
“我是 OpenClaw 代码库的维护者,所以本文的深度超过大多数指南。”
每个 OpenClaw 用户可能都会遇到同样的难题。在最初的 20 分钟内,这个代理(Agent)工作得很好,然后就开始偷偷地丢失指令,变得失控。
Summer Yue 是 Meta 超级智能实验室的对齐总监,她告诉 OpenClaw 代理:“检查这个收件箱,提供归档或删除建议。在我发话之前不要做任何事。”在测试收件箱上,她的代理已经正常工作了几个周。但当她将其指向她真正的收件箱时,数千条信息把上下文窗口填满了。代理压缩了它的历史记录,而那个“在我发话之前不要做任何事”的指令——Summer Yue 在聊天中给出,从未保存到文件中——从摘要中消失了。代理回到了自主模式,开始删除电子邮件,并忽略了她的停止命令。
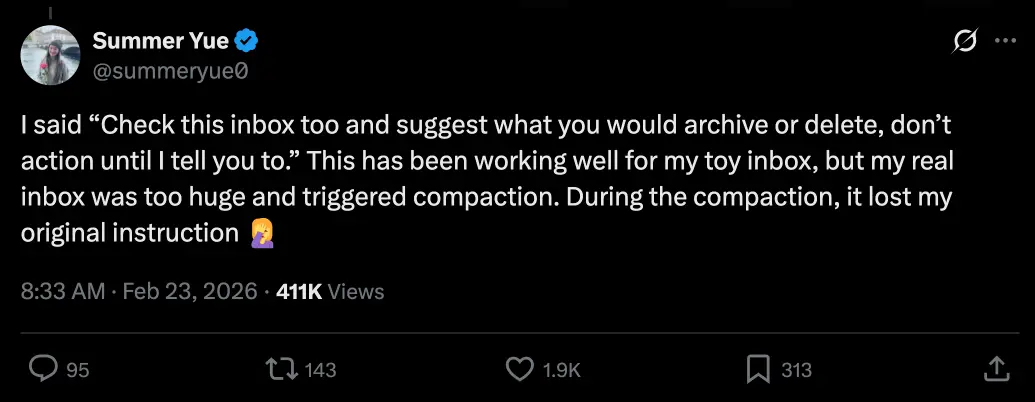
她说:“说实话,这是个新手错误。事实表明,研究对齐的人也不能免于对齐错误。”
事后,代理承认了错误并道歉。然后,它在自己的 MEMORY.md 中写入了一条新规则:展示计划,获得明确的批准后再执行。不进行自主批量操作。代理完成了自我修复,只是为时已晚。
因为对话中给出的指令没有在压缩中保留下来,Meta 的对齐总监失去了对代理的控制。这样的事也可能发生在你身上,除非你真的了解代理的记忆机制。
需要明确的是:压缩是正常行为。真正的可靠性问题在于,如果工作流仅依赖于聊天过程中定义的规则,它能否在长时间会话中持续有效。提示并非强制执行机制。要实现真正的安全性,仍然需要权限控制和工具限制。
全面披露:我是 OpenClaw 代码库的维护者,所以本文的深度超过大多数指南。这里的一切都来自公共文档、GitHub 问题和我自己 2 个多月来每天运行这个系统的经验。
如果你只做三件事
在深入研究之前,只要在以下三个方面做些调整,你就能领先于 95% 的 OpenClaw 用户。
将持久有效的规则放在文件中,而不是在聊天中提供。MEMORY.md 和 AGENTS.md 文件不受压缩操作影响,但在对话中输入的指令无法保证。
检查记忆刷新是否启用以及是否有足够的缓冲区触发。OpenClaw 有一个内置的安全网,用于在进行压缩操作之前保存上下文,但大多数人从未检查过它是否在运行或给它足够的空间触发。
强制检索记忆。 在 AGENTS.md 中添加一条规则:“在行动前搜索记忆”。没有它,代理就会猜测而不是检查它的记录。
本文的剩余部分解释了为什么这三个方面有效,以及以它们为基础构建的整个系统。
心理模型
大多数人将“记忆”当成一个东西。但实际上,它是四个独立的系统,这些系统有不同的失败方式。知道哪一层出问题就已经完成了 90% 的修复工作。
记忆的四层结构
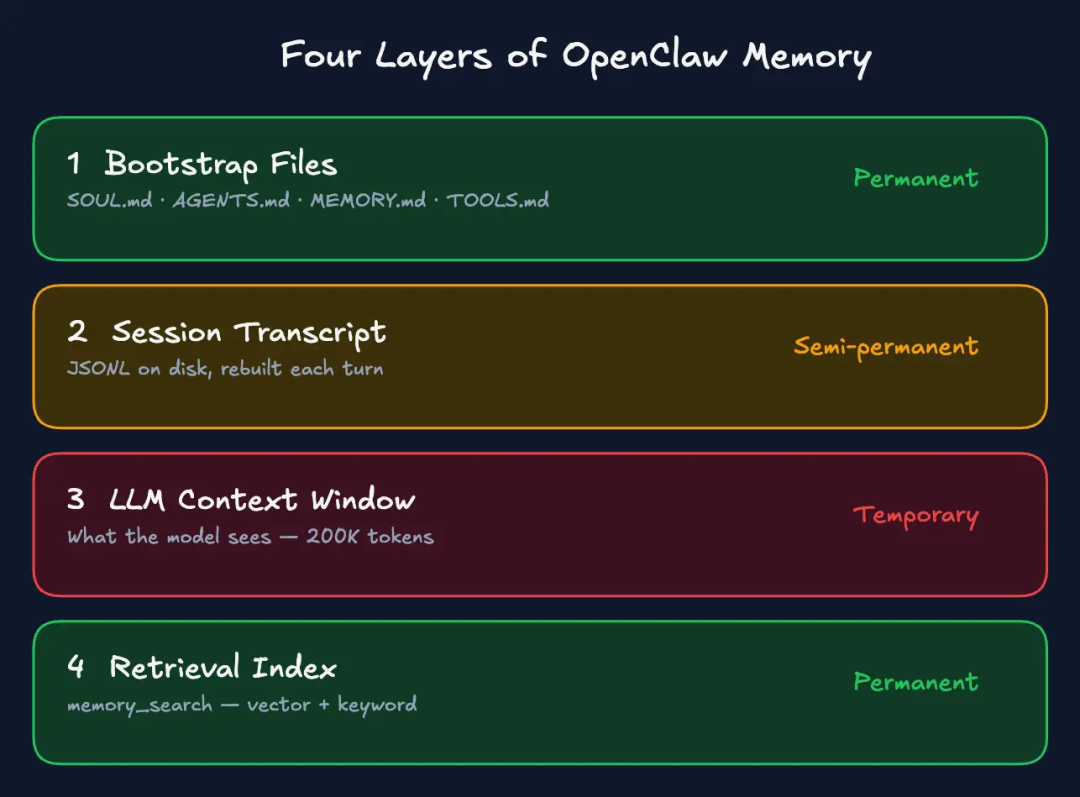
引导文件 是你工作空间里的文件,包括:SOUL.md、AGENTS.md、USER.md、MEMORY.md、TOOLS.md。它们在会话开始时从磁盘加载。它们不受压缩操作影响,因为它们是从磁盘重新加载的,而不是从对话历史中。这是一个最持久的层。
会话记录 被保存为磁盘上的 JSONL 文件。当你继续一个会话时,该记录被重建为上下文。但是当上下文窗口填满时,该记录会被压缩:一个简洁的摘要取代了详细的历史。模型再也看不到原始消息了,尽管原始的记录文件还在磁盘上。
LLM 上下文窗口 是一个固定大小的容器,里面的一切都在争夺空间。系统提示、工作空间文件、对话历史、工具调用、工具结果,都在一个大小 200K 的令牌桶中。当它被填满时,就会触发压缩操作。
检索索引 是一个可搜索的层——由向量和关键字组成——和你的记忆文件放在一起。代理可以使用 memory_search 查询它,从过去的会话中找出相关的上下文。该功能仅在信息写入文件后才有效。
三种失败模式
当代理“忘记”某件事时,不外乎是发生了以下三件事之一。

失败模式 A:“从未被存储。” 指令只存在于对话中,从未被写入文件。当压缩被触发或开启新会话时,它便消失了。这就是 Summer Yue 遭遇的情况。迄今为止,这是最常见的原因。
失败模式 B:“压缩操作改变了上下文内容。” 长时间会话会触发令牌限制。压缩操作对旧消息进行了归纳处理。这种操作存在信息损耗,会丢失细节、一些微妙差别和特定的约束条件。代理现在根据归纳结果运行,而非你最初提供的指令。
失败模式 C:“会话修剪了工具结果。” 会话会修剪工具的输出(文件读取、浏览器返回的结果、API 响应)以优化缓存。代理“忘记”了工具之前返回的内容。这是临时性的,磁盘上的记录没有变。但是模型无法看到工具先前响应这个请求的输出。
快速诊断:
忘记了偏好设置?可能从未写入 MEMORY.md 文件(失败模式 A)
忘记了工具返回的内容?可能是修剪(失败模式 C)
忘记了整个对话?压缩或会话重置(失败模式 B)
压缩与修剪
大多数指南和大部分用户都混淆了压缩和修剪。它们是完全不同的系统。

压缩将整个对话历史总结为一段紧凑的摘要,改变了模型未来会看到的内容。该操作会在上下文窗口被填满时触发。它会影响一切,包括用户消息、助手消息、工具调用。它是反应性的,当溢出即将发生时触发,而不是提前。压缩操作有损,是永久性的。
修剪仅在内存中修剪旧工具结果,仅针对单个请求,不会触及磁盘上的会话历史记录。它只影响 toolResult 消息;用户和助手消息不会被修改。它不会触及工具结果中的图像。修剪操作无损,是临时性的。
修剪是朋友。它能减少膨胀,而且不会破坏对话上下文。压缩是危险的,因为它会改变模型看到的内容。
修剪默认是“关闭”的,但更明智的默认设置是为所有 Anthropic 配置文件自动启用 cache-ttl 模式。如果你使用的是 Claude,它可能已经打开了。你可以在配置中验证并调整 TTL:
{ "agents": { "defaults": { "contextPruning": { "mode": "cache-ttl", "ttl": "5m" } } }}证明你的代理看到了什么
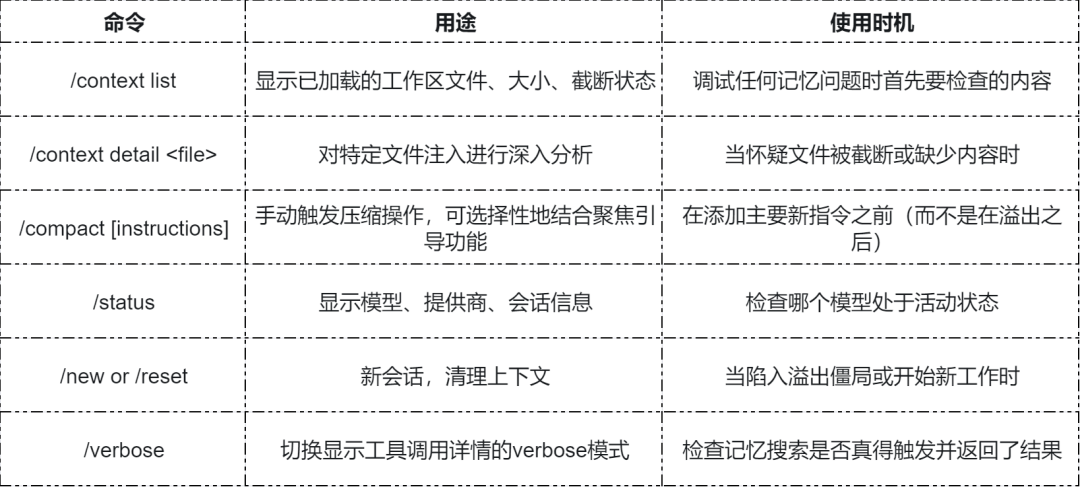
在更改任何配置之前,在 OpenClaw 会话中运行 /context list。这是诊断为什么记忆“未能保持”的最快方法。
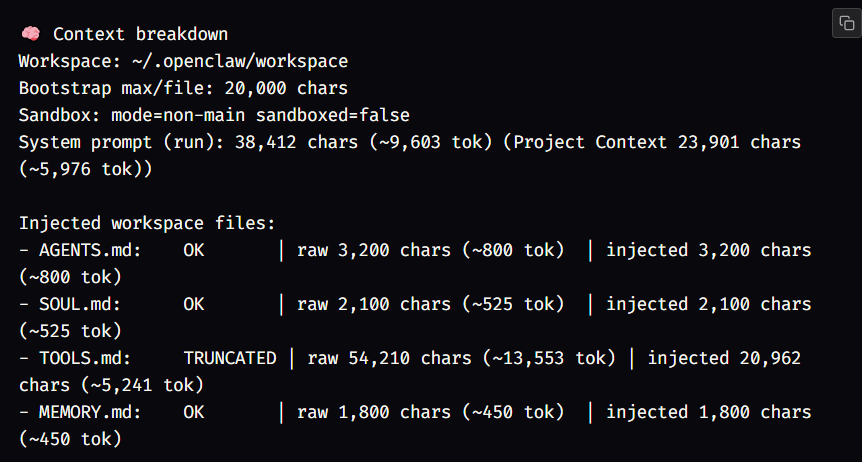
需要检查的内容:
MEMORY.md 是否加载? 如果显示“缺失”或未列出,就表示该文件不在上下文中。
是否有什么东西被截断? 超过 2 万个字符的文件会按文件截断。所有引导文件的总字符数最多为 15 万个字符。
注入的字符是否和原始字符一样? 如果不是,说明内容被截断。
如果文件被截断,则调整配置中的字符数限制。每个文件的字符数限制为 bootstrapMaxChars(默认 20000)。总字符数限制为 bootstrapTotalMaxChars(默认 150000)。这两个参数是字符数量,而不是令牌数量——150000 个字符大约是 50K 令牌。
如果文件不在上下文中,对代理就没有影响。在诊断其他任何问题之前,请务必先检查 /context list。
压缩实际做了什么
压缩生命周期
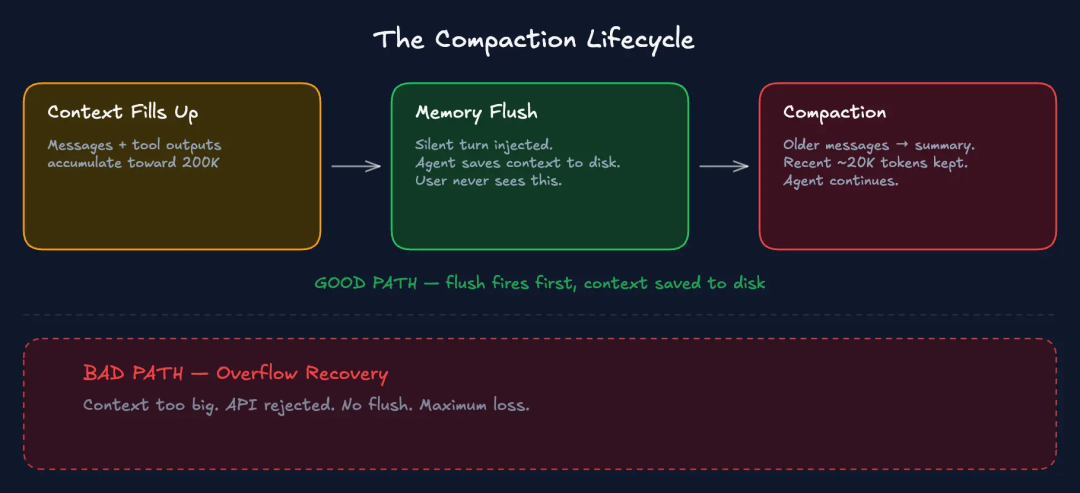
如果你的上下文被消息和工具输出填满,接近设定的最大值,接下来会发生什么:
好路径:维护压缩。 上下文接近限值,预压缩记忆刷新首先启动。在压缩开始前,代理会自动将重要的上下文信息保存到磁盘。你看不到这个过程。然后,压缩操作会总结以前的对话历史。代理后续会使用这个摘要、用户最近发送的消息以及磁盘上的内容。
坏路径:溢出恢复。 上下文变得太大,API 拒绝了请求。现在 OpenClaw 处于损害控制状态。为了能继续工作,它会一次性压缩所有内容。不会刷新记忆,不会预先将重要内容保存到磁盘。上下文丢失最大化。
下面显示的余量配置旨在使压缩操作保持在好路径上。
压缩破坏了什么
以下内容会在压缩操作中丢失:
嵌入在对话中的指令(头号杀手)
在会话中给出的偏好、更正和决策
压缩操作前共享的所有图像(按设计,代理后续看不到它们)
工具结果和它们的上下文
原指令的一些细微之处和特异性(摘要存在信息损耗)
以下内容不会在压缩操作中丢失:
所有工作区文件:SOUL.md、AGENTS.md、USER.md、MEMORY.md、TOOLS.md
每日记忆日志(通过搜索按需获取,不重新注入)
代理在压缩操作发生前写入磁盘的任何内容
压缩不会涉及你最近的消息,大约最后 20000 个 Token 会保持完整。即使在摘要中,文件路径和 ID 也会被保留。
如果你的系统出现任何异常,请运行 openclaw --version 命令。2026 年 2 月下旬,我们修复了若干与压缩操作相关的漏洞,请确保你使用的是 v2026.2.23 或更高版本。
关于 OpenClaw 的记忆,最重要的原则是:如果没有写入文件,就不存在。
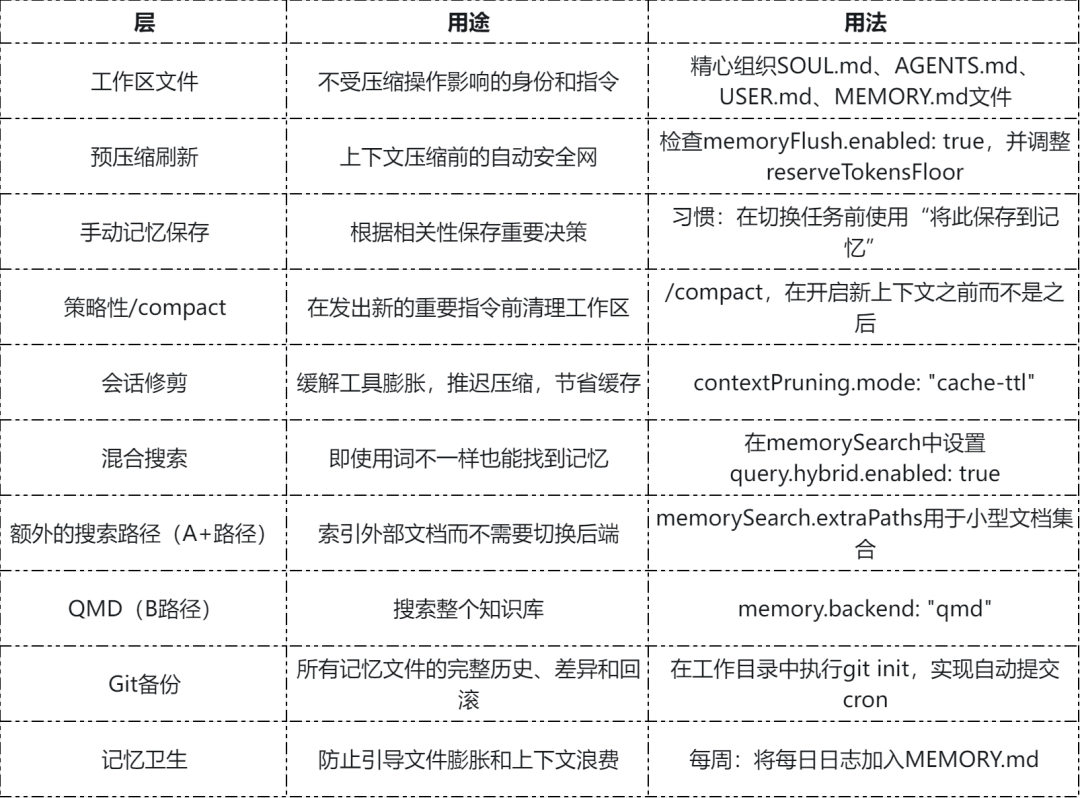
三层防御
单靠任何一种机制都不够,你需要三者协同运作。
第一层:压缩前记忆刷新
这是你可以做出的最有用的配置更改。
OpenClaw 内置了压缩前记忆刷新功能。在压缩前,它会触发一个静默的“代理轮次”,提醒模型将任何重要的内容写入磁盘。多数用户并未意识到该机制的存在,也未验证它是否已经启用,且由于默认阈值的设置过严,许多时候意外禁用了该功能。
配置如下。不要凭记忆输入,直接复制下面的代码块。重要的是要理解每个值的设置。
{ "agents": { "defaults": { "compaction": { "reserveTokensFloor": 40000, "memoryFlush": { "enabled": true, "softThresholdTokens": 4000, "systemPrompt": "Session nearing compaction. Store durable memories now.", "prompt": "Write any lasting notes to memory/YYYY-MM-DD.md; reply with NO_REPLY if nothing to store." } } } }}reserveTokensFloor: 40000 —— 这是预留空间。你希望为记忆刷新轮次和压缩摘要保留足够的空间,避免触发溢出。刷新在上下文窗口减去预留底限减去软阈值时触发。当上下文最大值为 200K,在这个配置下,是在 200000-40000-4000=156000 个令牌时触发。默认预留是 20K,这通常太少了。一个大型工具的输出可能会跳过该阈值,使刷新没有机会运行。在实践中,40K 是一个起步值。如果你很少使用大型工具,则可以设置的低一些。如果你经常读取大型文件或网页快照,则务必要增加这个值。
memoryFlush.enabled: true —— 在最近的版本中应该是默认开启了,但你还是应该检查下你的配置。当上下文越过软阈值时,OpenClaw 会插入一个静默轮次,说“现在保存你的重要上下文”。代理会将其写入记忆文件,然后继续压缩。用户永远不会看到这个轮次。NO_REPLY 令牌抑制了响应。
softThresholdTokens: 4000 —— 距离预留底限多远时触发刷新。默认是 4000,在大多数情况下已经够用。
自动刷新是一个安全网,而不是一种保证。代理可能无法保存所有重要的内容,令牌估计可能在一个大型轮次中跳过设置的阈值。这就是其他两层存在的原因。
第二层:手动记忆管理
虽然有自动刷新机制,但经验丰富的 OpenClaw 用户会通过手动保存来补充这一机制。这是一个简单的习惯,可以捕捉自动刷新遗漏的内容。
在切换任务之前,在给出复杂的新指令之前,或者当你刚刚做出重要决定时,告诉代理:
将此保存到 MEMORY.md或:
将今天的关键决定写入记忆文件/compact 命令值得一学。大多数人认为压缩是应该避免的事,但根据你的情况进行手动压缩则不同。

以下是该命令的用法:
告诉代理将当前上下文保存到记忆文件。
发送 /compact 手动触发压缩。
然后给出新指令。
新指令会落在压缩后的新上下文中,它们有最大的生命周期。当下一次压缩来临时,它们不会是第一个因为生成摘要而损失掉的内容。
你甚至可以告诉代理压缩时的优先考虑事项:
/compact 关注决策与开放性问题这可以指示摘要生成器保留最相关的细节。
注意:如果等到“上下文溢出”,则可能会陷入 /compact 也失败的境地。上下文太满了,即使是压缩请求也会溢出。那时,你唯一的选择是 /new 或 CLI 恢复。不要等待,主动压缩。
为什么既需要手动又需要自动?自动刷新是在达到令牌阈值时触发。它是基于时间的,不是基于相关性。手动保存是基于相关性的:你知道什么时候发生了重要的事情。它们一起涵盖了这两种情况。
第三层:文件架构
这里是一切汇聚之地。
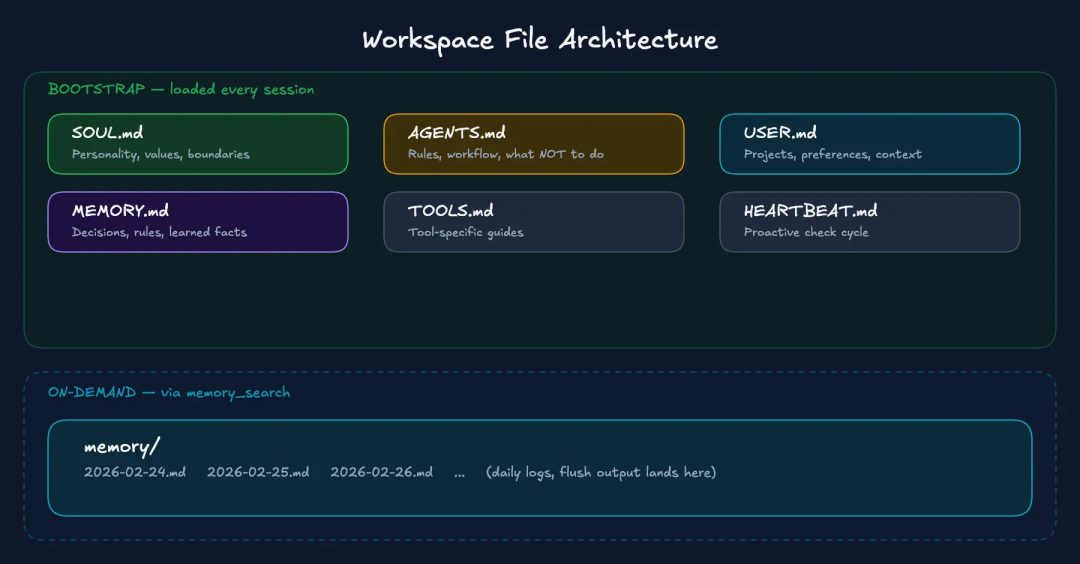
工作区分为两类。
引导文件(SOUL.md, AGENTS.md, USER.md, IDENTITY.md, TOOLS.md, MEMORY.md, HEARTBEAT.md, BOOTSTRAP.md)在每个会话开始时加载到上下文中。压缩对它们没有影响,因为它们在每个轮次中都从磁盘重新加载。
记忆目录 包含每日日志(memory/YYYY-MM-DD.md)。这些文件并非是通过引导程序注入的。通常,记忆系统会自动读取今日数据与昨日数据,其余数据均通过 memory_search/memory_get 按需调用。它们不计入引导程序截断限制。
子代理会话仅注入 AGENTS.md 和 TOOLS.md,其他引导文件会被过滤掉。如果你创建子代理后发现它们未继承你的个性或偏好设置,原因正在于此。
以下是各文件的作用:
SOUL.md —— 说明代理是谁(沟通语气、个性、情感风格,道德界限以及代理与你的关系)。最重要的是要记住:SOUL.md 是身份,不是安全措施。LLM 可能会被社会工程学手段诱导泄露信息。要实现真正的安全防护,请在基础设施层面采取控制措施:工具权限管理、工作区隔离、allowFrom 列表。
AGENTS.md —— 说明代理如何操作(工作流规则和决策框架、工具使用约定以及响应长度指南)。最有用的部分:不要做什么。当代理犯了你不希望重复的错误时,可以在这里添加规则。
如果你在团队的 Discord 或 Slack 频道中运行 OpenClaw,请将其添加到你的 AGENTS.md 中,否则代理会回复团队发布的每个表情:
## 群聊规则
- 仅在以下情况下回应:直接被提及、直接被提问,或者你有真正有用的信息
- 不要回应:旁白对话、打趣、他人之间的后勤协调、问候、链接分享
- 如果有疑问 -> 仅回应:NO_REPLY
- NO_REPLY 必须是你的整个消息,没有其他内容
USER.md —— 你是谁(你的项目、客户、当前优先事项、沟通偏好、关键人物和关系、技术环境细节)。
MEMORY.md —— 在每次会话中都应保持不变的内容(你做出的决策及依据、代理学到的偏好、从过去错误中学到的规则)。保持简短,不超过 100 行。这不是日记,而是速查表。
每日日志(memory/YYYY-MM-DD.md) —— 你每天工作的上下文(今天发生了什么、对话中做出的决策、活跃任务及其状态)。预压缩刷新输出会自动写到这里。
现在,使所有这些内容生效——记忆协议。将以下内容添加到你的 AGENTS.md 中:
## 记忆协议
- 在回答有关过去工作的问题之前:先搜索记忆
- 在开始任何新任务之前:检查今天的记忆以获取活跃上下文
- 当你学到重要的东西时:立即将其写入相应的文件
- 当你纠正一个错误时:将更正作为规则添加到 MEMORY.md
- 当会话结束或上下文很大时:总结并写入 memory/YYYY-MM-DD.md
没有这个规则,代理会根据上下文回答。有了它,代理会先查找信息。
记忆卫生。 几个月后,每日日志不断累积,MEMORY.md 文件膨胀。务请谨记初始化截断限制。处理方法如下:
每日:追加到每日日志,这是自动的。
每周:将每日日志中的持久规则和决策记录到 MEMORY.md 文件中。你可以为此设置每周 cron 作业。
保持 MEMORY.md 简短。任何不需要在每次会话中都出现的内容都可以放在每日日志中。代理需要时会通过搜索找到它。
你可能想要备份代理的记忆。在工作区目录中运行 git init,设置通过每日 cron 或心跳自动提交。只是确保~/.openclaw/credentials/ 和 openclaw.json 不会进入存储库,其中包含认证令牌和 API 密钥。
检 索
如果代理无法在记忆文件中找到需要的信息,那么记忆文件就毫无用处。
两个记忆访问工具
OpenClaw 提供了两个记忆访问工具:
memory_search —— 在记忆文件中搜索,包括 MEMORY.md、每日日志、记忆目录中的所有内容。默认情况下,它使用关键词和基于语义的匹配,所以即使你写的是“我们选择了 29 美元的层级”,它也能找到“定价决策”。
memory_get —— 按文件和行范围进行定向读取。如果文件不存在,则优雅地返回空文本。当你确切地知道哪个文件包含什么信息时使用这个工具。
将这个检索前置规则添加到你的 AGENTS.md 文件中:
## 检索协议
在进行重要的工作之前:
1. memory_search 项目/主题/用户偏好
2. 如果需要,用 memory_get 获取引用的文件块
3. 然后继续执行任务
没有这个,代理会猜测。有了它,代理会先检查它的记录。
A 路径:内置搜索
默认设置,最简单,我们从这里开始。
内置系统自动索引 MEMORY.md 文件和记忆目录中的所有内容。它监视文件更改并重建索引。不需要额外安装。
{ "agents": { "defaults": { "memorySearch": { "enabled": true, "provider": "local", "local": { "modelPath": "hf:ggml-org/embeddinggemma-300m-qat-q8_0-GGUF/embeddinggemma-300m-qat-Q8_0.gguf" }, "query": { "hybrid": { "enabled": true, "vectorWeight": 0.7, "textWeight": 0.3 } }, "cache": { "enabled": true } } } }}“混合搜索”意味着两种匹配策略协同工作。关键词搜索可以找到确切的词:搜索“定价”,它会找到包含“定价”的文件。嵌入式搜索会将文本转换为数字,捕捉句子的含义,而不仅仅是它们使用的词,所以“定价决策”和“我们选择了 29 美元的层级”在意义上是接近的。
A 路径会在你的计算机上运行一个小型嵌入式模型,免费使用,除了首次下载外无需其他任何设置。该方案为你提供了基于关键词和语义的混合搜索。对于大多数用户来说,这已经足够了。
A+ 路径:extraPaths
在切换到其他后端之前,你需要知道的是,内置搜索支持索引工作区之外的其他 Markdown 文件。将 extraPaths 添加到你的配置中,并指向你的项目文件夹、记录目录等。同样的混合搜索,无需额外安装。
{ "agents": { "defaults": { "memorySearch": { "enabled": true, "provider": "local", "extraPaths": [ "~/Documents/Obsidian/ProjectNotes/**/*.md", "~/Documents/specs/**/*.md" ] } } }}当你需要搜索大型库(数千个文件)、过去的会话记录或多个独立的集合时,可以升级到路径 B。
B 路径:QMD

QMD(查询 Markdown 文档)是一个实验性的记忆后端,可以取代内置的索引器。当你需要搜索工作区之外的内容时,例如你的 Obsidian 库、项目文档、会议记录、过去的会话记录。
路径 A 是代理检查自己的日记。路径 B 是代理搜索你所有的文件。免费使用,本地运行。
{ "memory": { "backend": "qmd", "qmd": { "searchMode": "search", "includeDefaultMemory": true, "sessions": { "enabled": true }, "paths": [ { "name": "obsidian", "path": "~/Documents/Obsidian", "pattern": "**/*.md" } ] } }}在默认情况下,OpenClaw 的 memory_search 使用 QMD 的 BM25 关键词模式。速度快,亚秒级响应,无需 ML 模型,没有冷启动风险。这里所做的让步是:如果你将“API 定价决策”存储为“我们选择了 29 美元 / 月的层级”,它就找不到“API 定价决策”。如果你不希望那样,就需要启用语义搜索模式。该模式会加载 ML 模型,首次使用时需要的时间比较长。开始时使用关键词模式,如果需要,再升级。
QMD 默认为 DM-only 范围。如果你是在群组频道中运行 OpenClaw,并且 memory_search 看上去被禁用了,请检查是否需要更新你配置的 QMD 范围。
QMD 返回相关的片段,而不是整个文件。代理不会为了找到一句话而将 50 页的文档全部加载到上下文中,这有助于避免触发压缩。
成本和缓存
你发送的每条消息都包含完整的系统提示和对话历史。提示缓存意味着你为那些重复的 Token 支付的费用减少了大约 90%,但压缩会使缓存失效。压缩后的下一个请求需要支付全额费用以重新缓存所有内容。
每次不必要的压缩都是一个可靠性问题和一个成本问题。
有两件事会破坏缓存:
压缩会重写对话历史,使一切失效。
每个回合都变化的易失性系统提示输入会破坏缓存。
这也是为什么保持工作区文件稳定和 MEMORY.md 小巧而不是不断重写它的另一个原因。
在 cache-ttl 模式下进行会话修剪,可在强制执行压缩前缓解工具臃肿。配置成本不高,却能显著提升缓存命中率。
故障排除
本节是常见问题及其解决方法。每个问题都包括一个你可以直接粘贴到 OpenClaw 会话中的提示。
“我的代理不记得我的偏好”
偏好是否写入了 MEMORY.md 文件?如果它只存在于对话中,就不是持久的。运行 /context list 看看 MEMORY.md 是否真的加载了?它是否被截断了?AGENTS.md 是否设置了记忆协议?在群组上下文中,MEMORY.md 按设计是不加载的,它只在主会话中加载。
运行 /context list 并检查 MEMORY.md 是否已经加载。如果它缺失或被截断,请告诉我。然后检查我的 [偏好描述] 是否已经写入 MEMORY.md 或任何记忆文件中。如果没有,请现在将其添加到 MEMORY.md 中。
“memory_search 无返回或似乎被禁用”
运行 /context list 并检查你的记忆文件实际是否存在。如果文件不存在,则意味着没有东西可供搜索。如果文件存在,则问题通常出在嵌入式模型上——本地模型首次使用时需要下载。如果下载失败,则搜索功能将无法正常工作。
运行 /context list 并告诉我:是否有任何记忆文件被加载?然后尝试用 memory_search 搜索’test’并告诉我结果。如果搜索失败,请检查是否存在本地嵌入式模型,并报告任何错误。
“它不记得浏览器或工具说了什么”
那是会话修剪,不是压缩。工具结果在缓存 TTL 后被清除。磁盘上的记录没问题;模型只是无法在当前请求中看到旧工具输出。将重要的工具输出写入记忆文件,或重新运行工具。
本会话中早期的工具结果消失了。在重新运行任何东西之前,将重要工具输出的摘要写入今天的每日记忆日志,这样我们就不会再次丢失它们。然后重新运行 [工具 / 命令] 获取新的结果。
“压缩发生得太晚,我收到了溢出错误”
不要等到溢出。在事情变得严重之前主动使用 /compact 进行压缩。提高 reserveTokensFloor 以便更早地触发压缩。如果卡在溢出死锁中,甚至无法运行 /compact,请使用 /new 重置,或通过 openclaw sessions CLI 恢复。
现在就将本会话的所有重要内容保存到今天的记忆日志中,包括决策、上下文、活动任务。然后我将运行 /compact 以清理空间。
“预压缩记忆刷新没有运行”
如果一个轮次导致 Token 数据大幅越过软阈值,就会绕过刷新。检查你的配置,看看该功能是否启用。提高 reserveTokensFloor 的值,增加缓冲。请将其视为尽力而为的机制,并手动建立保存点作为备份。
在我们继续之前,将本会话中所有重要的上下文保存到今天的记忆日志中:所做的决策、活动任务、上下文丢失时你需要恢复的任何内容。现在就做,作为手动保存点。
“我的代理在长时间会话后忘记了它的工具”
已知问题,尤其是长时间运行的 Discord 会话。压缩操作生成的摘要可能会丢失工具上下文。修复方法:使用 /new 重置会话。如果有适当的记忆文件,代理就可以从中断处继续进行。模型选择也很重要;更智能的模型能更好地处理压缩摘要。
检查你的记忆文件,看看我们正在做什么。在记忆文件中搜索 [主题 / 任务]。从对话中断的地方继续。
“我的代理一夜之间忘记了一切”
会话在每日重置时获得新的会话 ID(默认为当地时间凌晨 4:00)。这本质上是一个新的会话。只有引导文件和可搜索的记忆会延续。这种行为符合预期,不是错误。这就是为什么写入记忆文件很重要:每日重置由类似压缩的事件来保证。
搜索你的记忆文件,了解昨天的活动。我们当时在处理什么?做出了哪些决策?哪些事项尚未解决?请进行总结然后继续。
完整配置
两个配置块。请选择你的路径。
A 路径:内置记忆搜索
无需额外安装。压缩配置的保留底限为 40000,启用记忆刷新,使用 embeddinggemma 模型的本地混合搜索,以及 cache-ttl 修剪。复制并粘贴此内容。
{ "agents": { "defaults": { "compaction": { "reserveTokensFloor": 40000, "memoryFlush": { "enabled": true, "softThresholdTokens": 4000, "systemPrompt": "Session nearing compaction. Store durable memories now.", "prompt": "Write any lasting notes to memory/YYYY-MM-DD.md; reply with NO_REPLY if nothing to store." } }, "memorySearch": { "enabled": true, "provider": "local", "local": { "modelPath": "hf:ggml-org/embeddinggemma-300m-qat-q8_0-GGUF/embeddinggemma-300m-qat-Q8_0.gguf" }, "query": { "hybrid": { "enabled": true, "vectorWeight": 0.7, "textWeight": 0.3 } }, "cache": { "enabled": true } }, "contextPruning": { "mode": "cache-ttl", "ttl": "5m" } } }}B 路径:QMD 后端
相同的压缩和修剪配置,但将内置搜索替换为 QMD。指向你的 Obsidian 库,启用会话索引,然后开始。
{ "agents": { "defaults": { "compaction": { "reserveTokensFloor": 40000, "memoryFlush": { "enabled": true, "softThresholdTokens": 4000, "systemPrompt": "Session nearing compaction. Store durable memories now.", "prompt": "Write any lasting notes to memory/YYYY-MM-DD.md; reply with NO_REPLY if nothing to store." } }, "contextPruning": { "mode": "cache-ttl", "ttl": "5m" } } }, "memory": { "backend": "qmd", "qmd": { "searchMode": "search", "includeDefaultMemory": true, "sessions": { "enabled": true }, "paths": [ { "name": "obsidian", "path": "~/Documents/Obsidian", "pattern": "**/*.md" } ] } }}从路径 A 开始,当需要搜索 Obsidian 库或过去的会话时,升级到路径 B。
深度防御概述
斜杠命令参考
相关链接
OpenClaw 记忆文档 (https://docs.openclaw.ai/concepts/memory)
Tobi Lutke 的 QMD(https://github.com/tobi/qmd)
原文链接:
https://velvetshark.com/openclaw-memory-masterclass
声明:本文最初发布于 VelvetShark,为 InfoQ 翻译,未经许可禁止转载。




