
项目地址:
自 2014 年开源以来,Kubernetes 已然成为编排调度系统的事实标准,为开发者提供了极大的便利。随着越来越多企业拥抱云原生,全球云基础设施规模仍在加速增长,Kubernetes 社区版本单集群 5000 节点的规模已经无法满足企业级大规模应用场景,同时,更多公司选择使用多云架构满足降本增效、异地容灾、环境隔离等需求,多集群管理的必要性日渐显著。
背景
伴随业务的飞速发展,字节跳动内部 Kubernetes 集群的数量也不断壮大,集群数量超过 500,应用的副本数从 0 到 20000 不等,其中最大的某个应用体量超过 100W core。
早期出于隔离和安全的考虑,字节各个业务线独占集群,这些独占的集群带来造成资源孤岛,最终影响资源的弹性效率。这首先体现在各个业务线需要维护独立的 buffer;其次业务和集群深度绑定,业务感知大量的集群,并在集群之间为应用人肉分配资源,SRE 在运营资源上也需要深度感知业务和集群,最终导致资源在各个业务线之间的周转慢、自动化效率低以及部署率不够理想。因此我们需要引入联邦,解耦应用和集群的绑定关系,将各个业务线的资源并池,减少 buffer,提升资源的自动化效率。
随着多云、混合云愈发成为业内主流形态,且 Kubernetes 成为云原生的操作系统,并就各类基础设施进一步抽象和规范,为应用提供更加统一的标准接口。在此基础上,我们期望引入联邦作为分布式云场景下的云原生系统底座,面向应用提供统一的平台入口,提升应用跨集群分发的能力,做好应用跨集群的分发调度,管理好多个云云原生场景下的基础设施。
KubeFed V2 字节落地
面对多集群管理带来的挑战,基础架构团队在 2019 年以社区 KubeFed V2 为基础开启集群联邦的建设。KubeFed V2 区分主控集群和成员集群,用户在主控集群中创建“联邦对象”,KubeFed 的多个 Controller 根据联邦对象在成员集群中分发资源。联邦对象上有 Template(对象模板),Placement(目标集群),Overrides(集群差异化)三个字段声明对象的部署情况。例如,可以在主控集群中创建如下所示的 FederatedDeployment 进行 Deployment 的分发:
apiVersion: types.kubefed.k8s.io/v1beta1kind: FederatedDeploymentmetadata: name: test-deployment namespace: test-namespacespec: template: # 定义 Deployment 的所有內容,可理解成 Deployment 与 Pod template 之间的关联。 metadata: labels: app: nginx spec: ... placement: # 分发到指定的两个集群中 clusters: - name: cluster1 - name: cluster2 overrides: # 在cluster2中修改副本数为5 - clusterName: cluster2 clusterOverrides: - path: spec.replicas value: 5对于 Deployment 和 ReplicaSet,KubeFed 也允许通过 ReplicaSchedulingPreference(RSP)指定更高级的副本分发策略。用户可以在 RSP 上配置每个集群的权重、最小与最大副本数,RSP controller 自动计算出 placement 和 overrides 字段并更新 FederatedDeployment 或 FederatedReplicaSet。
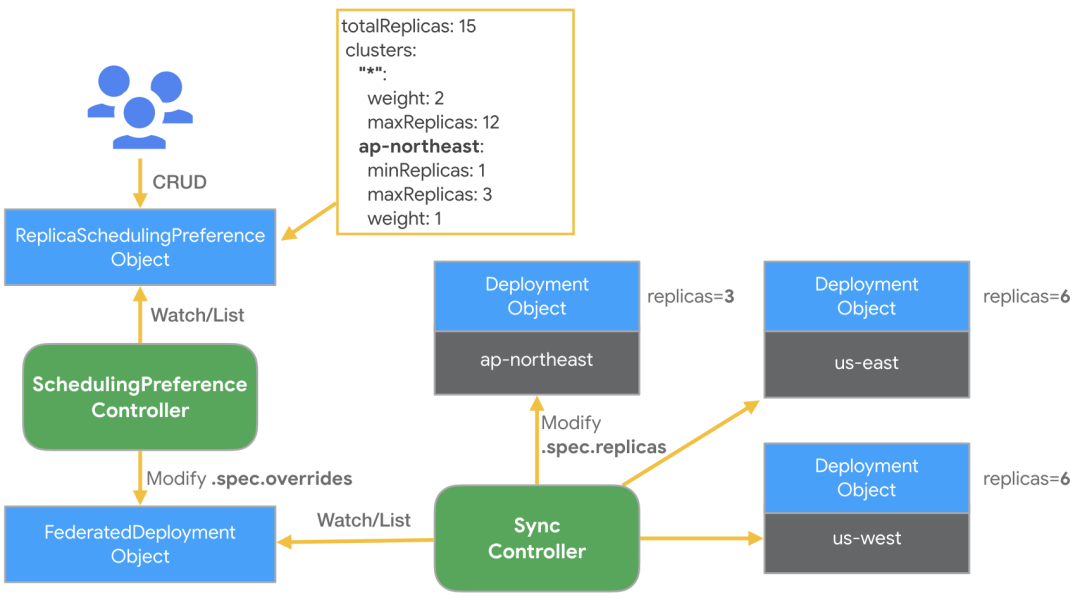
图片来源:https://www.kubernetes.org.cn/5702.html
但是,在具体落地时,我们发现 KubeFed 并不能满足生产环境的要求:
资源利用率低 - KubeFed 的副本调度策略 RSP 只能为每个成员集群设置静态权重,无法灵活应对集群资源的变化,导致不同成员集群的部署水位不均。
变更不够平滑 - 扩缩容时经常出现实例分布不均的现象,导致容灾能力下降。
调度语意局限 - 只对无状态类资源有较好的支持,对于有状态服务、作业等多样化的资源支持不足,调度扩展性差。
接入成本高 - 需要通过创建联邦对象进行分发,不兼容原生 API,用户和上层平台需要完全改变使用习惯。
随着字节跳动基础架构的演进,我们对于效率、规模、性能与成本提出了更高的要求;同时随着有状态服务、存储、离线作业、机器学习等业务场景进一步拥抱云原生,支持多样化场景的跨集群编排调度能力显得愈发重要。因此,我们在 2021 年底基于 KubeFed v2 研发了新一代集群联邦系统 KubeAdmiral。

KubeAdmiral 架构演进
KubeAdmiral 命名引申自 admiral(读音 [ˈædm(ə)rəl]),本意为舰队司令,加上 Kube(rnetes) 前缀,寓意该工具具有强大的 Kubernetes 多集群编排调度能力。
KubeAdmiral 支持 Kubernetes 原生 API,提供丰富的、可扩展的调度框架,并对调度算法、分发过程进行了细致的打磨。以下对一些显著特性进行详细介绍:
丰富的多集群调度能力
调度器是联邦系统的核心组件,它负责把资源分配到成员集群中,在副本调度场景也负责计算每个集群中应得的副本,其调度的逻辑直接影响联邦多集群容灾、资源效率、稳定性等重要功能。
KubeFed 提供了 RSP 调度器进行副本调度,但其定制性和扩展性非常有限,逻辑抽象性不足,要改变其行为必须通过修改代码完成,同时对于有状态服务、作业类资源等缺乏支持能力。
KubeAdmiral 引入了更丰富的调度语义,支持通过标签、污点等更灵活的方式选择集群,提供有状态、作业类资源调度能力,同时引入依赖跟随调度等优化。调度的语意可以通过如下所示的 PropagationPolicy 对象配置:
apiVersion: core.kubeadmiral.io/v1alpha1kind: PropagationPolicymetadata: name: mypolicy namespace: defaultspec: # 提供多种集群选择方式,最终结果取交集 placement: # 手动指定集群与权重 - cluster: Cluster-01 preferences: weight: 40 - cluster: Cluster-02 preferences: weight: 30 - cluster: Cluster-03 preferences: weight: 40 clusterSelector: # 类似Pod.Spec.NodeSelector,通过label过滤集群 IPv6: "true" clusterAffinity: # 类似Pod.Spec.NodeAffinity,通过label过滤集群,语法比clusterSelector更加灵活 - matchExpressions: - key: region operator: In values: - beijing tolerations: # 通过污点过滤集群 - key: "key1" operator: "Equal" value: "value1" effect: "NoSchedule" schedulingMode: Divide # 是否为副本数调度 stickyCluster: false # 仅在首次调度,适合有状态服务或作业类服务 maxClusters: 1 # 最多可分发到多少个子集群,适合有状态服务或作业类服务 disableFollowerScheduling: false # 是否开启依赖调度同时,对于调度到不同集群中的资源,支持使用 OverridePolicy 基于集群名或标签进行差异化:
apiVersion: core.kubeadmiral.io/v1alpha1kind: OverridePolicymetadata: name: example namespace: defaultspec: # 最终匹配的集群是所有rule匹配集群的交集 overrideRules: - targetClusters: # 通过名称匹配集群 clusters: - member1 - member2 # 通过标签selector匹配集群 clusterSelector: region: beijing az: zone1 # 通过基于标签的affinity匹配集群 clusterAffinity: - matchExpressions: - key: region operator: In values: - beijing - key: provider operator: In values: - volcengine # 在匹配的集群中,使用jsonpatch语法修改第一个容器的镜像 overriders: jsonpatch: - path: "/spec/template/spec/containers/0/image" operator: replace value: "nginx:test"调度能力可拓展
KubeAdmiral 参考 kube-scheduler 的设计,提供了可拓展的调度框架,将调度逻辑抽象成 Filter, Score, Select 和 Replica 四个步骤,并由多个相对独立的插件各自实现其在每个步骤的逻辑。上图所示的 PropagaionPolicy 中几乎每个字段都由一个独立的内置调度插件负责实现,各插件之间互不干扰,由调度器调用需要的插件进行全局的编排。
此外,KubeAdmiral 调度器也支持通过 http 协议与外部插件交互,用户可以自行编写并部署定制化的调度逻辑,满足接入公司内部系统进行调度等需求。内置的插件实现较为通用的能力,与外部插件相辅相成,用户可以以最小成本、不需要改动联邦控制面的方式实现调度逻辑的拓展,并依赖 KubeAdmiral 强大的多集群分发能力将调度结果生效。

应用调度失败自动迁移
对于副本调度的资源,KubeAdmiral 会计算出每个成员集群应得几个副本,并将副本数字段覆盖后下发到各成员集群,这一过程称为联邦调度;资源下发后,各成员集群的 kube-scheduler 又会把资源对应的 pod 分配给相应的 node,这一过程成为单集群调度。
资源下发后,有时会出现因为节点下线、资源不足、节点亲和性无法满足等等情况造成单集群调度失败的情况,如果不做处理,业务可用实例会低于预期。KubeAdmiral 提供调度失败自动迁移的功能,开启后可以识别成员集群中不可调度的副本并迁移到可容纳多余副本的集群,实现多集群资源周转。
如 A、B、C 三集群相等权重分发 6 个副本,初次联邦调度后每个集群分到 2 个副本。如果 C 集群中的 2 个副本在单集群调度失败,则 KubeAdmiral 会自动将其迁移到 A 和 B 中。
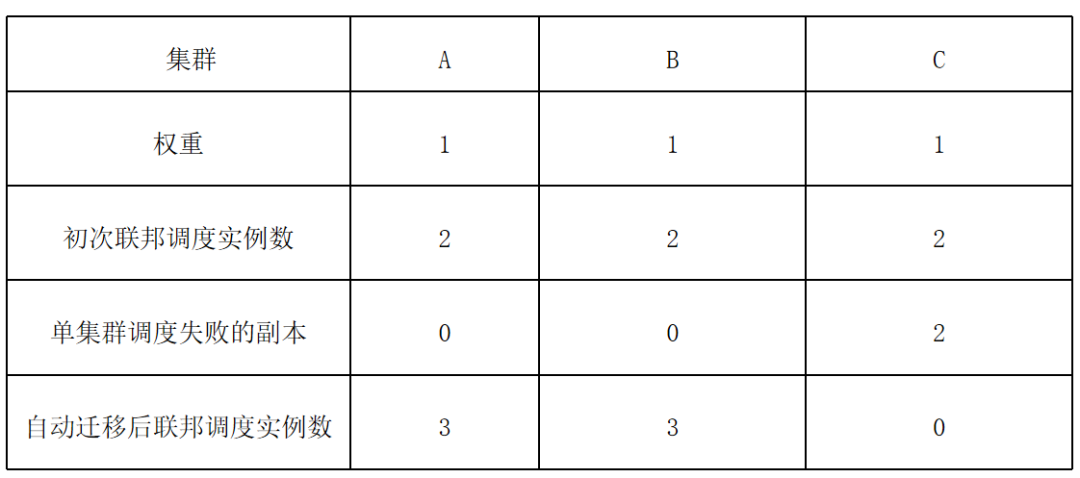
根据集群水位动态调度资源
在多集群环境中,各集群的资源水位因机器上下线而动态变化,仅依靠 KubeFed RSP 提供的静态权重调度副本容易造成集群水位不均的情况,部署率过高的集群在服务升级过程中容易出现 pod 长时间 pending,而部署率过低的集群资源无法完全利用。对此,KubeAdmiral 引入了基于集群水位的动态权重调度,通过收集每个集群的资源总量与使用量计算出可用量,并将可用资源量作为副本调度的权重,最终达到各个 member 集群负载均衡,且所有 member 集群的部署率都维持在 95% 以上。
副本分配算法改进
KubeFed 的副本分配算法在扩缩容时经常导致实例数偏离预期,例如:30 个实例分布在 A、B、C 三个成员集群,在 rsp.rebalance = false 情况下,用户想缩容到 15 个实例:
缩容前:
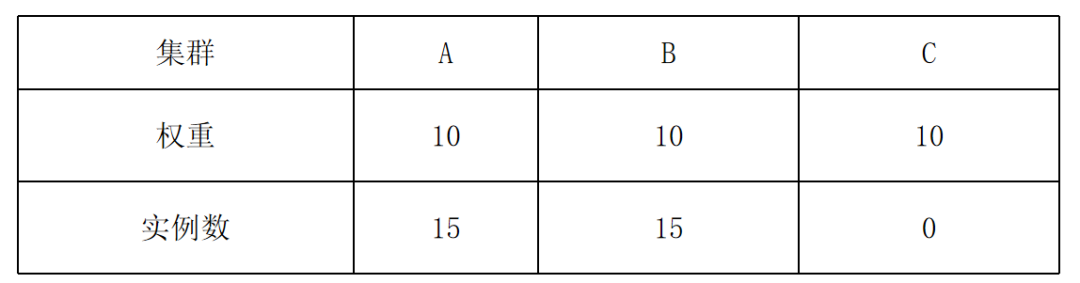
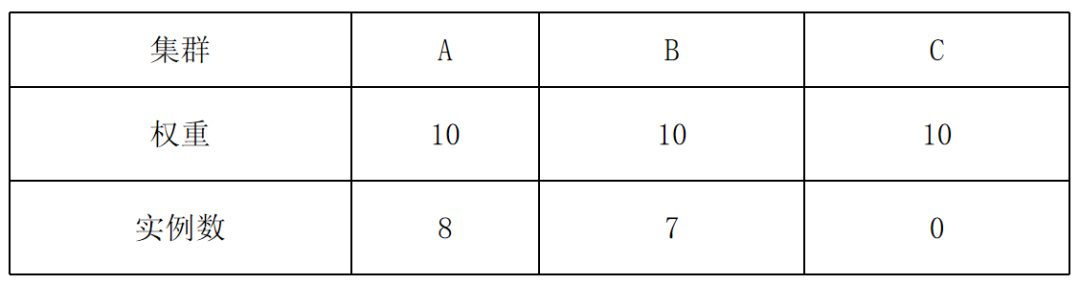
缩容后:
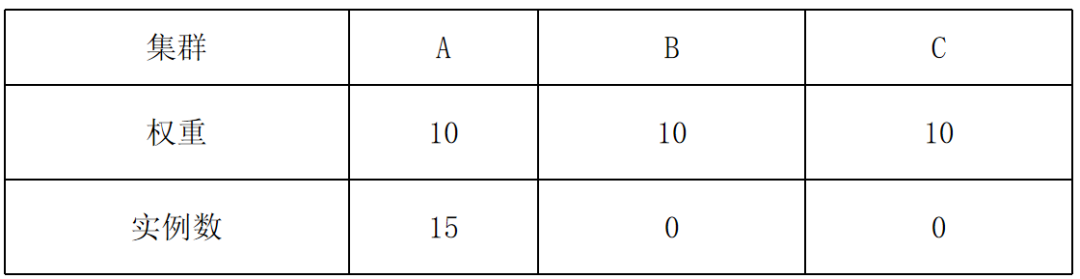
发生这种现象的原因是,KubeFed 的副本算法首先在集群中预分配当前存在的实例数,然后再将剩余的实例按照各个集群的权重分配,如果当前集群中存在的副本数过多,就会导致实例分布与权重严重偏离。
KubeAdmiral 对 KubeFed 的副本算法进行了优化,在保证扩缩容时不产生非预期迁移的情况下,使最终分发尽量趋近于权重分布。以从 30 个实例缩容到 15 个为例,简化的算法流程如下:
current distribution = [15, 15, 0], total replicas: 30
desired distribution = [5, 5, 5], total replicas: 15
distance = desired - current = [-10, -10, 5], total distance: 15
对于缩容场景,去掉正数项 distance = [-10, -10, 0]
以 distance 为权重,重新分配差值 15:[-7, -8, 0]
最终调度结果:[-7, -8, 0] + [15, 15, 0] -> [8, 7, 0]
支持原生资源
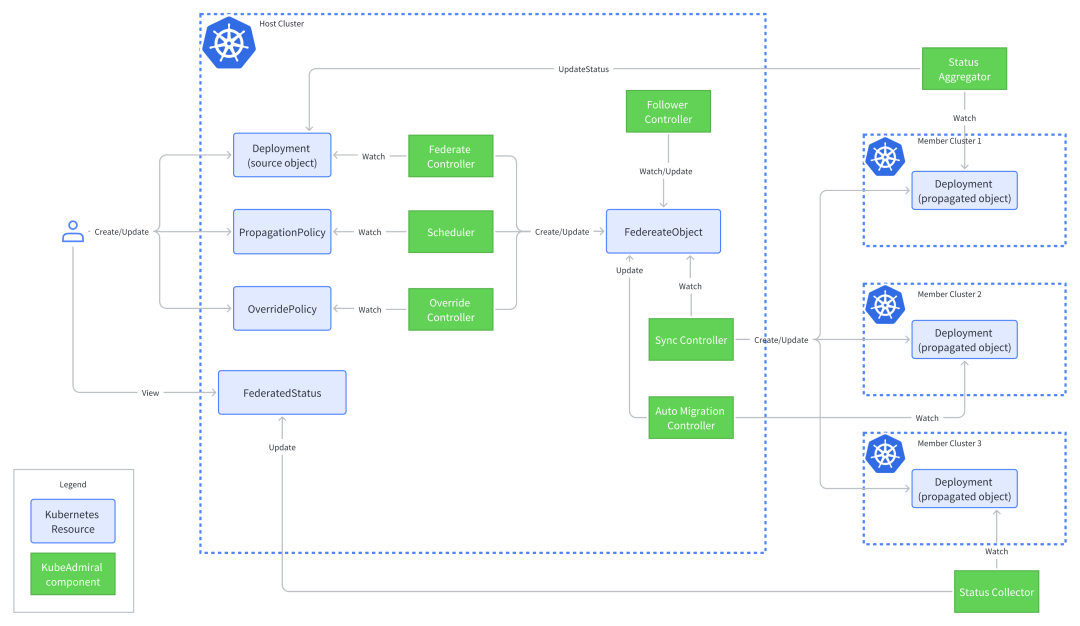
不同于 KubeFed 要求用户使用一套完全不兼容的新 API,KubeAdmiral 迎合 Kubernetes 单集群用户的使用习惯,提供了原生 Kubernetes API 的支持。用户创建原生资源(如 Deployment)后,由 Federate Controller 将其自动转化为联邦内部对象供其他 controller 使用,用户可以快速从单集群迁移到多集群架构,低门槛享受多集群带来的便利。
KubeAdmiral 并未止步于此。在单集群中,Kubernetes 的原生 controller 会更新一些资源的 status 反映其当前的状态,用户或上层系统经常依赖 status 查看部署情况、健康状态等信息。在多集群中,资源的 status 分散在多个集群中,用户要查看全局的状态,就必须逐个查看每个集群中资源的 status,造成视图碎片化、运维效率低下等问题。为了解决这个问题,无缝支持原生资源,KubeAdmiral 提供了 status 汇聚的能力,Status Aggregator 将多个成员集群中资源的 status 进行合并与融合,并写回原生资源,让用户无需感知多集群拓扑,就可以一目了然地观测到资源在整个联邦中的状态。
当下与未来
KubeAdmiral 在字节内部孵化多年,强力支撑字节集团业务 TCE 平台,管理 21 万 + 台机器、1000 万 +pod,经过了抖音、今日头条等大规模业务的打磨,沉淀了许多宝贵的实践经验。为了回馈社区,KubeAdmiral 已正式在 GitHub 开源。同时,火山引擎正在以 KubeAdmiral 为基础打造企业级多云多集群管理新模式——分布式云原生平台(DCP),敬请期待。
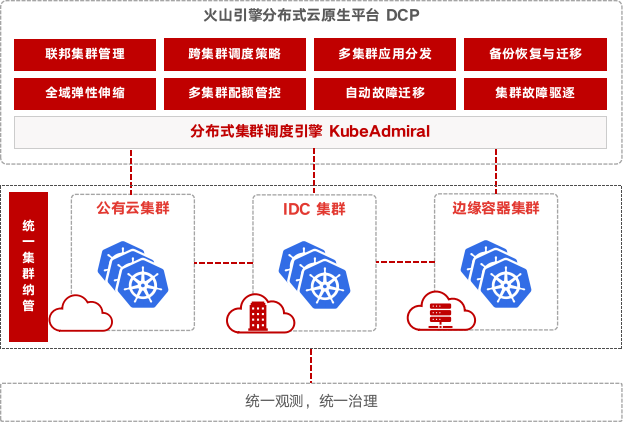
放眼未来,我们计划在以下几个方面持续演进:
继续完善有状态、作业类等资源的编排调度能力,沉淀出自动迁移、比价调度等高级能力,拥抱批量计算多云多集群时代的来临。
改善用户体验,提供开箱即用的解决方案,进一步减少用户的认知负担。
提高可观测性,对日志与监控指标进行优化,同时提高调度器的可解释性。
探索一键联邦化、多集群迁移等功能,完全释放多集群架构的潜力。
多集群编排调度本质上并不简单,一个通用、完善的多集群联邦系统必定需要各种场景的打磨,我们期待有更多朋友关注与加入 KubeAdmiral 社区,也欢迎大家试用 KubeAdmiral 并给我们提出各种建议!
GitHub 地址:https://github.com/kubewharf/kubeadmiral




