
OpenAI 发布新模型,专为实时编码而生
昨晚,OpenAI 正式发布了 GPT-5.3-Codex-Spark 的研究预览版本。这是一款从 GPT-5.3-Codex 主模型中“裁剪”而来的精简版本,同时也是 OpenAI 首个专门围绕实时编码(real-time coding)场景设计的模型。
从定位上看,Codex-Spark 并不是为了替代现有的 Codex,而是补齐其在“即时交互”场景中的短板:在过去,Codex 更擅长长时间运行的复杂任务,而 Codex-Spark 的目标则非常明确——把人与模型之间的交互延迟压缩到接近“无感”的程度。
这一发布同时也是 OpenAI 与 芯片初创企业 Cerebras 合作的重要阶段性成果。为了减少对英伟达芯片的依赖,上个月 OpenAI 签署了一项金额超过 100 亿美元的协议,使用 Cerebras 的硬件以提升其模型的响应速度,而 Codex-Spark 被视为这项合作落地的第一个技术里程碑。
为实时而生:Codex-Spark 的核心是“速度”
在官方定义中,Codex-Spark 是一个“专为实时使用 Codex 而设计的模型”,它支持进行针对性编辑、重塑逻辑或优化界面,并能立即查看结果。这一表述背后,隐含的是对交互方式的重新假设。
在传统的 AI 编码流程中,开发者往往需要等待模型完成一次较完整的推理和生成,再基于结果进行下一轮调整。这种模式在复杂任务中是必要的,但在日常开发中——例如小范围代码修改、逻辑重构、界面样式调整——高延迟本身就成为效率瓶颈。
Codex-Spark 针对的正是这一类高频、碎片化、对即时反馈极度敏感的使用场景。
据 OpenAI 介绍,Codex-Spark 在执行长时间运行的任务方面展现出卓越的优势,无需人工干预即可自主运行数小时、数天甚至数周。借助 Codex-Spark,Codex 现在既支持长时间运行的复杂任务,也支持即时完成工作。
Codex-Spark 在发布时拥有 128k 的上下文窗口,并且仅支持文本。在研究预览期间,Codex-Spark 将拥有独立的速率限制,其使用量不计入标准速率限制。但是,当需求量较高时,用户可能会遇到访问受限或临时排队的情况,因为需要平衡不同用户的可靠性。
OpenAI 还表示,Codex-Spark 针对交互式工作进行了优化,在这种工作环境中,延迟与智能同样重要。用户可以与模型实时协作,在模型运行过程中随时中断或重定向它,并快速迭代,获得近乎即时的响应。由于 Codex-Spark 注重速度,因此其默认工作方式非常轻量级:它只进行最少的、有针对性的编辑,并且除非用户主动要求,否则不会自动运行测试。
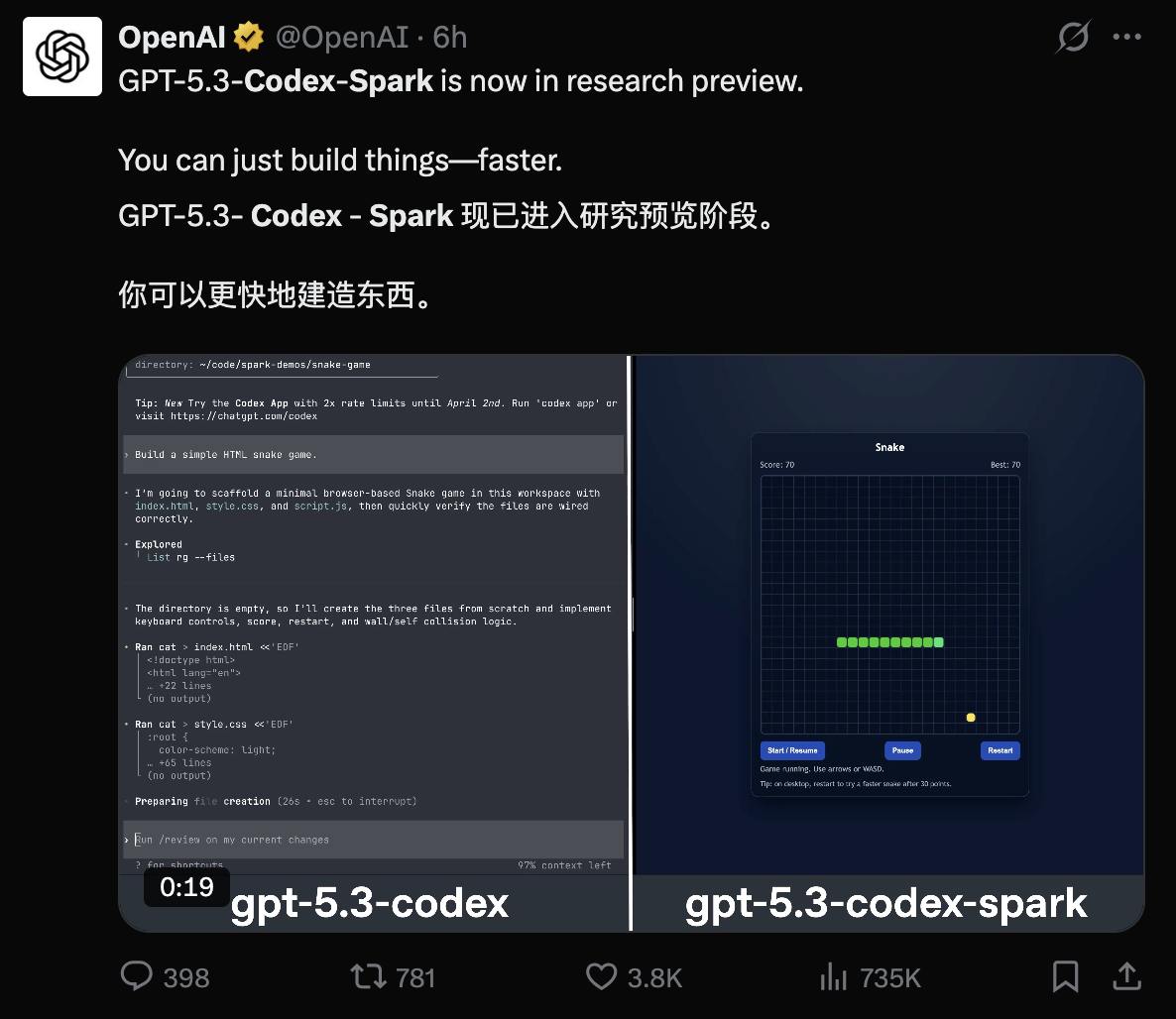
提示词:制作一款贪食蛇游戏
编码能力如何?
在评估层面,Codex-Spark 作为一个小型模型,仍然在多个软件工程基准测试中表现突出。
Codex-Spark 特意针对快速推理进行了优化。在 SWE-Bench Pro 和 Terminal-Bench 2.0 这两个评估智能体软件工程能力的基准测试中,GPT-5.3-Codex-Spark 表现出色,且完成任务所需时间远低于 GPT-5.3-Codex。
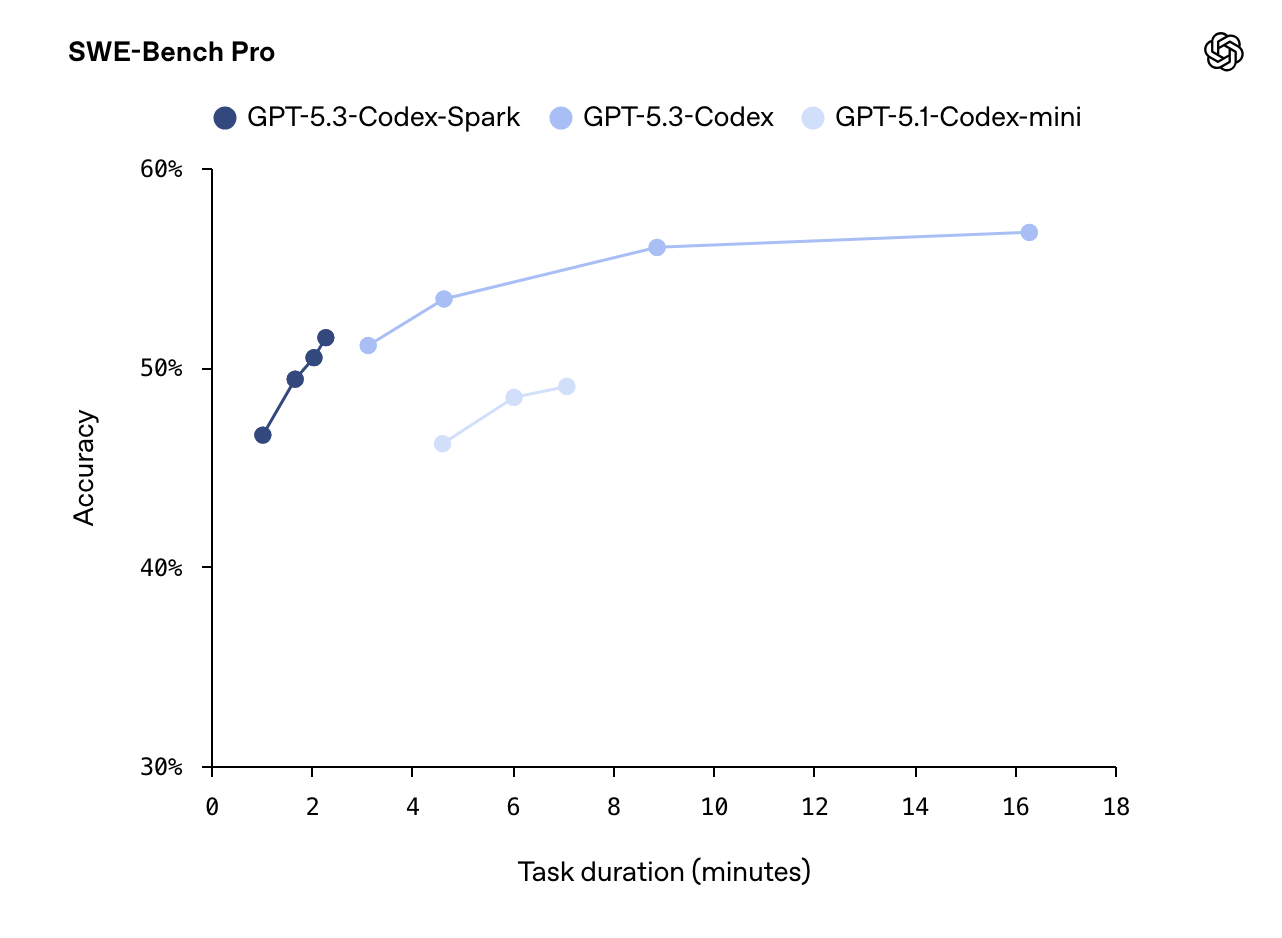
持续时间估计为以下各项之和:(1)输出生成时间(输出 token ÷ 采样速度),(2)预填充时间(预填充令牌÷预填充速度),(3)工具执行总时间,以及(4)网络总开销。
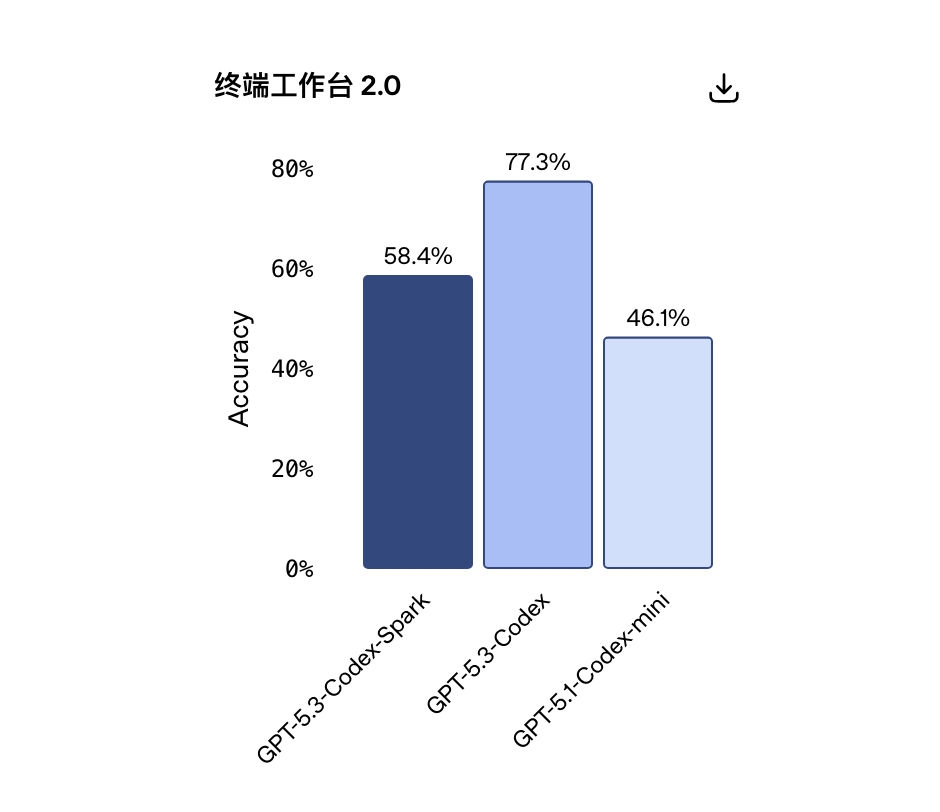
那么,这样的编程表现是如何实现的?在训练 Codex-Spark 的过程中,OpenAI 意识到模型速度只是实现实时协作的一部分——还需要降低整个请求-响应流程的延迟。所以研发团队在框架中实现了端到端的延迟优化,这将使所有模型受益。
在 Codex-Spark 的研发过程中,OpenAI 意识到一个关键问题:模型本身的速度只是实时体验的一部分。
真正影响用户感受的,是从客户端发出请求,到第一个可见 token 出现,再到持续生成的整个端到端路径。
因此,OpenAI 对 Codex 的底层架构进行了系统级优化,包括:简化客户端到服务器、以及服务器返回响应的流程、重写推理栈中的关键路径、改进会话初始化机制、引入持久化 WebSocket 连接以及对响应 API 进行针对性优化。
这些改动带来的量化结果包括:
客户端/服务器单次往返开销降低 80%
每个 token 的处理开销降低 30%
第一个 token 的出现时间缩短 50%
Codex-Spark 默认启用 WebSocket 路径,而这一通信方式也将在未来逐步成为所有模型的默认配置。
这印证了 Codex-Spark 的核心定位:不是通过更复杂的推理链取胜,而是通过更快的反馈循环提升整体效率。
开发者关注的不只是“更快”
在 OpenAI 发布面向实时编码场景的 Codex-Spark 研究预览版后,在 x 上迅速展开讨论。与官方强调的“超低延迟”和“即时协作体验”相比,社区关注的焦点明显更加集中在一个问题上:在速度大幅提升的同时,模型是否还能维持足够的推理深度与代码质量。
从目前的讨论来看,围绕 Codex-Spark 的反馈并不单一,而是呈现出几种具有代表性的声音。
有 x 用户表示:
“真正的问题不仅仅是速度。关键在于它能否在压力下保持质量。如果延迟降低而推理深度没有减少,这将改变日常工作流程。”

还有用户指责 OpenAI 过于关注编码性能,其他性能被忽视了。
“你们把所有注意力都放在代码和那些影响用户体验的广告上,但这并非绝大多数日常用户真正关心的。你们无视 #Keep4o (保留 4o 模型)的声音,就像我们无视你们那些垃圾般的新产品一样。即便你们装作视而不见,我们也不会停止。”
“速度更快”固然很好,但真正的问题是:它能否在速度的同时保持代码质量?
有用户指出,速度快但有缺陷的代码毫无用处。代码速度慢但正确才有用。期待看看 Spark 能否在这两方面都做到最好。

多位用户表达了类似的观点,认为只速度快有什么意义?它至少应该达到 GPT 5.3 编解码器的水平。“否则,你很快就会一无所获”。
谷歌更新 Gemini 3 Deep Think,能处理真实科研难题
OpenAI 发新模型的同时,谷歌也没闲着。
谷歌昨晚同步更新了旗下最具研究取向的推理模型——Gemini 3 Deep Think。这次更新并非一次常规能力迭代,而是一次明确面向现代科学研究、工程建模与复杂推理问题的系统性升级。
值得注意的是,去年 9 月加盟谷歌 DeepMind 的清华物理系知名研究者姚顺宇(Shunyu Yao),同样是 Deep Think 新模型的核心参与者之一。
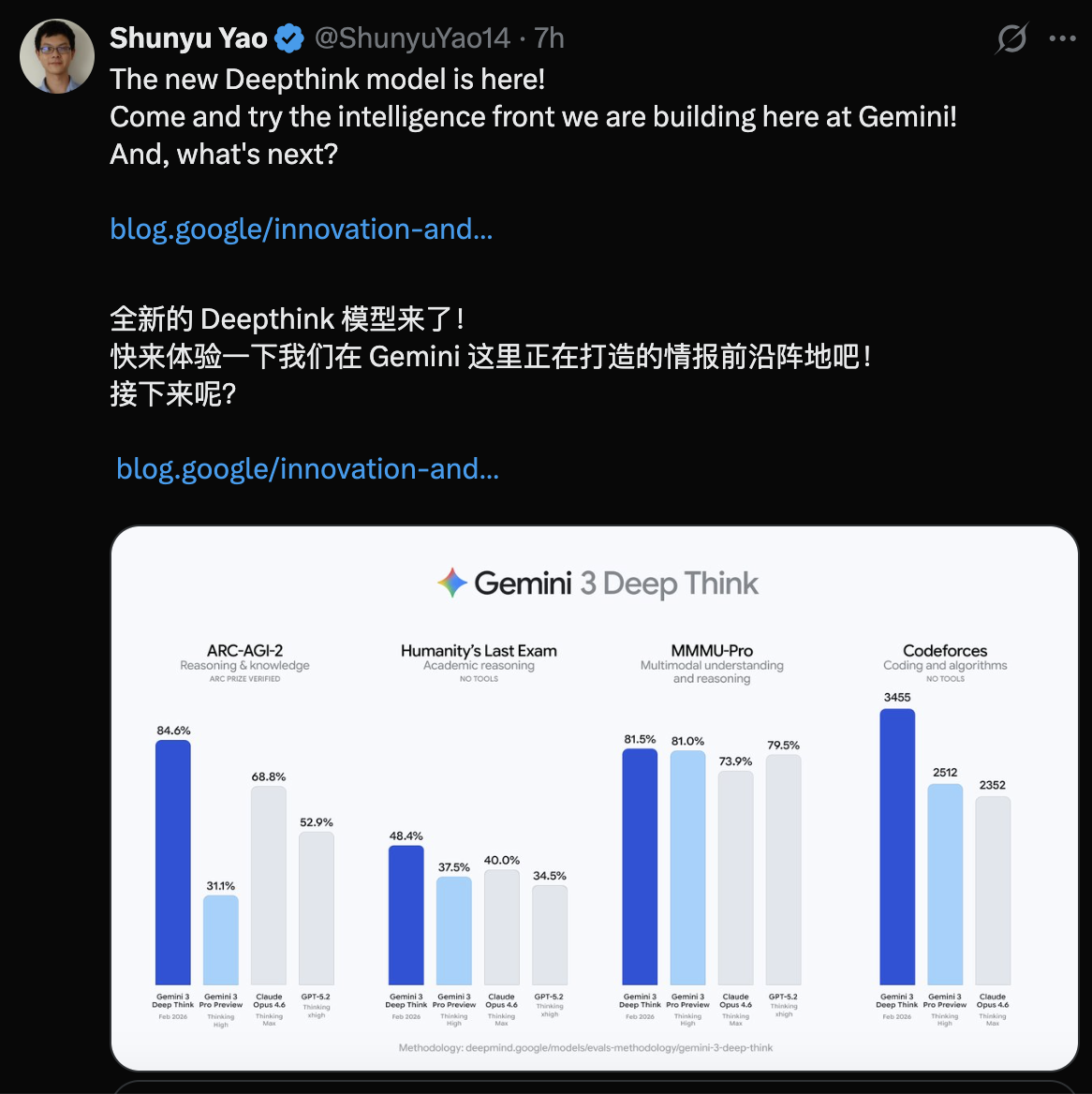
从官方定位来看,Gemini 3 Deep Think 的目标并不是更流畅的对话体验,而是解决那些长期困扰科研人员和工程师的“硬问题”:
这些问题往往缺乏明确的解题路径,不存在唯一正确答案,数据本身也常常不完整、噪声较多,甚至彼此矛盾。
谷歌表示,此次更新是在与大量科学家和研究人员的长期合作基础上完成的,模型的设计思路也明显偏向真实科研与工程实践,而不仅是抽象推理能力的展示。
全新 Deep Think 现已在 Gemini 应用中上线,供 Google AI Ultra 订阅用户使用。此外,我们首次通过 Gemini API 向部分研究人员、工程师和企业开放 Deep Think 的使用权限。
Deep Think 访问地址:https://forms.gle/eEF5natXTQimPhYH9
以下是早期测试用户如何使用最新版 Deep Think 的演示:
罗格斯大学的数学家丽莎·卡博内致力于研究高能物理学界所需的数学结构,以弥合爱因斯坦引力理论和量子力学之间的鸿沟。由于该领域缺乏大量的训练数据,她利用 Deep Think 技术审阅了一篇高度专业的数学论文。Deep Think 成功地识别出了一个细微的逻辑缺陷,而这个缺陷此前在人工同行评审中均未被发现。
在杜克大学,王氏实验室利用 Deep Think 技术优化了复杂晶体生长的制备方法,以期发现新的半导体材料。DeepThink 成功设计了一种能够生长厚度大于 100 微米薄膜的工艺,达到了以往方法难以企及的精确目标。
谷歌平台与设备部门研发主管、前 Liftware 首席执行官 Anupam Pathak 测试了新的 Deep Think,以加速物理组件的设计。
运用数学和算法的严谨性提升推理能力
在以往的大模型评估体系中,推理能力往往通过标准化问题来衡量:问题定义清晰、目标明确、评价方式单一。
而 Gemini 3 Deep Think 试图应对的,是另一类问题——研究型问题。
这类问题通常具备几个特征:
没有固定模板
没有明确步骤
数据来源复杂且不完备
解题过程本身可能需要不断修正假设
谷歌在技术博客中强调,Deep Think 的更新重点,在于将深厚的科学知识与工程实践中的常识和方法论结合起来,让模型不再停留在理论层面,而是更贴近真实世界的研究流程。
在推理能力的提升上,数学与算法仍然是 Gemini 3 Deep Think 的核心抓手。
早在去年,谷歌就曾展示过专门定制的 Deep Think 版本,在多项高难度推理任务中取得突破,并在国际数学和编程类赛事中达到金牌水平。此次更新,在这一方向上继续向前推进。
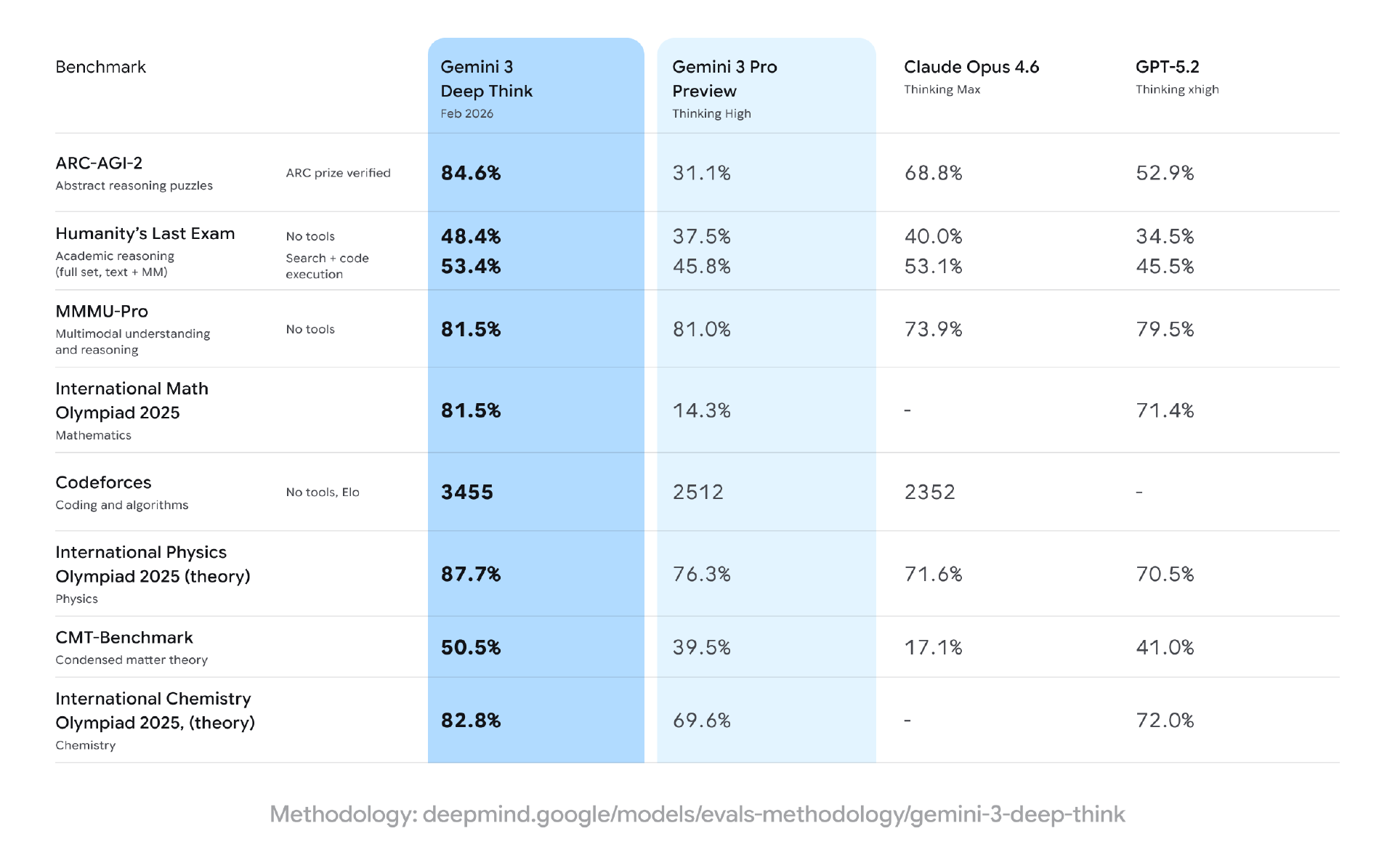
根据谷歌披露的数据,升级后的 Deep Think 在多项严苛学术基准测试中刷新了当前水平,包括:
在 Humanity’s Last Exam(“人类的最后考验”)中,在不借助任何外部工具的前提下,取得 48.4% 的成绩。这一基准被认为是专门用于测试前沿模型能力极限的高难度测试。
在 ARC-AGI-2 测试中,Deep Think 取得 84.6% 的成绩,并已通过 ARC Prize Foundation 的官方验证。
在竞技编程平台 Codeforces 上,模型达到了 3455 Elo 的评分区间,这一水平在该平台上已属于极高段位。
从 Gemini Deep Think 3455 的得分来看,其编码能力排名世界第八。
在 2025 年国际数学奥林匹克竞赛的评测中,整体表现达到了金牌水平。
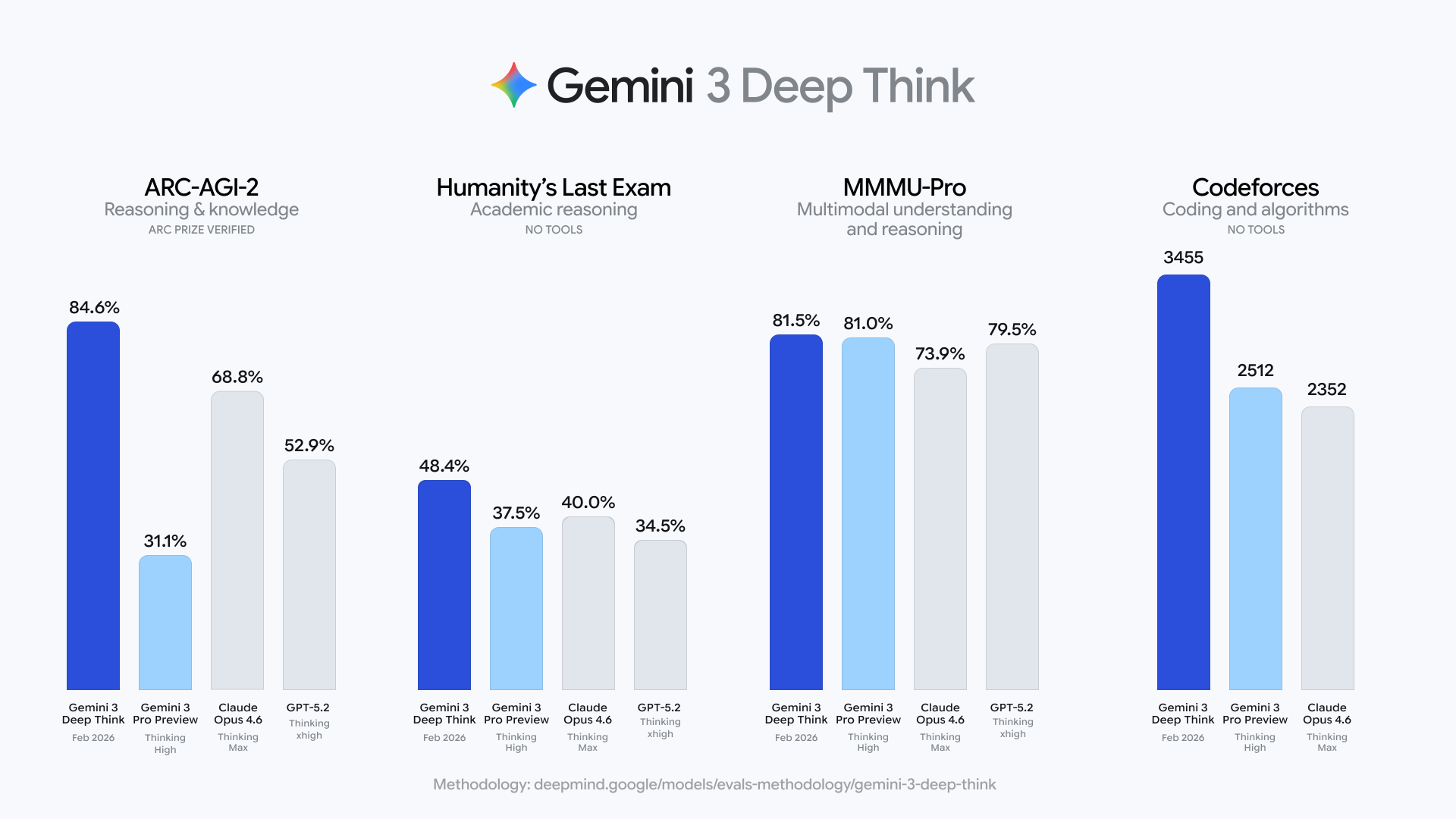
这些结果表明,Deep Think 的提升并非集中在单一任务类型,而是在多种高约束推理环境下保持了稳定表现。
不止于数学:向复杂科学领域扩展
相比以往更多集中在数学与代码推理上的展示,Gemini 3 Deep Think 此次更新明显扩大了能力覆盖范围。
谷歌表示,当前版本的 Deep Think 已经在化学、物理等多个科学领域中展现出显著提升,尤其是在需要跨学科知识和多层次建模的任务中。
在官方披露的测试中:
在 2025 年国际物理奥林匹克竞赛和国际化学奥林匹克竞赛的笔试部分,Deep Think 均达到了金牌级别表现。
在评估高等理论物理能力的 CMT-Benchmark 中,模型取得了 50.5% 的分数,显示出其在凝聚态物理等高度抽象领域中的推理潜力。
这些结果意味着,Deep Think 已不再局限于形式化推理问题,而开始具备处理真实科研难题的能力基础。
面向真实工程场景,而非“榜单模型”
谷歌在介绍中反复强调,Gemini 3 Deep Think 的设计目标,并不是单纯在榜单中取得高分。
在工程应用层面,Deep Think 被定位为一种辅助研究与工程决策的工具,可用于:
帮助研究人员理解结构复杂、变量众多的数据
协助工程师使用代码对物理系统进行建模与仿真
在设计与验证阶段提供多路径推理支持
尤其是在工程与科研交叉的场景中,Deep Think 被视为一种潜在的“认知放大器”,而不是自动化替代方案。
谷歌表示,接下来将继续通过 Gemini API 等渠道,将这一能力逐步提供给真正需要它的研究人员和从业者,并在真实使用中持续优化模型行为。
从此次更新可以看出,Gemini 3 Deep Think 的发展方向,正在从单点能力展示,逐步走向更底层的科研与工程智能基础设施。
在大模型普遍追求通用性和产品化体验的背景下,谷歌选择继续在 Deep Think 上深耕高复杂度、低确定性的任务空间。这一策略,也使其在当前大模型格局中,形成了与偏重实时交互和工具化路径的模型体系的明显区隔。
随着 Gemini API 的逐步开放,Gemini 3 Deep Think 是否能够真正嵌入科研与工程流程,并在真实环境中经受住复杂问题的考验,将成为外界关注的下一步关键。
用户:这是真正有用的工具
和 OpenAI Codex Spark 一样,谷歌 Deep Think 也一样逃不掉网友热议。
在 x 上,有用户认为,Deep Think 的价值在于它能否经受住现实的考验:返回可运行的代码,显示假设/单位,并在数据缺失时发出明确的错误提示。如果它仍然只是“推理”工具,无法交付模拟程序或调试模型,那么它只不过是一个更高级的自动补全工具而已。
还有 x 用户认为这是一次重要的升级,他表示:“Gemini 将草图转化为 3D 打印模型的功能简直太棒了——这才是工程师们真正会使用的 AI 升级。如果这种趋势持续下去,原型制作速度将提升近 10 倍。”
一位主页介绍为 Amazon 工程师的 x 用户表示:我们正在从聊天时代迈向推理时代。谷歌刚刚升级了 Gemini 3 Deep Think,以解决科学和工程领域最棘手的问题。
“为什么这次更新是一次力量倍增器:它通过探索多个假设来解决没有单一‘正确’答案的问题。针对研究和高级工程中混乱、不完整的数据进行了优化。它使用‘思维签名’来保持长期、复杂项目的逻辑性。”
还有用户表示,此次更新的模型取得的基准测试结果令人印象深刻。
但真正的变革将在以下情况下发生:
人工智能可将工程时间缩短 50%;
人工智能改进科学建模;
人工智能降低研发成本;
参考链接:
https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-deep-think/




