
ZGCLAB 与北航提出 XRAG,涵盖 50+ 以上的测试指标检索增强生成 RAG 的全面评测与失败点优化!支持 4 类 Advanced RAG 模块(查询重构,先进检索,问答模型,后处理)的对比,支持 OpenAI 大模型 API,以及本地化模型 Qwen,LlaMA 等。XRAG 1.0 版本还提供了简单的 WebUI Demo!轻交互的数据上传与统一标准格式,集成了 RAG 失败点检测与优化方法。目前文章和代码已开源发布。
题目:《XRAG: eXamining the Core – Benchmarking Foundational Components in Advanced Retrieval-Augmented Generation》
paper: https://arxiv.org/abs/2412.15529
code: https://github.com/DocAILab/XRAG
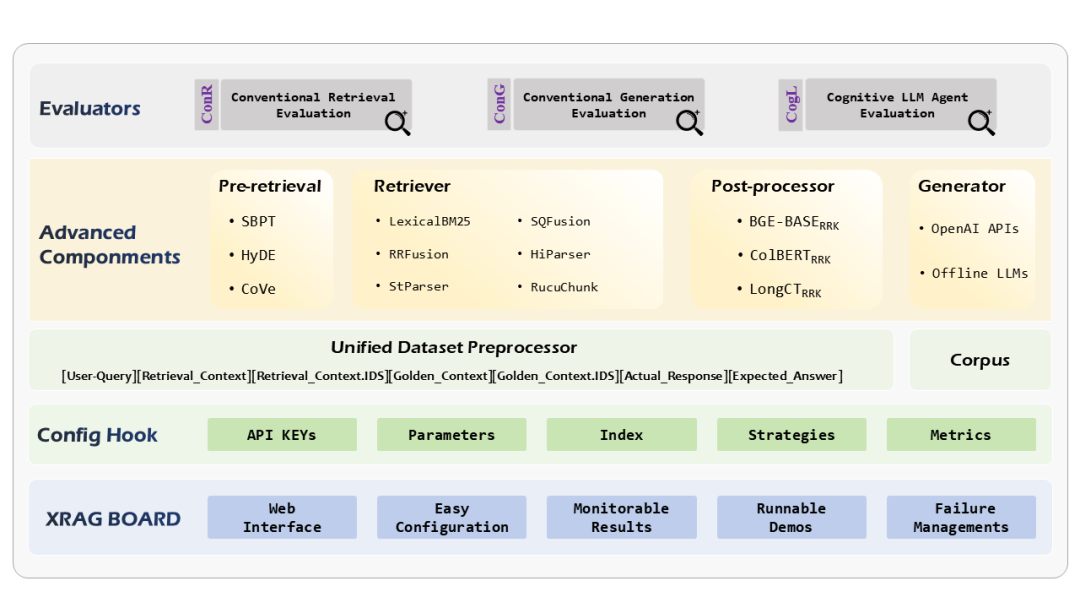
XRAG 概览 - 四大核心功能
模块化 RAG 过程:XRAG 允许执行对高级模块的实验分析,涵盖了查询重写、高级检索、后处理技术,以及来自 OpenAI、Meta 和 Google 的 LLM 生成器。
统一基准数据集:XRAG 标准化了三个流行的基准问答数据集,使检索和生成能力的评估可以统一进行,简化了不同 RAG 系统间的比较评估。
全面的测试方法:XRAG 引入了一个多维度的评估框架,包括传统检索评估、传统生成评估和基于 LLM 指令判别的评估,总计超过 50 个指标。
识别和优化 RAG 故障点:XRAG 开发了一套失败点诊断的实验方法,以识别和纠正特定 RAG 问题,并提出了针对性的改善策略与验证数据,以验证失败点解决方案的有效性。
较其他 Toolkits 优势
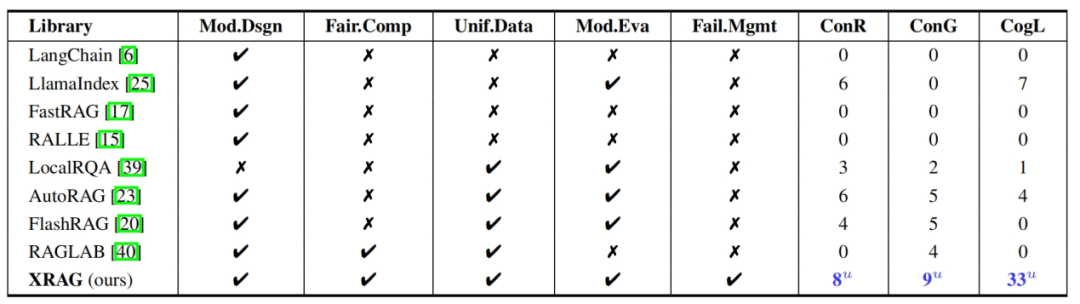
模块化设计(Mod. Dsgn):表示工具包的模块化程度 (索引、检索、问答、参数配置、实验测评等)。
公平的比较(Fair. Comp):通过校准关键参数(如种子、生成器、检索器和指令)来进行评估。
统一数据集(Unif. Data):确保检索和生成的数据集格式统一。
模块的评估(Mod. Eva):全面评估 RAG 基础模块、高级模块的性能差异性。
失败点管理(Fail. Mgmt):失败点检测与优化策略,提供测试方法与实验数据,便于开发者进行 RAG 失败点研究。
全面的指标 (ConR/ConG/CogL):支出 8 个令牌匹配的检索评估指标,9 个令牌匹配的生成评估指标,33 个基于 LLM 指令判别的检索与生成评估指标。
模块化 RAG 过程
我们将 RAG 过程划分为查询重写、高级检索、后处理、问答生成四个部分,以提升系统的灵活性与可扩展性,使得每个模块可以独立优化并针对特定需求进行定制。
查询重写包括回退提示[SBPT](https://openreview.net/forum?id=3bq3jsvcQ1),假设文档嵌入[HyDE](https://aclanthology.org/2023.acl-long.99/),验证链[CoVe](https://github.com/ritun16/chain-of-verification) 等。在高级检索部分,我们实现了模块化的检索类,支持向量检索、LexicalBM25,互惠重排融合检索器 RRFusion,自动合并层次检索器 HiParser,句子窗口检索器 StParser,递归块检索器 RecuChunk 等检索方法。集成的后处理模块负责对检索结果进行进一步加工,从多个角度提升检索质量。
统一的数据格式
我们发现当前很多[Q\&A 数据集](https://www.sciencedirect.com/science/article/pii/S2666651022000249) 的格式并未统一,这导致很难实施 RAG 数据基准,我们开发了一个统一的数据集结构,以便于对检索和生成模块进行性能测试,并采用了标准化的格式:

实验数据的选择上,我们为了突出多样性,大概选择了三个典型的数据集:HotpotQA,DropQA,NaturalQA。他们的特点是有区分的,HotpotQA 主要特点是其中的大部分问题需要在多个支持文档上找到答案并进行推理,这意味着一个查询可能需要结合多个相关文本中的信息才能得出答案。DropQA 数据集中的问题需要模型进行离散推理(Discrete Reasoning),例如加法、排序或计数等操作,要求模型对段落语义的逻辑理解,问题难度较大。NaturalQA 包含了真实用户向 Google 搜索提出的问题,这些问题反映了实际用户的需求。需要注意的是,三个数据集中的问题既有长答案也有短答案。长答案通常是包含所需信息的整个段落,而短答案则是简短的单词或词组。这使得在测试过程中可能不大适合 EM(Extract Macth)指标的测试,这一测试指标可以在大量简短答案比如 KG 问答的任务中被经常看到。
备注:除了在论文中呈现的三个典型的数据集,在我们的发布的 XRAG 1.0 版本的 Web UI 中也支持开发者上传自己的数据,仅需按照我们提示的 JSON 格式,XRAG 2.0 版本,将支持 vllm 或者 ollama 来部署本地的大模型(todo…)。
全面的测试指标
有了统一的数据格式后,这使得对 RAG 的测试过程便于执行大量指标,我们集成了检索测试的指标工具集:[Jury](https://github.com/obss/jury), [UpTrain](https://github.com/uptrain-ai/uptrain) 和 [DeepEval](https://github.com/confident-ai/deepeval),当然也包括了 LlamaIndex 中的指标。在论文中我们呈现了共计 50 个指标的测试性能。
这些指标可以总结为几个方面的优势:
一次性评估:XRAG 评估器允许开发者同时评估各种 RAG 的指标。这种能力简化了评估过程,使得无需连续评估即可进行全面的性能分析。
标准化评估:统一的数据格式简化了不同 RAG 组件在检索和生成方面的比较。
字符级与语义级性能×检索与生成性能:我们形式化把它称为四维可交叉的指标能力,包括字符级别的匹配测试,即 token 匹配的检索测试与生成测试),语义级别的理解测试,即基于判别指令的大模型语义理解评测。
实验结果
主实验
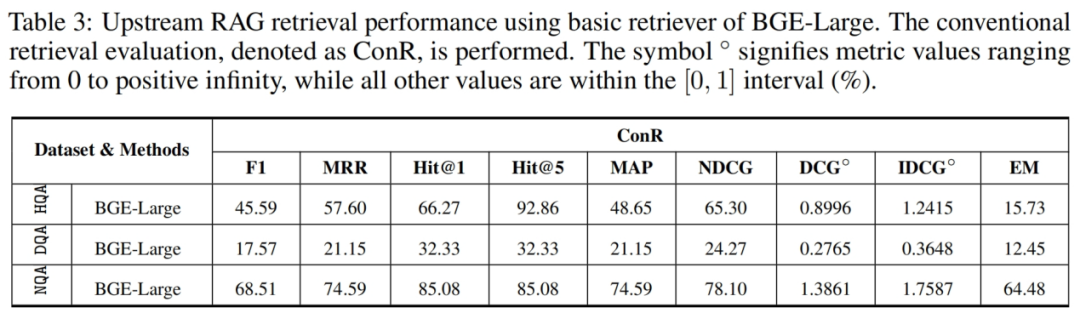
检索测试 – 基准检索器 [3 个数据集,令牌匹配的检索评估 ConR]
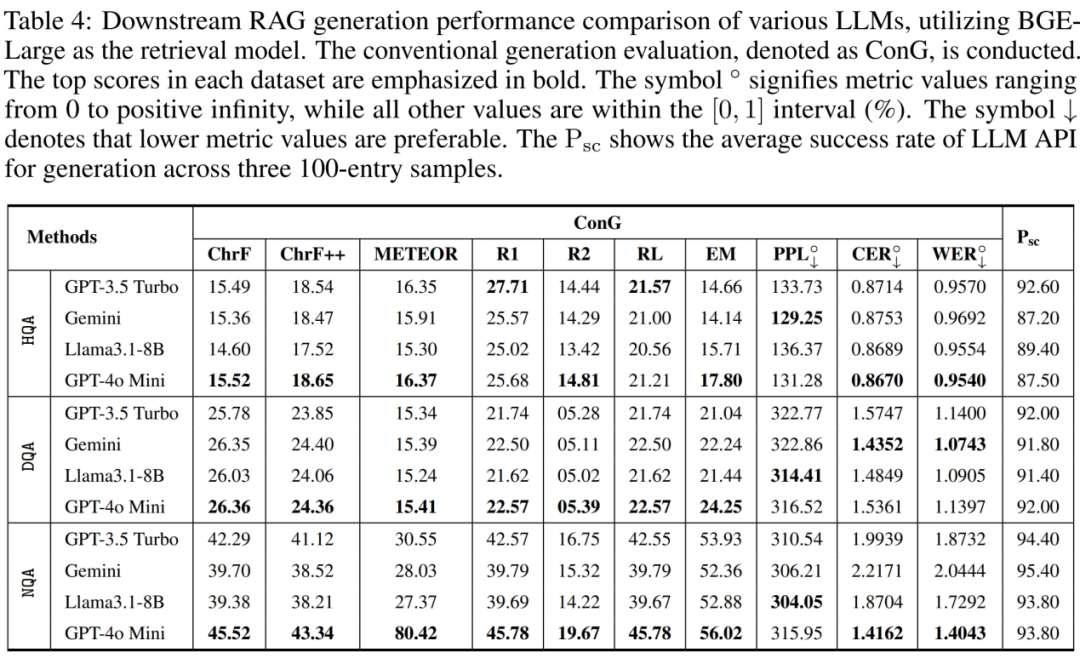
生成测试 – 基准大模型 [3 个数据集,令牌匹配的生成评估 ConG]
辅实验
检索测试 – 先进查询重构方法 [1 个数据集,令牌匹配的检索评估 ConR,大模型判别指令评估 CogL]
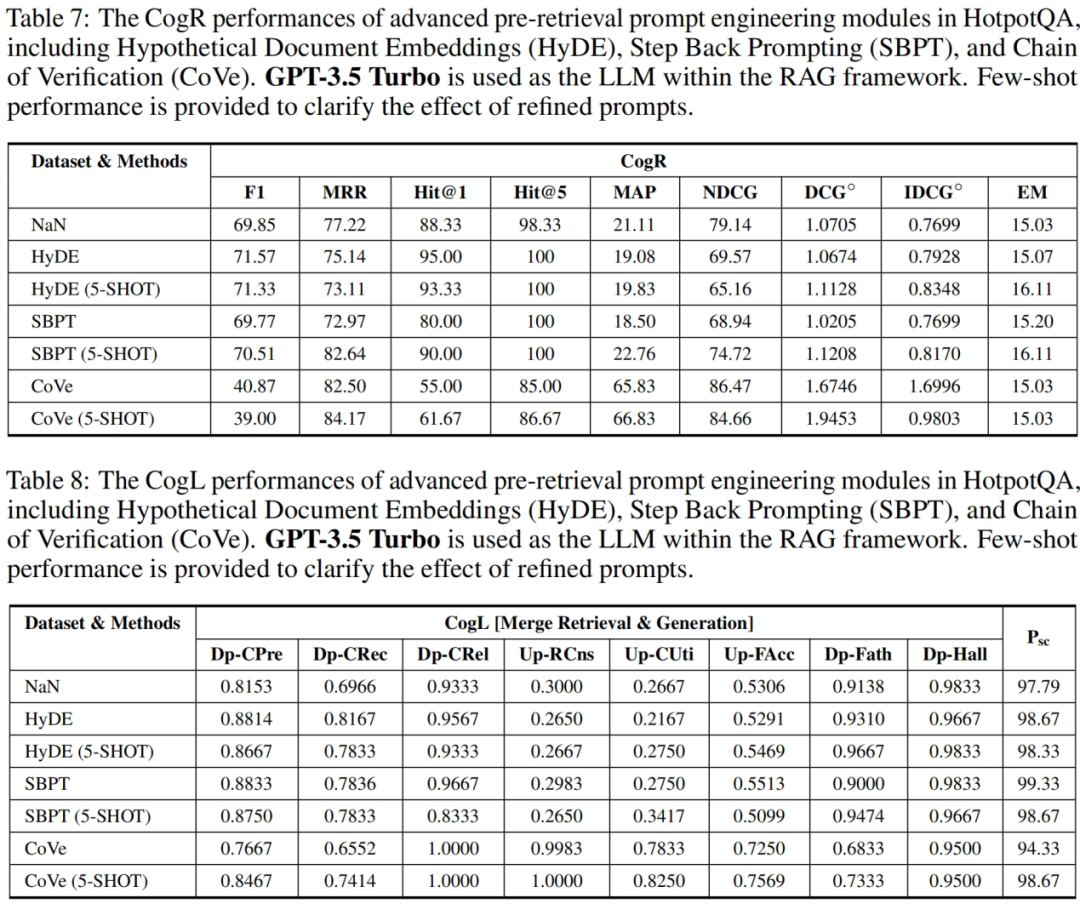
检索测试 – 先进检索器方法 [1 个数据集,令牌匹配的检索评估 ConR,大模型判别指令评估 CogL]

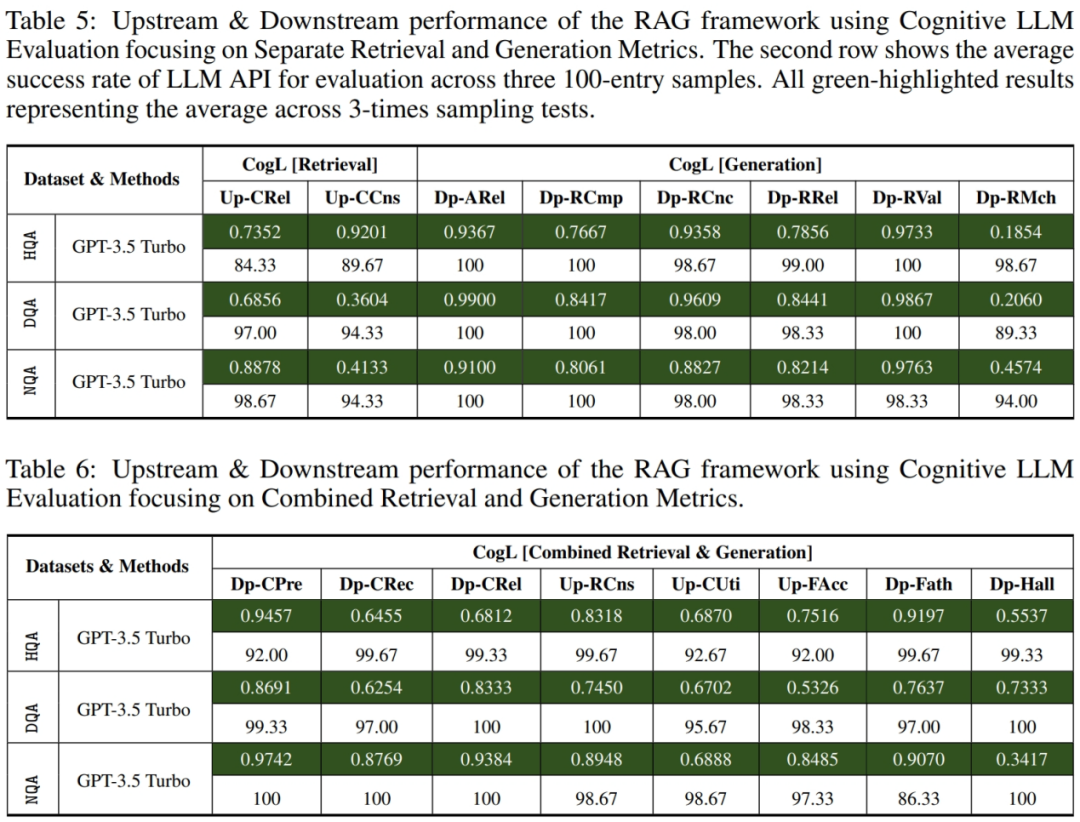
生成测试 [1 种大模型,大模型判别指令评估 GogL]
实验结论
检索方面,在三个数据集上的检索性能存在显著差异,最差的表现出现在 DropQA 数据集。由于 DropQA 需要高级的段落理解和离散推理能力,因此在检索上面临更大的挑战。NDCG 指标表明,基本的检索模型在 HotpotQA 和 NaturalQA 数据集上的相关性和查询结果排序准确性方面表现良好。忽略查询结果排序准确性,高于 0.8 的 Hit@5 得分表明检索到语义相关文档块的可能性相当大。Hit@1 指标衡量将正确答案作为排名 top-1 的结果返回能力,因此适合用于单一检索目标的任务(例如 NaturalQA 数据集中的单个片段的检索)。然而,对于需要多个同等优先级多个对象的检索(如 HotpotQA 数据集)来说,Hit@1 指标反应出来了其检索难度与测试指标缺陷。
问答方面,RAG 框架在 NaturalQA 数据集上表现出稳健的性能。
从 HotpotQA 和 DropQA 数据集的角度来看,在回答过程中优化 LLM 的查询理解和推理能力具有明确的潜力。然而,大模型测试方法在三个数据集的结果可以发现,即使是基础的 RAG 系统,在使用 LLM Agent(大模型判别指令评估) 做评估时,在检索和回答的成功率上表现出色,许多指标的得分均超过 0.9,语义理解测试的重要性,但是从对 LLM 的 API 调用成功率来看,总会存在请求失败的问题,这反应了大模型进行问答与评测的不足。
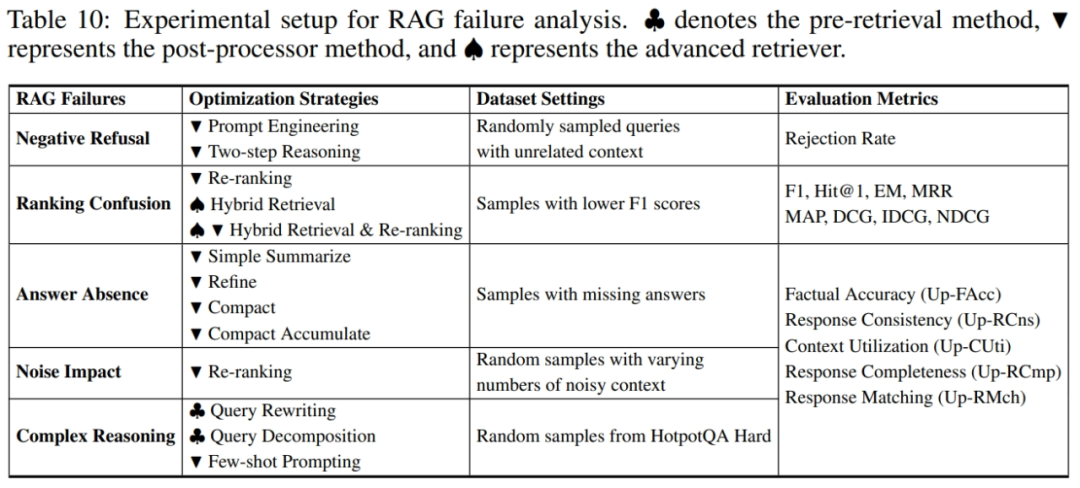
RAG 系统故障点检测与优化
在深入研究 RAG 系统的性能过程中,XRAG 不仅全面评估了其核心组件,还系统地识别了 RAG 流程中的多个潜在故障点,包括欺骗性响应、检索结果的不当排序、不完整的回答、对噪声的敏感以及处理复杂推理任务时的局限性等问题,并提出了针对性的常用优化方案。为深入探究并评估故障点及优化方案,我们通过人工分析标准 RAG 流程下系统回复表现,筛选并构造了相应数据集,以实验验证优化方案的有效性。
否定拒绝
面对信息不足的查询时,系统有时会倾向于给出错误或误导性回复而非承认不知。优化策略:
提示工程:以明确的 prompt 提示,让大模型在适当时候给出否定回答。
两步推理:基于大模型首先判断检索信息是否足够回答用户查询,再选择是否进行答案推理。
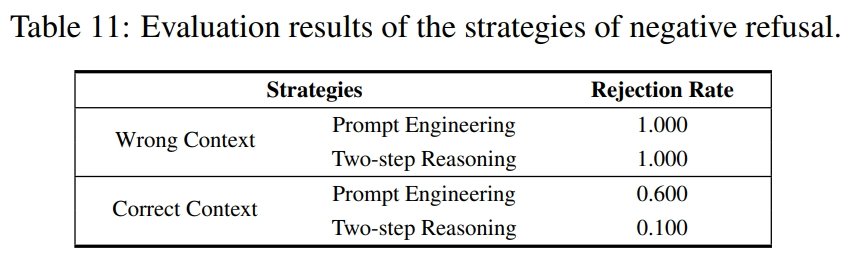
实验结果表明两种策略均可提高拒绝率,但提示工程在正确上下文时拒绝概率过高,影响可用性。同时表明了 prompt 的设计需要精心考虑和充分测试,否则将影响系统性能。
排名混淆
大模型对输入的检索序列顺序敏感,当相关文档片段未在序列前部时,易影响系统输出的准确性。优化策略:
重排序:采用重排序模型对检索结果做二次精排。
混合检索:整合 BM25 与向量检索,多视角获取相关文档。
混合检索及重排序:先进行混合检索,再应用重排序,综合二者优势。
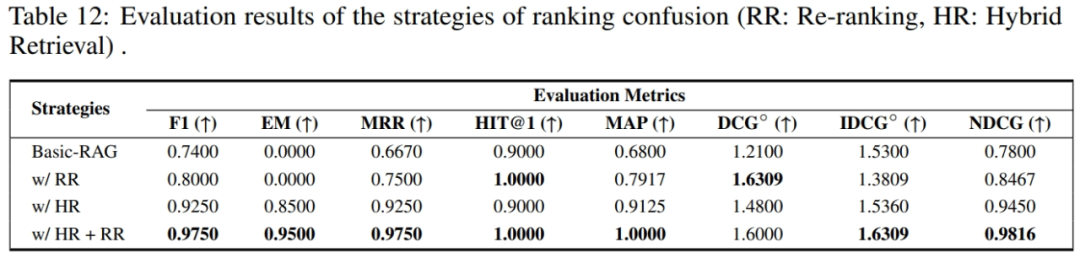
实验结果表明两种策略均可有效提升 RAG 性能,且二者结合后的性能优化将更为显著。
答案缺失
即使检索到了所有相关上下文,由于文档块输入给大模型的方式不同(受 LlamaIndex 的启发),仍可能导致大模型忽略相关细节,造成答案不完整。优化策略:
Simple Summarize:将检索到的文档块拼接为一个整体,一次性输入大模型。
Refine:每个文档块依次独立输入给大模型,逐次总结答案。
Compact:将文档块尽可能合并后,再应用 Refine 方法。
Compact Accumulate:将文档块尽可能合并后,每块独立与大模型回答,最后合并结果作为回复。
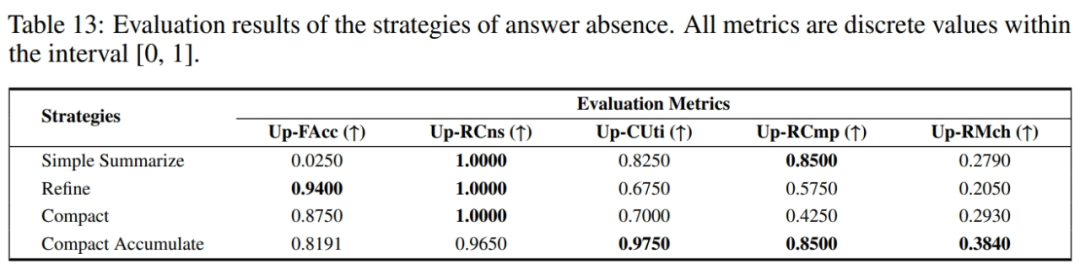
实验结果表明独立响应查询的方法效果较好(Compact Accumulate),而更为复杂的迭代响应生成方式效果较差(Refine,Compact),表明设计更为复杂的系统实现并不一定能取得更好的性能,甚至可能会适得其反,需结合场景实际设计测试。
噪声影响
检索结果往往包含数量不等的不相关文档块,将影响系统判别能力及回复性能。优化策略:
重排序:采用精排模型进行二次相似度判别,筛选排除噪声文档。
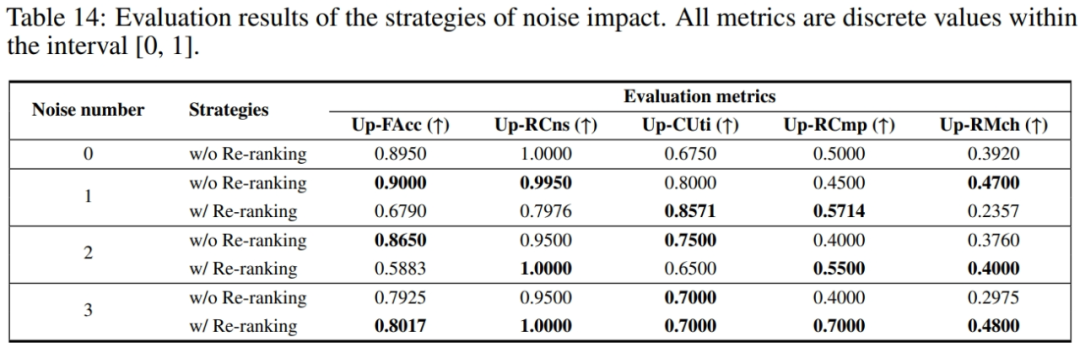
实验结果表明 RAG 系统输出准确性随噪声文档数量的增加而显著下降,当采用重排序策略后可有效缓解,且噪声越多时,优化效果越为明显。
复杂推理
面对多文档多步推理的复杂任务时,RAG 系统可能难以充分理解查询的全部隐含信息需求,导致推理失败。优化策略:
问题重写:基于大模型对查询进行改写,添加更多信息辅助检索模块获取相关文档。
问题分解:基于大模型将查询分解为简单子问题,简化搜索和推理过程。
少样本提示:在 prompt 中添加少量复杂推理示例,激发大模型潜在推理能力。
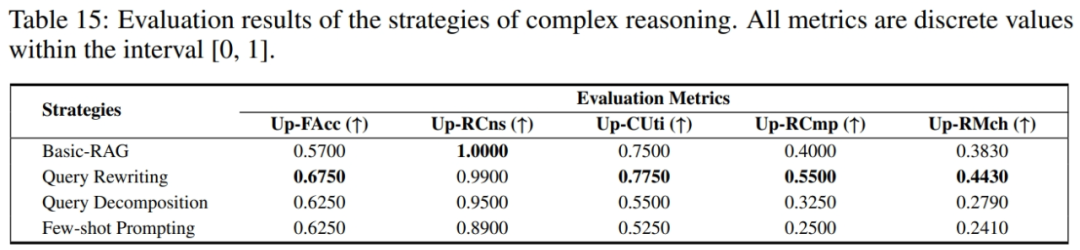
实验结果表明只有问题重写取得了积极的性能提升,而问题分解与少样本提示甚至进一步导致了性能的弱化,表明后者的方式仍具有潜在的风险,需在应用时进行充分的可行性测试和调整。
参考文献
致谢相关 RAG 的技术报告、综述文章与实验测试
A Comprehensive Survey of RetrievalAugmented Generation (RAG): Evolution, Current Landscape and Future Directions. CMU. [Arxiv 2024(https://arxiv.org/abs/2410.12837)
Retrieval-Augmented Generation for LargeLanguage Models: A Survey . 同济 \& 复旦. [Arxiv 2023] (https://arxiv.org/abs/2312.10997)
The Survey of Retrieval-Augmented Text Generation in Large Language Models. York University. [Arxiv 2024](https://arxiv.org/abs/2404.10981)
Seven Failure Points When Engineering a Retrieval Augmented Generation System. Deakin University. [CAIN 2024](https://dl.acm.org/doi/10.1145/3644815.3644945)
Benchmarking Large Language Models in Retrieval-Augmented Generation. 软件所. [AAAI 2024](https://ojs.aaai.org/index.php/AAAI/article/view/29728)
RaLLe: A Framework for Developing and Evaluating Retrieval-Augmented Large Language Models. Kioxia Corporation. [EMNLP (Demos) 2023](https://aclanthology.org/2023.emnlp-demo.4/)
FlashRAG: A Modular Toolkit for Effcient Retrieval-Augmented Generation Research. 高瓴 AI. [Arxiv 2024](https://arxiv.org/abs/2405.13576)
RAGLAB: A Modular and Research-Oriented Unified Framework forRetrieval-Augmented Generation. [EMNLP (Demos) 2024](https://arxiv.org/abs/2408.11381)




