
本文是数据库内核系列文章之一。
上一期介绍了执行器的两种主流的实现来提升性能:code-gen(代码生成)和 vec-exec(向量计算)。这期的内容,介绍一个实现了 vec-exec 的商用数据仓库系统,Snowflake。除了使用了 vec-exec(毕竟,联合创始人 Marcin 的博士毕业论文就是关于 vec-exec 的),Snowflake 也是一款 100%计算和存储分离,面向云原生的数据仓库系统(是不是第一个我不敢确认,还请大家查证,留言给我)。本文内容主要参考他们发表于 SIGMOD-16 的 paper: The Snowflake Elastic Data Warehouse。
Snowlake 是 2012 年成立的,2015 年正式推出商用版本。2012 年,正是云服务起步不久,大数据热火朝天的时候。当时,数据仓库的主流趋势是 SQL On Hadoop。Cloudera, Hontornworks, MapR, Greenplum HAWQ, Facebook 的 Presto,算是百花齐放。但主创团队认为,RDBMS 不会消失,用户们会因为上云的趋势,想要一款完全适配云端的数据仓库。
简介
文章简单介绍了市面上通常的 on-prem 分布式数据仓库的一些缺点。首先就是计算和存储硬件是耦合的,即每个服务器同时负责存储数据,并且执行 SQL 语句得到结果。耦合的劣势在于,不能针对不同的 workloads 做优化。二就是服务器的 node membership 改变(无论是因为服务器损坏,或者是因为数据量提升需要扩容)对用户来说都不友善。一,就是要进行大量数据的 reshuffle。二是,为了做到高可用,可能会保留一部分 node 作为 stand-by replica,当主节点有问题时,马上接替主节点,这相当于变相提高了数据成本。总结来说,on-prem 的数据仓库要做到同时保持可伸缩性(elasticity)和高可用性(availability)并兼顾成本,是很难鱼与熊掌兼得的。三就是对服务进行升级比较麻烦。
由于云服务的出现,很多上述的问题,变得不再是问题了。一就是,云服务通常会提供多种类型的服务器来针对特定的 usecase;二,服务器的下线,上线,扩容在云服务上都属于基本操作;三是,云上有高可用,低成本的存储系统;四是,服务更新非常方便。基于这些原因,Snowflake 选择了完完全全的计算和存储分离的架构设计。整个架构分成三个大模块:
1)数据存储:完全交给 AWS 的 S3 来存储数据。
2)Virtual Warehouse(VW) 虚拟数据仓库实例(下面简称 VW):由多个 Virtual Node(AWS 中的 EC2 instance)组成的一个 Virtual Cluster,负责执行各种 SQL 语句,因此称为 Virtual Warehouse。数据库的执行引擎是也是自己构建的分布式引擎。
3)Cloud Services:整个 Snowflake 的大脑:负责管理数据存储和 VW,以及其他一系列的操作,比如安全,登陆,事物管理,用户隔离,等等。值得注意的是,你可以大致认为整个 AWS,所有的用户,共享这一个大脑实例(当然,这个实例本身是多中心复制,高可用加高备份的),但每个用户只能管理属于自己的数据和 VW。
数据存储
在设计存储系统的时候,Snowflake 有纠结过,是应该使用 AWS 的 S3,还是自行设计类似于 HDFS 的存储系统。最终,在经过了各种比较,利弊权衡后,决定使用 S3。虽然,S3 的性能并不是最快;并且,由于是网络接入,也不是最稳定。但是,胜在高可用性和高可靠性上。团队决定基于 S3 打造数据存储系统,同时,可以把精力放在优化 local caching 和数据倾斜(skew resilience)上。
相对于本地文件系统,S3 的 access latency 会更高,并且,由于是网络接入(尤其是用 https),CPU 使用率也更高。而且,S3 本身就是一个简单的 blob 存储,支持的主要创建,删除和读取文件,即,不能对现有文件进行更新,更新相当于重新创建一个更新过的文件。但是,S3 的读取有一大好处在于,可以读取部分文件。
S3 的这些属性,对于整个 Snowflake 的数据存储和并行控制设计有重大的影响。首先,表数据被水平(horizontally partitioned)地切分成多个不可变的 blob 文件;每个文件通过列存(column-store)的形式保存数据,Snowflake 具体使用的存储格式是 PAX 的 Hybrid-column store(挖个坑,可以单独讲一期这个)。每个数据文件包含数据头用来存储元数据。基于 S3 的下载部分文件的 API,对于运行的 SQL 语句,优化器会选择只下载必须用到的数据 block 即可。
值得一提的是,Snowflake 不单单使用 S3 来存储表数据文件,也用 S3 来存储临时生成的 intermediate result(语句执行中,某个 operator 产生的临时结果集)。一旦这些结果集的大小超过了本地磁盘空间,spill 到磁盘上的文件就会以 S3 的形式存储。这样的好处在于,可以让 Snowflake 真正可以处理巨大的数据而不用担心内存或者本地磁盘空间吃紧。另一个好处在于,这些临时结果集也可能被利用作为 cache 使用。
最后文中还提到了数据库的其他元数据存储,包括有哪些 caching 文件,每个表存在了哪些 S3 文件中,等等,都是存储在一个 transactional 的 key-value store 中,并不在 S3 里。
虚拟数据仓库实例(Virtual Warehouse)
VW 就是一个由多个 EC2 instance(文中称这些 instance 为 worker node,以下简称 WN)组成的的分布式数据库实例。并且,可以根据 workload 的需求,选择不同的体量(Snowflake 提到是用 T-shirt size 来划分,从 X-S 到 XX-L)。VW 本身单单是作为计算引擎存在,是无状态的,所有的数据文件都在 S3 上,所有的 metadata 都在 key-values 上。因此,Snowflake 建议,如果没有查询语句,可以把 VW 给关了,来节省成本。
执行 SQL 语句:每个语句 instance 都只会运行在一个 VW 上;每个 VW 有多个 WN;每个 WN 只隶属于一个 VW,不会被共享。(这边有注解说,WN 变成共享的会是一个未来的工作,因为可以更好地提升使用率并且会进一步降低用户成本)。当一个语句被运行时,所有的 WN 在这个 VW 上,(或者也可能是一部分 WN,如果优化器认为这是一个非常轻量级的语句),都会起一个 worker process,这个进程的生命周期就是这句语句的执行周期。worker process ,在执行的过程中,不会对外部资源造成任何变化,换言之,no side effect,即使是 update 语句。为什么这么说呢,因为所有的表数据文件都是 immutable 的。这样带来的好处就是,如果 worker process 由于各种原因崩溃了, 通常只是需要 retry 即可,没有其他善后事宜要做。现在 VW 里还不支持 partial retry,这也在未来计划的工作中。
每个用户可以同时拥有几个 VW 实例,并且这些 VW 还分别同时运行多个语句。VW 通过 S3 共享数据文件。这里 S3 的优势就体现出来了,几乎无限的存储空间,使得用户可以查询,整合所有的数据。同时,用户可以通过构建多个 VW 的形式,对不同类型的语句进行分类,使得彼此之间互相不会影响。
由于 VW 的可伸缩性(elasticity),通常情况下,可以通过起一个更大 size 的 VW 来提升语句的性能,但保持一样的使用成本。例如, 一个复杂的分析语句在一个 4 节点 VW 上需要运行 15 个小时,但在一个 32 节点 VW 上只需要 2 小时。因为是云原生,用户只需要支付运行 VW 时的费用即可。因此,在价格不变的情况下,用户体验和查询速度却大幅度提升。这也是 Snowflake 云原生数据仓库的一大卖点。
本地缓存: 每个 WN 都会用本地文件为表数据做本地缓存,即已经被从 S3 那读取的数据文件。这些文件是包含元数据信息和要用到的 column 的数据。这些缓存的数据文件可以被多个 worker process 共享(如果需要读取一样的数据),文中提到维护了一个简单的 LRU 的 cache replacement 策略,效果非常不错。为了进一步提升 hit rate,同一份数据文件被多个 WN 节点保存,优化器会用 consistent hashing 算法,来分配哪些节点保存哪些数据。同时,对于后续要读取对应数据的语句,优化器也会根据这个分配发送到对应节点。
数据倾斜处理:一些节点可能相对于其他节点,运行更慢,比如硬件问题或者是单纯网络问题。Snowflake 的优化是,每个 WN 在读取了相应的数据文件后,当它发现其他 WN 还在读取,他会发送请求给其他 WN 要求分担更多的数据,而且这些数据直接从 S3 读取。从而来确保不要把过多的数据处理放在速度慢的 WN 上。
执行引擎:虽说可以通过增加节点来提升性能,但是 Snowflake 依然希望每一个节点的单体性能都能做到极致。因此,Snowflake 构建了自己的,基于列存,向量执行(vec-exec),并且是 push-based(推模式)的执行引擎。Columnar: 没啥争议,对于 OLAP 语句来说,Columnar-store 无论从存储,读取效率和执行效率来说,都优于 row-store。Vec-exec:也没有争议,Marcin 肯定把 Vec-Exec 这套运行优化放到执行器上。push-based: 相对于 Volcano 的拉模式,是下方的 operator,当处理完数据后,把数据 push 到上方的 operator(从执行计划角度来看上下),类似于 code-gen,这样的好处是提高了 cache 的利用率,因为可以避免不必要的循环控制语句。另一点就是,一些其他传统数据库系统在执行语句时需要考虑的麻烦,对于 Snowflake 来说没有。比如,不用 transaction management,因为所有的语句都是没有 side effect 的。
Cloud Services(VW 大脑)
相对于 VW 的无状态即插即用,Cloud Services (以下简称 CS)是一个长期在线的,有状态的大脑。它管理,协调着所有的用户请求,数据存储,VW 的生成,停止,接入控制, 优化器, 元数据,等等,并且是对所有用户共享的。CS 相当于是 Snowflake 提供 SAAS 对于用户的单点接入。当然,不同用户之间是不知道对方的存在的。实现方面,CS 的所有组件都是有多备份,并且可以做到多数据中心复制,用来保证高可用和高性能。
至此,所有的组件都介绍过了,下图也清晰地展现了整个 Snowflake SAAS 架构。
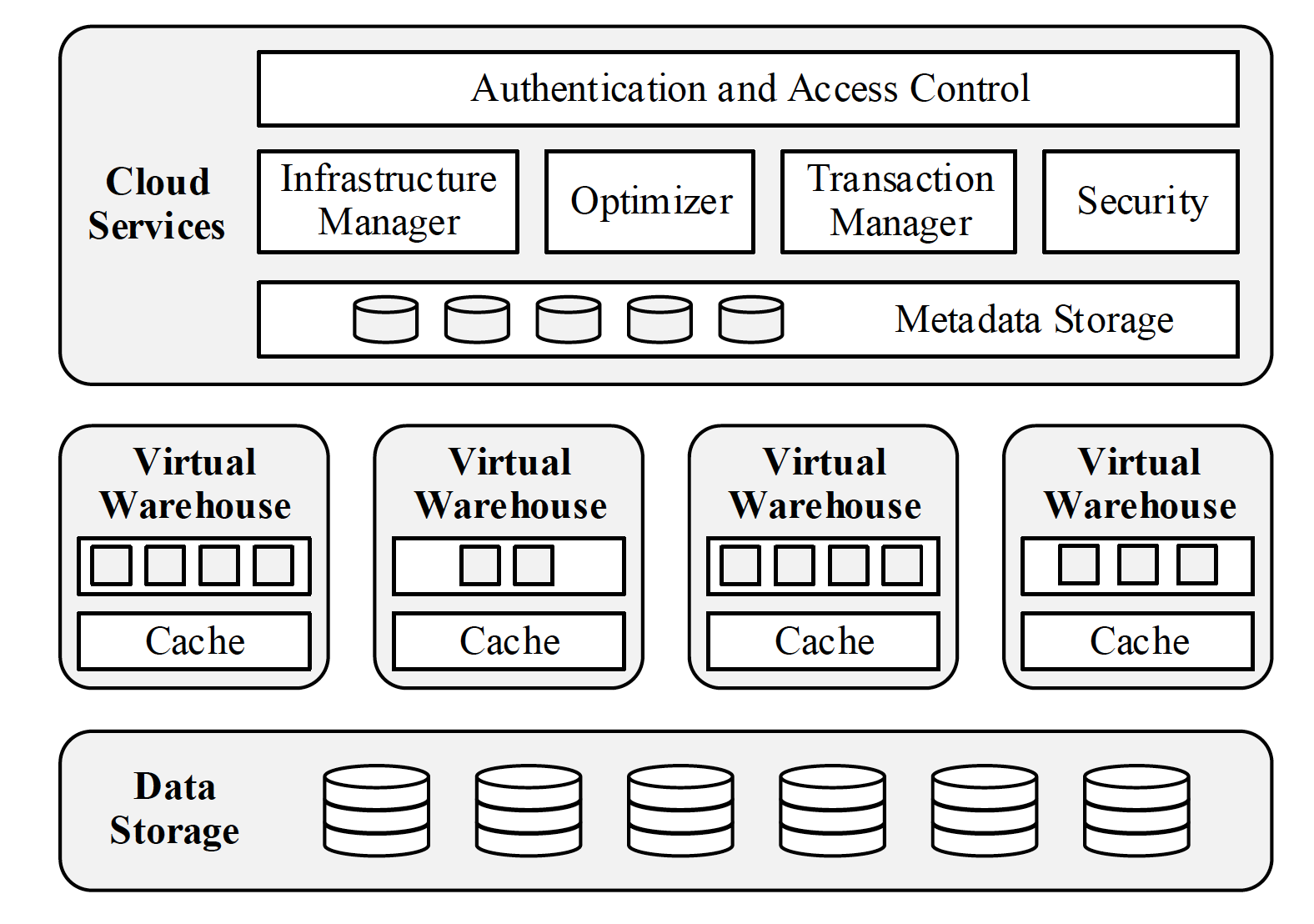
正是依托了云服务的高可用和可伸缩性,Snowflake 提供了 100%SAAS 的云原生数据仓库服务,对于用户而言,只需要支付数据存储费用,以及即插即用的 VW 的费用。主创团队真的很有眼光,坚信云原生的数据库会有自己的市场,而当时大红大紫的 SQL On Hadoop,已经没有太大声音了。如今 Snowflake 已经成功上市(截止 2021 年 2 月 12 日,市值高达:84.78 Billion)。今天的内容就到这,欢迎阅读。
2021 年的愿景之一是做更多对于技术和管理的输出,如果想要和我更多交流,欢迎关注我的知识星球:Dr.ZZZ 聊技术和管理。




