
⼀场震动 AI⾏业的指控
2026 年 2⽉23⽇,Anthropic 正式公开指控三家中国 AI 公司——DeepSeek、MiniMax 和 Moonshot AI ——利⽤超过 24,000 个虚假账⼾,对其旗下 Claude 模型进⾏了总计超过 1,600 万次对话交互,通过“模型蒸馏”技术⼤规模提取 Claude 的核⼼能⼒。
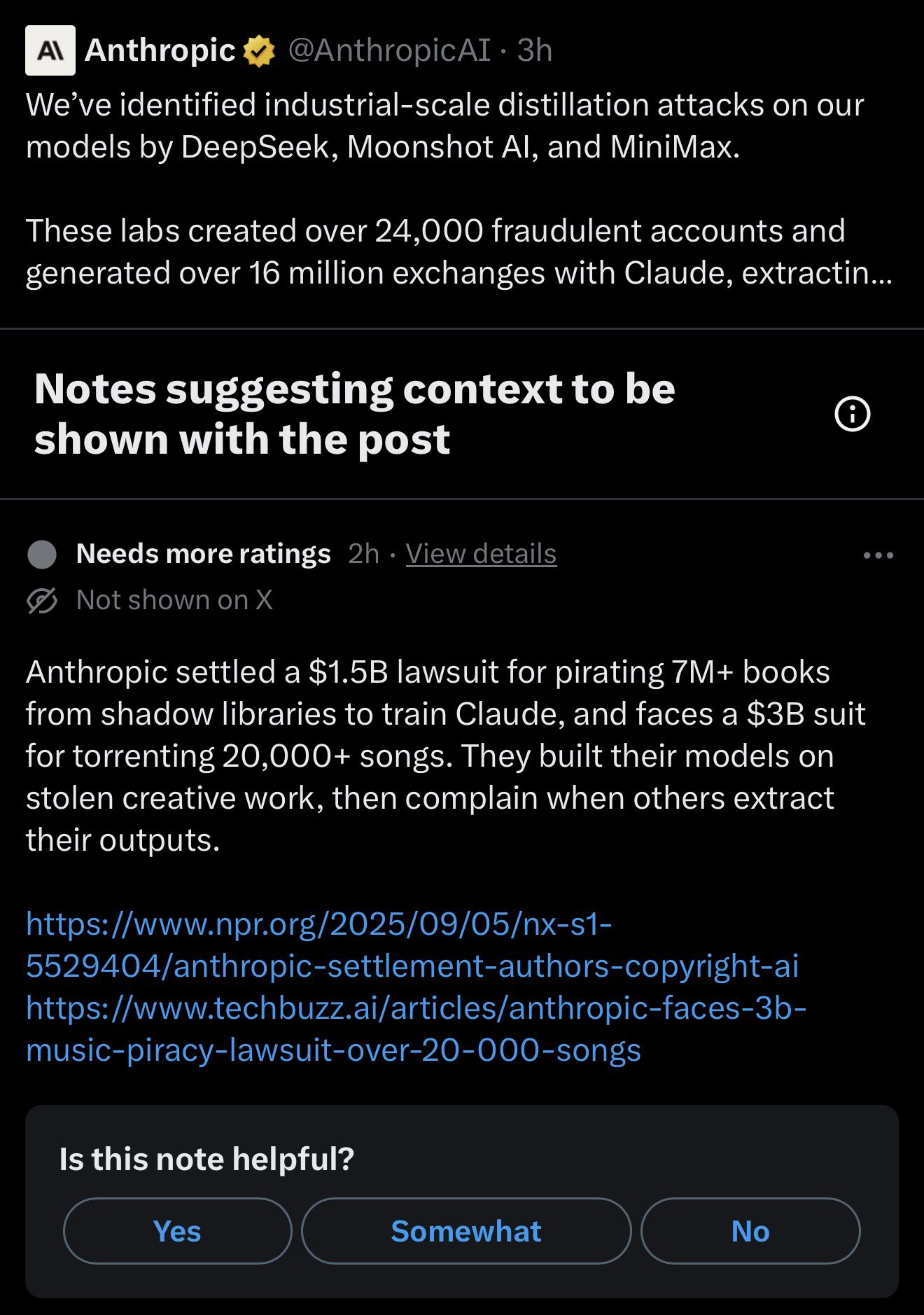
这不是⼀句模糊的“我们怀疑有⼈抄了”。Anthropic 拿出了 IP 地址追踪、元数据分析、⾏业伙伴交叉验证,甚⾄将部分账⼾关联到了具体的公司研究⼈员。截⾄发稿,三家公司均未公开回应。三家公司中,MiniMax 交互量最⼤(1,300 万次),Moonshot 居中(340 万次),DeepSeek 量最⼩但据称⼿法更有针对性(15 万次),专攻推理链的逆向提取。
乍⼀看,这是⼀个清晰的故事:有⼈偷了东西,被抓了。
但越往深看,越觉得不简单。抄了 1,300 万次作业的那家,为什么产品还是打不过⽼⽼实实练基本功的同⾏?指控别⼈偷的这家,⾃⼰的训练数据就⼲净吗?为了抓住“⼩偷”,平台对所有⽤⼾的对话到底看了多深?⽽这⼀切发⽣的时间节点——恰好是 Anthropic 在五⻆⼤楼谈判桌上最需要筹码的时候。
更别提,还有⼀种规模远超 1,300 万次的“蒸馏”,正在全球范围内公开进⾏,从来没有⼈叫它蒸馏,也从来没有⼈喊停。
这篇⽂章会从头讲清楚模型蒸馏是什么、怎么操作、威⼒有多⼤。但更重要的是,我们会追问那些新闻标题⾥不会告诉你的问题。
先从技术本⾝说起。
蒸馏:⼀个诺贝尔奖得主的“好主意”
2015 年,Geoffrey Hinton——后来拿了 2024 年诺⻉尔物理学奖的“深度学习之⽗”——和 Google 的 Jeff Dean 等⼈发表了⼀篇论⽂,正式提出了“知识蒸馏”(Knowledge Distillation) 的概念。
他的出发点很朴素:⼤模型能⼒强,但太笨重、太贵、跑太慢,能不能把⼤模型的“知识”压缩进⼀个⼩模型⾥?
Hinton 注意到⼀个关键现象:⼤模型在给出答案之前,内部其实产⽣了⼀组丰富的概率分布。 ⽐如让它识别⼀张动物图⽚,它不只是说“这是猫”,⽽是给出“猫 90%、狗 8%、虎 2%”。这个分布本⾝就是知识——它说明了猫和狗⽐猫和卡⻋更相似。⽤这种“软知识”去教⼩模型,⽐只告诉它“对或错”有效得多。
这个技术迅速成了⾏业标配。Google⽤它、OpenAI⽤它、Anthropic ⾃⼰做轻量版模型 Haiku 时也⽤它。完全合法,完全正向——让 AI 更便宜、更快、更容易部署到⼿机和边缘设备上。
⼗年后,同样的技术被⽤在了 Anthropic 指控的这个场景⾥。只不过⽅向变了:不再是压缩⾃⼰的⼤模型,⽽是从别⼈的⼤模型⾥抽取能⼒。
⼀个⼩时学会⼗年功夫
传统的 AI 模型训练,像是让⼀个学⽣从⼩学开始⾃学——读课本、做习题、犯错、总结,⼀步步积累能⼒。这个过程需要海量数据、巨⼤算⼒、⼤量⼈⼯标注,周期⻓达数⽉,花费动辄数亿美元。
模型蒸馏的逻辑完全不同:不⾃⼰学,直接抄“学霸”的答题过程。
具体怎么操作?三步:
第⼀步:批量出题。 针对你想提取的能⼒(⽐如推理、代码编写、⼯具调⽤),设计成千上万个精⼼构造的问题。不是随便问,⽽是覆盖这项能⼒的各种维度和难度组合。
第⼆步:让“学霸”答题。 把这些问题发给⽬标模型(⽐如 Claude),收集它的全部回答。这些回答⾥隐含了模型的判断逻辑、推理路径、表达策略——这是花了⼤量资⾦和算⼒训出来的能⼒结晶。
第三步:⽤答案训练⾃⼰的模型。把这些⾼质量的“问题-回答”数据对,直接喂给⾃⼰的模型做训练。你的模型不需要理解“为什么这样回答好”,只需要学会“遇到这类输⼊时,输出这种模式”。
举个具体例⼦。假设我想让⾃⼰的模型学会“智能客服处理客⼾投诉”的能⼒:
“客⼾要求把贷款利率从 4.5%降到 2%,否则转⾛存款,怎么回复?”,同样的场景,但客⼾是 VIP;
同样的场景,但客⼾正在发脾⽓;
同样的场景,但客⼾搬出了⾏⻓的名字。
⼀个能⼒点,展开成 5,000 个变体。Claude 对每个变体给出⼀个⾼质量回答——什么时候坚持原则、什么时候给台阶、怎么平衡合规和客⼾体验。这 5,000 对数据的质量,远⾼于你从互联⽹上能爬到的任何东西。
“5,000 条数据,只能应对 5,000 种情况吧?” 直觉上是这样,但神经⽹络不是背题库。
你给孩⼦做 100 道⼏何证明题,他学到的不是“100 道题的标准答案”,⽽是“辅助线该往哪⾥做”的直觉。遇到第 101 道没⻅过的题,他照样能做。
模型训练⼀样。那 5,000 条银⾏客服数据喂进去,模型学到的是⼀套放在哪⼉都管⽤的应对逻辑:情绪升级时先共情再给⽅案,涉及合规红线时⽤“制度要求”⽽⾮“我不⾏”来托底,对⽅搬出权⼒关系时既不接招也不硬顶。
蒸馏的精妙之处在于:你不需要覆盖所有场景,只需要覆盖⾜够多的能⼒维度。 就像不需要教孩⼦每⼀道可能出现的⼏何题,只需要让他把“相似三⻆形”“圆的切线”“⾯积法”⼏个核⼼⽅法练熟,他就能组合应对绝⼤多数题⽬。
所以 MiniMax 做了 1,300 万次交互——这不是在收集 1,300 万个答案,是在系统性扫描 Claude 的整个能⼒图谱。
1,300 万次,怎么可能做到?不需要⼈。
⼀个脚本,⼏⼗⾏代码。⽤AI 批量⽣成 prompt,再⽤Claude 批量回答。机器对机器,24⼩时不停。24,000 个假账号分散请求,每个账号每天⼏百条,混在正常⽤⼾流量⾥,⼀个⽉就能跑完。
Anthropic 在报告中描述了⼀种叫“Hydra Cluster”的架构:⼀套代理⽹络同时控制两万多个账号,⾃动轮转、⾃动混⼊正常请求来躲避检测。实际操作团队可能只需要⼏个⼯程师。
成本?按 API 定价粗估,1,300 万次对话⼤约⼏⼗万美元。对⽐从头训练⼀个同等能⼒模型需要的数亿美元——投⼊产出⽐惊⼈。
这也是为什么 Anthropic 说这件事光靠⾃⼰防不住:攻击⽅的边际成本⼏乎为零,防守⽅要在海量正常流量⾥⼤海捞针。
1,300 万次到底覆盖了多少?
Anthropic 报告提到 MiniMax 主攻的⽅向包括⾃主编程、⼯具调⽤、任务编排等。综合其他报道,加上推理、视觉等领域,假设总共覆盖⼗⼏个⼤的能⼒域。
算⼀笔粗账:1,300 万次交互分配到 15 个能⼒域,每个域⼤约 87 万次。每个域下⾯拆出 50 个⼦任务,每个⼦任务⼤约 17,000 个变体。
17,000 个变体意味着什么?意味着⼀个具体的能⼒点——⽐如“从⼀段⾃然语⾔需求⽣成可执⾏的 SQL 查询”——被从各种⻆度、各种边界条件、各种难度级别反复扫过。这不是⼤海捞针式的乱抓,⽽是⼀张精⼼设计的能⼒扫描⽹,基本把⽬标模型最有商业价值的能⼒维度都过了⼀遍。
但抄作业有天花板
读到这⾥,你可能觉得蒸馏⽆敌了。 实际上不是。
⼀个有趣的事实:MiniMax 做了 1,300 万次蒸馏,但在很多⽤⼾的体感中,它的模型并不⽐⼀些没有被曝出蒸馏⾏为的国产模型更好⽤。
这恰恰说明蒸馏有它绕不过去的短板。
抄作业能让你从 60 分快速冲到 85 分,但从 85 分到 95 分靠的不是抄更多作业——是你⾃⼰的底⼦: 模型架构怎么设计、预训练数据质量好不好、训练⼯程扎不扎实、跟⼈类偏好的对⻬调得细不细。这些东西,蒸馏搬不⾛。
⽽且蒸馏有⼀个硬顶:你最多只能接近⽼师,不可能超过⽼师。⽬标模型⾃⾝的短板,你也原样继承了。
那些被觉得“更好⽤”的模型,往往是在底⼦上下了更扎实的功夫——训练数据质量更⾼、更懂⽬标⽤户的习惯和偏好、在具体场景上打磨得更深。这是硬功夫,没有捷径。
1,300 万次蒸馏,结果并没有造出公认最强的模型——这本⾝就是蒸馏局限性的最好注脚。
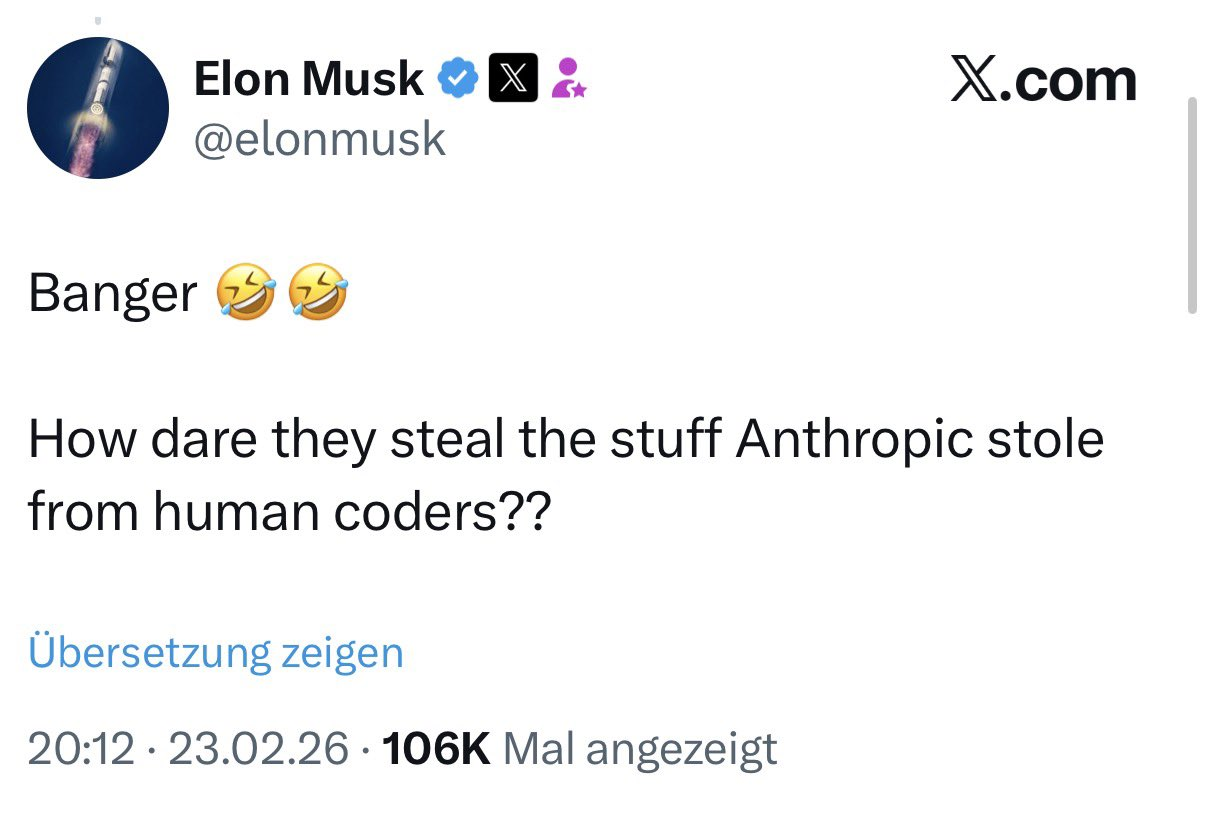
“可是 Anthropic⾃⼰的训练数据不也是‘偷’来的?”
这是很多⼈的第⼀反应,也不是没有道理。
Anthropic 训练 Claude 时,⼤规模抓取了互联⽹上的书籍、新闻、论⽂、代码、论坛帖⼦——其中⼤量 内容的版权属于原作者,既没有被告知也没有授权。《纽约时报》诉 OpenAI、 Getty Images 诉 Stability AI,打的都是这个仗。
所以就有了⼀个绕不开的追问:你拿别⼈的作品训练出模型,然后宣称模型的输出不可被提取——“所有权”到底从哪⼀环开始成⽴?
但这两件事放在⼀起⽐,还是有本质区别的:
法律性质不同。训练数据的版权争议⽬前还没有定论,合理使⽤(fair use)的边界还在被法院⼀点点划定。⽽Anthropic 所指控的蒸馏⾏为涉及违反服务条款、使⽤欺诈账⼾、绕过地域限制——这些在合同法层⾯是板上钉钉的违约。
做法不同。训练基础模型时,从海量数据⾥学通⽤规律,任何单⼀来源的内容都被稀释到了可以忽略的程度。蒸馏是盯着你⼀个模型定点抽取——精⼼设计 Prompt,专⻔榨你最值钱的能⼒。⼀个是“读了⼀万本书”,另⼀个是“把隔壁学霸的笔记本偷来复印”。
这不意味着 Anthropic 在道德上就完全站得住。只是说明这是两个不同层⾯的问题,不能简单地⽤“你也偷了”来对冲。
你的企业可能正在灰⾊地带⾥
上⾯说的是 Anthropic 指控的违规⾏为。但现实中,⼤量企业的正常使⽤⾏为,其实离“蒸馏”只有⼀步之遥。假设⼀家电商公司是 Claude 的付费企业客⼾,⽤它来⽣成客服话术——处理退货纠纷、应对差评投诉、化解价格争议。⽣成了⼏千条⾼质量回复后,存进内部知识库。以后客服遇到新问题,系统⾃动从知识库⾥检索最相似的话术推荐给客服。
这完全合规,是标准的企业 AI 应⽤。
但仔细看——它的效果和蒸馏⼏乎⼀样:付⼀次钱,把能⼒带⾛了。新场景来了不需要再问 Claude,知识库加语义检索就能覆盖绝⼤多数情况。
类似的场景到处都是:
律所⽤Claude 批量⽣成合同审核意⻅,整理成模板库,以后新合同对照模板⾛,不再需要 AI 逐份审核;
医疗公司⽤Claude 撰写⼏百种常⻅症状的分诊指南,嵌⼊⾃⼰的问诊系统,从此⾃给⾃⾜;
⼴告公司⽤Claude 为不同⾏业、不同调性⽣成上千条⽂案范本,建成内部的“创意弹药库”。
这些企业没有⼀个在做“蒸馏攻击”,甚⾄动机完全正当。但效果是⼀样的:⼀次性提取 AI 的能⼒,转化为⾃⼰的⻓期资产。
那 Anthropic 的服务条款怎么划这条线?⽬前的规定是:禁⽌⽤输出“训练模型”,但没有禁⽌你把输出存进知识库做检索。两种做法的实际效果可以⾮常接近,但在合同层⾯⼀个违规、⼀个不违规。
这恰恰暴露了当前规则体系的脆弱——技术⼿段可以达到⼏乎相同的⽬的,但法律和条款只能按⾏为⽅式划线,没办法按效果划线。
这也意味着,当我们讨论 Anthropic 对中国 AI 公司的指控时,真正的问题可能⽐“谁偷了谁”要深刻得多。
还有⼀个没⼈问的问题
回过头看 Anthropic 的指控,有⼀个细节很容易被忽略:他们是怎么发现的?
Anthropic 说⾃⼰通过 IP 地址追踪、元数据分析、请求模式识别来锁定这些蒸馏⾏为,甚⾄将部分账户关联到了具体公司的具体研究⼈员。
这意味着什么?意味着 Anthropic⾄少在做这⼏件事:记录每次对话的来源 IP 和元数据,分析⽤户 Prompt 的内容和模式(否则怎么判断“这些 Prompt 是在做蒸馏⽽不是正常使⽤”?),对对话内容进⾏聚类和分类。
问题来了:要抓蒸馏,就得看⽤⼾在聊什么。⽽看⽤⼾在聊什么,本⾝就是对隐私的侵⼊。
想想你⾃⼰⽤AI 的场景。你可能跟它聊过商业策略、法律纠纷、健康问题、家庭⽭盾,甚⾄⼀些你不会告诉任何⼈的⼼事。你打下这些字的时候,有没有想过平台⽅不仅有能⼒、⽽且可能正在分析这些对话的内容、模式和意图?
Anthropic 能够精确识别出哪些对话在做什么、来⾃谁、⽬的是什么——这说明 AI 公司能看到的东西,远⽐⼤多数⽤户以为的要多得多。
AI 公司保护⾃家模型不被蒸馏,当然有正当理由。但“保护”需要的监控⼒度,和“⽤⼾隐私”之间的⽭盾, ⽬前⼏乎没有⼈公开讨论过。⽤⼾为此让渡了多少隐私?这些让渡是否被充分告知和授权了?当 AI 公司说“我们检测到了异常使⽤模式”时,这句话背后站着⼀整套针对所有⽤⼾⾏为的监控体系。
我们在讨论“谁偷了谁的模型”时,或许也该问⼀句:谁在看我们的对话?
追问到这⾥,我们已经从技术层⾯⾛到了伦理层⾯。但还有⼏个更尖锐的问题,涉及动机、⽴场和话语权。
为什么是现在?
指控的内容值得关注,指控的时机同样值得关注。
就在 Anthropic 发布这份报告的同⼀时期,多家媒体报道了另⼀件事:美国国防部⻓召⻅Anthropic CEO Dario Amodei 前往五⻆⼤楼,就 Claude 的军事⽤途进⾏谈判。据报道,⽓氛相当紧张——Anthropic 因拒绝完全解除 AI 安全护栏,正⾯临被定性为“供应链风险”、从⽽失去国防合同的压⼒。 与此同时,Elon Musk 的 xAI 和 Google 已经先后与五⻆⼤楼达成了协议。
在这个节骨眼上,公开指控中国 AI 公司对⾃⼰发动“⼯业级蒸馏攻击”,客观效果是什么?
它强化了“美国 AI 技术正在被系统性窃取”的叙事,也强化了 Anthropic 作为“被攻击的受害者”和“负责任的安全守卫者”的公众形象——⽽这恰恰是它在五⻆⼤楼谈判中最需要的筹码。
这不是说指控⼀定是策略性的,也不是说内容是捏造的。但⼀个⾏为同时服务于多个⽬的时,我们⾄少应该意识到这些⽬的的存在,⽽不是只看到其中⼀个。
同样的逻辑,也适⽤于下⼀个问题。
反⽅向有没有⼈在做?
⽬前的公开讨论⼏乎是单向的:中国公司蒸馏美国模型。但⼀个显⽽易⻅的反向问题很少被提及。
DeepSeek 的 R1 是开源模型,权重完全公开,任何⼈都可以下载和使⽤。美国公司有没有在研究、借鉴、甚⾄直接使⽤DeepSeek 的模型输出来改进⾃⼰的产品?
开源不等于放弃所有权利——很多开源协议明确禁⽌⽤输出来训练竞品模型。但在⽬前的舆论环境中,这个⽅向的审视⼏乎为零。
如果蒸馏在道德上是错的,那它在任何⽅向上都应该是错的。如果只在⼀个⽅向上被追究、被报道、被上升到国家安全⾼度,那我们⾯对的到底是⼀个知识产权问题,还是⼀个披着技术外⾐的地缘政治叙事?
这个问题没有现成答案。但不问这个问题,我们的理解就是不完整的。
安全叙事经得起推敲吗?
Anthropic 在这次指控中反复强调⼀个论点:蒸馏出来的模型会丢失安全护栏,可能被⽤于⽣物武器开发、⽹络攻击、⼤规模监控。这也是它呼吁加强出⼝管制的核⼼理由。
这个论点听起来很有说服⼒,但逻辑上有⼀个跳跃。
安全护栏不是通过蒸馏传递的。护栏是在模型基础能⼒训练完成之后,通过⼈类反馈强化学习(RLHF)等技术单独加上去的⼀层约束。蒸馏抽⾛的是模型的底层能⼒——推理、代码、⼯具调⽤——⽽不是护栏本⾝。
换句话说,任何⼀个拥有⾜够技术能⼒的团队,拿到⼀个开源模型之后都可以⾃⾏移除安全限制,根本不需要通过蒸馏 Claude 来获得“没有护栏的危险能⼒”。
把“蒸馏”和“安全风险”强⾏绑定,在技术逻辑上并不严密。但它在政策倡导上⾮常有效——因为它把⼀ 个商业竞争问题包装成了国家安全问题,⽽国家安全的标签⼀旦贴上,讨论的空间就会急剧收窄。
这不是说安全风险不存在。AI 能⼒的扩散确实带来真实的风险。但谁在定义“安全”、定义的标准是什么、定义的动机是否纯粹——这些问题同样需要被追问。
蒸馏 AI 违规,蒸馏⼈呢?
我们已经聊了机器对机器的蒸馏。但还有⼀种提取能⼒的⽅式,规模更⼤、更隐蔽,却⼏乎没⼈拿来跟蒸馏放在⼀起说。
以头部数据标注公司为代表,⾏业内普遍以 100 到 200 美元的时薪,在全球范围内招募各⾏业的资深专业⼈⼠参与 AI 训练任务。⼀个医⽣标注“这张 CT 影像的诊断应该是什么”,⼀个投⾏分析师标注“这份财报的关键风险点在哪”,⼀个律师标注“这段合同条款的法律风险是什么”。
但实际操作⽐“标注”两个字残酷得多。
很多时候,专家不只是答题的⼈,还得⾃⼰出题。平台要求专家⾃⾏构建业务场景,然后⾃问⾃答—— 相当于⼀个⼈同时扮演蒸馏流程⾥“设计 Prompt”和“⽣成输出”两个角⾊。更关键的是,如果专家构建的场景不够特别,或者跟平台已有的数据太像,就会被打回重来,要求想更⼩众、更边缘的情境。⽽被打回的那些时间,不计⼊⼯时,不算钱。
想想这在⼲什么:平台⽩嫖了专家最难的那部分劳动——思考、构建、探索——只为最终被“认可”的输出买单。⽽那些被打回的场景,平台真的删掉了吗?还是也悄悄进了数据库,只是没有付钱?
⽽且平台为什么拼命逼专家往⼩众场景⾛?因为通⽤场景互联⽹上到处都是,不需要花钱找⼈。平台真正饥渴的是只存在于资深从业者脑⼦⾥的边界知识——罕见病例怎么判断、极端市场条件下怎么对冲、冷⻔法律条款怎么适⽤。这些知识的稀缺性,恰恰是这些专家和他们所在机构最核⼼的竞争壁垒。
⼀⼩时⼀两百美元买⾛的不是劳动时间,是⼏⼗年经验⾥最稀缺的那⼀层。⽽且被打回的那些⼩时,连⼀两百美元都省了。
流程拆开看:让⾏业专家⾃⼰构建场景、⾃⼰回答、不断被逼向更稀缺的知识边界——这和机器蒸馏的流程如出⼀辙,只是被蒸馏的对象从 AI 模型换成了⼈。
⽽且这些专家通常签过竞业协议和保密协议,他们在标注任务中输出的专业判断,严格来说很可能已经违反了与雇主的合同义务——只是没有⼈追究,甚⾄没有⼈意识到。
Anthropic 指控 MiniMax 蒸馏了 1,300 万次对话。这些数据标注公司在全球有多少标注员,累计产出了多少条训练数据?这个数字恐怕⽐1,300 万⼤⼏个数量级。
如果从别⼈的 AI 模型⾥提取能⼒叫蒸馏,那从别⼈的员⼯脑⼦⾥提取能⼒,该叫什么?
这个问题之所以没有被讨论,可能恰恰因为它牵扯到的不是⼏家中国公司,⽽是整个 AI 产业的训练数据供应链——包括指控别⼈蒸馏的那些公司⾃⼰。
AI⾏业最⼤的未解命题
这整件事撕开了 AI⾏业⼀个根本性的问题:在 AI 的价值链条上,知识产权的边界到底画在哪?
作者写了⼀本书→ 被抓取⽤于训练→ 模型学会了写作→ 模型输出了新⽂本→ 这个输出⼜被另 ⼀个模型蒸馏⾛了。这条链条上,从哪个环节开始算“偷”?
美国版权局已经明确:AI⽣成的内容不享有版权保护,因为版权要求⼈类作者⾝份。那么 Anthropic 指控别⼈“偷”了它的模型输出,法律基础到底有多牢固?
蒸馏技术本⾝是公开的、通⽤的机器学习⽅法。禁⽌别⼈对你的模型做蒸馏,和禁⽌别⼈对你的产品做逆向⼯程,边界在哪?
为了抓蒸馏,AI 公司得把⽤⼾⾏为看多深?⽤⼾知道⾃⼰被看了吗?同意了吗?
⼀项指控同时服务于商业利益、公众形象和政策博弈时,动机还能说得清吗?
蒸馏这件事,是不是只许州官放⽕不许百姓点灯?如果只在⼀个⽅向上被追究,它还算技术伦理问题吗?
当“国家安全”成为 AI 竞争的万能论据时,谁来审视这个论据本⾝?
从专业⼈⼠脑⼦⾥⼤规模提取⾏业经验⽤来训模型,和从 AI 模型⾥提取能⼒,本质上有什么区别?凭什么前者是正常⽣意,后者就是“盗窃”?
法院还没有答案,⽴法者还没有答案,⾏业⾃⼰也还没有答案。
但有⼀件事是确定的:这场博弈怎么收场,直接决定未来⼗年 AI⾏业的竞争格局和游戏规则。
谁拥有 AI 的“知识”?这个问题,⽐我们想象的要难回答得多。
本⽂基于 Anthropic 2026 年 2⽉23⽇公开声明及 Bloomberg、TechCrunch、VentureBeat 等多家媒体报道整理。⽂中涉及的指控均为 Anthropic 单⽅⾯陈述,截⾄发稿三家公司均未公开回应。




