
模力工场新鲜事
模力工场秋季赛正式结束,榜单如下,恭喜各位上榜的同学!完整榜单见模力工场网页端或小程序端秋季赛区域,获奖同学奖励将在本月陆续发放,感谢大家对模力工场的支持!
12 月 6 日本周六下午,Vibe Coding Sprint · AI 编程闪电黑客松 将在阿里巴巴数字生态创新园(西溪 B 区)7 号楼 413 正式开跑。
模力工场携手 TGO 鲲鹏会,发出一份属于新一代 builder 的现场邀约:用 AI 写代码,用代码写公司。活动将以 3 小时极限 Vibe Coding 为核心,在真实场景中跑通一条 AI 工作流链路,鼓励每位参与者围绕现场发布主题,打磨一个 Demo。现场将评选出 3 个“模力工场 x 潜力之星 Demo ”获得惊喜奖励,优秀作品还将登上模力工场与 InfoQ 的舞台。诚挚邀请你走出屏幕、走进现场,让一时的灵感,长成一家公司。

022 周榜单总介绍
模力工场 第 022 周 AI 应用榜来啦!
本周 AGICamp 榜单,一头连着“AI 长记忆与基础设施”,一头连着“写作天团、职业路径和个人形象设计”。从为智能体提供持久记忆能力的 powermem,到面向 AI Native 搜索场景的 OceanBase seekdb,再到 FastGPT、通义灵码 这样的开发与 Agent 搭建平台,底层能力在加速夯实。另一方面,GetDraft 起稿、海螺 AI、Path.ai、梦想卡片、AI 换发型 等应用,则把写作、人生规划、形象管理这些“人的需求”包进 AI 工具里,呈现出一条清晰的路线:AI 不只帮你算,更要“懂你是谁、帮你写、替你想象未来的你”。
PowerMem 📍北京: 软件开发、AI Infra、产品插件类, Build Persistent Memory for AI Applications
灵光: 设计创意、工作效率、教育学习类, 让复杂,变简单
OceanBase seekdb 📍北京: AI Infra 类, The open source AI-Native Search Database
通义灵码:工作效率、软件开发、产品插件类, 由阿里云提供的智能编码辅助工具,提供代码智能生成、智能问答、多文件修改、编程智能体等能力,为开发者带来高效、流畅的编码
海螺AI:工作效率、社交社区、设计创意类, 每个想法都是一部大片——您的多模态智能创作伙伴
GetDraft 起稿 📍北京: 工作效率、教育学习、生活服务类, 懂你风格的 AI 写作天团,与你一起,将想法写成好文章。
Path.ai(pathtalk.cn) 📍杭州: 人力资源、教育学习、社交社区类, 理解你是谁,分析你能成为谁,最终帮你抵达那里
FastGPT 📍杭州: 工作效率、软件开发、产品插件类, 企业级 Agent 搭建平台
梦想卡片 📍北京: 设计创意、教育学习、生活服务类, 上传一张正面照片,说出你的梦想,我将为你生成一张梦想实现后的专属卡片!
AI换发型 📍北京: 设计创意、生活服务类, 如果妈妈允许,我想一天换一个发型,一周不重样,哈哈!
榜首应用开发者 Q&A
本周模力工场助手小 A 采访了榜一应用 的开发者,带来七个快问快答。
开发者自我介绍:我是来自 OceanBase 开源社区的一名开发工程师汤庆(花名:靖顺),也是OceanBase PowerMem 项目的研发之一。
OceanBase PowerMem 是什么:致力于解决 AI 应用中的记忆管理难题,让基于大语言模型的 AI 应用能够像人类一样持久化地"记住"历史对话、用户偏好和上下文信息。OceanBase seekdb 提供企业级的高性能向量存储和多模检索能力,当 OceanBase PowerMem 与 OceanBase seekdb 结合时,实现了 1+1>2 的协同价值,两者深度融合,为 AI 应用构建了既高效又智能的记忆基础设施。
OceanBase PowerMem 核心功能包括:
智能记忆管理:通过 LLM 自动从对话中提取关键事实,智能检测重复、更新冲突信息并合并相关记忆
艾宾浩斯遗忘曲线:基于认知科学的记忆遗忘规律,让 AI 系统像人类一样自然"遗忘"过时信息
多智能体支持:为每个智能体提供独立的记忆空间,支持跨智能体记忆共享和协作
混合检索架构:深度融合 OceanBase seekdb 的向量检索、全文搜索和多跳图检索,实现了更精准、更快速的多路召回。
多模态支持:支持文本、图像、语音等多种模态的记忆存储和检索
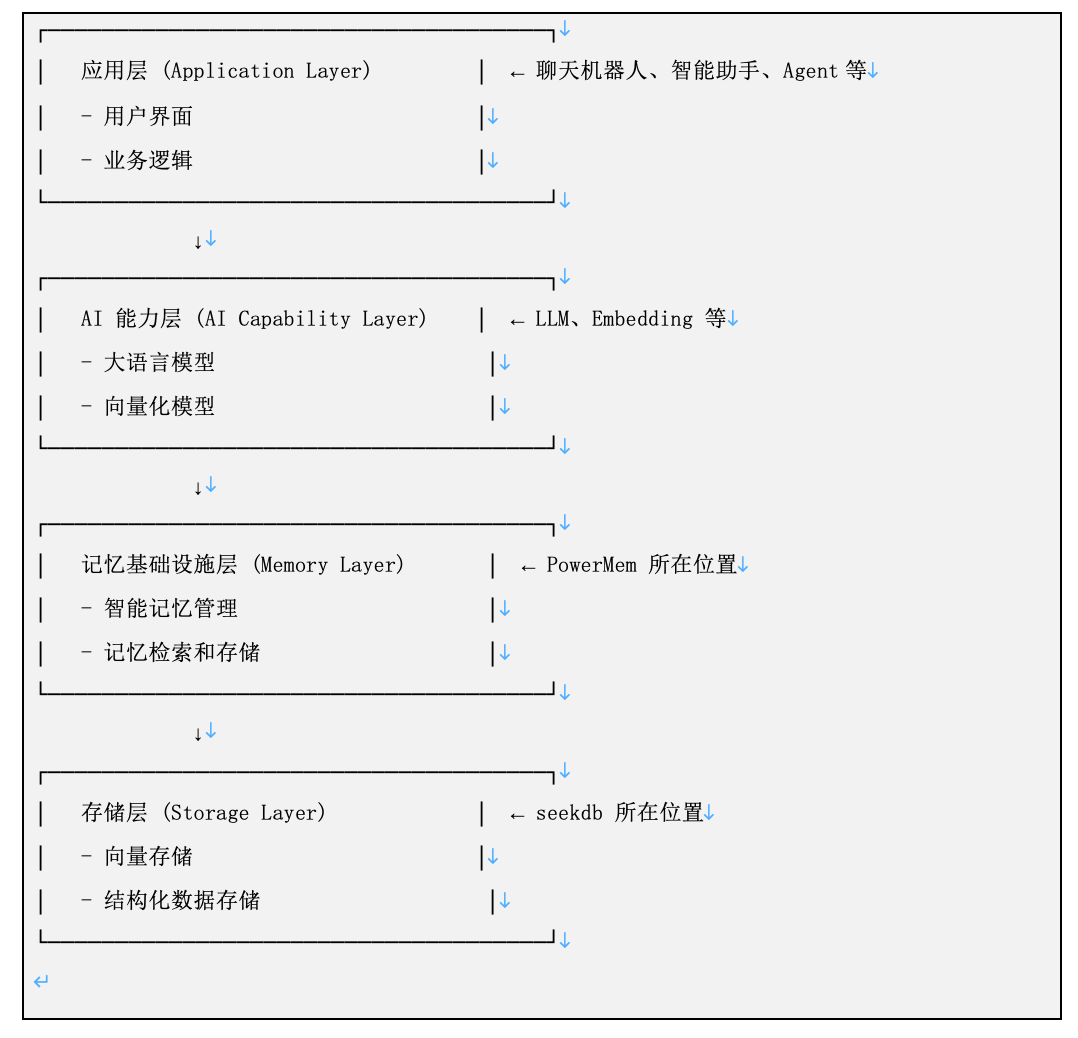
小 A:可以介绍一下 PowerMem 是在 AI 应用架构的哪一层吗?如何发挥它的最大价值?
靖顺:PowerMem 位于 AI 应用的基础设施层(Infrastructure Layer),具体来说是记忆基础设施层。在典型的 AI 应用架构中,可以这样理解:
小 A:请先介绍下"PowerMem"的起源:是什么契机、什么痛点促使你们启动这个项目?
靖顺:OceanBase PowerMem 的起源来自于我们在 AI 应用开发中遇到的核心痛点:
核心痛点:
上下文窗口限制:大语言模型的上下文窗口有限,无法直接存储所有历史对话,导致 AI 系统无法"记住"用户之前说过的话。
成本问题:即使使用更大的上下文窗口,将所有历史对话都传入模型会导致 Token 成本急剧上升,对于长期使用的应用来说成本不可控。
记忆质量:简单的向量检索虽然能召回相关信息,但缺乏智能去重、冲突检测和记忆合并能力,导致记忆库中存在大量重复和冲突信息。
多智能体场景缺失:现有的记忆系统大多只考虑单智能体场景,缺乏对多智能体协作的支持。
启动契机:从"存数据"到"理解数据",从"查询优化"到"上下文工程",从"事务处理"到"记忆管理"——这些看似不同的领域,底层逻辑都是如何高效地管理数据。而这,正是 OceanBase 的主场。于是我们决定基于 OceanBase seekdb (AI 原生数据库)的混合检索能力,构建一个既智能又简单易上手的记忆组件。
小 A:在技术角度,你们有没有做过对比实验:同一个 AI 助手,接入 PowerMem 前后,在留存、重复提问率、对话时长、用户满意度等指标上有什么变化?有没有可以分享的典型数据或案例?
靖顺:我们在 LOCOMO 基准测试中做了详细的对比实验,主要对比了 PowerMem 和 full-context(全上下文)方式:
性能指标对比:
准确率:PowerMem 78.70% VS full-context 52.9%,提升 48.77%
响应速度:PowerMem p95 延迟 1.44s VS full-context 17.12s,快 91.83%
Token 成本:PowerMem 0.9k tokens VS full-context 26k tokens,降低 96.53%
小 A:如果我是一个已经有聊天机器人或 Agent 产品的开发者,从 0 集成 PowerMem 到上线,大致会经历几个步骤?在你们的真实用户里,典型的接入周期大概多长?
靖顺:集成步骤(非常简单,只需 3 步):
1、安装和配置:

创建 .env 文件,配置 LLM、Embedding 和存储后端
2、代码集成:

3、测试和优化(根据项目复杂度,1-3 天):
测试记忆的准确性和相关性
根据业务场景调整检索参数
个性化提取策略,比如使用更加合适自身业务的提示词
4、典型接入周期:
简单场景(单用户、单智能体):1-2 天即可完成集成和测试
中等复杂度(多用户、多智能体):3-5 天,主要是配置和测试多智能体场景
复杂场景(大规模数据、自定义需求):2-3 周,需要定制化开发和性能优化
小 A:有没有收到用户反馈"这个功能不够用"或"这个功能很惊喜"?能分享一个典型案例吗?
靖顺:"很惊喜"的功能:
艾宾浩斯遗忘曲线:很多用户反馈这个功能让他们"眼前一亮"。一个典型反馈是:
"我们之前使用其他记忆系统时,总是担心记忆库会无限增长,导致检索变慢。PowerMem 的遗忘曲线功能让系统能够自动'遗忘'过时信息,这太符合我们的需求了。而且这个功能是基于认知科学的理论,让我们觉得这个系统很'智能'。"
这个功能让用户意识到,记忆系统不应该只是简单的存储,而应该像人类记忆一样有选择性地保留重要信息。
"不够用"的反馈:
多模态支持:一些用户希望支持更多模态,比如视频记忆。虽然我们已经支持文本、图像和音频,但视频的处理和检索确实是一个挑战。我们正在考虑如何处理视频的处理和存储。
小 A:产品上线后,最有效的用户获客方式是什么?你们主要依赖哪些渠道?
靖顺:最有效的获客方式:
开源社区:我们将 PowerMem 以 Apache 2.0 协议开源在 GitHub 上,通过技术社区的口碑传播获得了大量开发者关注。
合作伙伴生态:与主流 AI 框架(LangChain、LangGraph)等集成拓展生态。
主要渠道:
GitHub(开源仓库)
技术社区和论坛
AI 应用平台集成
技术会议和分享
小 A:技术上/业务上未来 12 个月你们最想解决或突破的三大目标是什么?
靖顺:技术目标:
基于情感陪伴的用户画像
在智能陪伴场景中,我们发现用户不仅需要 AI 记住事实,更需要 AI 理解他们的情感状态、性格特点、行为模式。我们计划在 PowerMem 上支持基于情感陪伴的用户画像功能,让 PowerMem 从"记住事实"升级到"理解人",真正实现智能陪伴。
多模态记忆的深度融合
虽然我们已经支持文本、图像、语音,但目前的处理还比较独立。我们计划实现:
跨模态关联理解:理解"用户发的照片"与"用户说的话"之间的关联,构建更丰富的上下文
记忆的视觉化检索:支持"用图片找记忆"、"用语音找记忆"等更自然的检索方式
实时记忆同步和多智能体协作优化
在多智能体场景中,我们发现记忆的实时同步和一致性保证是关键挑战。我们计划构建:
实时记忆同步机制:实现多智能体之间的实时记忆共享和同步
协作模式优化:基于智能体的协作模式,自动优化记忆的共享策略和权限控制
业务目标:
垂直领域深度优化:
针对医疗、金融、教育等垂直领域提供专门的优化
提供领域特定的记忆模板和最佳实践
建立行业解决方案库
开发者生态建设:
与更多 AI 框架和平台深度集成
建立开发者社区和贡献者计划
提供更丰富的示例和教程
来自上周榜一应用万象代码生成平台的问题:面对同类竞品的竞争,你们是怎么找到差异化优势的?有没有某个决策让应用脱颖而出?应用上线后,有没有出现过和预期完全不一样的用户使用场景?这让你们对产品有了什么新的认知?
靖顺:我们的差异化优势主要体现在三个方面:
混合存储架构:我们融合了向量检索、全文检索和图检索三种技术,而不是单一依赖向量检索。这使得系统能够在众多开源 AI 记忆产品中脱颖而出,在 LOCOMO 基准测试中达到了 SOTA 水准。
开发者友好的轻量级集成:我们提供了最简单的 Python SDK 以及 MCP 服务,让开发者能够在几分钟内完成集成,而不是需要复杂的配置和部署流程。
认知科学理论的应用:我们引入了艾宾浩斯遗忘曲线理论,这是其他记忆系统很少采用的。这让 AI 系统能够像人类一样自然"遗忘"过时信息,而不是简单地存储所有历史数据。这个决策让我们的系统在长期记忆管理上更加智能和高效。
发现了几个超出预期的使用场景:
智能陪伴场景:我们最初主要考虑的是功能性场景(如客服、医疗支持),但有用户反馈,他们想将 PowerMem 用于情感陪伴和长期关系建立的场景。记忆系统不仅要记住事实,更要理解情感和关系。我们意识到需要区分"重要的事实"和"重要的情感时刻",后者对陪伴场景至关重要。
多模态记忆的深度应用:用户会分享照片、语音消息,希望 AI 能够"看到"和"听到"他们的生活。这让我们意识到多模态记忆也是记忆中非常重要的一部分。
个性化程度的需求:每个用户都希望 AI 记住的是"属于他们"的独特记忆,而不是通用的模板。这促使我们加强了记忆的个性化提取和存储。
大规模数据的分区管理:一些企业用户需要管理超大规模的记忆数据,这促使我们开发了子存储(Sub Stores)功能,通过数据分区管理显著提升查询性能。
这些场景让我们认识到,记忆系统不仅仅是简单的存储和检索,更需要考虑业务场景的复杂性、数据规模的可扩展性,以及个性化的需求。
小 A:您最想将模力工场推荐给身边的谁?
我最想推荐给正在寻找好用 AI 应用的用户和产品经理:对于每天需要"发现好用的 AI 应用"的用户来说,模力工场就像中文版的 Product Hunt,通过榜单的形式帮助他们快速找到真正有价值的 AI 工具。特别是那些对 AI 应用感兴趣但不知道从哪里开始的用户,模力工场提供了一个很好的发现和筛选平台。对于产品经理来说,这里也是观察 AI 应用趋势、了解用户需求的好地方。
留给下周榜一应用开发者的问题:在构建 AI 应用时,如何在个性化定制与通用性之间找到平衡?你们是如何让产品既能满足不同用户的独特需求,又能保持核心功能的稳定性和可维护性的?
本周必试应用
应用名称:GetDraft 起稿
关键词:工作效率|教育学习|写作|生活服务
小 A 推荐:懂你文风的 AI 写作天团,接得住你所有“想写但没时间写完”的内容。不是单一助手,而是“写作天团”:用多个不同角色的智能体,把“列大纲—起稿—润色—风格统一”拆开做,适合长文、专栏、公众号、课程稿、活动复盘等场景。重视“你的个人风格”:可以通过历史文章/素材训练,让模型更贴近你的语气,而不是千篇一律的“AI 腔”。
上榜冷门但有趣的应用
应用名称:梦想卡片
关键词:设计创意|教育学习|生活服务
小 A 推荐:梦想卡片能帮你把“立 Flag”具象化,你不只是说“我要当建筑师”,而是能看到未来某个版本的自己——穿着怎样的衣服、在什么场景、是什么气质,将 Flag 变成具体可感的照片。
本周上榜应用趋势解读
本周模力工场榜单的关键词是——“持久记忆”
PowerMem把“持久记忆”从概念落到可用 Infra,与 OceanBase seekdb 这类 AI 基础设施一起,构成了智能体时代的新地基——谁先把记忆、检索、工作流打通,谁就更有机会成为下一代应用平台。在应用层,通义灵码继续加固“开发者日常工作流”的阵地,而 GetDraft 起稿、海螺 AI则指向一个更具体的现实:写作与内容创作正在被重新分工——人给方向和判断,AI 负责铺陈与成稿。Path.ai、梦想卡片、AI 换发型这组应用,则从“职业决策、人生愿景、个人形象”三个角度,把 AI 拉进每个人的自我认知与自我设计过程。
最后再介绍一下模力工场的上榜机制和加入榜单的参与方式,欢迎大家继续积极参与提交 AI 应用:
模力工场AI 应用榜并非依靠“点赞刷榜”,而是参考以下权重维度:
评论数(核心指标,代表社区真实反馈)
收藏与点赞(次级指标)
推荐人贡献(注册推荐人可直接为好应用打 Call)
加入榜单的参与方式:
如果你是开发者:上传你的 AI 应用,描述使用场景与核心亮点;
如果你是推荐人:发现好工具,发布推荐理由;
如果你是用户:关注榜单,评论互动,影响榜单权重,贡献真实声音。
One More Thing,对于所有在模力工场上发布的 AI 应用,极客邦科技会借助旗下各品牌资源进行传播,短时间内触达千万级技术决策者与开发者、AI 用户:
InfoQ 全媒体矩阵
AI 前线全媒体矩阵
极客时间全媒体矩阵
TGO 鲲鹏会全媒体矩阵
霍太稳视频号




