
5 月 28 日深夜,Anthropic 发布了其旗舰模型 Opus 的最新版本 Opus 4.8。
相比 Opus 4.7,这次升级的重点不只是模型跑分,而是围绕 Claude Code 增加了两个更直接面向开发者工作流的能力:dynamic workflows 和更便宜的 fast mode。
dynamic workflows 允许 Claude 编写用于任务编排的脚本,调度数十到数百个并行 subagents 运行。单次运行中,subagents 的并发上限为 16 个,总数上限为 1000 个。
fast mode 则主要面向对速度和吞吐量更敏感的场景。它可以让 Opus 以 2.5 倍的输出速度运行,同时保持相同质量;在 Opus 4.8 上,fast mode 的价格已经降至此前的三分之一,但使用前需要启用 usage credits。
基准测试显示,Opus 4.8 不仅超过了前代模型,也领先于 GPT-5.5 和 Gemini 3.1 Pro。不过在 agentic terminal coding 这一项上,OpenAI 的模型仍然保持领先。发布当天,Opus 4.8 的常规模式价格与 Opus 4.7 相同,仍为每百万输入 token 5 美元、每百万输出 token 25 美元。
Claude Opus 4.8 升级的三个重点
这次 Opus 4.8 的升级,可以先抓住三个关键词:dynamic workflows、思考强度控制,以及更便宜的 fast mode。前两个直接影响 Claude Code 能处理多大规模的任务、以什么方式完成任务;后一个则关系到延迟和成本。
先看 dynamic workflows。
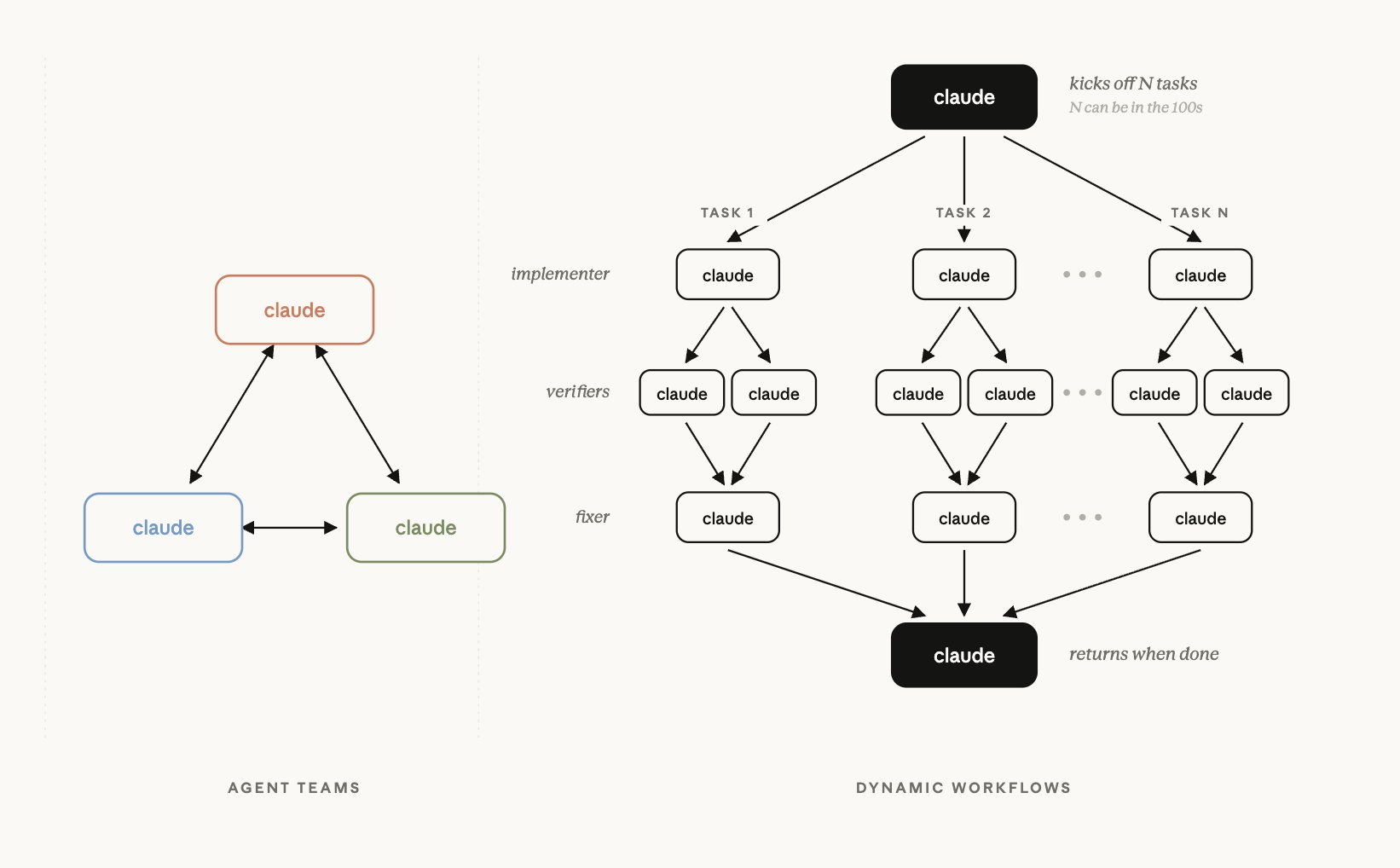
dynamic workflows 本质上是一段 JavaScript 脚本,用来大规模编排 subagents。用户描述一个任务之后,Claude 会为这个任务编写脚本,然后由一个运行时在后台执行。与此同时,用户当前的 session 仍然可以保持响应,不会因为 agents 在后台工作而卡住。
它的核心变化在于,任务计划被转移到了代码里,而不是继续塞在 Claude 的上下文窗口中。中间结果也会保存在脚本变量里。因此,Claude 的上下文里只保留最终答案。这一点,正是 dynamic workflows 与 subagents、skills 的关键区别。
这个功能要求使用 Claude Code v2.1.154 或更高版本。它可以在 CLI、Desktop 和 VS Code 插件中运行,面向 Max、Team 和 Enterprise 计划开放。在 Max 和 Team 计划中,它默认开启;在 Enterprise 计划中,则需要管理员启用后才能使用。它也可以在 Claude API、Amazon Bedrock、Vertex AI 和 Microsoft Foundry 上运行。
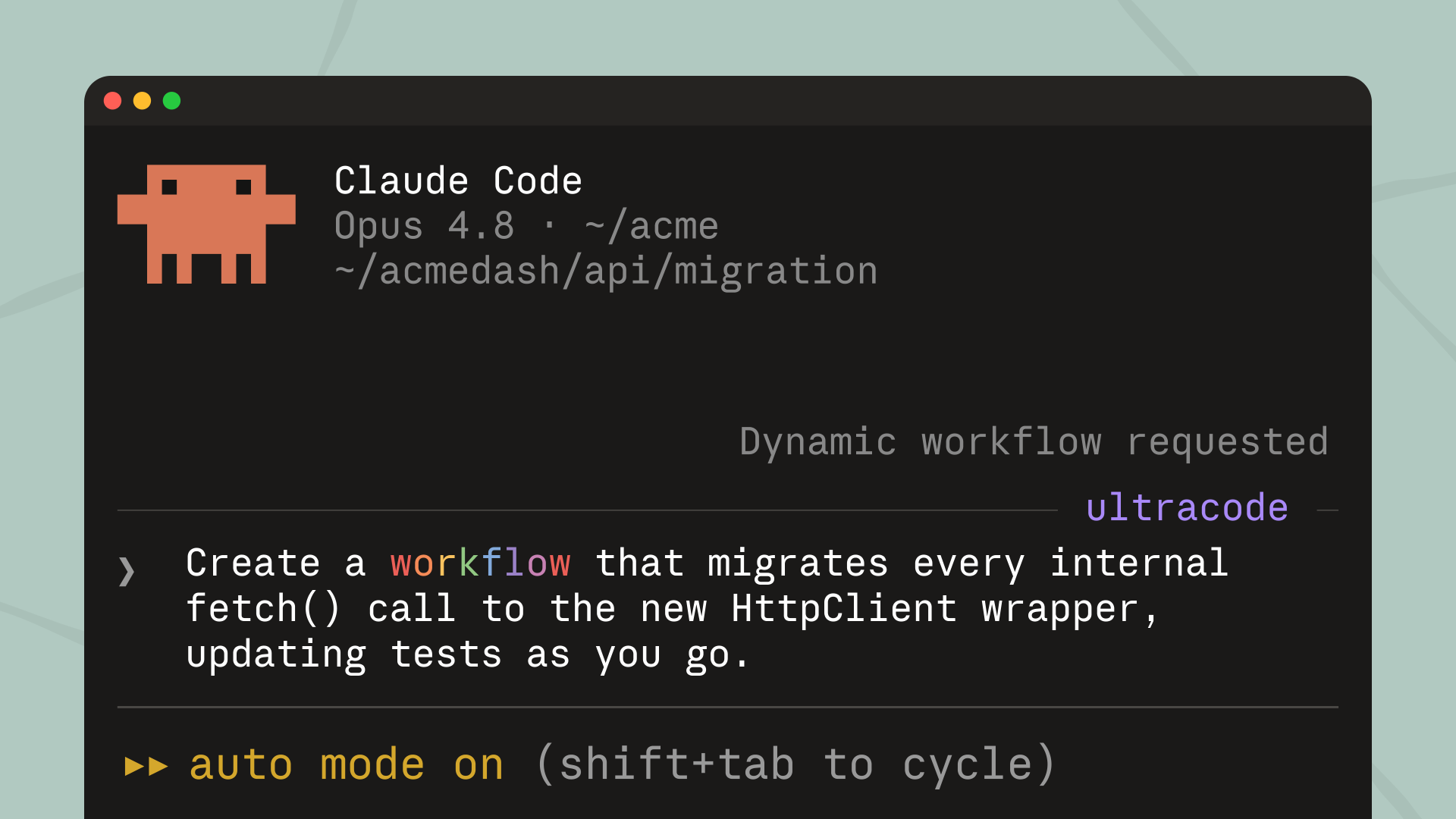
用户可以通过两种方式启动一个 workflow。第一种是在 prompt 的任意位置包含 workflow 这个词。第二种是开启一个名为 ultracode 的设置。Ultracode 会把 xhigh 级别的推理强度与自动 workflow 编排结合起来。Claude Code 还内置了 deep-research,它本身就是一个预置 workflow。
当一个 workflow 启动后,Claude 会根据用户的 prompt 动态规划任务。它会把任务拆解成多个子任务,然后把工作分发给并行运行的 subagents。这些 agents 会从彼此独立的角度处理问题,另一些 agents 则会尝试反驳这些发现。整个运行过程会不断迭代,直到答案逐渐收敛。在结果被纳入最终输出之前,还会经过检查。
运行时会施加明确的硬性限制。它最多允许 16 个 agents 并发运行,单次运行的 agents 总数上限为 1000 个。workflow 脚本本身不能访问文件系统或 shell,只有 agents 可以读取、写入文件并运行命令。
随着运行推进,进度会被保存下来。如果任务中途被打断,它可以在同一个 session 中恢复。已经完成的 agents 会在恢复时返回缓存结果。由于协调过程发生在对话之外,任务计划也就更容易保持稳定,不会在会话上下文中被不断稀释或带偏。
Anthropic 重点展示了一个大型案例。Jarred Sumner 使用 dynamic workflows 对 Bun 进行移植,把 Bun 从 Zig 迁移到 Rust。这个迁移版本通过了现有测试套件的 99.8%,生成了大约 75 万行 Rust 代码,从第一次 commit 到最终 merge 用了 11 天。
其中一个 workflow 负责为每个 struct 字段映射正确的 Rust lifetime;下一个 workflow 则把每个 .rs 文件写成行为一致的移植版本。数百个 agents 并行工作,并且每个文件都有两个 reviewer。随后,一个修复循环持续驱动构建和测试套件,直到全部清理干净。不过,这个结果虽然已经合并,但目前还没有进入生产环境。
第二个重点,是用户现在可以控制 Claude 的思考强度。
新的控制项意味着,用户可以调高或调低 Claude 在任务中投入的推理资源。Anthropic 在公告博客中解释称,当用户让 Claude 全力处理任务时,它会“更频繁、更深入地思考,以给出更好的回答”。相反,在较低思考强度下,Claude 会更快给出回应,同时消耗用户 rate limit 的速度也会更慢。
对那些已经感到 AI 服务正在通过额度缩水变相涨价、又担心额度比预期更快用完的用户来说,这可能算是一个好消息。
第三个重点,是 fast mode 降价。
Anthropic 大幅下调了 Opus 4.8 快速模式的价格。在快速模式下,模型生成 token 的速度约为正常速度的 2.5 倍;而 Opus 4.8 的快速模式价格降至每百万输入 token 10 美元、每百万输出 token 50 美元,低于 Opus 4.7 的 30 美元 / 150 美元。
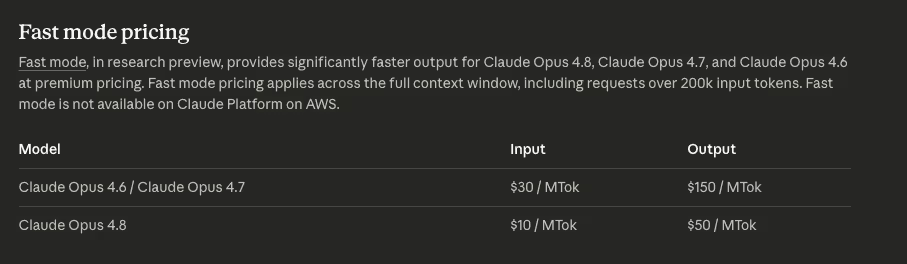
这相当于在此前模型的快速模式价格基础上降低了 3 倍,也让高吞吐推理更接近那些对延迟敏感的生产工作负载。
快速模式已经可以在 Claude Code 中通过 /fast 命令使用;API 访问目前仍有限制,需要在 claude.com/fast-mode 申请 waitlist。
在常规模式下,Claude Opus 4.8 仍然属于价格较高的前沿模型之一,但价格依然低于主要竞争对手 OpenAI 的 GPT-5.5。
不过,速度、成本和代码能力之外,Opus 4.8 这次还试图回答另一个问题:AI 能不能更诚实。
在今天的大模型竞争中,越来越难回避的一点是,我们其实很难找到一个真正“诚实”的 AI。古希腊哲学家第欧根尼有一个著名传说:他曾在白天提着一盏点亮的灯,在雅典街头四处寻找,并说自己在寻找一个诚实的人。把这个故事放到今天,人们寻找的恐怕就不只是一个诚实的人,而是一个诚实的 AI。
一个模型可以更聪明、更快、更会写代码,但它能不能承认自己不知道,能不能发现自己写错了,能不能在用户最需要判断力的时候保持诚实,反而成了更稀缺的能力。这也是 Anthropic 这次想重点强调的方向。Opus 4.8 被 Anthropic 描述为更能支持用户,也更少欺骗用户。
Anthropic 的 Alignment 团队在公告博客中表示,这个模型“在我们衡量亲社会特质的指标上达到了新高”。具体而言,Anthropic 称,Opus 4.8 在支持用户自主性、以及按照用户最佳利益行事方面都有提升。
另一个看起来积极的变化是,Anthropic 表示,Opus 4.8 的欺骗率,以及配合滥用请求的比例,都比前代模型“显著更低”。这似乎意味着,它已经追上了 Claude Mythos Preview。Anthropic 此前曾称 Claude Mythos Preview 是“我们训练过的对齐程度最高的模型”。
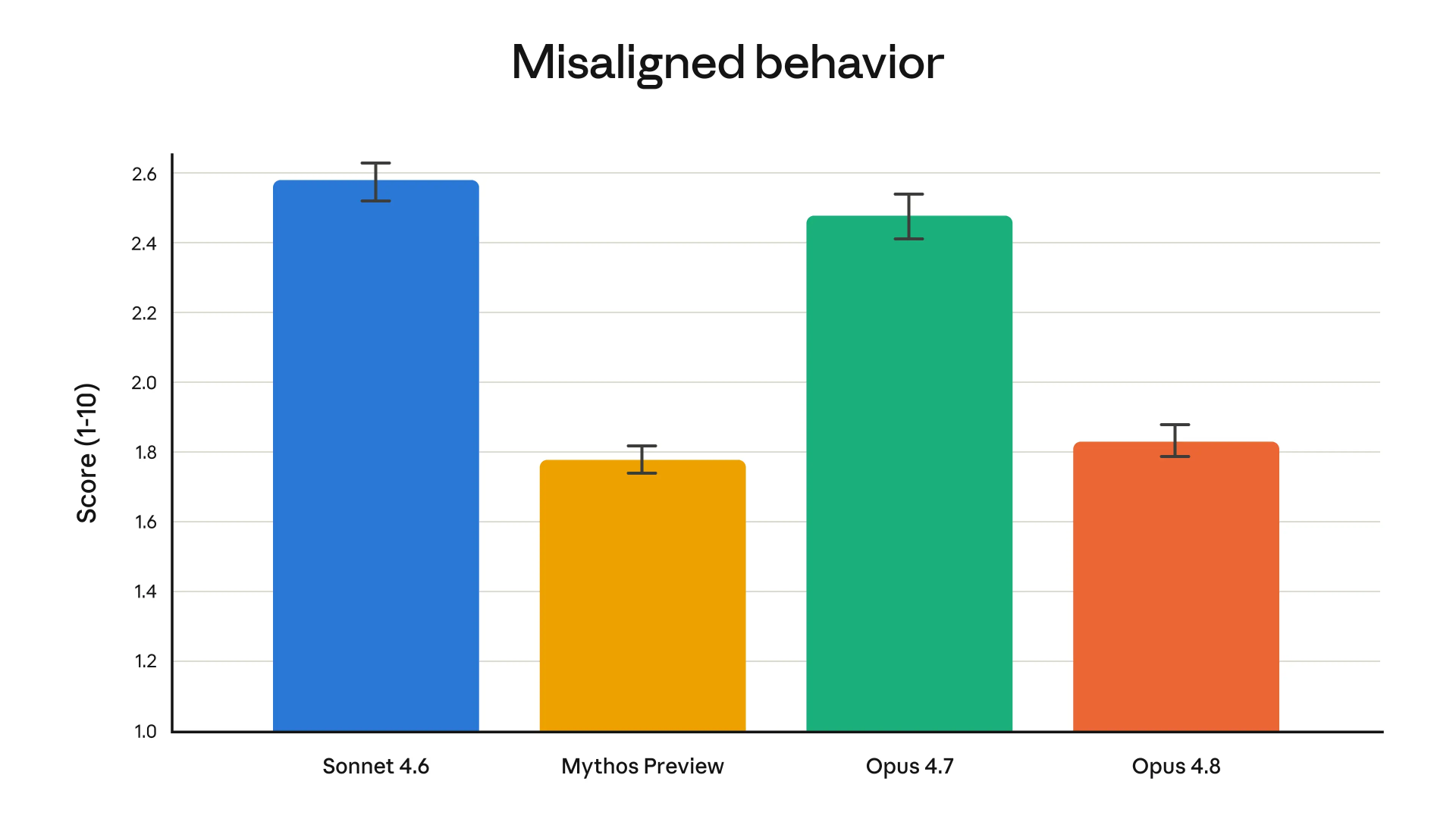
Anthropic 还表示,相比前代模型,Opus 4.8 “大约低四倍概率会对自己写出的代码中的缺陷视而不见、不加说明”。Anthropic 称,早期测试者也印证了这一点,并形容 Opus 4.8 在执行 agentic 任务时“更可靠,在判断上也更敏锐”。换句话说,Opus 4.8 试图解决的不只是模型能不能完成任务,而是它在完成任务时,是否愿意指出风险、承认问题,并在必要时反过来提醒用户。
基准测试:一个“重大战略错误”?
从基准测试来看,Opus 4.8 相比其他模型表现如何?Anthropic 表示,Opus 4.8 在所有基准测试中都比前代模型更进一步。虽然发布当天公布的基准测试不一定总能对应真实使用体验,但这些数字确实显示出一定潜力。
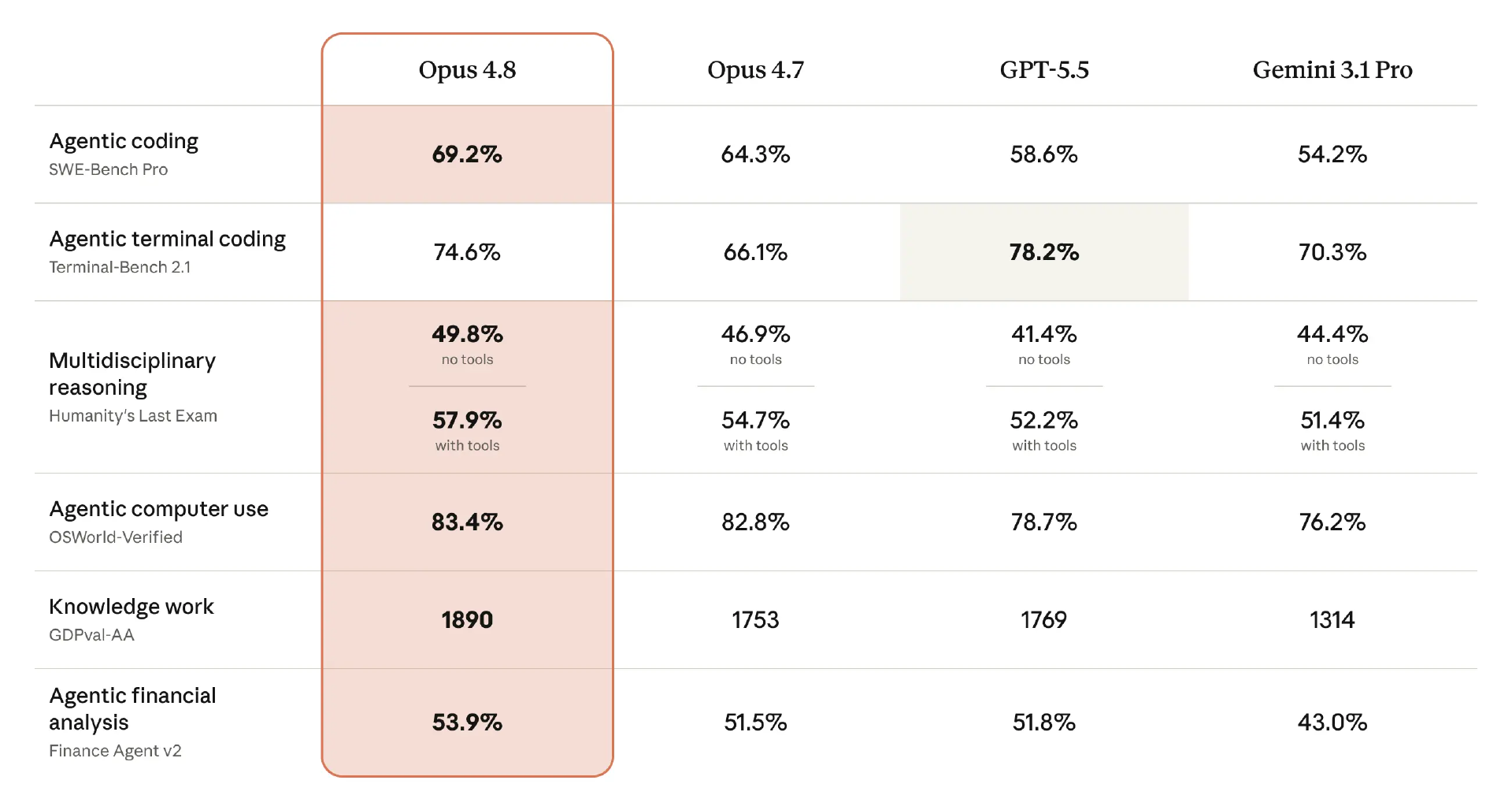
其中最值得注意的是,Opus 4.8 在 agentic coding 上达到 69.2%,明显高于 Opus 4.7 的 64.3%,也超过 GPT-5.5 的 58.65% 和 Gemini 3.1 Pro 的 54.2%。它在 agentic compute use 上的得分为 83.4%,相比 GPT-5.5 的 78.7% 和 Gemini 3.1 Pro 的 76.2%,同样不容忽视。但在 agentic terminal coding 上,Opus 4.8 仍然输给了 GPT-5.5,比 OpenAI 的模型低了 3.6 个百分点。
不过,正是这组对比,也引发了外界对基准测试可信度的讨论。
尤其是在开发者社区里,GPT-5.5 的编码体感正在获得很强的正面反馈。DHH 不久前在 X 上表示,自 Opus 4.5 以来,没有哪个模型像 GPT-5.5 这样让他反复出现“难以相信它已经这么好”的时刻。
也正是在这种背景下,Redis 作者 antirez 对 Anthropic 的基准测试呈现方式提出了批评。他认为,Anthropic 这次犯了一个“重大战略错误”:过去厂商通常更强调新模型相对旧模型的提升,但这一次,在很多人已经感受到 GPT-5.5 编码能力很强的情况下,Anthropic 把 GPT-5.5 放进同一组对比里,反而让客户看到,基准测试和真实使用体感之间可能并不一致。
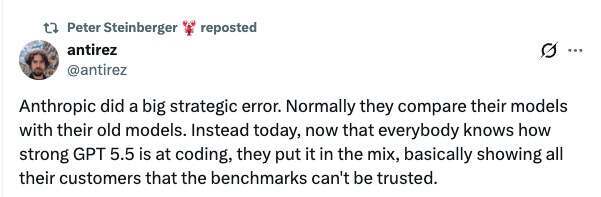
有人在评论区反问,这难道不是一种透明吗?antirez 的回应是,问题不在于是否透明,而在于如果 Anthropic 明知道 GPT-5.5 在编码上比 Opus 4.7 强得多,即使后者在某些基准测试中得分更高,却仍然把这些数字呈现为“模型更强”的证明,就会让用户感到困惑。
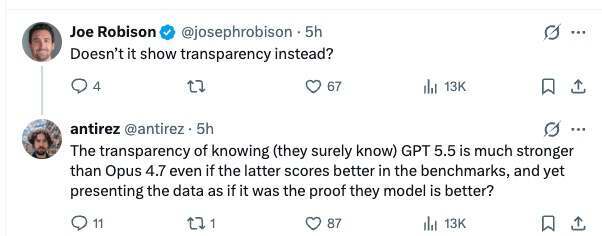
另一位用户指出,主流模型发布时本来就常常会把 Big Three 的最新旗舰模型放进对比图里,Anthropic 并不是例外。antirez 则表示,这并不改变核心问题:用户看到的是厂商说法与实际体验之间的错位。
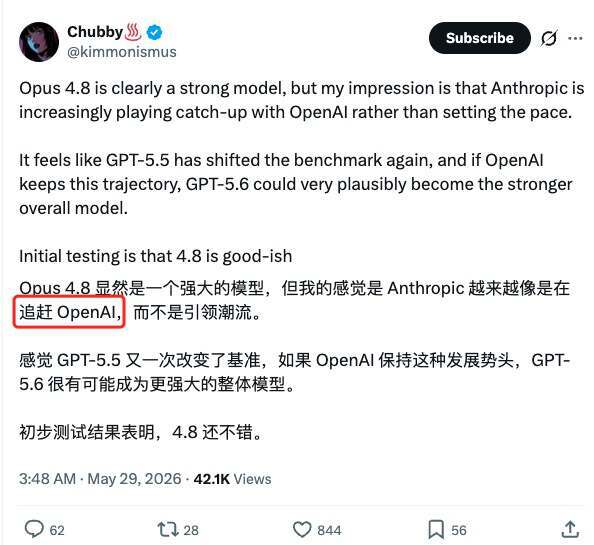
网友 Chubby 就评价称,Opus 4.8 显然是一个很强的模型,但他的印象是,Anthropic 正越来越像是在追赶 OpenAI,而不是继续定义节奏。
在他看来,GPT-5.5 似乎再次抬高了基准;如果 OpenAI 保持这样的推进速度,GPT-5.6 很可能成为整体更强的模型。
Opus 这一年:从“封王”到变相涨价争议
2025 年 5 月,Anthropic 在首届开发者大会 Code with Claude 上发布 Opus 4,并称其为“世界上最好的编码模型”。当时,这家公司承诺要在编码、高级推理和 AI agents 方面树立新标准。这个模型在编码和长上下文推理方面带来了显著进展,尤其突出的是,它能够处理长时间运行的任务,并在 Anthropic 当时所说的“数千个步骤”中保持上下文。
很快,2025 年 8 月,Opus 4.1 发布,在 agentic 任务、编码和推理能力上带来了一些提升。但这只是一次小更新。当时,Anthropic 还预告称,“未来几周,我们会对模型带来大得多的改进”。
2025 年 11 月,Opus 4.5 高调发布。Anthropic 再一次称它是“世界上最适合编码、agents 和 computer use 的模型”。同样,他们也再次吊起外界胃口,称 Opus 4.5 只是“工作完成方式发生更大变化的一个预览”。就这个预览本身而言,Opus 4.5 的确带来了一些能力改进,让模型能够更好地处理模糊性,并解决涉及多个系统的 bug。从很多方面看,在 OpenAI 的 GPT-5.1-Codex-Max 和 Google 的 Gemini 3 获得市场青睐之后,Opus 4.5 帮 Anthropic 重新夺回了编码王冠。
此后又过了三个月,Anthropic 带来了 Opus 4.6。Opus 4.6 “让大型语言模型用于企业工作流发生了阶跃式变化,因为它能够处理更复杂的任务,并更好地交付结果”。Opus 4.6 在规划、编码和调试能力上继续提升,成为 Anthropic 首个使用 adaptive thinking 的模型,并取得了亮眼的基准测试成绩。其中尤其值得注意的是,它拥有 100 万 token 的上下文窗口。
不过,Opus 4.6 的争议也很快出现。发布之后,Anthropic 很快因为一次定价调整遭到批评:虽然模型在技术上支持接近 100 万 token 的 prompt,但只要请求超过约 20 万 token,整个请求都会被划入更高的“长上下文”价格层级。
Opus 4.7 也遇到了一些麻烦。它在 2026 年 4 月发布,是 Opus 4.6 的直接升级版本,带来了更好的视觉能力、更好的记忆能力和更好的指令遵循能力。但发布之后,有用户反馈称,Claude Opus 4.7 会出现自相矛盾的回答,性能也有所下降,这引发了外界对模型质量、安全权衡以及 AI 服务变相涨价的讨论。更尴尬的是,Anthropic 自己也称 Opus 4.7 “整体能力不如”当时备受讨论的 Claude Mythos Preview。从外界报道看,Opus 4.7 在某种程度上像是在为 Mythos 的新网络安全防护机制试水。
现在,Opus 4.8 已经正式发布。对近期屡屡引发用户不满的 Anthropic 来说,这确实是一个重要节点。一方面,它需要证明 Opus 系列仍然能在编码和 agentic 任务上继续向前推进;另一方面,它也需要回应用户对额度、价格、模型稳定性和产品体验的持续不满。
本月早些时候,Anthropic 推出的 Claude Code agent view 并没有让开发者买账。有人评价说,它只是“减少了一些摩擦,但没有改变底层问题”。同一周,Anthropic 还宣布,从 6 月 15 日开始,将对 Agent SDK 使用量进行拆分计费。对于那些已经习惯把程序化使用和交互式使用都计入同一个订阅额度的用户来说,这显然不是一个受欢迎的变化。
当然,Opus 4.8 可能还不是 Anthropic 接下来唯一的一张牌。此前同一则泄露消息中还提到过 Sonnet 4.8 和 Mythos 1,如果这两个名字也陆续落地,Anthropic 才算真正进入下一轮产品更新周期。
参考链接:




