
2026 年,智能体将在企业级应用中取得哪些实质性突破?点击下载《2026 年 AI 与数据发展预测》白皮书,获悉专家一手前瞻,抢先拥抱新的工作方式!
自 Observe 三个月前加入 Snowflake 以来,我们一直以加速的节奏推进工作,接入新用户并构建扩展观测访问的新功能。但 Observe 要解决的核心问题未曾改变。我们的使命依旧是实现大规模观测,这也是当今许多企业面临的挑战。
为什么大规模观测是一个数据问题
现代系统生成的遥测数据(包括日志、指标和追踪)的数量已超出传统方法的处理能力,领先企业每天需摄取数百 TB 数据。随着 AI 生成代码的普及和 AI Agent 的扩展,遥测数据的规模和复杂性只会不断增加。如果不解决这一问题,观测成本将变得无法承受,排障时间也会随之增加。
遗留系统的问题在于其架构,具体表现为多方面:
基于索引的系统开销高;
存储与计算高度耦合 ;
依赖高价存储 ;
数据以专有格式孤立存放 。
由于大规模观测本质上是一个数据问题,因此将观测解决方案与数据平台紧密集成具有最合理的架构意义。在 Observe,我们早期就决定基于 Snowflake 构建现代观测架构,利用其丰富功能,在不受传统架构成本与性能限制的情况下提供观测能力。
什么是 Snowflake 的 Observe
Observe 是一个 AI 驱动的观测平台,从设计之初就旨在支持大规模操作。它旨在解决遗留系统的不足,采用现代观测架构,包括 AI SRE、观测上下文图(Observability Context Graph)以及遥测湖仓(Telemetry Lakehouse Foundation)。其结果是以更低成本实现更快速的排障。

可编程 AI SRE
Observe 通过内置 AI SRE 提供 AI 驱动的观测,同时支持通过 MCP 或 CLI(即将推出)访问。SRE、开发人员、支持工程师及自动化 Agent 均可通过最适合其工作流程的界面访问和交互遥测数据。这种程序化访问使组织能够在观测数据之上构建自定义的 Agent 驱动工作流。
为精确度而设计的上下文
观测上下文图模型化了环境中的语义和关系,连接跨服务和基础设施的日志、指标和追踪,并扩展至业务和代码上下文。其结果是基于为观测结构化和策划的上下文,实现更快速、更准确的推理。
成本效益的可扩展性
遥测湖仓是 Observe 架构的支撑,提供低成本云存储和计算-存储分离,并继承 Snowflake 的核心特性,使 Observe 能以更低成本摄取、存储和分析 PB 级遥测数据。
AI SRE Agent 需要观测上下文以提升效率
上下文对于高效的 AI 驱动观测至关重要。当团队将 Agent 纳入运维工作流时,如果缺乏上下文,Agent 可能会出现查询超时、响应不可靠或 token 消耗高于预期的问题。访问正确的观测上下文后,Agent 的效率将大幅提升。Agent 能够解析歧义术语、遍历复杂关系并缩小搜索空间,从而以显著更低的成本返回更精确的结果。这正是 Observe 实践中支持 Agent 驱动工作流的基础。观测上下文图是驱动查询精确性、速度和成本效率的根本架构差异。
实践中的应用
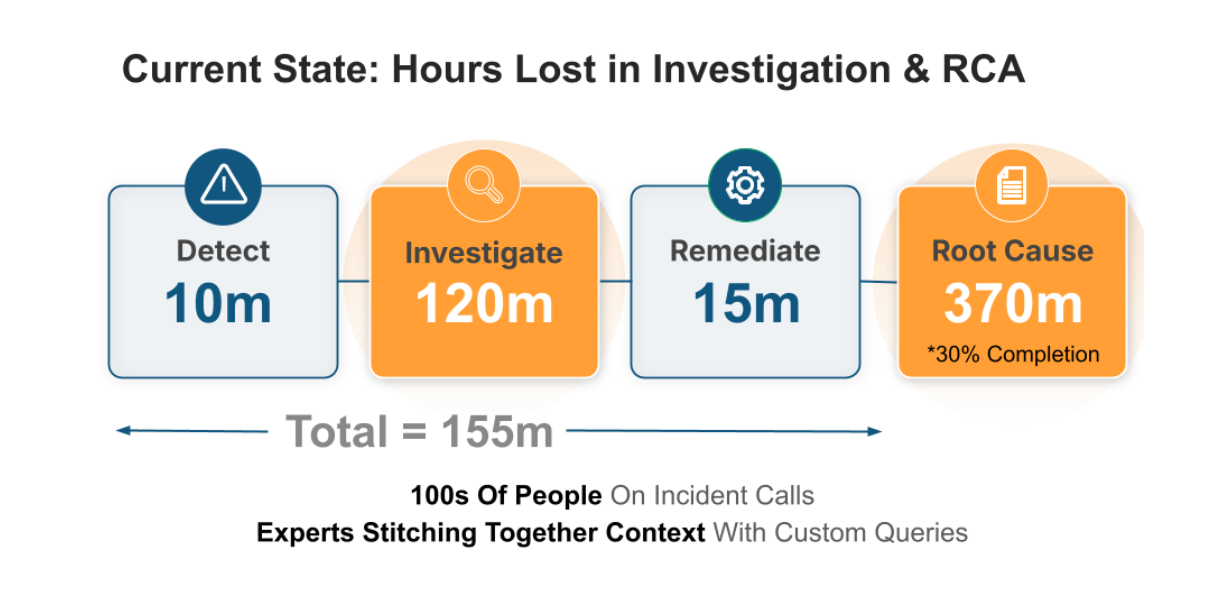
一个具备上下文的 AI SRE Agent 如何加速排障流程?考虑一次事件调查,某服务开始返回错误且影响范围不明确。
在典型工作流中,工程师可能会:
从一个工具中提取 ID;
在另一个工具中运行查询;
导出数据进行关联;
在系统间重复上述步骤。
大量时间花费在确定查询范围上。
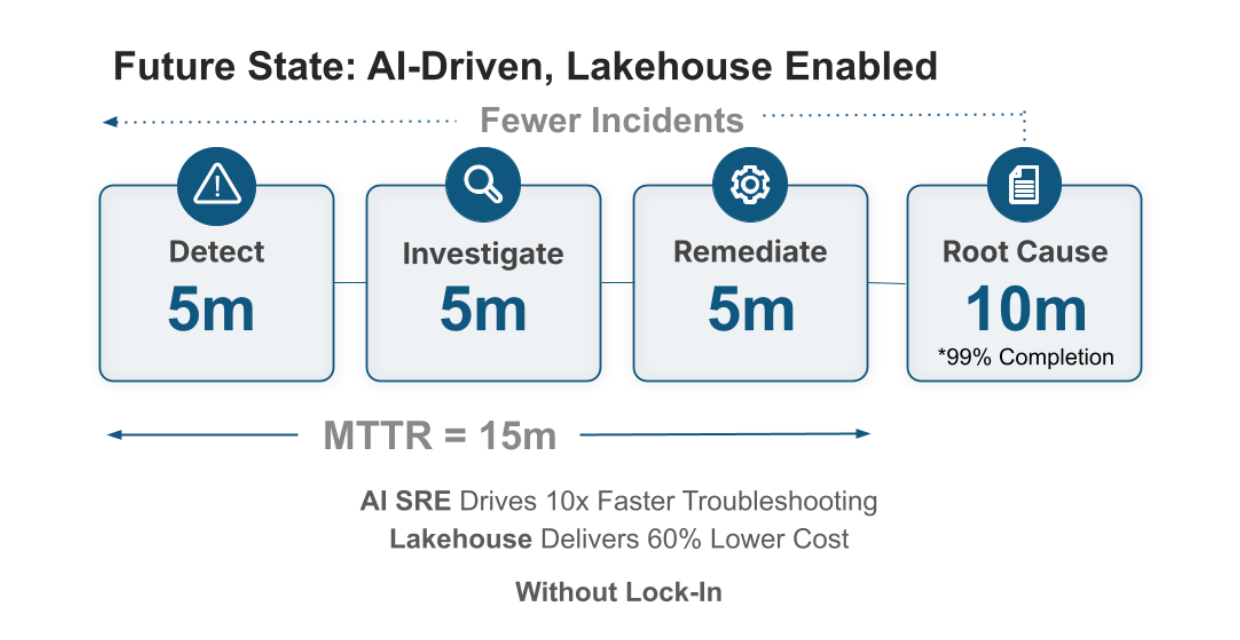
使用上下文感知的 Agent 进行同样调查的流程可能如下:
Agent 查询上下文图;
Agent 识别受影响服务;
Agent 遍历依赖关系;
Agent 隔离变更事件;
Agent 提取相关日志和追踪。
Agent 返回的不是原始信号列表,而是一组针对“问题出在哪里以及如何修复”的精确结果。
作为 Snowflake 一部分的观测扩展
自加入 Snowflake 以来,我们观察到接触观测的人群正在发生变化。数据负责人开始关注遥测作为一级数据对象的价值,强烈希望将遥测与企业其他数据一起存储、治理和分析,而非孤立在工程工具中。
同时,AI SRE、DevOps 和软件工程工作流的兴趣正在加速增长。这推动现有客户的扩展,使观测成为运营中更主动的一部分。我们还看到前瞻性团队跳过传统观测界面,在 Observe 的 MCP 服务器上直接构建自己的观测 Agent,直接基于存储在 Observe 中的数据和上下文操作。
这一增长势头的重要原因在于降低了入门门槛。Snowflake 客户现在可以使用现有 Snowflake 积分,无限制地用于 Observe,使采用观测作为 Snowflake 数据平台一部分变得更加容易。
开放数据与灵活访问
我们正在两个方向扩展平台:原生 Agent 访问和使用开放格式的数据互操作性。目标是使遥测数据及其构建的上下文可从用户偏好的环境访问,并通过符合其工作方式的访问路径使用。
Observe CLI:对观测上下文的程序化访问
开发人员越来越多在 IDE、终端和编码 Agent 旁工作。观测必须融入这个流程。 我们将推出 CLI(即将发布),针对 Agent 驱动工作流设计,为开发者提供与遥测交互的另一途径,可能是最自然的选择。上下文感知对于 Agent 效率至关重要,Observe 将允许通过 CLI 执行任务的 Agent 查询上下文图。
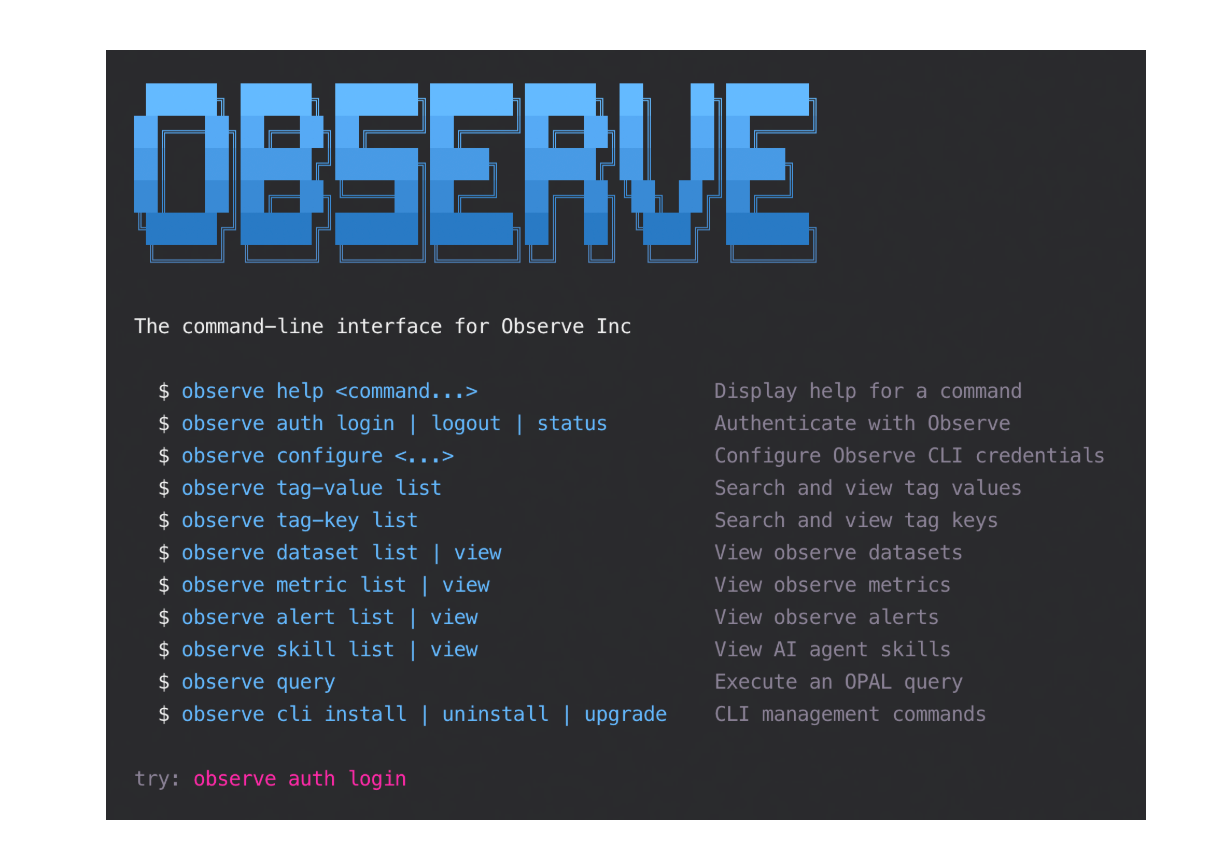
Observe CLI 将使用户和 Agent 能够基于可复用技能集操作观测数据和上下文——这些技能是针对常见任务(如事件调查、故障追踪或变更验证)构建的结构化工作流。一些工作流可在后台自主运行,另一些可交互调用。模型支持 Agent 处理例行任务,也支持工程师直接执行并指导更复杂调查,可能在如 Claude Code 的环境中操作。CLI 将成为系统控制界面,提供对 Observe 能力的细粒度程序化访问,使观测得以组合、自动化和长期扩展。
Apache Iceberg:开放访问所有遥测
我们还展示了对 Apache Iceberg 的读写支持进展。观测数据可以直接写入您自有数据湖的 Iceberg 表,存储在对象存储中,并通过 Observe UI、CLI 或 MCP 或任意兼容引擎访问。这意味着您拥有 Observe 摄取和处理的遥测数据,它与其他数据并存,受您控制,并可通过团队已使用的工具访问。
整个组织的团队可在不提取或复制到独立系统的情况下,查询并组合遥测数据与其他数据。同时,工程团队仍可在同一数据上使用 Observe 原生观测工作流。在 Iceberg 表上运行的观测工作流性能与 Observe 原生数据相当。结果是提高了数据存储与治理的灵活性,以及访问和使用方式的灵活性。
观测的未来
我们一直认为观测是一个数据问题。随着 AI 增加系统复杂性和遥测数据量,这种压力加剧,考验底层数据平台的规模和经济性。
团队在两个方面作出响应。首先,他们需要更高效的方式存储、处理和查询高容量遥测数据,而不会导致成本不可持续增长。其次,他们采用 AI 驱动工作流,以降低 MTTR(平均修复时间)并转向更主动的可靠性工程。
Observe 正在构建以满足这些需求。Iceberg 的支持允许团队通过将遥测存储在低成本云存储的数据湖中管理成本,同时实现广泛访问,避免厂商锁定。Observe CLI 反映了观测消费方式的巨大转变,从精心策划、基于 UI 的体验转向通过 CLI 和 MCP 程序化访问,并支持像 Claude Code 和 ChatGPT 这样的工具。
随着观测用户及其访问模式持续演变,对大规模遥测及上下文的需求保持不变。Observe 提供了这一基础,同时不断扩展客户存储、访问和使用数据的方式。
了解更多
观看由 Jeremy Burton 主持的 Snowflake Observe 发布活动。
前瞻性声明
本文包含前瞻性声明,包括有关我们未来产品的内容,但并非产品交付承诺。实际结果和产品可能有所不同,并受已知及未知风险与不确定性影响。详见最新 10-Q 报告。
原文地址:https://www.snowflake.com/en/blog/observe-by-snowflake-ai-observability-at-scale/
点击链接立即报名注册:Ascent - Snowflake Platform Training - China,更多 Snowflake 精彩活动请关注专区。




