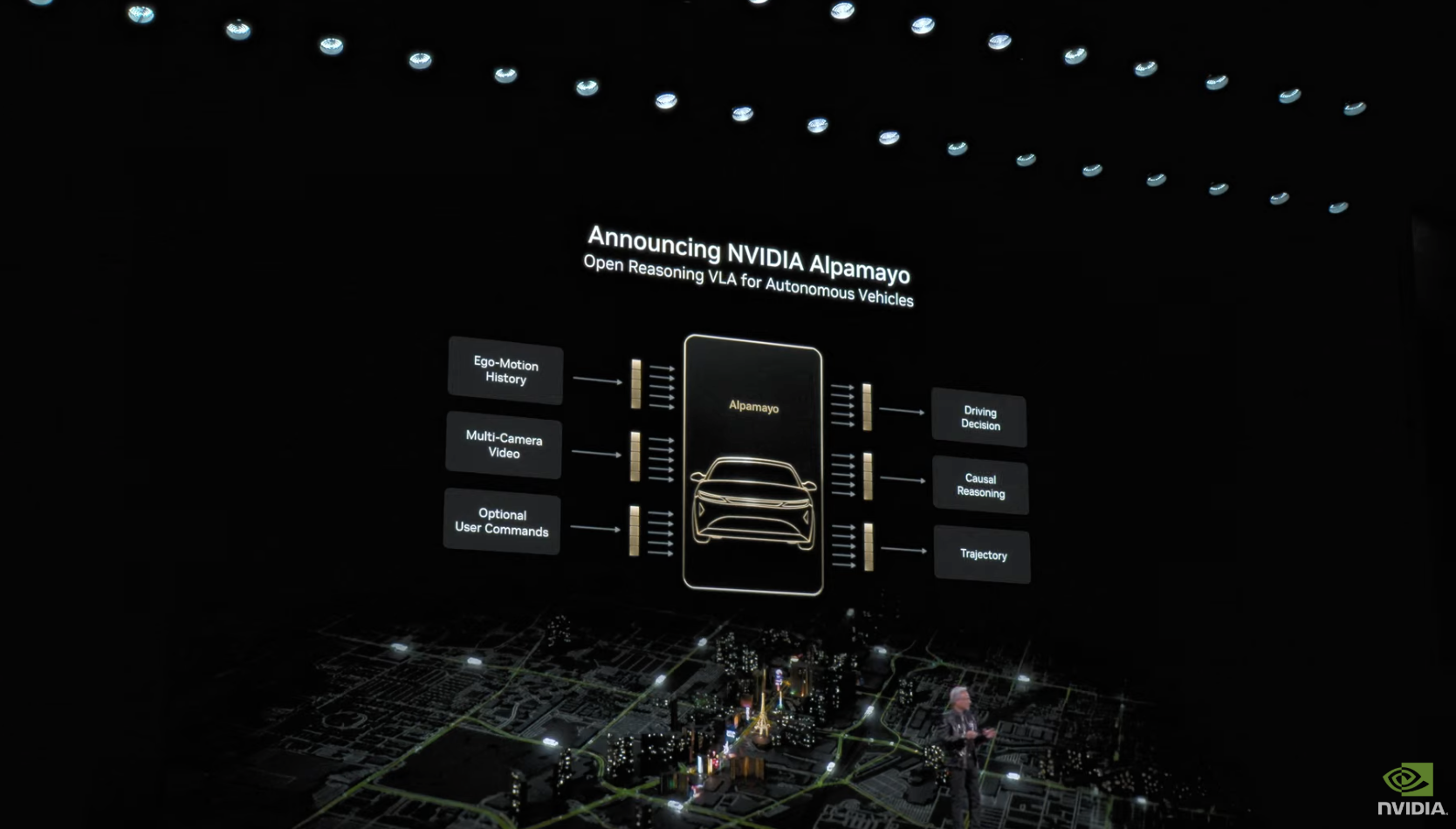
英伟达还宣布推出 AlpaMayo。这是一个全新的开源人工智能模型、仿真工具和数据集系列,用于训练物理机器人和车辆,旨在帮助自动驾驶车辆应对复杂的驾驶情况。这是史上首个让自动驾驶车辆具备思考能力的模型,可以让自动驾驶汽车“像人类一样思考”。这种推理-视觉-行动模型使自动驾驶系统能解决复杂边缘场景,例如首次遇到繁忙十字路口的故障交通灯。其方法是分解问题步骤,推理各种可能性,然后选择最安全路径。
AlpaMayo 开源地址:https://github.com/NVlabs/alpamayo
AlpaMayo 拥有 100 亿参数,既足以处理自动驾驶任务,又轻量化到可在工作站运行。它专为自动驾驶研究者设计,接收文本、环视摄像头、车辆历史数据及导航输入,最终输出轨迹与推理路径,让我们能理解车辆的决策逻辑。
除 AlpaMayo 外,英伟达还开源了部分训练数据,包含 17 小时驾驶记录,成为业内最大最多元的公开自动驾驶数据集。此外,黄仁勋同时发布完全开源的 AlpaSim 仿真框架,用于评估 AlpaMayo 等推理模型。
开发者可利用自有数据微调 AlpaMayo,也可通过 Cosmos 生成合成数据,结合真实与合成数据集训练测试自动驾驶应用。这些模型与工具将激活自动驾驶生态,构建完整的自动驾驶开发闭环。
AlpaSim 地址:https://github.com/NVlabs/alpasim
发布最新机器人开源模型 GROOT 1.6
正如 AI 已从基础识别迈向深度思考,机器人智能也在经历变革。
黄仁勋表示,当前大多数机器人属于“专才”——精于单一任务却缺乏适应能力。如今我们正见证“通才型机器人”的出现,它们如同拥有学士学位的毕业生,能应对多样情境但仍欠缺复杂任务所需的专家技能。未来将属于“通专融合型机器人”,它们如同机器人领域的“博士”,兼具广博知识与精深专长,实现多功能与高可靠性的统一。构建这类先进机器人需要一个开放的开发平台。

英伟达 Isaac 机器人平台提供了构建这类“通专融合型机器人”所需的开放框架、模型与工具库。这类机器人需要强大的“大脑”执行复杂任务,但从零训练机器人模型需耗费巨大时间与资金。英伟达则通过预训练模型并向所有人开放来降低这一门槛。
随后,老黄宣布正式对外发布 GROOT 1.6——专为人形机器人打造的最新开源推理模型。该版本包含两大升级:首先,它采用 Cosmos Reason 作为长效思考中枢,显著提升推理能力与情境理解水平;其次,它解锁了人形机器人全身协调控制能力,使其能同时执行移动与物体操控任务。GROOT 1.6 已成为社区热门选择,位列 Hugging Face 平台下载量最高的机器人基础模型之一。
GROOT 开源地址:https://github.com/NVIDIA/Isaac-GR00T
发布全球首个仿真环境机器人安全技能检测框架
机器人开发本身已具挑战,而当工作分散在笔记本电脑、实验室设备与云端时,协同调度更为困难。为此,英伟达开发了开源控制中心 NVIDIA OSMO,它如同粘合剂般无缝整合从数据生成到训练的完整流程,简化跨桌面与云端的开发工作。最后,现实世界中的机器人技能测试极为困难。为降低门槛,英伟达发布 Isaac Lab Arena——全球首个用于在仿真环境中安全测试机器人技能的开源框架。
接下来老黄深入介绍了前文提及的新开放框架之一:Isaac Lab Arena。开发者正教机器人掌握从精细物体抓取、线缆安装到动态环境导航等日益复杂的技能,但在现实世界中验证这些技能却存在过程缓慢、成本高昂、风险巨大等问题。当前行业缺乏严谨验证机器人技能的基础工具与技术——例如许多 AI 模型仍以语言能力为测试重点,而非机器人实际所需的精确物理动作;缺乏统一标准导致技能验证困难,基准测试体系碎片化。Isaac Lab Arena 作为全球首个大规模机器人策略评估与基准测试协作系统,正为填补这一关键空白而生。它整合了资产库、任务集、训练脚本及 Libero、RoboCasa、RobotIn 等重要机器人社区基准测试标准,成为社区的权威参照体系,为技能在现实部署前提供必要的基准测试框架。

一些先进的机器人公司已在 Isaac 与 GROOT 基础上构建其新一代物理 AI 系统,涵盖从人形机器人到外科手术系统等多元领域:波士顿动力推出基于 Jetson 与 Thor 平台并在 Isaac Lab 中训练的新款 Atlas 人形机器人;Franco Robotics 采用 GROOT 模型驱动其双臂操控机器人;Lem Surgical 运用 Isaac 与 Cosmos Transfer 训练外科手术机器人;LG 电子发布能处理多种家务的新型机器人;Noira 推出基于 GROOT 开发并借助 Isaac Lab 设计的门廊服务人形机器人;FSR Labs 则通过 Thor 与 Isaac 为外科医生提供实时 AI 导航。
开源生态正推动机器人世界飞速发展。为支持这一趋势,英伟达与 Hugging Face 强强联手,将 200 万英伟达机器人专家与 1300 万 Hugging Face AI 开发者社区连接起来。通过将英伟达顶尖工具集成至开发者现有工作环境来简化开发流程:Isaac 与 GROOT 技术现已内置入 Hugging Face 的 Lair 机器人库,使开发者能即时调用 GROOT 等模型及 Isaac Lab Arena 等仿真框架来评估机器人技能。硬件层面同样实现无缝对接——开源 Regi 2 人形机器人将在英伟达 Jetson 与 Thor 平台上流畅运行,让开发者能将先进 AI 模型直接部署于机器人本体;对于桌面级项目,开发者可完美结合 Reach Mini 与 DGX Spark 在本地运行定制化的 AI、语音及视觉模型。
最后是第三类计算机——机器人内置的、需要极致能效优化的计算单元。黄仁勋宣布,英伟达正式推出 Thor 家族新成员 Jetson T4000,它基于 Blackwell 架构,为现有 Orin 客户提供高性价比升级方案:在 40-70 瓦功耗下提供 1,200TOPS 的 AI 算力与 64GB 内存,其 AI 性能与能效较 AGX Orin 提升 4 倍,且与 T5000 接口完全兼容,可轻松进行量产替换。预计该模块将赋能从机械臂、自主移动机器人到人形机器人的广泛机器人类型。
发布 AI 超算 Vera Rubin,并宣布已全面投产
本场演讲的重中之重,当然还是要回到芯片上。
黄仁勋发布了其面向人工智能数据中心的新计算平台 Vera Rubin。英伟达此前已公布了 Vera Rubin 的部分细节,但直到刚刚的主题演讲中,老黄才详细阐述了该系统的工作原理并公布了其发布时间。他表示,Vera Rubin 目前正在生产中,首批搭载该系统的产品将于 2026 年下半年上市。
他在演讲中花了近 10 分钟来介绍这款芯片的设计初衷、架构、技术细节等信息。
据黄仁勋介绍,Vera Rubin 超算正是为了应对目前行业面临的根本性挑战而设计:AI 所需的计算量正在飙升,对英伟达 GPU 的需求也急剧增长。这是因为 AI 模型的规模每年都在以 10 倍的速度增长,更不用说之前提到的 O1 模型发布已成为 AI 发展的拐点——推理不再是一次性生成答案,而变成了一个思考过程。为了教会 AI 如何思考,英伟达在训练后阶段引入了强化学习和巨大的计算量。这不再是单纯的监督微调或模仿学习,而是让计算机通过不断尝试不同迭代来自主学习如何执行任务。因此,预训练、后训练及测试时扩展所需的计算量都呈现爆炸式增长。如今,每次推理不再是一次性完成,大家可以看到 AI 在“思考”,而思考时间越长,答案往往越好。这导致每年生成的文本量以 5 倍的速度增长。
与此同时,AI 竞赛正在白热化:每个人都在努力突破下一个边界,而每次达到新边界,上一代 AI 生成文本的成本就会下降约 10 倍。这种每年 10 倍的成本下降实际上揭示了竞争的激烈程度——总有人在不断突破前沿。
因此,这一切本质上都是计算问题:计算速度越快,就能越早抵达下一个前沿。所有这些变化都在同时发生,所以英伟达决定必须每年推进计算技术的尖端水平,绝不落后。
一年半前英伟达开始交付 GB200,现在 GB300 已进入全面量产阶段,Vera Rubin 已经全面投产,并且今年就会发布。
Vera Rubin 细节揭秘:重两吨、100%全液冷
Vera Rubin 的诞生恰逢 AI 下一个前沿时代的到来。其架构是一个由六种芯片组成的系统,通过极致的协同设计使其如一体般运作。它始于 Vera——一款定制设计的 CPU,性能是上一代的两倍,以及 Rubin GPU。

Vera 和 Rubin 从一开始就协同设计,实现高速、低延迟的数据定向一致性传输。随后,1.7 万个组件在 Vera Rubin 计算板上精密集成。高速机器人以微米级精度放置组件,最终完成包含多种 CPU 和两颗 Rubin GPU 的组装。该板卡可提供 100 Petaflops 的 AI 算力,是前代的 5 倍。
AI 需要高速数据吞吐。ConnectX9 为每个 GPU 提供 1.6TB/s 的横向扩展带宽,BlueField4 DPU 则卸载存储与安全任务,确保计算资源全力专注于 AI。Vera Rubin 计算托盘经过彻底重新设计:无电缆、无螺丝、无风扇,集成 1 个 BlueField4 DPU、8 个 ConnectX9 芯片、2 颗 Vera CPU 和 4 颗 Rubin GPU——这就是 Vera Rubin AI 超算的计算构建单元。接下来是第六代 NVLink 交换机,其数据交换量超过全球互联网流量,可连接 18 个计算节点,横向扩展至 72 颗 Rubin GPU 协同工作。
此外,SpectrumX 以太网光子技术——全球首个拥有 512 通道、200G 能力的共封装光学以太网交换机,可将数千个机柜横向扩展为 AI 工厂。
自设计启动以来累计投入 1.5 万工程师·年,首台 Vera Rubin NVL72 机柜现已上线运行:6 款突破性芯片、18 个计算托盘、9 个 NVLink 交换机托盘、220 万亿个晶体管、总重近 2 吨——这是迈向 AI 下一个前沿的巨大飞跃。
随后,为了回应外界关切,黄仁勋还解读了这款芯片的技术细节。
这是一个包含 1152 颗 GPU 的 Rubin 计算集群,由 16 个机柜组成。每个机柜包含 72 颗 Rubin GPU(每颗 Rubin 由两个实际 GPU 芯片连接构成)。他也在现场展示了实物,但有些细节需要保留,不能一次性全部透露。

据介绍,英伟达这次设计了六款不同的芯片。公司内部有个很好的原则:每代新品最多只更换一两款芯片。但问题在于——正如刚才描述的每款芯片的晶体管数量——摩尔定律已大幅放缓。晶体管数量逐年增加的幅度,根本无法跟上模型规模每年 10 倍的增长速度,也无法应对每年 5 倍的文本生成量增长,更无法匹配文本成本每年 10 倍的骤降速度。如果行业要继续前进,英伟达必须实施激进的极致协同设计,在整个系统层面同步创新所有芯片。
这就是为什么这一代产品别无选择,必须重新设计每一款芯片。刚才描述的每一款芯片本身都足以召开一场独立的发布会,在过去可能需要整家公司专注开发。而它们每一款都具有革命性,是同类中的巅峰之作。
黄仁勋称,“Vera CPU 让我深感自豪。在功耗受限的环境中,它的能效比全球最先进的 CPU 高出两倍,数据吞吐能力惊人。它专为超级计算设计,而 Vera GPU 同样卓越——如今 Vera 在单线程性能、内存容量等各方面都实现了飞跃性提升。这是一项巨大的成就。”

这是 Vera CPU(单颗),与之相连的是 Rubin GPU,这确实是颗巨型芯片。它采用了一项先进的发明——NVFP4 TensorCore。英伟达芯片中的 Transformer 引擎不仅仅是简单引入 4 位浮点数处理,而是一个完整的处理器单元,能动态自适应地调整精度和结构,以应对 Transformer 模型的不同层级:在可降低精度的环节实现更高吞吐量,在需要时恢复最高精度。
这种动态调节能力无法通过软件实现(因为速度太快),必须内置于处理器中。这就是 NVFP4 的核心价值。当人们谈论 FP4 或 FP8 时,对英伟达而言这几乎无意义——真正关键的是 TensorCore 结构及其配套算法。关于 NVFP4 英伟达已经发表论文,其在吞吐量与精度保持方面达到的水平令人惊叹。这是开创性的工作,未来这种格式和结构很可能成为行业标准。
正是通过这样的协同设计,英伟达才能在晶体管数量仅增加 1.6 倍的情况下实现性能的巨幅提升。值得一提的是,这款芯片是 100%全液冷。这确实是一个重大突破。
具体而言这款芯片的性能如何?
据老黄介绍,Vera Rubin 有几项惊人特性:首先,虽然功耗翻倍,但冷却液温度仍保持 45°C,整个系统能效提升约两倍——这预计能为全球数据中心节省 6%的电力,意义重大。
其次,全系统实现机密计算安全:所有数据在传输、静态存储及计算过程中均加密,每条总线(包括 PCIe、NVLink、CPU-GPU 及 GPU 间互联)全部加密。这让企业能安心将模型部署于第三方环境而不担心泄露。
第三,针对 AI 工作负载瞬时尖峰特性(如 AllReduce 计算层会导致 25%的瞬时功率骤增),我们实现全系统功率平滑技术,避免 25%的过度资源预留造成的能源浪费,让总功率预算得以充分利用。
最后看性能表现。这些图表是 AI 超算构建者最关注的:第一列是 AI 模型训练速度——训练越快,就能越早将下一代前沿技术推向市场,这关乎产品上市时间、技术领导力和定价权。
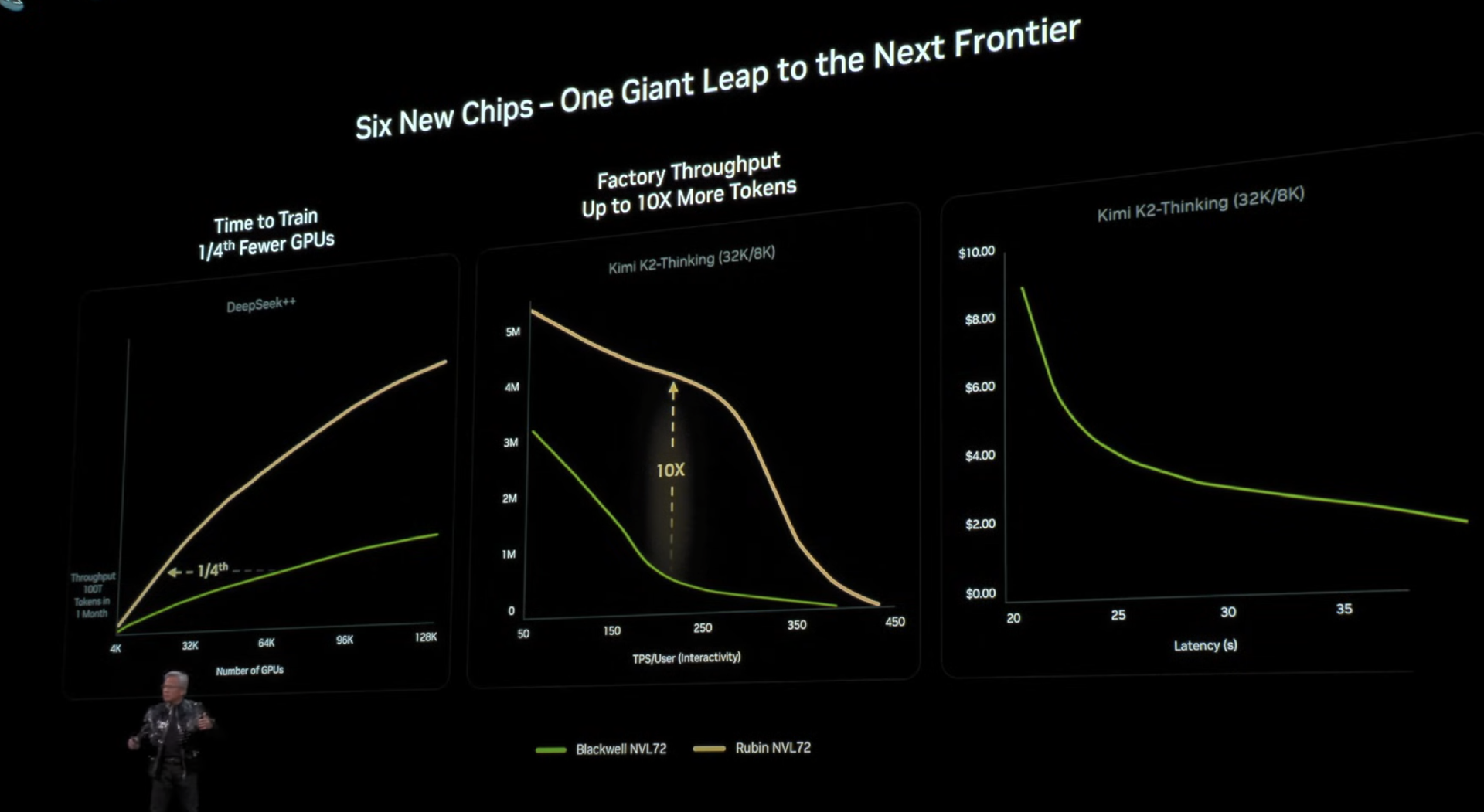
以训练 10 万亿参数模型为例(使用 100 万亿 token 数据),绿色柱表示 Blackwell 性能,而 Rubin 的吞吐量远超前者——仅需 1/4 数量的系统即可在一个月内完成相同训练。时间对所有人公平,但训练速度与模型规模将决定谁先抵达技术前沿。
第二部分是数据中心吞吐量:在吉瓦级数据中心(投资 500 亿美元)中,功耗是硬性约束。因此每瓦性能至关重要——如果你的每瓦吞吐量更高。
英伟达以“全栈 AI 计算架构”为核心理念,从底层芯片、系统平台到上层应用模型,构建了贯穿云端、边缘与终端的完整技术闭环。从 DGX 超级计算到 Omniverse 数字孪生,从 DRIVE 自动驾驶到 Isaac 机器人平台,英伟达正将物理世界的复杂问题转化为可计算、可迭代的 AI 工程系统。这不仅是对算力边界的持续突破,更是对“AI 重塑现实”这一命题的深刻实践——通过软硬件协同进化、开源开放生态与跨领域技术融合,英伟达正在为智能时代的根本性创新铺设道路。





