
谷歌 DeepMind 的研究人员提出了 ATLAS,这是一套针对多语言语言模型的缩放定律,用于形式化描述随着支持语言数量的增加,模型规模、训练数据量以及语言组合之间如何相互作用。该研究基于 774 次受控训练实验,模型参数规模从 1000 万到 80 亿不等,使用覆盖 400 多种语言的多语言训练数据,并在 48 种目标语言上评估模型性能。
现有的大多数缩放定律主要来源于仅使用英语或单一语言的训练设置,因此对于多语言训练的模型只能提供有限的指导。ATLAS 在此基础上进行了扩展,显式建模了跨语言迁移以及由多语言训练引入的效率权衡。该框架不再假设新增语言会产生统一影响,而是估计在训练过程中,单个语言如何促进或干扰其他语言的性能表现。
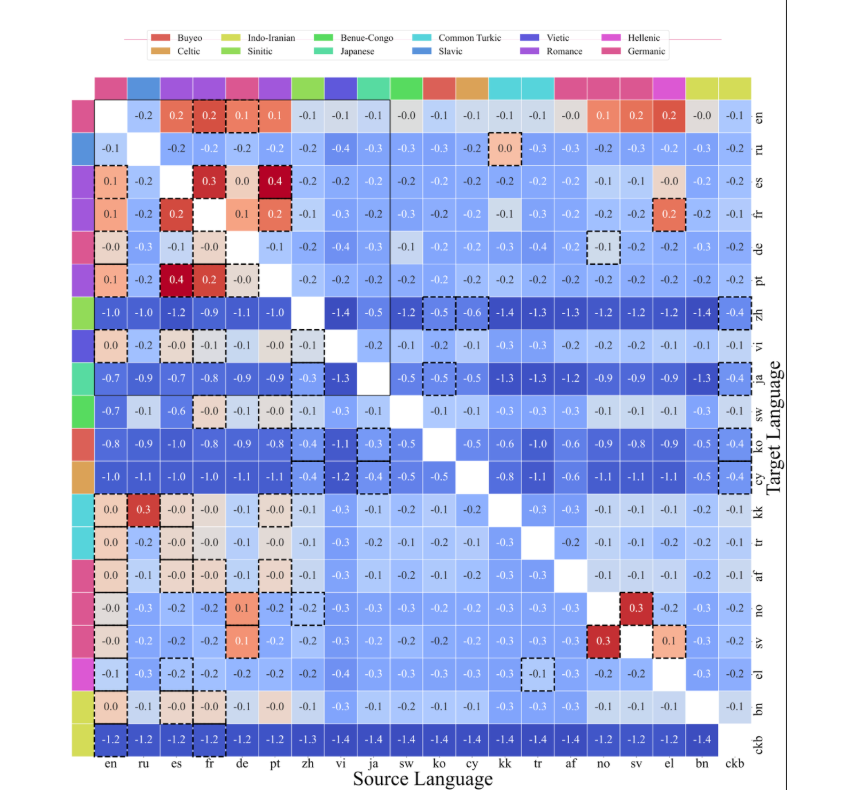
ATLAS 的核心是一种跨语言迁移矩阵,用于衡量在一种语言上训练对另一种语言性能的影响。分析结果表明,正向迁移与共享书写系统和语言家族高度相关。例如,斯堪的纳维亚语言之间表现出明显的相互增益,而马来语和印尼语则构成了一个高迁移效率的语言对。英语、法语和西班牙语则表现为广泛有益的源语言,这很可能与其数据规模和多样性有关,但这种迁移效应并不具备对称性。
ATLAS 通过将训练语言数量与模型规模和数据量一并纳入建模,扩展了传统的缩放定律。它量化了所谓的“多语言诅咒”:在模型容量固定的情况下,随着支持语言数量的增加,每种语言的性能会下降。实验结果表明,在保持性能不变的前提下,若语言数量翻倍,模型规模需增加约 1.18 倍,总训练数据量需增加约 1.66 倍;而正向的跨语言迁移可以在一定程度上抵消单语言数据减少所带来的性能下降。
该研究还分析了在不同条件下,是从零开始预训练一个多语言模型,还是在已有多语言模型检查点上进行微调更为有效。结果显示,在较低 token 预算下,微调在计算效率上更具优势;而当训练数据和计算资源超过某一与语言相关的阈值后,从头预训练反而更有利。对于 20 亿参数规模的模型,这一拐点通常出现在约 1440 亿到 2830 亿 token 之间,为根据可用资源选择训练策略提供了实用参考。
此次发布也引发了关于替代模型架构的讨论。一位 X 用户评论道:
与其训练一个在每种语言上都使用大量冗余数据的超大模型,一个纯粹用于翻译的模型需要多大规模?这样又能让基础模型缩小多少?
尽管 ATLAS 并未直接回答这一问题,但其提供的迁移测量结果和缩放规则,为探索模块化或专用化的多语言模型设计奠定了定量基础。
原文链接:




