
刚刚,可灵 AI 面向全球正式发布可灵 2.0 视频生成模型及可图 2.0 图像生成模型。即日起,可灵 2.0 和可图 2.0 在全球范围上线。
“这是你能用到的,世界上最强大的视觉生成模型。”快手高级副总裁、社区科学线负责人盖坤说道。
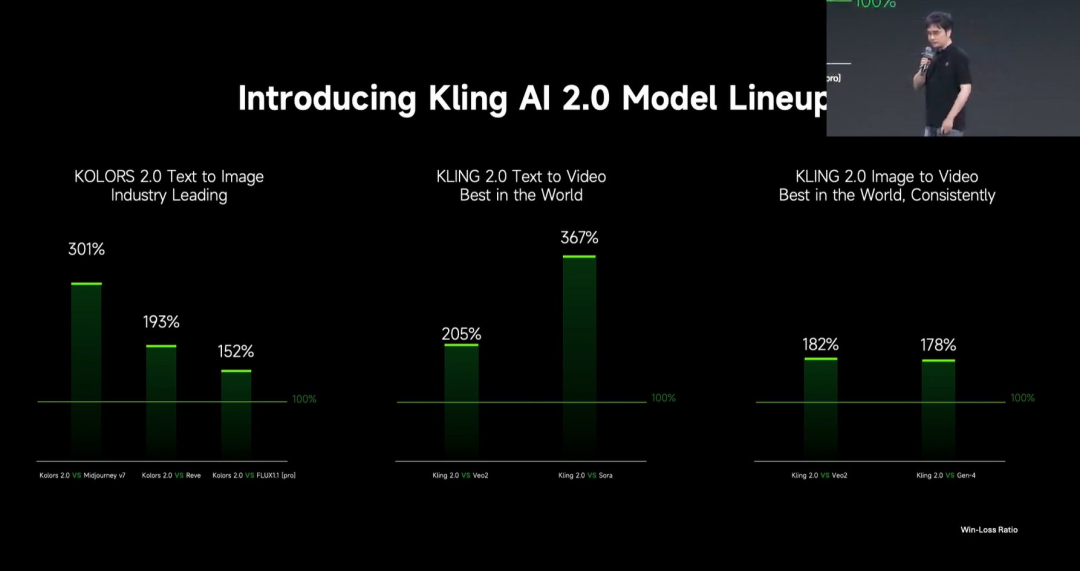
根据对比测试,可灵 2.0 文生视频大模型与 Veo2 的胜负比为 205%,与 Sora 的胜负比为 367%(如果两模型胜负比为 100%,说明两者水平相当)。可灵 2.0 图生视频大模型与 Veo2 的胜负比为 182%,与 Gen-4 的胜负比为 178%。
另外,可图 2.0 文生图大模型,与 Midjourney v7 的胜负比为 301%,与 Reve 的胜负比为 193%,与 Flux 1.1 Pro 版本的胜负比为 152%。
可灵 2.0 生成效果如何?
快手副总裁、可灵 AI 负责人张迪介绍,现在的视频 AI 生成技术还远远不够,目前创作者们会遇到两类问题:一类是语义遵循能力在部分情况下能力不够,妨碍了创作者们用文字精准表达、控制生成结果;二是动态质量问题,包括大家所常说的运动崩坏或者不符合物理规律。
为此,可灵 2.0 视频生成模型在语义响应、画面质量、动态质量、真实度和美感上都有大幅提升。
语义响应
“一个视频生成模型的语义响应,已经不能用简单的文本响应来看了,我们希望它有更强的动作响应能力,有更强的运镜响应能力,有更强的时序响应能力。”张迪说道。
可灵 2.0 完善了 1.6 版本中的表情的动作描述和肢体的动作描述的细节错误:
时序响应指的是在同一个 prompt 里面,按照时间顺序进行分段描述,模型需要按照严格的时间顺序进行展示。可灵 2.0 在背景延时摄影的完成度都很高:
除了基础运镜,可灵 2.0 可以直接用提示词激活环绕运镜、跟随运镜、镜头组合运镜等方式:
动态质量
可灵 2.0 重点优化了历史版本中可能出现慢动作的问题,对于运动速度的把握更加精准:
更合理的运动幅度使得整个画面的表现张力更好、更有冲击力:
美学优化
在美学优化方面,可灵 2.0 可以生成更具电影大片质感的镜头,同时让每一个镜头的细节表达更加丰富:
可灵 2.0 在一些细节上的优化:
对于可灵 2.0 的生成效果,网友们也给出了很高评价。
”AI 视频的质量一夜之间提升了 10 倍,我已经无话可说了。Kling 2.0 刚刚发布,我已经花掉了 1250 美元的额度来测试它的极限。我从没见过这么流畅的动态效果,也从没见过对提示词的理解这么准确的模型。”PJ Ace 说道。
“相信我,这次模型升级绝对惊艳!现在你可以生成的动态动作数量达到了新的高度。如果您想让动作更快速,新模型在这方面完全胜任,动作看起来非常自然流畅。”网友 Travis Davids 说道。
一系列技术创新细节披露
“所有的这些能力提升,都离不开整个团队背后的大量的技术创新。”张迪介绍,可灵 2.0 在基础模型架构和训练和推理策略上进行了全新的升级,这些工作使其打开了建模和仿真的能力空间。
可灵整体框架采用了类 Sora 的 DiT 结构,用 Transformer 代替了传统扩散模型中基于卷积网络的 U-Net。具体来说,可灵 2.0 在基础模型上的架构升级包括:
全新设计的 DiT 架构,提升视觉 / 文本模态信息融合能力。
全新设计的 VAE,使复杂动态场景下过渡更顺畅、质感更自然。
首次系统性研究了视频生成 DIT 架构的 Scaling Law 特性。
为解锁更强的指令响应和运动表现,可灵 2.0 采用了以下训练和推理策略:
强化对于复杂运动、主体交互的生成能力提升视频表现张力。
强化对运镜语言、构图术语等专业表达的理解和响应能力。
人类偏好对齐技术,让模型更懂”常识”和“审美”。
据张迪透露,在可灵 AI 平台上,85% 的视频创作是通过图生视频完成的,这一方面说明了图生视频可以更好地表达用户的创作意图,另一方面也彰显了图片赋予整个视觉创作流的重要性。
此次升级的可图 2.0 模型,在指令遵循、电影质感及艺术风格表现等方面作了显著提升。 在风格化响应上,可图 2.0 支持 60 多种风格化的效果转绘,包括受大家喜爱的 GPT 风格、二次元风格、插画风格、数字世界、3D 等,模型出图创意和想象力实现因此大幅跃升。
而在可图 2.0 背后,同样暗含许多技术创新。张迪介绍称,快手团队在预训练阶段,通过精准建模预训练文本到视觉表征的映射,使得文本和图像的对齐做得更好;在后训练阶段,该模型更多地使用了强化学习技术来提升美感、对齐人类审美,并大量探索了后训练阶段的 Scaling Law;在推理阶段,大量使用了全新的提示词工程和推理策略,提升了出图的稳定性和创造性。
视频和图像都能放进 prompt 了
“文字作为人去描述自己想象中的世界的媒介是不完备的,需要定义一个人和 AI 交互的新的语言,让人的想象能够被 AI 完全感知到。”盖坤说道。
在一些场景里,文字很难准确描述出视频内容,比如复杂的武打画面,即使用很大篇幅的文字也难以准确描述。
为此,快手还在可灵 2.0 大师版上线了全新的多模态编辑功能,能灵活理解用户意图,支持对视频和图像内容实现增、删、改元素。
具体可以看到,多模态编辑器中,可以将多模态的表达放进提示词中,以实现更准备的修改。

此外,图像多模态编辑具有风格重绘的能力,能够对图片可进行不同风格的重绘,且保持原图片的语义。
在本次 2.0 模型迭代中,可灵 AI 正式提出了 AI 视频生成的全新交互理念 Multi-modal Visual Language(MVL),即将语义骨架(TXT)和多模态描述子(MMW)结合,让用户能够结合图像参考、视频片段等多模态信息,将脑海中的多维度复杂创意,直接高效地传达给 AI。此次发布的多模态视频编辑功能,正是基于 MVL 的思想所研发。
张迪介绍称,多模态编辑功能背后是一整套多模态控制技术,快手目前在这方面迎来了很大的突破,包括以下三个方面:
把文本模态、图像模态和视觉模态进行了统一表征,并使用超长的上下文进行训练;
通过高效的 Token 压缩与缓存算法,可以支持长序列的训练和推理;
在推理环节,使用了带有 CoT 的多模态推理能力技术来理解用户输入的多模态信息。
结 语
截至目前,可灵 AI 全球用户规模突破 2200 万,过去的 10 个月里,其月活用户量增长 25 倍,累计生成超过 1.68 亿个视频及 3.44 亿张图片。
张迪表示,在发布之初,快手便深知视频生成技术赛道是一个长跑,为此可灵 AI 自发布后就进入了夺命狂奔模式,过去 10 个月时间里已经历了 20 多次的产品迭代,发布了 9 个有里程碑意义的产品。可灵 1.0 于去年 6 月发布,是全球首个用户真实可用的 DIT 架构的视频政策大模型。
对于这一次的更新,可灵 AI 团队给出了这样的评价:“我们可以当之无愧的说,可灵 2.0 文生视频模型是一个全球大幅领先的视频模型。”
声明:本文为 AI 前线整理,不代表平台观点,未经许可禁止转载。




