
在刚刚过去的首届 OpenAI 开发者大会上,OpenAI 不仅公布了新的 GPT-4 Turbo 模型,还推出了多项对现有功能的升级和融合,一系列新产品和新功能的发布让外界大呼过瘾。虽然其中重要内容很多,但一条具有革命性意义的消息让人很难不注意到:消除在某些用例中对纯向量数据库的需求。换言之,OpenAI 将提供一款 Retrieval 检索工具,用户已无需创建或搜索向量。
那么,到底什么是 Retrieval 检索工具?它和此前 OpenAI 使用的向量数据库有什么区别?
检索增强生成(RAG)到底是什么?
大语言模型尽管具有所有语言能力,但缺乏掌握“现在”的能力。 在快节奏的世界里,“现在” 就是一切。
基于大语言模型 (LLM) 构建的产品(例如 OpenAI 的 ChatGPT 和 Anthropic 的 Claude)非常出色,但也存在缺陷:
它们的数据集是静态的——大语言模型在静态数据集上进行训练,该数据集仅在某个时间点是最新的。这意味着它们可能无法收集训练数据后发生的事件或发展的信息。
缺乏特定领域的知识——大语言模型接受过通用任务的培训,这意味着它们不能访问某一家公司的私有数据或本地数据。它们只能根据接受过训练的知识生成响应,这可能会限制他们提供个性化或针对具体情况的响应的能力。
幻觉“黑匣子”——很难理解大语言模型在得出结论时考虑了哪些数据来源。大语言模型有时会产生事实上不准确或毫无根据的信息,这种现象被称为“幻觉”。
生产效率低下且成本高昂——很少有组织拥有财力和人力资源来生产和部署基础模型。
不幸的是,这些问题影响了基于大语言模型 (LLM) 构建的应用程序的准确性。而好在,这些问题都可以通过检索增强生成(RAG)来解决。
据悉,检索增强生成(RAG)一词来自于 Facebook AI 部门自然语言处理研究员 Lewis 等人在 2020 年发表的一篇论文中。这个想法是使用预先训练的语言模型 (LM) 来生成文本,但使用单独的检索系统来查找相关文档来调节语言模型。
也就是说,RAG 提供了一种方法,在不修改底层模型本身的情况下,用目标信息优化大语言模型的输出;有针对性的信息可以比大语言模型更及时也更聚焦某一特定组织和行业。这意味着生成式人工智能系统可以为 Prompt 提供更适合上下文的答案,也可以根据最新的数据提供这些答案。简而言之,RAG 帮助大语言模型(LLM)给出更好的答案。
在此之前,如果想要开发基于大语言模型(LLM)的应用,首先需要保证该应用能够识别相关数据(即存放在防火墙之后、或虚拟私有云之内的数据),这就需要用到 LangChain、Llamaindex 以及纯向量数据库等一整套工具组合。相关架构如下图所示:
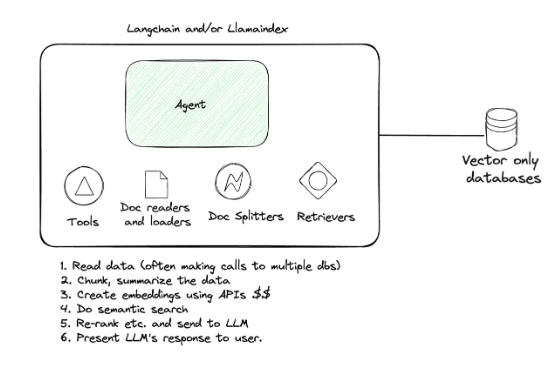
使用 LangChain 与 Llamaindex 实现检索。
这一次,OpenAI 引入了名为 Assistants 的新概念,允许用户以低代码/无代码方式配置出类似的架构。这就消除了对纯向量数据库的需求,并将整个过程简化为两个步骤。此外,在 Assistants 助手创建完成之后,我们可以通过几行代码轻松加以访问。
再有,用户现在可以通过 API 向 OpenAI 发送其他文件,而且所能接收的上下文最多可达 128K token,相当于约 300 页的文本内容。在通过代码访问这些 Assistants 时,我们还可以向其提供最多 128 种工具的访问权限,包括调用外部 API 并接收返回的数据以供 Assistants 进行处理。
下面来看基于 Assistants 的新架构:
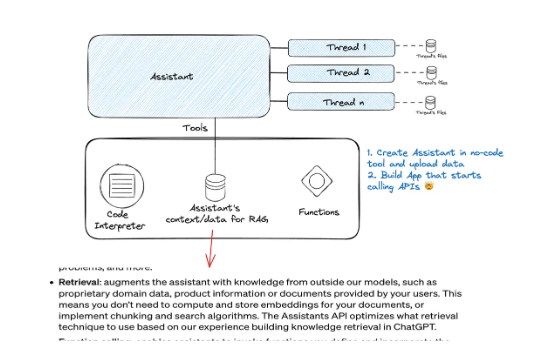
OpenAI 的 Assistant 助手与 Retrieval 检索工具。
以下是 OpenAI 在官方公告中关于 Retrieval 检索工具的重要说明:“此工具主要是利用我们模型之外的知识以增强助手,例如专有领域数据、产品信息或用户提供的文档。也就是说,您不再需要计算和存储文档嵌入、也无需实现分场和搜索算法。Assistants API 将根据我们在 ChatGPT 中构建知识检索的经验,对所用检索技术进行优化。”
未来几天之内,众多开发人员将着手测试这项新功能,并思考新架构之下 Llamindex 与纯向量数据库将往何处去。但这里需要强调一点,尽管新架构消除了个人/独立/业余开发者使用/购买纯向量数据库以构建新应用程序的需求,但大规模企业仍然掌握着 SQL、NoSQL、二进制、HDFS 等各种格式的 PB 级数据。
如果您是一家需要构建数据感知大模型应用的规模化企业,那么将仍然需要使用上下文数据库——即能够提供混合搜索(词汇与语义搜索)功能以存储和检索多种数据类型的数据库。但无论如何,看到 OpenAI 保持如此迅猛的发展速度仍然令人欣慰。
下图所示,为 OpenAI Retrieval 检索工具目前所能支持的文件类型。

RAG 技术的优越性及未来发展方向
说了这么多,到底 RAG 技术有哪些具体的优越性?归根结底,RAG 技术可用于提高生成式 AI 系统对提示的响应质量,而不仅仅是大语言模型所能提供的那些。具体的优势包括:
RAG 可以访问可能比用于训练大语言模型的数据更新鲜的信息;
RAG 知识存储库中的数据可以不断更新,而不会产生重大成本;
RAG 的知识存储库可以包含比通用大语言模型中的数据更关联上下文的数据;
可以确定 RAG 的向量数据库中的信息来源。由于数据源是已知的,因此可以更正或删除 RAG 中的错误信息。
可以确定的是,如今,我们正处于 RAG 的早期阶段,目前该技术还仅被用于为查询提供及时、准确和上下文相关的响应。这些用例适用于聊天机器人、电子邮件、文本消息传递和其他会话应用程序。在未来,RAG 技术可能的方向是帮助生成式人工智能根据上下文信息和用户提示采取适当的行动。
RAG 也许还能协助处理更复杂的问题。例如,生成式人工智能或许能够告诉员工公司的学费报销政策;RAG 可以添加更多的上下文数据来告诉员工附近哪些学校有符合该政策的课程,并可能推荐适合员工工作和以前培训的课程——甚至可能帮助申请这些课程并发起报销请求。
纯向量数据库厂商何去何从?
尽管 RAG 技术有着种种优势,但一直以来 OpenAI 内部一直是向量数据库和 RAG 技术并行采用的状态。而在 OpenAI 发布了这份关于 RAG 技术的最新公告后,各家纯向量数据库厂商“坐不住了”。
有创业者调侃,“OpenAI 几乎把上半年的创业项目全都自己做了一遍,也彻底把创业者们打懵了。”
此外,一些唱衰向量数据库的言论也此起彼伏:“去死吧向量数据库”,“还要什么向量数据库缓存呢”,“还要什么 LangChain 中间件呢”?
在业内竞争已经十分激烈的环境下,OpenAI 的一纸公告给整个向量数据库行业又增添了一丝焦虑。
近日,Chroma 的联合创始人 Anton Troynikov 在接受外媒采访时讨论了 RAG 技术以及在传统数据库厂商虎视眈眈下,纯粹的向量数据库初创公司该何去何从的问题。
大模型爆火后,向量数据库成了一块人人都想进来分一杯羹的“香饽饽”。现有的数据库厂商也在竞相在传统数据库上增加向量存储功能,当被问及这是否会让 Chroma 和其他向量初创公司难以发展业务时,Anton 表示,“这样的想法太过局限了”。
Anton 观察到,Chroma 中存储的大部分数据以前从未存储在数据库中,这表明在一段时间内,至少在基础设施层将会出现大量此类数据,这类数据将为 Chroma 带来越来越多的价值。向量数据库可以让向量检索就变得像将文本转储到文本框中一样简单,这与人们目前使用聊天机器人的方式没有什么不同。这个领域即使有很多传统数据库厂商加入游戏,似乎也不影响 Chroma 取得伟大的成果。
而当谈及如今比较火的 RAG 技术时,Anton 表示要保持检索增强生成(RAG)技术在大模型内部循环运行,而不仅仅依赖于外部 API。
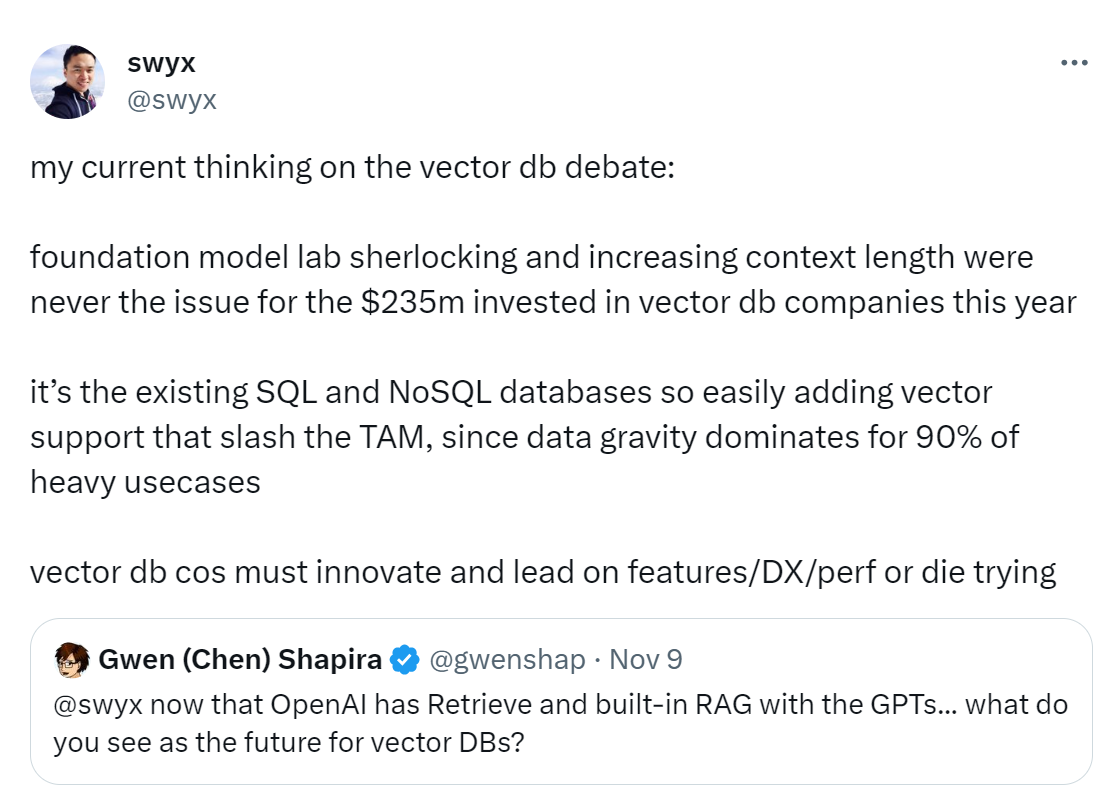
对于这些唱衰的声音,一位 IDswyx 的用户为在 X 上发表言论称:“对于今年向向量数据库投资 2.35 亿美元的公司来说,他们要的不是基础模型实验室 Sherlocking 和增加上下文长度这些基础功能,因为现有 SQL 和 NoSQL 数据库很容易增加向量支持,从而大幅减少 TAM。在 90%的重度用例中,数据的基本处理功能是占主导地位的。纯粹的向量数据库厂商必须竭尽全力在功能、DX 或性能方面进行创新和领先。”
参考链接:
https://cookbook.openai.com/examples/fine-tuned_qa/ft_retrieval_augmented_generation_qdrant
https://arxiv.org/abs/2005.11401
trieval-augmented-generation-rag-and-vector-only-54bfc34cba2c
https://www.oracle.com/artificial-intelligence/generative-ai/retrieval-augmented-generation-rag/




