
端到端语音识别技术,如何更好的落地?
出门问问开源端到端语音识别框架 WeNet,star 数已超 1300
今年 2 月,中国人工智能公司出门问问联合西北工业大学推出了全球首个面向产品和工业界的端到端语音识别开源工具 —— WeNet。
在正式发布后短短 8 个月的时间里,WeNet 在 Github 上的 star 数已超过了 1300 个。
近日,出门问问 WeNet 项目负责人接受了 InfoQ 专访,详细介绍了 WeNet 研发创新的思考与实践。
据了解,2020 年 10 月,WeNet 在出门问问内部正式立项。当时,公司内部多位研发人员同时展开对端到端语音识别技术的研发探索。
在探索过程中发现,主流的端到端语音识别工具 ESPnet 并不能完全满足需求,ESPnet 在工程上难以产品化,也难以支持流式语音识别、语言模型等语音产品中的核心特性。
因此,出门问问决定走自研之路,打造出一款以产品化为核心的端到端语音识别工具。与此同时,也想借此机会将公司内端到端的研究工作加以整合,将技术成果沉淀下来,这也正是“WeNet”名字的来源,“We”寓意“共创”。
“WeNet 的研发过程其实也是‘摸着石头过河’,边实践,边总结,边提高”,最开始,只有该项目负责人张彬彬一个人在开发核心代码,他用一个月时间完成了框架设计,很快又有 2 位成员加入进来,组成‘三人小分队’。随后,他们联合了西北工业大学的音频语音与语言处理研究组来开发这款 WeNet。
怎样做好流式的端到端语音识别是 WeNet 团队在研发过程中遇到的一个棘手问题。流式端到端语音识别是指在处理音频流的过程中,实时返回识别结果,延迟极低,对实时率要求高。为攻克这一难点,WeNet 团队首创了 U2 算法,经过反复试错、调优、实验,最终实现了良好的模型和识别效果。
项目启动 2 个月后,WeNet 即在 GitHub 上放出了部分代码。今年 2 月,WeNet 发布第一个正式版本 — WeNet 1.0 版本,WeNet 1.0 版本支持流式和非流式语音识别,支持云端 x86 和设备端 android 端的推理。
这时,WeNet 框架已相对完备,初步达成产品化目标,也收获了不少来自社区的正向反馈,于是团队决定将 WeNet 正式对外开源。
开源地址:https://github.com/wenet-e2e/wenet/
今年 6 月,WeNet 推出了 1.0.0 版本,该版本支持更多的数据集,解决了目前主流语音开源工具的痛点,且各项性能指标表现优异。
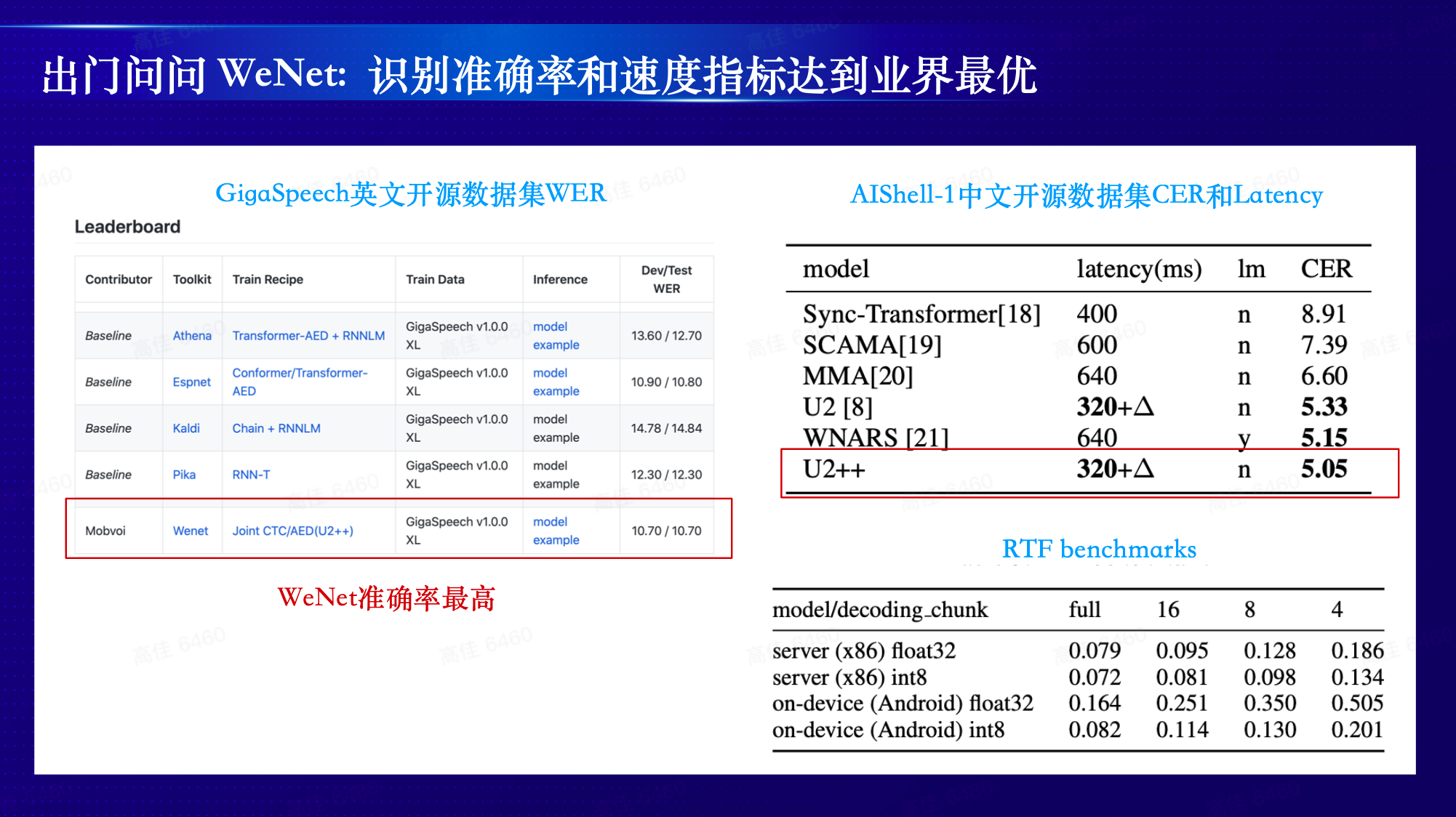
WeNet 使用业内前沿的深度学习模型结构 U2++ ,支持语言模型、endpoint、n-best、时间戳、提供数据量最大的中文和英文预训练模型等,在 Aishell-1 ,Aishell-2 和 GigaSpeech 上准确率达到 SOTA ;推理方案支持 Android 平台和 x86 平台,支持基于 gRPC 和 WebSocket 的服务端推理和端侧推理。
接下来,WeNet 将按照“边开发、边开放”的节奏逐步开源。
目前,WeNet 团队正在规划下一个版本,新功能主要会围绕三个核心点研发:
支持更多产品级、工业级特性。
如超大规模数据 IO(10 万小时以上)、热词、关键词检测、ITN,标点、标注错误检测等;
完善生态建设。
包括文档和教程建设,进行国际化推广、开发者社群维护、获得更多公司、高校的支持,支持更多更广泛的数据集,目前正在进行数个对中文、英文、日文等标准数据集的支持;
据悉,**今年 10 月,西北工业大学联合出门问问、希尔贝壳、西安未来人工智能计算中心发布超 10000 小时超大规模开源中文网络语音数据集 WenetSpeech。**具体开放时间为:10 月 8 日,开放论文;10 月 25 日开放数据集下载;11 月 11 日,开放基于该数据集的 WeNet 预训练模型。
更前沿模型的探索:
在技术上,将探索更好的端到端模型、预训练模型、无监督训练等技术。
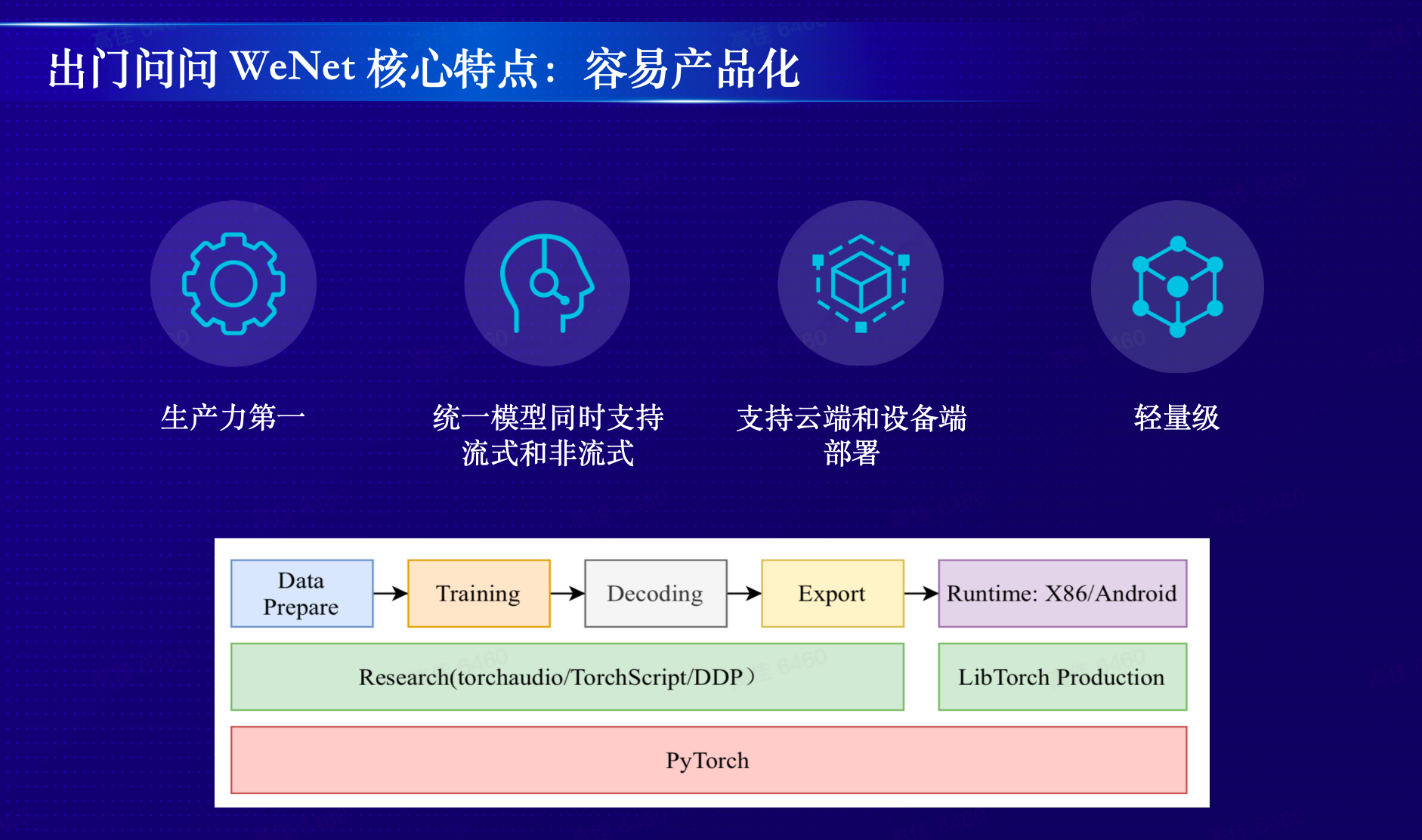
WeNet 核心特性:生产力第一
“我们希望 WeNet 成为国内和国际上最流行、最有生产力的智能语音工具”,出门问问对 WeNet 的未来充满期待。
如果用简单的几个词总结 WeNet 的特性,那就是**“更快、更高、更强、更有生产力”**。目前,WeNet 1.0 以其“小而精”的鲜明特色,已构建了一个完整完善的语音识别所需的方方面面的能力,且具有工业界应用的典型案例。
“生产力第一”是 WeNet 自诞生之初就确立的核心原则,其定位是面向产品和工业界。“WeNet 在设计之初、开源之前,就是为了落地端到端语音识别,解决语音识别在实际产品和应用中的实际问题”,张彬彬表示,“端到端语音识别产品在落地过程中存在的痛点和难点,多数是产品化的问题,把产品化做好才是关键”。
WeNet 的架构和特性也主要遵循“生产力至上”的原则而设计。
据介绍,WeNet 的核心算法是 U2 和 U2++,WeNet 1.0 中将 U2 算法升级到 U2++,U2++是当前全球最前沿的深度学习模型结构。使用 Conformer 网络结构和 CTC/attention loss 联合优化方法,先用 CTC 进行流式解码,再用 Attention Decoder 去重打分,进一步提高了识别准确率。
与企业相比,高校和研究机构做语音识别相关的模型和算法,无需过多考虑模型是否有应用场景以及能不能落地。在设计公开数据集上的性能时,也基本不用考虑是否是流式的,模型的参数量如何,是否能采用低成本的方式等。
但在企业不同。出门问问认为,一个算法、一个模型、一个产品和项目,如果不能在公司里面落地,可能毫无价值可言。
生产级语音识别系统的建设,对技术团队的能力提出了更高的要求,需要更深入的理解语音识别的场景和实际的产品诉求,以及更高标准的工程能力的要求,还要更专注产品的特性,更克制。
不过,WeNet 虽是一款面向工业级产品的端到端语音识别解决方案,但因其简单、高效的特性,也被很多高校用来作为学习和科研工具。WeNet 在整体结构设计上属于轻量级的框架,安装、使用方便,这对于高校的研究者来说,便于快速上手。
WeNet 所具有的生产力第一、轻量级、准确率高等性能,对开发者群体十分友好,即便是在开发者已经使用其他语音识别框架的情况下,也能快速、安全、低成本的迁移到 WeNet 上来。
在迁移成本方面,WeNet 提供了模型训练、推理、预训练模型,如果用户想搭建语音系统,在出门问问的平台上下载预训练模型,再用推理的流程把模型给构思起来,整个过程约 10 分钟内就可以操作完,轻松获得专业级别、可以应用的语音能力。
WeNet 还提供一站式的服务,传统的语音识别模型的研发分为模型研发、模型训练、模型部署三个阶段,每一步都有很多复杂冗长的工作要做,而通过 WeNet ,原来需要三步,三个人甚至三个团队去做的工作,现在靠这一个平台就解决了。
现在,WeNet 已经广泛应用到到出门问问内部的各个产品线,如车载、魔音工坊等 toB 项目。
**出门问问也为企业使用 WeNet 部署语音识别提供商业化和技术支持。**企业皆可基于自己的数据和服务体系,拥有私有化系统。
目前,WeNet 应用到了喜马拉雅、作业帮、京东、腾讯等数百家公司,他们采用 WeNet 构建自己语音服务,覆盖智能车载、智能家居、智能客服、音频内容生产、直播、会议等语音识别应用场景。

在上述场景中,WeNet 都做到了更高水平的准确率。WeNet 被用户赞为“产品化集成度最好的框架”。WeNet 通过打造社区支撑、提供行业解决方案、落地私有部署等方面,为 AI 行业创建共享机制、建立生态。
端到端语音识别时代来临
“生产力第一”也是 WeNet 有别于其他语音识别工具的核心优势。
在 WeNet 早期,出门问问内部曾将其和主流的端到端语音识别框架 ESPnet 做过性能上的对比,WeNet 在易安装、易用性、产品化等方面表现要好于 ESPnet,其中在易用性上,可提供一键式训练脚本、预训练模型和多平台运行时工具。
相比 ESPnet,Wenet 没有对各类序列转化任务进行统一抽象,完全聚焦于语音识别任务,同时对常用的语音识别应用场景提出了一套端到端解决方案,而不是提供各类模型方案的大而全的集合。
自去年 12 月开始,出门问问内部全部迁移到了 WeNet 上,经验证开发效率得以大幅提升。如今,在 Github 的 Star 数量上,WeNet 也远超国内其他开源语音框架。
WeNet 团队表示,相比于其他的端到端语音识别工具,WeNet 现阶段还是一名“年轻选手”,WeNet 正式发布也就半年时间,在生态和数据集的建设方面还相对欠缺,“现在学术界有 50 个场景的数据集,我们只做了 5 个,数量还远远不够,未来会逐步补上来,目前正在借助社区的数量展开工作”。
近些年,随着深度学习技术的发展,语音识别技术经历了深刻的变革,从基于 DNN-HMM 的语音识别,到基于 CTC 的端对端语音识别再到基于基于 Attention 的端对端语音识别。
语音识别进入到“全民”端到端时代,已是毋庸置疑的趋势。学术界最早在 2014 年开始研究端到端语音识别技术,经过 7 年发展,该技术现在已经逐步趋向成熟。
端到端语音识别技术具有明显的优势,它大大简化了语音识别的流程,流程简化后,上手学习、应用的门槛都大大降低,同时还能实现非常好的语音识别效果。特别是近两三年,该技术已经在业界广泛的应用,落地,未来会有更多的行业应用涌现。
任何一项技术发展到一定阶段后都会面临瓶颈期,端到端语音技术现在面临的一个问题在于,端到端语音识别依赖平行语料数据,平行语料在低资源语言下的应用还需进一步探索,低资源的学习将是接下来的研究重点。
目前的深度学习依赖大量的语料及标注数据,预训练技术和无监督学习技术是当前语音领域研究的热点和难点。出门问问判断,接下来 3-5 年,预训练技术和无监督学习技术将是发展趋势。如何使用海量的无监督数据学习,并进行模型的预训练,然后以低成本进行迁移到其他任务上,值得投入更多探索。在预训练技术上,出门问问很早就开始了语音预训练和自然语言处理 GPT-3 的研究,未来会持续在这块发力。
拥抱开源生态 ,打破依赖国外语音框架的长期垄断 WeNet 发展的每一步离不开开源社区的助力。WeNet 研发借鉴了 Espnet 、Pytorch 、Kaldi 等优秀的开源项目。如今发展渐至成熟的 WeNet 也选择开源开放来回馈社区,为语音开源生态出一分力。
张彬彬觉得,Wenet 开源最大的意义是降低了语音识别的门槛。“传统的语音识别技术,门槛高,需要专业的背景知识。门槛降低后,越来越多的人能够接触、从事、开发和应用语音识别,只有越来越多的人从事这个行业,这个行业才会发展的更快,也能更好、更快的赋能和产品化”。
他表示,Wenet 开源后也收到了一些圈内人士的关心,Wenet 通过开源的方式把语音识别的门槛降低了,但这是否对出门问问公司本身带来不好的影响?
思考许久后,他更坚定的觉得这是一个正确无比的决定。
“如果用发展和长远的眼光来看,只有语音行业的快速发展、进步和应用才能带来更多的成长空间,我们更多的是追求全面的、发展的、生态的共赢,而不是片面的、孤立的、垄断的零和博弈。此外,WeNet 的成熟也能促使大家把重心放到打造真正的产品和应用上,而不是重复造轮子,只是处理各种琐碎和边边角角。”
如果从更宏观的维度看,WeNet 开源后,国产原创语音识别工具阵营又添一员“大将”。
我国产业界对开源语音框架依赖性较高。在很长一段时间里,我国语音识别领域所使用的工具和框架,多出自西方国家的企业或高校研发,被国外垄断开发。
最早期,在上世纪 90 年代到 2010 年代,传统的语音识别系统 HTK 是英国高校开发的。近 10 年里,最为流行的语音识别工具 Kaldi,是美国公司和高校开发的。最近三年,最主流的端到端语音识别工具 ESPnet 是美日高校和公司开发的。
现阶段,国内原创的语音识别工具还比较少,一些科技大公司虽开发了自己的工具,但因涉及核心资产等因素,这些工具通常不会被开放出来,也未能得到广泛应用。
在这样的背景下,打造自主可控的语音开源工具已是箭在弦上。
出门问问认为,WeNet 是真正意义上的第一个国产并广泛流行和应用的语音识别框架,打破了西方国家在该领域的长期垄断,对实现真正的自主可控具有重要意义。出门问问希望通过探索和构建开源开放协作的共享机制,创建自主可控的语音开源工具,寻求国产 AI 技术的进一步突破。
采访嘉宾介绍:
张彬彬,出门问问 WeNet 项目负责人,2018 年加入出门问问负责端到端语音识别系统的研发和落地,包括 WeNet 的开源推进,车载和 toB 项目等。2017 年硕士毕业于西北工业大学音频语音与语言处理研究组,曾在微软、百度、地平线等公司工作。
本文选自《中国卓越技术团队访谈录》(2021 年第五季),点击下载电子书,查看更多独家专访!

《中国顶尖技术团队访谈录》品牌升级,现正式更名为《中国卓越技术团队访谈录》,这是 InfoQ 打造的重磅内容产品,以各个国内优秀企业的 IT 技术团队为线索策划系列采访,希望向外界传递杰出技术团队的做事方法/技术实践,让开发者了解他们的知识积累、技术演进、产品锤炼与团队文化等,并从中获得有价值的见解。
如果你身处传统企业经历了完整的数字化转型过程或者正在互联网公司进行创新技术的研发,并希望 InfoQ 可以关注并采访你所在的技术团队,可以添加微信:caifangfang842852,请注明来意及公司名称。




