
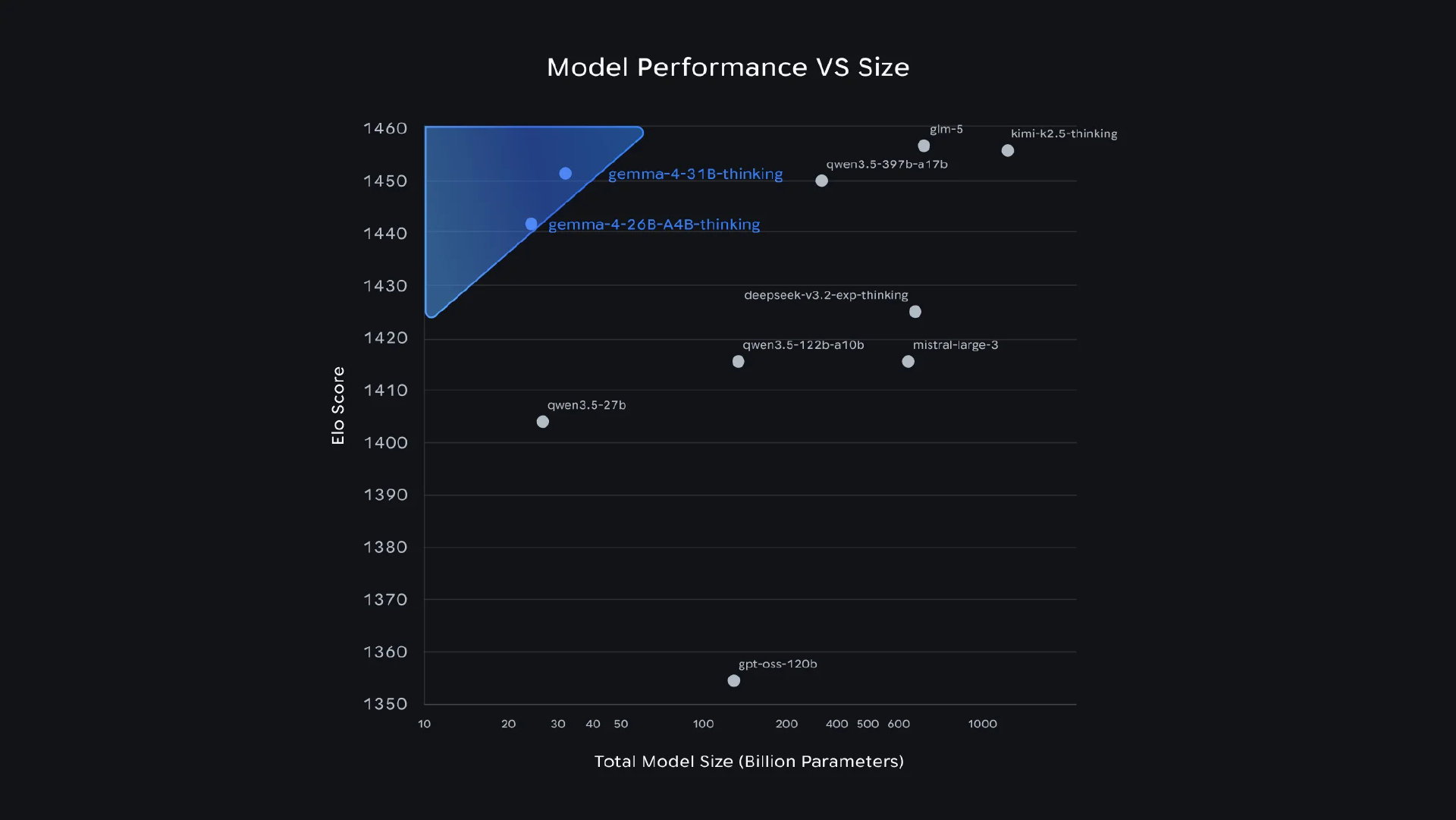
谷歌近期发布了 Gemma 4 系列开源权重模型,其中包含高效的 2B 和 4B 边缘端版本、一个 26B 混合专家(MoE)模型,以及一个 31B 稠密模型,所有模型均基于 Apache 2.0 许可开源。本次更新为全系列模型加入了原生视频与图像处理能力,小型模型还支持音频输入,上下文窗口最高可扩展至 256K 词元。基准测试结果显示,31B 稠密版本的性能已达到通常需要其三至五倍参数量级模型才能实现的水平。
该系列模型以“智能体”为核心定位,并在具体能力上得到充分体现。谷歌表示,31B 版本在 GPQA Diamond 上得分 84.3%,在 LiveCodeBench v6 上得分 80.0%。其中 GPQA Diamond 的成绩几乎是前代 Gemma 3 IT 27B 所达到的 42.4% 的两倍,体现出其在科学推理与代码生成能力上的显著提升。在工具使用方面,模型新增了对函数调用、结构化 JSON 输出与原生系统指令,这一组合旨在帮助开发者构建可与外部工具及 API 交互、并可靠执行多步骤工作流的自主智能体。
在架构方面,该系列模型同时采用稠密与稀疏两种设计。26B MoE 模型在推理时仅激活 38 亿参数,可实现高吞吐量的词元生成速度;31B 稠密版本则更适用于看重单词元成本稳定性、而非峰值参数数量的任务场景。面向内存与功耗受限的移动及物联网设备,边缘模型提供了 128K 上下文窗口;更大尺寸的模型则将上下文窗口扩展至 256K 词元,可在单次提示中处理体量较大的代码库或长文档。四款变体均支持可变分辨率的原生视频与图像处理,其中 E2B、E4B 边缘模型还新增了原生音频输入能力,支持语音识别与理解,整个系列的训练数据覆盖超过 140 种语言。
在基准测试方面,谷歌表示,31B 稠密模型的纯文本预估 LLMArena 得分为 1452,达到了通常需要参数规模大三至五倍的模型才能达到的性能水平。
来源:谷歌博客
开源模型社区的反应并未过多关注模型的原始分数,而是更多聚焦在实际可用性与新的许可协议上。Sam Witteveen 对谷歌采用了 Apache 2.0 许可表示赞赏:
这是真正意义上的 Apache 2.0 许可,意味着你可以拿到谷歌目前最优秀的开源模型,并可对其进行修改、微调、商业部署,自由使用,没有任何附加限制。
Nathan Lambert 认为 Gemma 4 的价值在于其无摩擦的集成体验,他指出:
Gemma 4 的成功将完全取决于易用性,基准测试 5% 到 10% 的波动根本无关紧要。它性能足够强、体量足够小、许可友好,再加上由美国公司研发,因此会被许多企业直接采用。
本次发布的分发渠道十分广泛:模型权重可在 Hugging Face、Kaggle 获取,并可通过 vLLM、llama.cpp、Ollama、MLX、LM Studio、Unsloth、SGLang 和 NVIDIA NIM 等平台使用,此外还提供了一个基于 NVIDIA Model Optimizer 的 NVFP4 量化版 31B 模型检查点。Kaggle 正在举办 Gemma 4 Good Challenge 挑战赛,邀请开发者使用这款新模型构建能产生积极社会价值的应用产品。
【声明:本文由 InfoQ 翻译,未经许可禁止转载。】




