
这两天,OpenRouter 一个名为“Elephant”(大象)的模型,Trending 榜排名突然超过 Gemma 4 31B,位列排行榜第二名。
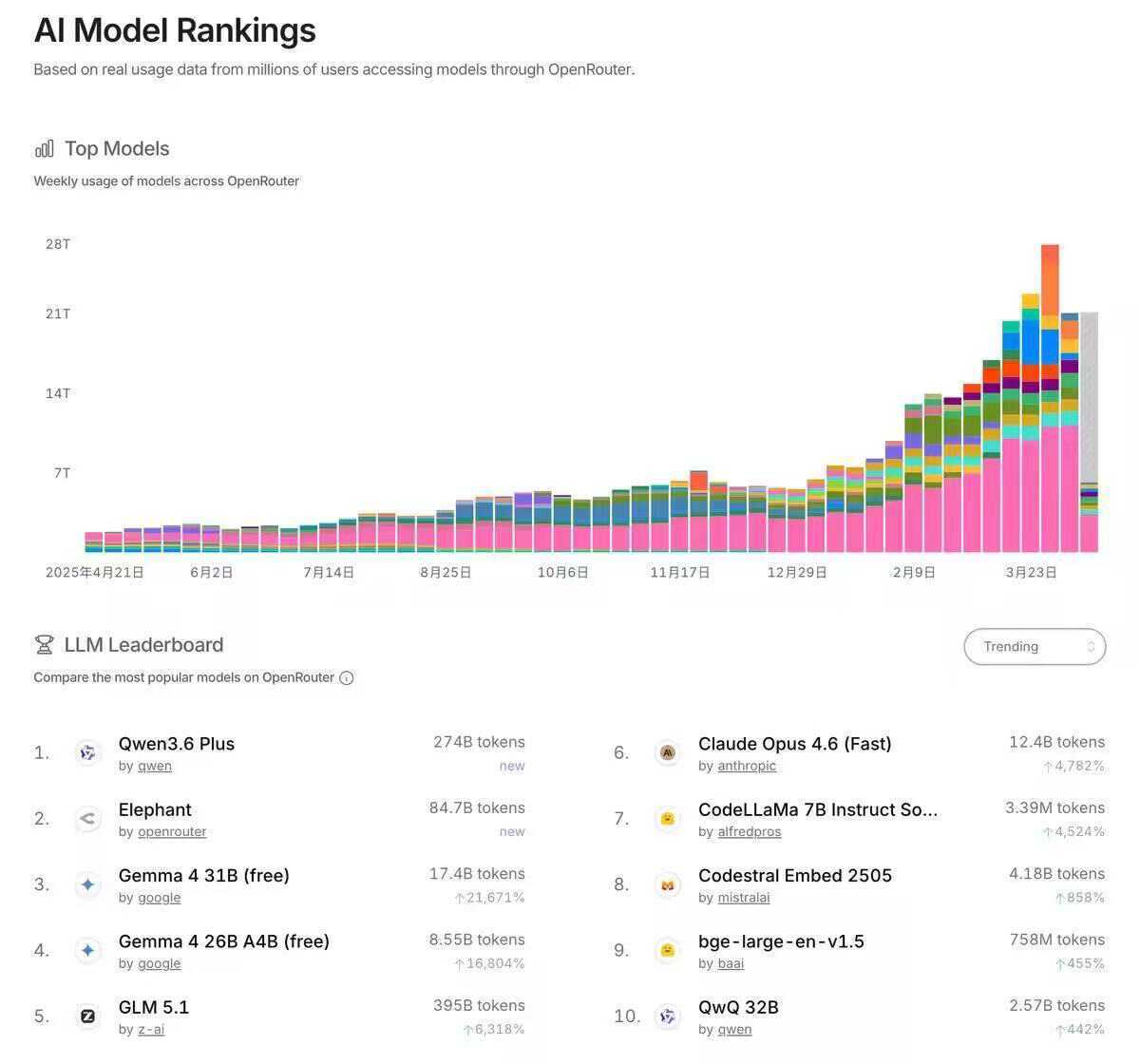
根据 Kilo 的说法,这款模型来自一家知名开源模型实验室,主打“智能效率”,在尽量减少 token 消耗的同时,提供接近同规模 SOTA 性能表现。
Elephant 是一款 100B 参数隐身模型(stealth model),支持 256K token 上下文窗口,可以一次性加载整个代码仓库或大型依赖树;最大输出长度为 32K token,适合单次生成完整模块或整套测试代码。与此同时,这款模型还支持提示缓存、函数调用和结构化输出,明显面向企业级开发和智能体工具链接入场景。
据 Kilo 介绍,Elephant 不是一款单纯追求规模的“大模型”,更强调速度、响应和实际开发效率。Elephant 主要针对快速代码补全与调试、大规模文档处理以及轻量级智能体交互等场景进行了优化,适合需要高频调用、低延迟反馈的开发工作流。相比那些更重、更慢的模型,Elephant 希望成为开发者日常使用中的“高响应主力模型”。
具体地,我们将同是 100B 级别的 NVIDIA Nemotron 3 Super、Qwen3.5-122B-A10B,以及 OpenAI 的 gpt-oss-120b 进行了直接对比。
在速度方面,Elephant 最快,平均响应时间约 1.27 秒;Qwen3.5-122B-A10B 最慢,平均约 31.38 秒。Elephant 在数据解析与提取平均响应时间只花了 979 毫秒,综合项目也只用了 3.70 秒。
相比之下,Qwen3.5-122B-A10B 的表现是靠更高的推理投入换来的,比如编程项目平均响应时间高达 70.98 秒,综合项目平均响应时间更是达到 107.79 秒,数据解析与提取这类任务也用了 16,558 推理 token。
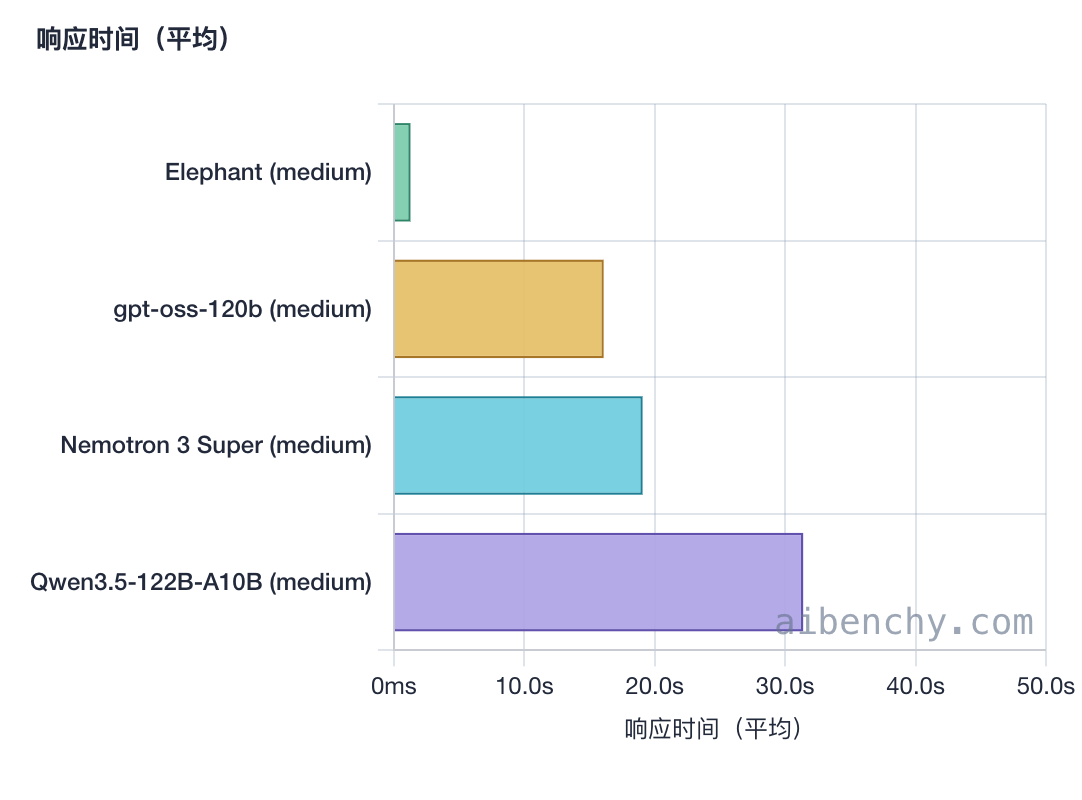
而在 token 消耗方面,Qwen3.5-122B-A10B 是这组里最“烧 token”的模型,推理 token 远高于另外三个;gpt-oss-120b 和 Nemotron-3 Super 120B 属于中间档;Elephant 基本不消耗。
在指令遵循上,Elephant 在稳定性上表现最突出。其一致性得分达到 9.6,说明它在重复运行中的结果波动最小,是这组模型里最稳定的一款。但 Qwen3.5-122B-A10B 在正确率和通过能力上依然领先,Nemotron-3 Super 120B A12B 表现较为均衡,而 gpt-oss-120b 则暴露出更明显的波动性。
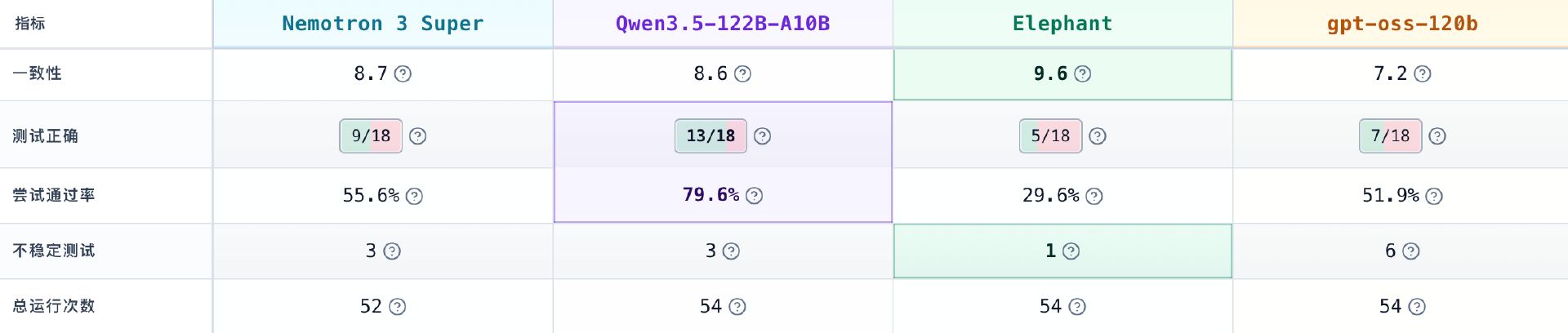
Elephant 的问题是综合项目上只有 3.0,在数据解析与提取上是 6.5,侧面说明其目前追求的是高频、低成本、先求有结果再说的场景,而非复杂 agent 工作流或者关键判断任务场景。
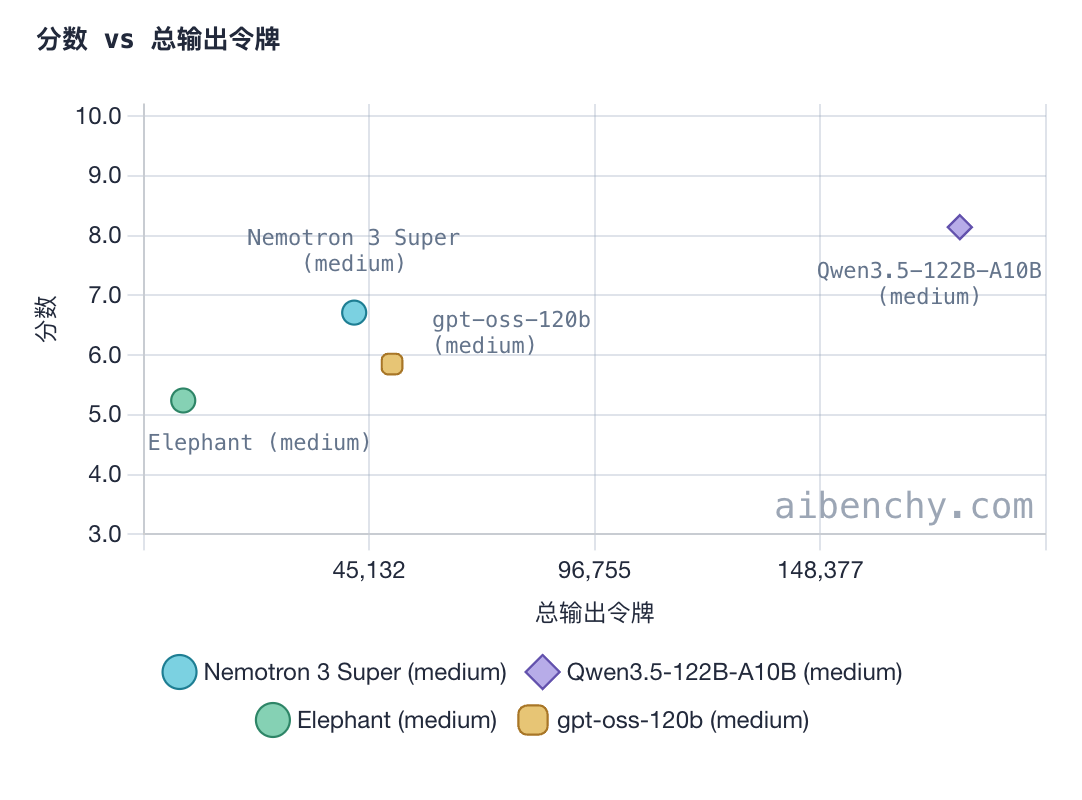
因此,如果将各个维度综合起来打分的话,Qwen3.5-122B-A10B 综合分 8.1,排第一,NVIDIA Nemotron-3 Super 120B A12B 6.7 分排第二,OpenAI gpt-oss-120b 第三,Elephant Alpha 第四。
与 Elephant Alpha 类似,Nemotron-3 Super 120B A12B 在综合项目上拿到 10.0,在工具调用上也是 10.0,在数据解析与提取上同样是 10.0。从结果看,它很适合那种流程清晰、任务边界明确、强调执行链条和调用能力的场景。但它在领域专项上只有 2.9,在通用智能上是 3.8,在谜题求解上只有 3.5,说明一旦任务从“结构化执行”转向“开放复杂推理”,其掉队就很明显。gpt-oss-120b 则在编程项目上只有 4.3,还出现了未遵循指令的问题。
可以看出,虽然同为 100B 级别模型,但大家的研发重点并不相同。
Qwen3.5-122B-A10B 代表了重推理、重完成度路线,有更高的分数和通过率,但需要付出更多延迟和更高推理开销。而 Nemotron-3 Super 120B A12B 是工作流型路线,它不一定最适合复杂开放问题,但在结构化抽取、工具调用、执行链条这类任务上表现突出。新上榜的 Elephant 则代表了极致轻量路线,把“快”和“低成本”做成了核心卖点。
相关链接:
https://blog.kilo.ai/p/introducing-elephant-a-new-stealth




