
数据分析是一个不断探索数据背后的规律,得出业务洞察的过程,开始整个工作之前,分析师需要先将原始数据转换为面向分析的、有业务语义的数据,数据清洗和整理是提升整个分析过程效率和质量的关键环节,数据分析是建立在一致、准确、完整的数据基础之上。
很多调查显示,数据分析师通常会将 60%以上的时间花在数据清洗和各种数据整理上,真正用来探索数据,获取业务洞察的时间反而有限,工作效率亟待提高。
面对这些工作过程中的挑战,我们不禁反思:如何降低数据处理的门槛,提高数据分析效率,推广基于数据驱动的决策文化,建设数据驱动型组织?实践过程中,我们发现将数据准备产品化,业务化,可视化,自助式数据准备工具可以有效赋能业务,有效提高了数据的整体运转效率。本文基于有数的数据准备产品,介绍有数 BI 在产品上的实践。
业务场景描述
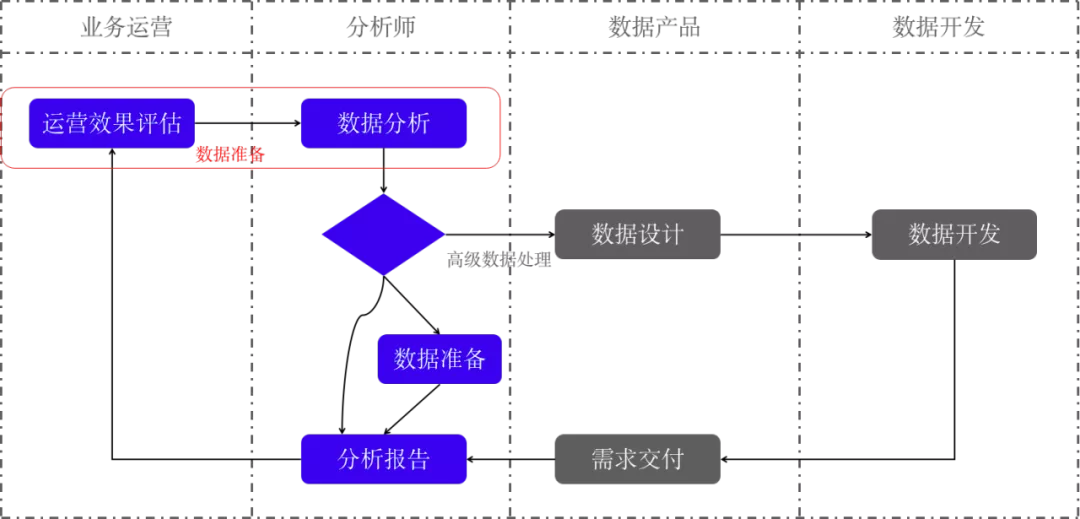
随着企业不断发展,业务对数据实效性和敏捷性要求越来越高,但是受到数据开发周期长、流程复杂的制约,很多业务决策仍然仅能依靠经验,成本高、效率低,如何降低分析和开发的门槛,提高效率,成为迫在眉睫的需求。(下图为常见数据工作流程图)

业务向分析师提出数据分析需求,比如效果评估、趋势预测、异常诊断等
分析师根据业务需求,整理分析思路,梳理数据指标,提供数据报告和业务策略,基于数据的完备性、可用性向数据产品提出数据需求
数据产品梳理数据指标,抽象业务流程,设计最终产品,并向数据开发提需求
数据开发根据产品需求,完成数仓建设以及实体表开发,最终交付分析师使用
分析师在数仓基础上向业务提供数据报告和决策建议,完成整个分析链路
复盘整个工作流程,数据分析师需要数据产品、数据开发的协作配合才能完成整个工作,中间需要反复沟通,确认需求,工作效率很容易遇到瓶颈。
回到问题的起点,如果大部分场景分析师可以独立完成整个过程,效率是否会提高很多?面向分析师的工作场景,一款体量轻,应用简单,操作便捷的工具是产品必然要求。这个工具可以赋能分析师独立完成大部分数据整理工作,缩短流程、提高效率。推而广之,甚至业务同学可以自己完成数据分析,得出有价值的业务结论。
数据准备介绍
从数据分析的整个流程上来看,数据准备既包含排除异常、保证一致性、缺失值处理等清洗工作,也包含组合、转置、透视、合并等数据整理工作,是一个不断迭代、改进、优化的过程。
数据准备的产出即可应用于各种数据分析工作,也能作为数据集应用于各种场景化数据产品。具体来说,数据准备将原始数据转化为准确、一致、清晰,并且有一定业务含义的数据,是数据和业务之间的桥梁和纽带。
介绍到这里,很多人可能有疑问“这不就是 ETL 工要做的事情吗?”,从某种角度来说确实是的,但是相对于 ETL 工具,数据准备有其独特的产品需求和用户群体。(ETL 是英文 Extract-Transform-Load 的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程)。
详细来说,ETL 与数据准备之间的对比:
用户群体:ETL 一般面向数据开发,而数据准备面向业务用户,例如数据分析师,产品经理,市场运营等。
应用场景:ETL 一般用来做数据归集和建模,面向长期,规范化数仓建模,数据准备一般用来做分析前数据预处理,很多场景是临时,短期,探索性场景为主。
产品形态:ETL 一般是以任务和代码的方式处理数据,用户需要有比较高的开发能力。数据准备一般以可视化方式做数据处理,产品会提供很多内置算子,用户仅需要了解基本的数据概念即可。
产品介绍
从源头和工具上来说,现有数据清洗和整理必须在数据开发平台完成,平台配置、代码开发等都要求用户有比较高的开发素养,但是对业务同学来说门槛太高,实用价值不大。
(典型的数据开发平台)
以终为始,面向业务用户,有数 BI 将数据开发过程产品化、工具化、可视化,用户仅需掌握基本的数据知识,不需数据开发辅助,几步拖拽即可实现复杂数据处理,门槛低、效率高。

数据准备:涵盖数据获取、整理、建模的整体数据处理流程
数据连接:数据开发在产品上经过简单配置即可获取数据
轻量 ETL:产品将常用转置逻辑包装成算子,用户拖拉拽即可实现数据整理
数据建模:用户将处理好的数据表关联合并,为分析做好准备
数据分析:无需转换平台,直接在现有平台即可实现数据分析
数据产品:用户可以将数据和可视化报表加工成数据产品
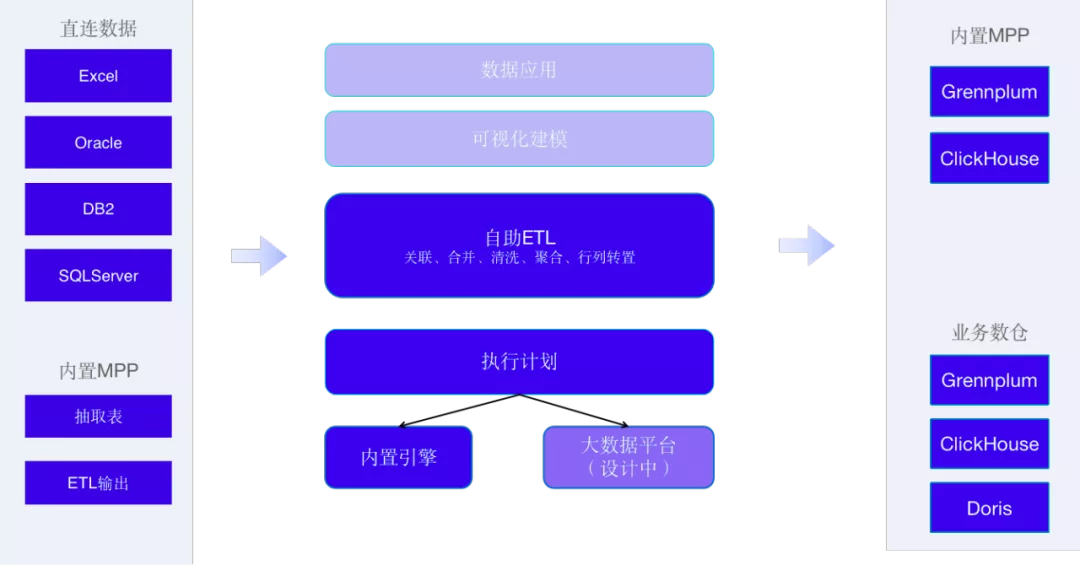
在设计上,有数 BI 基于 MPP 架构,数据计算节点支持水平扩展,随着数据量不断增长,产品仍然能够高效处理数据。同时,面向数据分析场景,现有数据准备跟 BI 无缝衔接,数据准备产出的表直接可以用来分析。不需要切换平台,即可实现数据的获取,处理,分析,整个平台的连贯性,一致性为用户的分析过程提供了极大的便利,从根本上降低了操作门槛,提高了效率,节约了整个企业的成本。
实际场景简介
假设业务需要分析不同等级会员的忠诚度,以便后续有的放矢,提高业务经营效率。用户手头有如下数据:2012-2015 年的订单明细数据;2016-2019 年的订单明细数据;会员维表。

基于当前数据,分析师面对以下几个难题:
用户仅关注会员粒度的销售数据,当前订单表粒度过细,数据量太大,不适合用来做数据分析;
订单表的客户 ID 是“姓名+订单 ID”组合字段,分析师需要先把这个字段拆分成两个字段;
分析过程中需要做关联查询,但很多数据引擎针对 Join 操作查询效率比较低。
基于数据准备,分析师可以直接在产品上完成整个数据整理过程,然后直接基于清洗的数据的建模分析,制作报告。
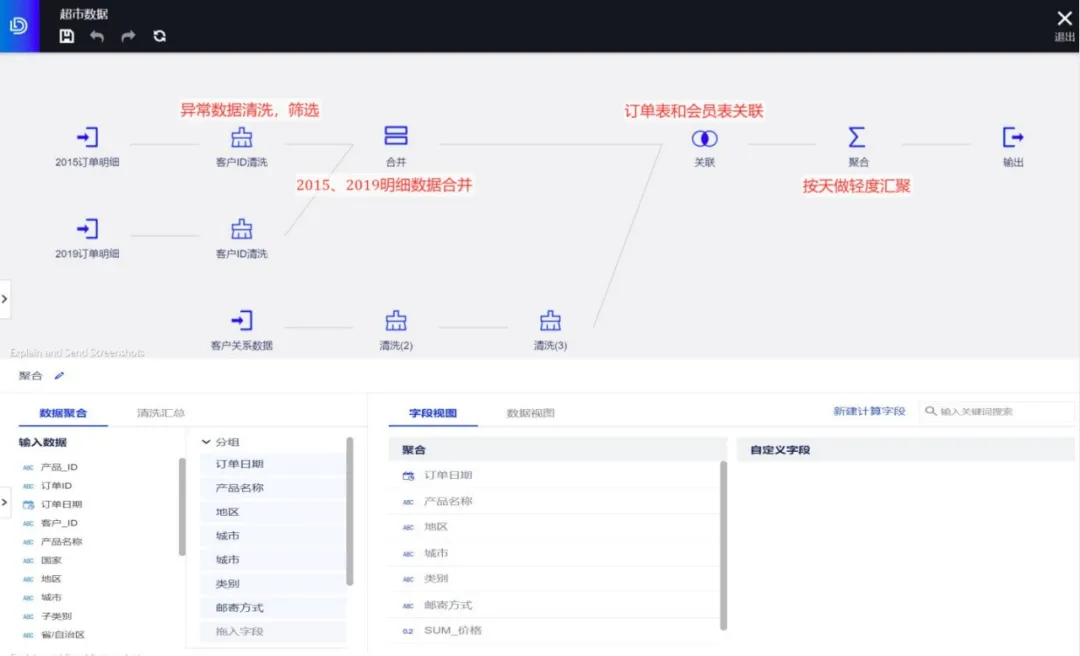
将两个表做清洗操作,去掉异常值,将姓名拆分成两列;
将 2015 年、2019 年的明细数据合并成同一份数据;
基于用户 ID 跟用户维表做关联操作,形成一个明细粒度的大宽表;
将日期、会员信息、销售信息做聚合操作,后续分析可以基于当前数据直接分析
基于当前表建立模型,制作报表,展示数据。
面向未来建设数据准备
为了数据建设的全局性、一致性、可维护性,保证数仓体系的整体产出质量,频繁使用、相对确定的需求应该由数据团队负责开发、运维。相对来说,临时的、高度不确定的探索性分析可以根据需要灵活处理,分析师在工作过程中可以将根据业务需求和上下文将原始数据加工成需要的数据。
经过实践证明,探索性需求由分析师完成,然后将需求明确、应用范围较广的需求向数据产品提出需求,整体工作流程更加顺畅,协作更佳便捷,有事半功倍的效果。
基于可视化、产品化的数据准备流程可以缩短整个分析流程的时间,推广数据驱动的企业文化,但是实际运行工作中,我们仍然面对很多挑战,突出表现为统一运维监控,产品适用性,架构可扩展性等方面,这些挑战的有效应对可以进一步提升产品能力,扩展应用场景,提高整个企业的运营效率。
统一运维、监控
基于有数 BI 的数据准备,探索性数据分析工作不需要由开发参与,分析师可以独立完成,省去了中间反复确认需求,不断修改设计过程,可以显著节省工作时间,提高业务满意率。但是在实际运行中,我们发现由分析师创建的表已经远多于开发创建的表,这部分表很多是临时创建,难以判断价值,体量又大,运维起来非常痛苦。同时,缺乏专业的数据开发支持,很多表的设计并不合理,执行效率较低,浪费资源。
数据分析的灵活性、开放性
为了降低产品的使用成本,扩展用户群体,数据准备将常用算法包装为算子,降低了用户用户整理数据的成本,但是这种设计降低了数据开发的灵活性,某种程度上无法达到效率最优。
不同平台的搭配应用
基于效率和质量考虑,部分大数据量,高复杂度的计算不适宜用可视化产品实现,数据准备需要搭配大数据平台使用,但是不同平台的联合应用建设带来了运维上的难题。




