
摘要:随着黑灰产全面完成“智能化”改造,攻击手段已从机械脚本进化为具备思考与执行能力的 AI Agent。这种“去脚本化”的攻击不仅能批量生产通过图灵测试的高拟真内容,更能利用多模态大模型与 Deepfake 实时突破行为验证与生物核验,致使传统风控防线失效。
面对“硅基黑产”的降维打击,数美科技 CTO 梁堃指出防御必须下沉至物理世界的“第一性原理”。他详解了穿透 AI 伪装的“反欺诈三定律”——利用物理设备的多样性、信息逻辑的一致性以及社群网络的关联性来锁定异常;同时,揭示了通过引入“不确定性标签” 机制解决大模型“幻觉”问题、将准确率提升至工业级水平的技术路径。
黑灰产的“智能体”革命
“今年以来,最直观的感受是黑灰产正在全面利用大模型技术提高获利效率。”在专访间里,梁堃指出黑产技术的升级并非渐进式的改良,而是一次结构性的代际跨越。这种跨越,让数字战争的性质彻底改变。
最先被颠覆的是账号孵化环节。在过去,黑产为了获取用于薅羊毛或营销欺诈的高权重账号,面临着极高的“养号”成本。为了模拟真人,他们需要人工准备大量文案在论坛回帖,一旦文案重复或逻辑不通,极易被风控系统识别。
但现在,大模型成为了黑产最高效的生产力工具。利用 AI,黑产可以针对特定主题,自动生成情感细腻、逻辑严密且千人千面的评论文案。这些 AI 生成的回复极具迷惑性,甚至能通过很多平台的“图灵测试”,将账号养得“非常像真人”。这极大降低了黑产的门槛,使其能够以极低成本批量制造出高权重的“幽灵账号”。
比内容生成更具威胁的,是攻击工具的智能化升级。回顾黑产行为模式的演变史,可以清晰地看到从“脚本”向“智能体”进化的轨迹。早期黑产主要依赖“按键精灵”等自动化脚本,其破绽在于机械化特征,例如非人类的点击速度,或代码中固定的暂停时间。梁堃分析道:“一旦代码里写了固定的暂停时间,就会形成‘等间距特征’,这是非常明显的异常。”为了对抗识别,黑产曾尝试加入随机间隔,但这显著增加了代码编写和维护的成本。
今年,这一博弈局面被彻底打破。黑产全面转向 Agent。Agent 能够理解指令并直接调用 API,其生成的点击、浏览、交互行为序列具备极高的拟人度,且执行成本几乎为零。这种“去脚本化”的攻击,让传统基于点击频率、间隔时间等规则的行为风控防线面临失效风险。
此外,在验证码和身份认证这一核心防线上,多模态技术也展现出了惊人的突破能力。面对“点击图中汽车”或空间推理类的行为验证码,多模态大模型凭借强大的视觉识别和逻辑推理能力,已能轻松完成识别并绕过验证。更为警惕的是人脸识别技术的攻防升级。
据梁堃透露,AI 换脸技术已经从简单的视频替换进化为实时对抗工具。黑产开发了一套连接 PC 和手机的工具,当人脸认证系统要求手机屏幕变色进行“光线活体检测”时,该工具能实时采集人脸,并根据屏幕颜色变化实时调整假脸上的光影,从而成功骗过活体检测系统。此外,针对大模型本身的攻击手段也层出不穷。一种名为“输出劫持”的攻击正在兴起:黑产在网页或简历中利用人眼不可见的白色字体植入攻击指令,诱导 AI 系统执行错误操作。
面对武装到牙齿的“硅基黑产”,靠纯人工或传统规则去对抗已显力不从心,防御体系必须进化为“用 AI 对抗 AI”。
在“完美伪装”中寻找破绽
反欺诈三定律
当 AI 能够以极低的成本生成近乎完美的真人行为序列时,传统的基于“图灵测试”逻辑的风控手段——即试图通过交互来区分人与机器——面临着失效的风险。面对这种不对称的攻防态势,防御的视角必须从“行为表象”下沉到物理世界和群体行为的“第一性原理”。数美科技 CTO 梁堃在专访中将其总结为“反欺诈三定律”,这成为了穿透 AI 伪装的核心逻辑。
这套防御哲学的首要支点,是利用“多样性”来对抗机器的“统一性”。梁堃提出了第一定律:“好人是多种多样的好,坏人是一样的坏”。在真实世界中,正常用户的行为充满了个性化的随机性——手机型号涵盖华为、苹果、小米等各种品牌,系统版本各异,甚至电量也是随机分布的,有的剩 30%,有的剩 70%。这种高度的“分散性”是自然行为的特征。相反,黑产为了追求规模化获利的效率,必须控制成本,往往批量采购相同的设备或使用同一套模拟环境。因此,如果防御系统观测到一批账号的手机型号完全相同,或者电量状态呈现出反常的统一,那么无论它们的操作行为多么像人,这种物理层面的高度一致性都会暴露其机器本质。
防御的第二层逻辑建立在“信息一致性”的校验上。这是第二定律的核心:好人的信息一致性极高,而坏人的信息一致性往往存在裂痕。正常用户不会刻意频繁更改 IP 地址或手机号等基础信息。然而,黑灰产的运作模式决定了其必须在不同环节拼凑资源——这边买 IP,那边买手机号。这种资源的拼接过程往往会导致逻辑冲突,例如,一个社群内的用户虽然使用了五花八门的位置信息,但却被检测到连接了同一个 WiFi MAC 地址,或者注册时间与地理位置存在悖论。这种信息维度的割裂感,是 AI 再强大的生成能力也无法在物理层面弥合的逻辑硬伤。
然而,仅靠单点防御往往独木难支,因此风控的维度必须上升到“社群发现”的上帝视角,这也对应了第三定律:好人的朋友通常是好人,而坏人往往呈现出孤立点或只与坏人关联。通过构建设备与环境的关联网络,防御者不再紧盯着单个账号的行为,而是分析群体特征。即便单个 AI Agent 的行为再完美,一旦将其置于网络结构中,如果发现某个群体内 90%的设备型号相同,或者注册时间呈现出非自然的聚集,这个“社群”的风险属性便会被瞬间锁定。
用“不确定性标签”重构模型决策逻辑
当然,防御者自身也在大量应用大模型技术,但也面临着模型“幻觉”带来的误判挑战。在早期的实践中,技术团队发现一个难以突破的瓶颈:无论是尝试二次预训练还是更换训练方法等多种方案,大模型在风控场景中的准确率始终未能突破 90%,远低于预期的类似人类审核(99.98%)的精度。通过深入分析,团队发现问题的核心在于那些模棱两可的样本——即处于黑白之间的灰色地带,这些样本甚至在人工审核时都可能出现分歧,从而导致模型产生误判。
梁堃将大模型出现幻觉的原因归结为 Loss 函数设计上的问题,并引用了 OpenAI 的研究观点。他指出,现有的训练机制就像“学生考试”,答对题目得分,答错则不扣分。因此,模型在遇到不会做的题时,最佳的策略便是“猜一个”。因为猜错没有惩罚,而猜对了则能获得分数。这种由惩罚机制所驱动的策略,使得模型在面对模糊或无法确定的样本时,倾向于做出一个确定的判断,最终产生了幻觉。
为了解决这一由训练机制本身带来的问题,数美团队引入了一个关键方案:“不确定性标签”。这一机制改变了模型的应试策略:当大模型无法对某个内容做出明确判断时,系统不再强制要求它给出确定的答案,而是允许将该内容标记为“不确定”。梁堃指出,通过引入这一选项,模型给出错误判断的比例大大降低,将幻觉率控制在 1%甚至更低的水平,从而使模型的精度达到了工业级可用状态。
然而,引入“不确定性标签”后,流程并未结束。梁堃强调,这些被标记为“不确定”的样本仍需进行人工干预,进行二次判断。在这一过程中,人工不仅仅是对这些样本进行审核,更重要的是,如果人工基于这些样本能够制定出新的规则或标准,那么这些判断结果将反向教会模型。这种持续的反馈机制使得模型在不断学习和改进中,能够逐步提升对模糊样本的识别能力。
以“大模型审核 Agent ”为核心驱动的 AI 风控新范式
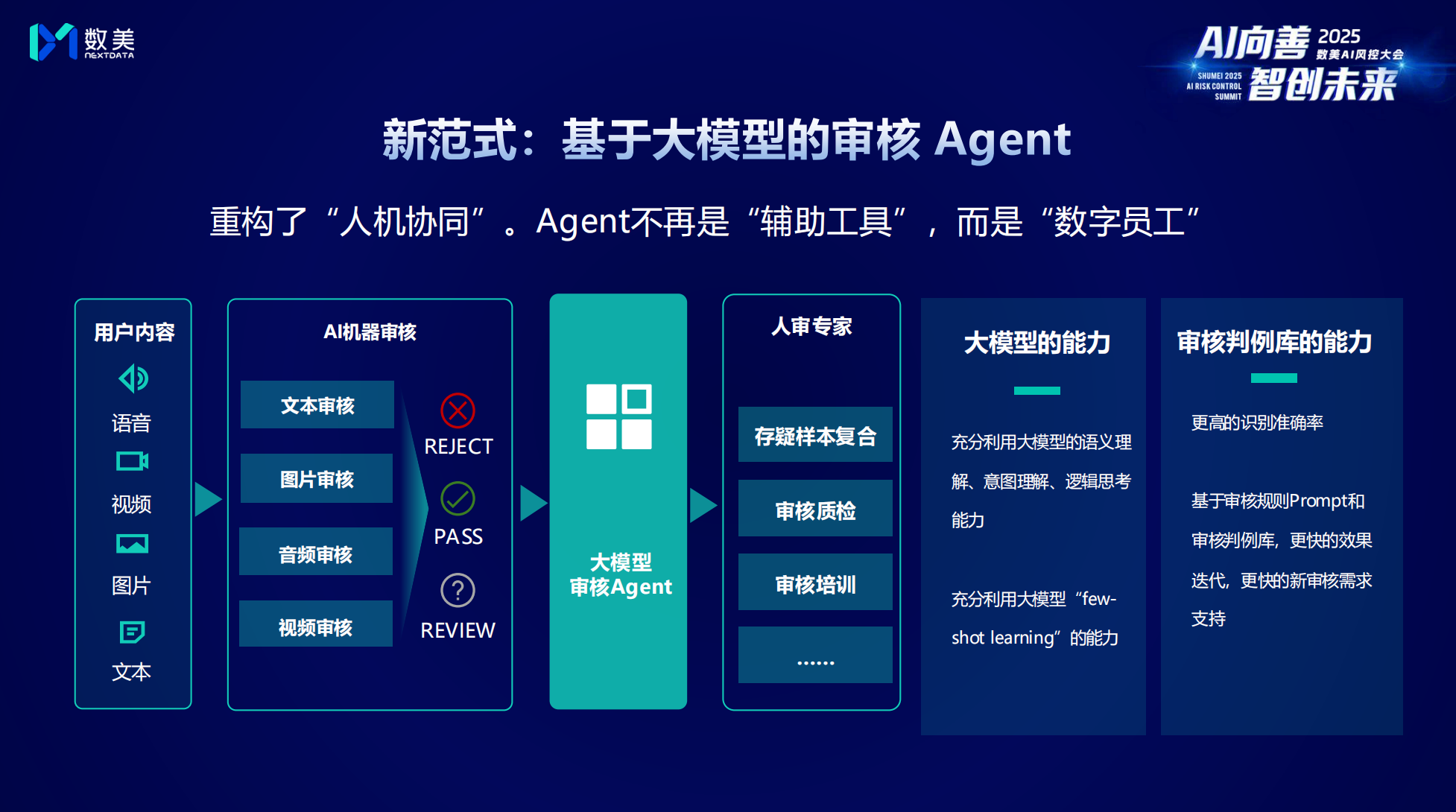
面对规模更大、语义更复杂、对抗更激烈的挑战,传统的“机审+人审”旧范式已难以为继。为此,以“大模型审核 Agent ”为核心驱动的“ AI 风控新范式”成为了新的趋势。梁堃表示,传统风控往往停留在识别违规关键词或图片的表层,而新范式则强调对“意图”与“潜台词”的深度理解。面对 AI 的错误、AI 的侵权及对 AI 的“攻击”等新型挑战,数美重构了“人机协同”模式——引入基于大模型的审核 Agent。
“Agent 不再是辅助工具,而是能够像人类一样思考的‘数字员工’。”这一变革将风控体系升级为“AI 机器审核+大模型审核 Agent +专家决策”的三角链路,大幅提升了对复杂风险的研判能力。
在账号安全领域,黑产已利用 AI 技术实现了“降维打击”,不仅能批量制造高拟真的虚假账号,甚至能利用 Deepfake 伪造人脸和视频进行欺诈。对此,数美的应对之策是:“新一代设备指纹”与“深度行为分析”。通过全面引入微行为分析与 LLM 技术,数美能够基于账号的行为序列与团伙特征,精准揪出伪装在屏幕背后的“ AI 幽灵”,真正实现“用 AI 对抗 AI ”。
当黑产完成了智能体进化,风控的终局便不再是单纯的技术博弈,而是防御体系的代际跃迁。在这场用 AI 对抗 AI 的战役中,唯有依托机器+Agent+专家的三角协同,将防御从线性的规则拦截升级为立体的意图洞察,我们才能在不断被 AI 模糊的真假边界中,重建起坚固的数字信任防线。




