
我们在 ClickHouse 25.6 的版本发布文章中已经介绍了很多功能,但实际上我们还有一个非常酷的新功能,保证大家会被“冰冻”的。😎
所以这就是你的夏日加餐博客,正好适合你躺在沙滩上时读一读:这次我们要专门介绍 CoalescingMergeTree —— 一个全新的表引擎,专为整合稀疏更新设计,可以在不损失数据完整性的前提下,帮你有效减少行数。
如果你是那种涂防晒霜的间隙也不忘查看 ClickHouse 更新的人,这篇文章正合你胃口。🏝️
让我们一探究竟。
CoalescingMergeTree 表引擎
贡献者:Konstantin Vedernikov
MergeTree 表引擎家族难得迎来新成员,因此这次的全新引擎 CoalescingMergeTree,值得我们用一整篇文章来介绍。
CoalescingMergeTree 能够在合并过程中,逐步将稀疏的记录合并,非常适合以下场景:
你希望高效地保留每个实体的最完整版本。
你可以接受在数据合并时,最终在磁盘上实现整合。
你希望避免像 ReplacingMergeTree 那样整行覆盖,只想填补缺失的字段。
一个典型的应用场景:IoT 设备的状态或配置快照。比如,车队的可观测性,就像 Tesla 那样[https://clickhouse.com/blog/how-tesla-built-quadrillion-scale-observability-platform-on-clickhouse]。
在现代的联网车辆,尤其是电动车中,遥测数据的更新通常来自不同的子系统:
电池模块汇报电量
GPS 模块发送位置信息
软件更新模块上报固件版本
传感器定期更新温度和速度
我们希望通过 CoalescingMergeTree,将这些增量的、稀疏的更新整合成每辆车的完整视图。
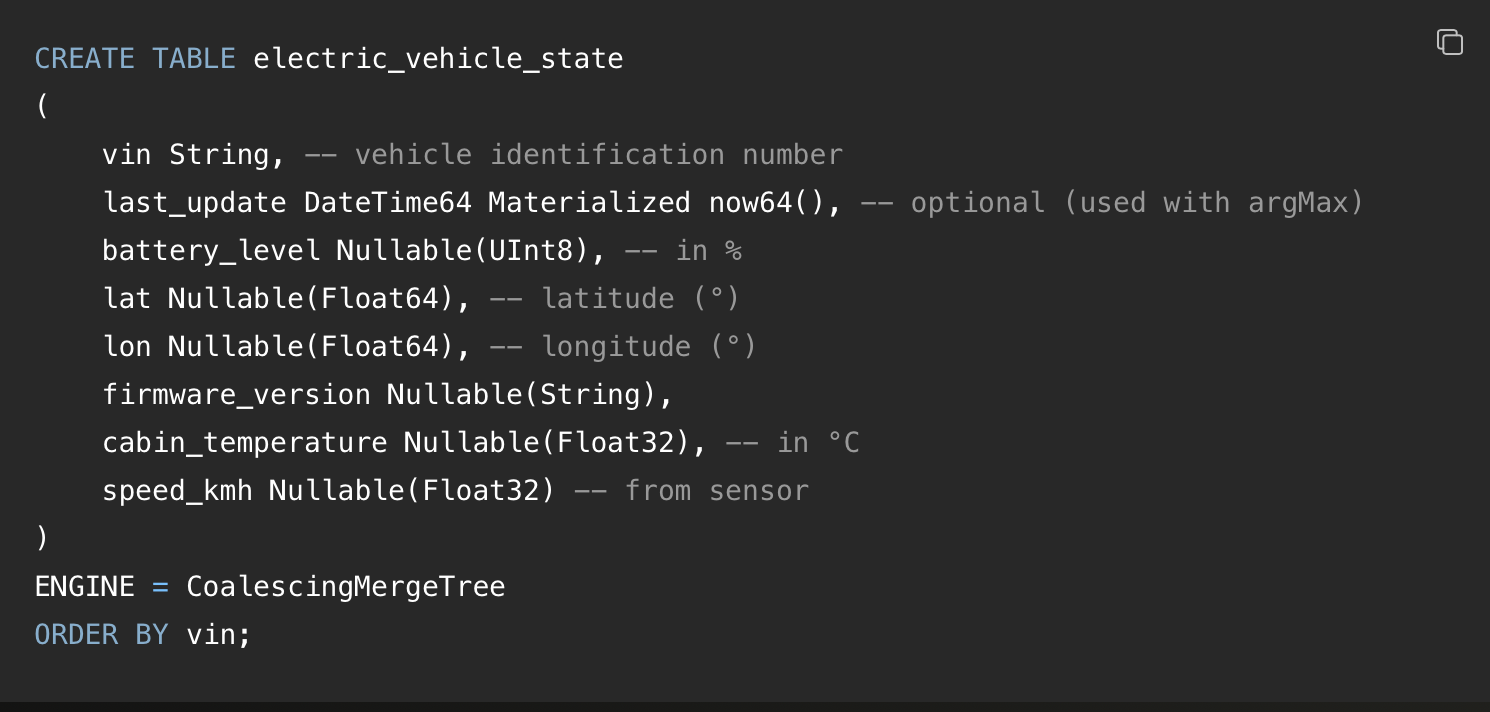
表定义
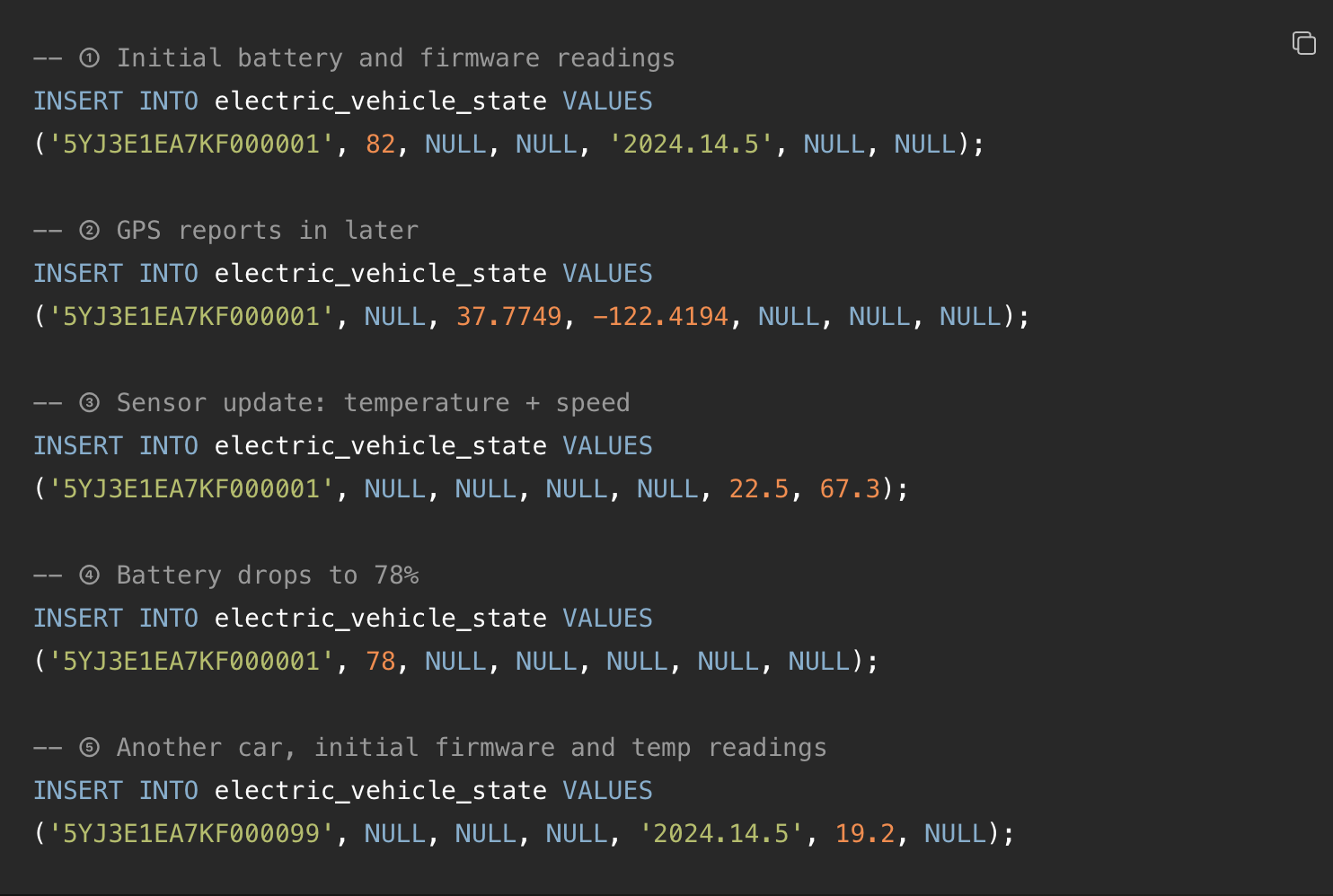
示例数据插入
为什么不直接用 UPDATE?
在许多数据库中,处理类似的状态变更通常会通过更新已有的行来实现,比如使用 UPDATE 指令来刷新最新的温度或固件版本。ClickHouse 当然也支持快速、频繁的单行 UPDATE。你可以在我们最近的 Open House 2025 用户大会上看到相关的功能演示[https://clickhouse.com/openhouse]。对于某些工作负载,这种方法确实很适用。
但在高吞吐量的 IoT 场景,这种做法就显得低效了:UPDATE 需要先找到已有的那一行,然后重写,过程中往往还会锁定或改写比必要更多的数据。
ClickHouse 更提倡一种简单的追加式模型:只要有新字段到达,直接插入即可。CoalescingMergeTree 则在此基础上再进一步,通过后台合并机制,自动把这些稀疏的插入记录整合成完整、紧凑的记录(后文我们会详细介绍)。这种方式尤其适合高写入量、高基数,且更新频繁但每次只改部分字段的场景。
ClickHouse 对插入型工作负载做了深度优化:插入操作是完全隔离的,支持并行写入,彼此不会产生干扰,且可以全速写入磁盘,因为 ClickHouse 不存在需要锁定或更新的全局结构(比如全局 B++ 索引)。而记录合并等额外的计算工作,都是通过后台合并任务来异步完成,从而保证插入操作始终轻量高效。
正是这种架构,使得 ClickHouse 在生产环境中能够实现超高的写入吞吐量。在某些部署场景下,ClickHouse 的稳定写入速度可超过每秒 10 亿行,同时保持内存和 CPU 使用的稳定。
要点:万亿级行数的挑战
在高吞吐量的 IoT 系统中,成千上万甚至上百万台设备持续不断地发送数据。每次更新往往只涉及一两个字段,结果就是表中充斥着大量稀疏且冗余的行。
为了还原每个设备的最新完整状态,你需要从每列中提取最新的非 null 值。ClickHouse 即使使用普通的 MergeTree 引擎,也可以通过 argMax() 聚合函数来实现这一点。
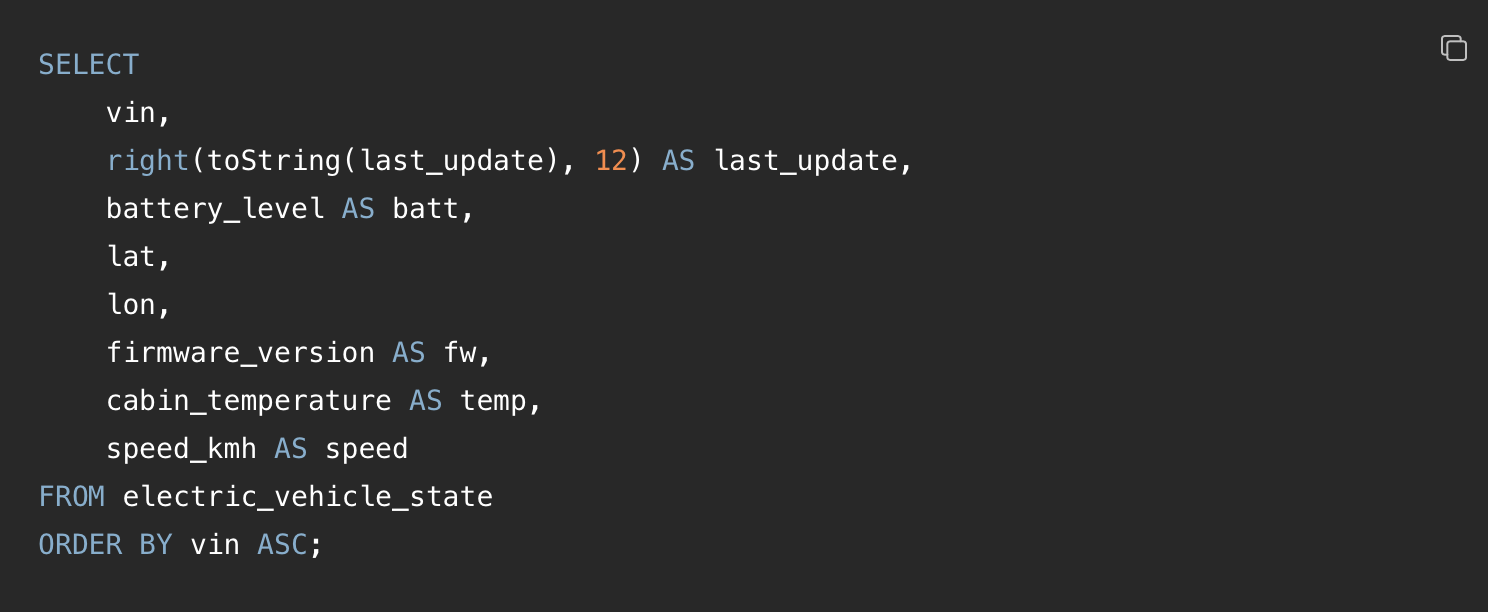
下面是 electric_vehicle_state 表在经过几次稀疏更新后的样子(假设还没有发生任何数据部分的合并,稍后会解释原因)。为了简洁,last_update 的时间戳被简化了:
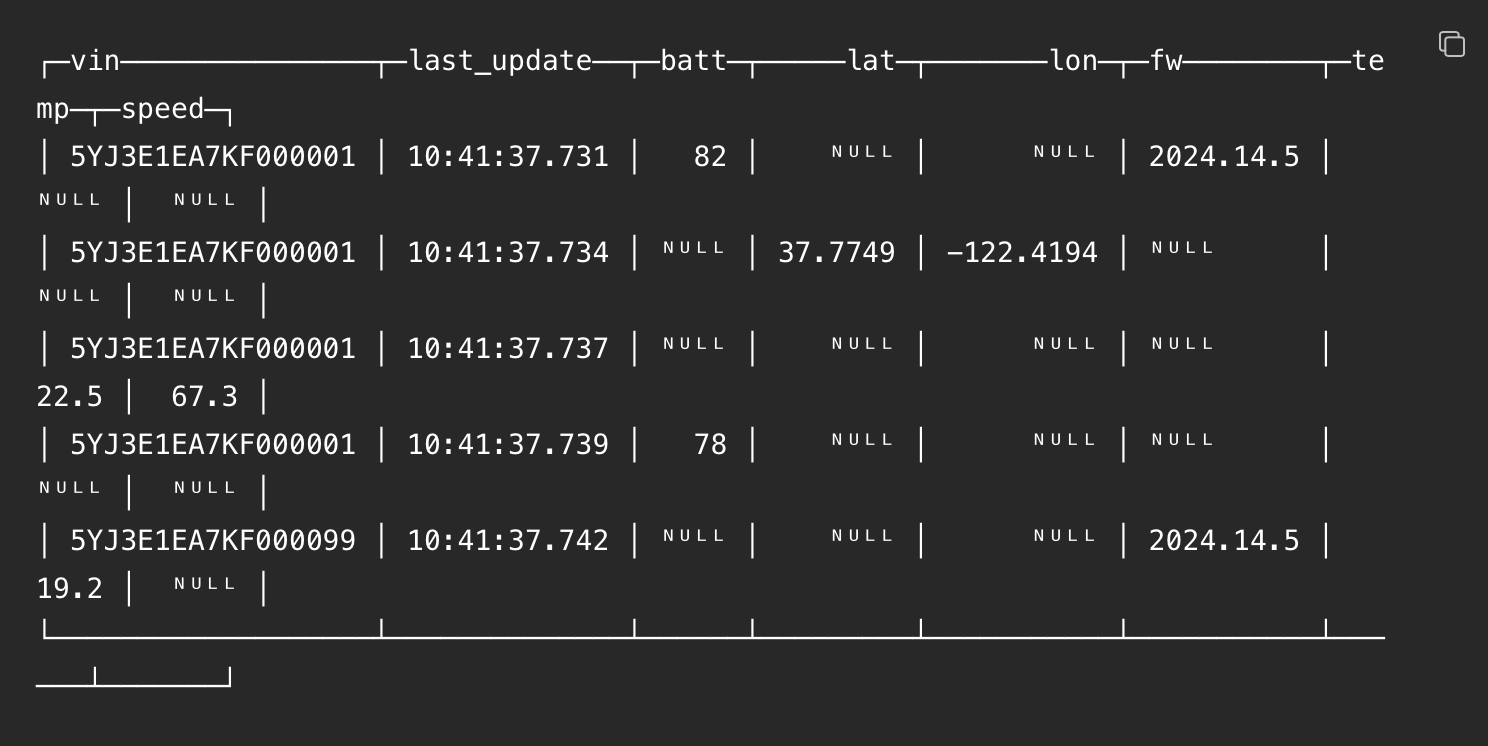
接着,这是使用 argMax() 查询每个设备最新状态的方法:
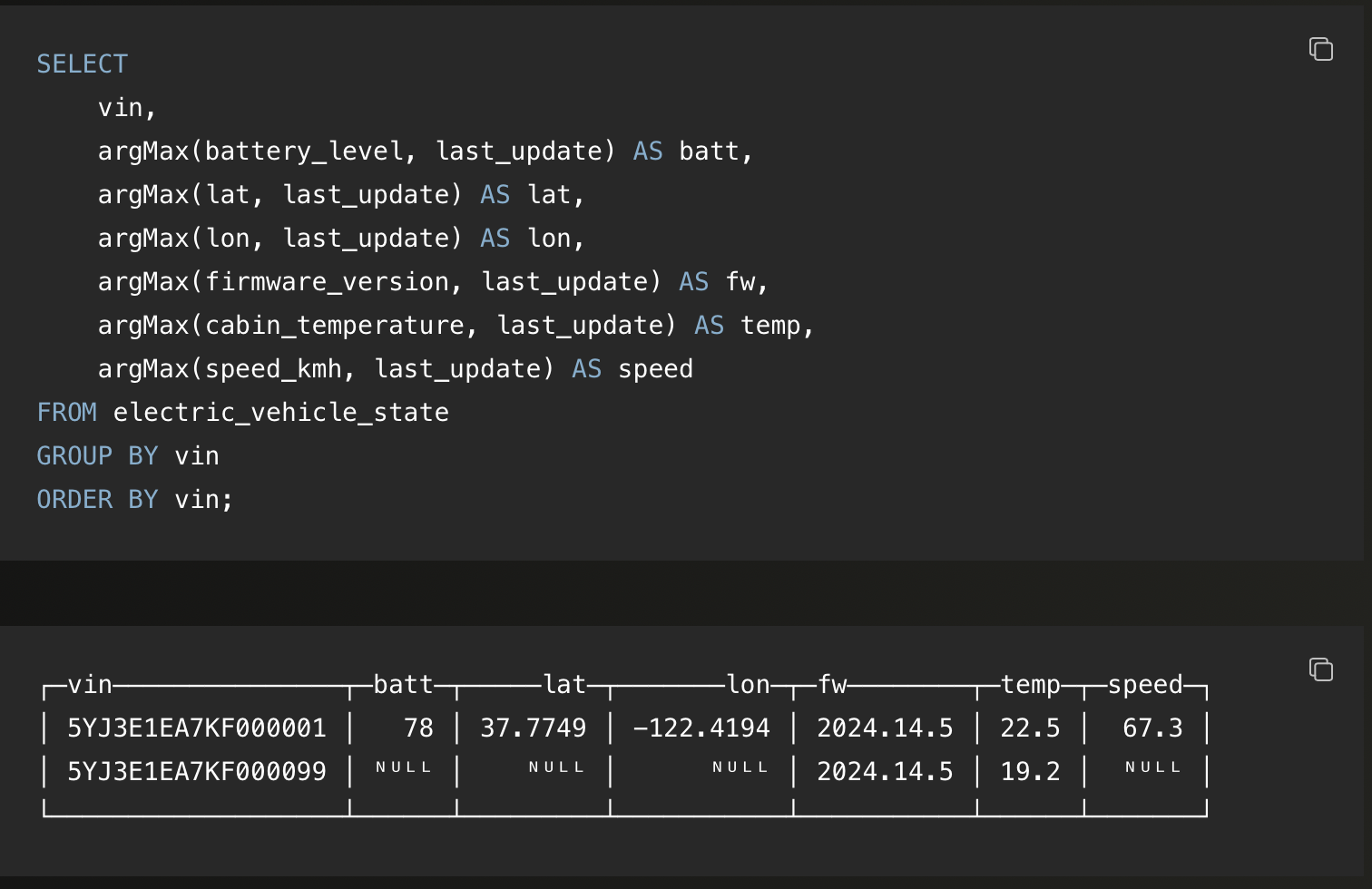
argMax 在这里非常适用,因为它可以保留每列的最新非 null 值。
具体来说,argMax(x, t) 会返回时间戳 t 最大且 x 不为 null 的那一行的 x 值。如果存在更晚的时间戳,但对应的 x 是 null,这些行会被跳过。
但如果完全依赖常规的 MergeTree 和 argMax(),就意味着:
每次查询都要全表扫描
每次都需要实时计算聚合
当表的规模达到数十亿、甚至万亿行时,这种方式的效率就会变得非常低下。
CoalescingMergeTree 如何解决这个问题
使用 CoalescingMergeTree,ClickHouse 可以在物理存储层,将具有相同排序键(如 VIN)的一组行合并。在后台的部分合并过程中,ClickHouse 会对每个排序键,仅保留每列最新的非 null 值,实现了磁盘上的预聚合:
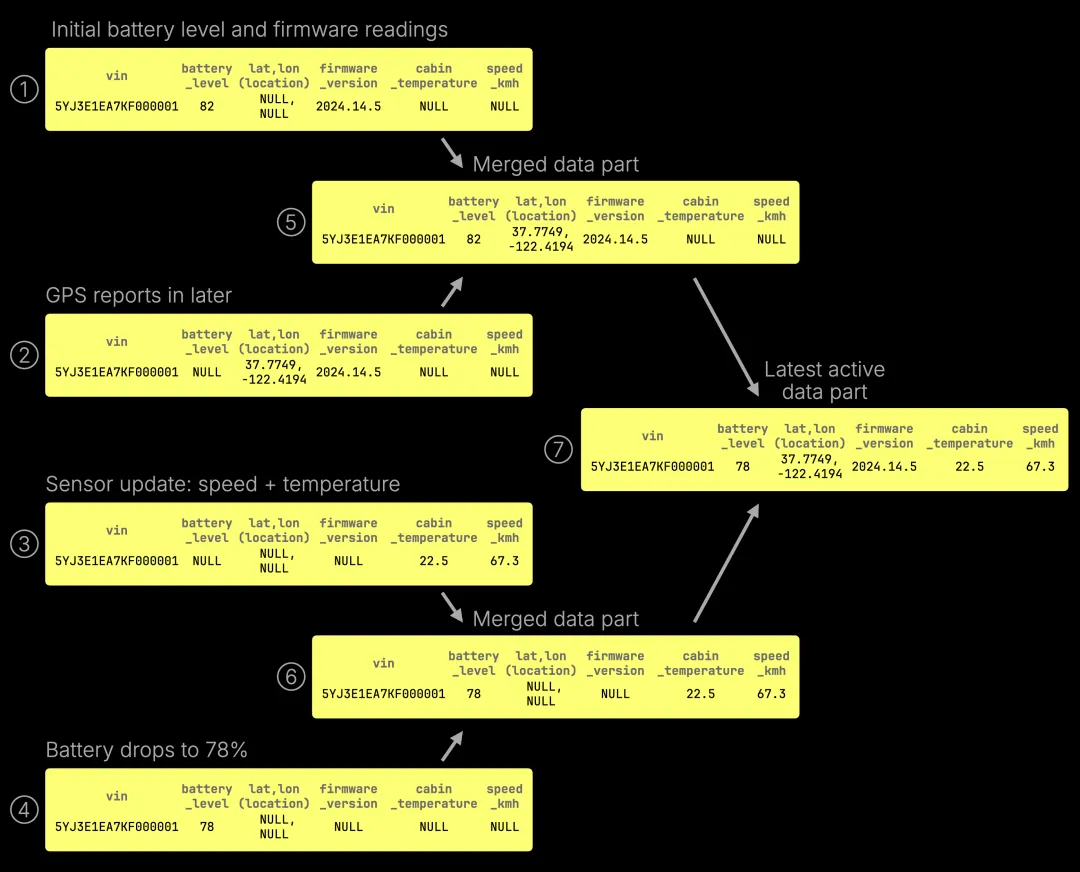
上图展示了不同子系统(如电池、GPS、传感器)产生的稀疏更新,如何通过 CoalescingMergeTree 逐步合并为一个完整的设备状态。每次更新只改动部分字段,ClickHouse 会在后台合并时,自动将排序键相同(例如 vin)的行合并,形成最新的完整设备视图。
图中展示了 7 个数据部分[https://clickhouse.com/docs/parts]:最初的插入数据(①–④)、中间合并形成的部分(⑤、⑥),以及最终的活跃部分 ⑦。合并完成后,①–⑥ 会变为非活跃数据并被自动清理。此后,查询只需在这个单一、紧凑的数据部分 ⑦ 上执行,效率大大提升。
需要注意的是,这里的“最新”并非依据时间戳列判断,而是基于行的物理插入顺序。合并时,CoalescingMergeTree 会使用各数据部分在磁盘上的写入顺序。对于每列,ClickHouse 保留的是合并过程中,排序键下,最近写入的非 null 值。
比如图中,数据部分 ① 到 ⑦ 按写入顺序排列,① 最早,⑦ 最新。
这种方式极大地降低了:
每个设备对应的行数
查询时需要扫描的数据量
读取最新状态:argMax 与 FINAL
在 IoT 这样的高写入场景中,后台合并通常跟不上插入的速度(合并在后台持续运行,但写入总是更快,就像有个合并滞后的窗口)。
即便如此,为了保证查询准确性,我们仍会使用 GROUP BY 和 argMax(),但由于后台合并已经完成了大部分整合,实际需要处理的行数大大减少。
(前文的图示中为了简洁省略了 last_update 列。它并不影响 CoalescingMergeTree 的合并逻辑,后台合并会自动保留每列的最新非 null 值。但如果你在查询时使用 argMax(),就需要依靠 last_update 这样的时间戳来判断“最新”是哪一行。)
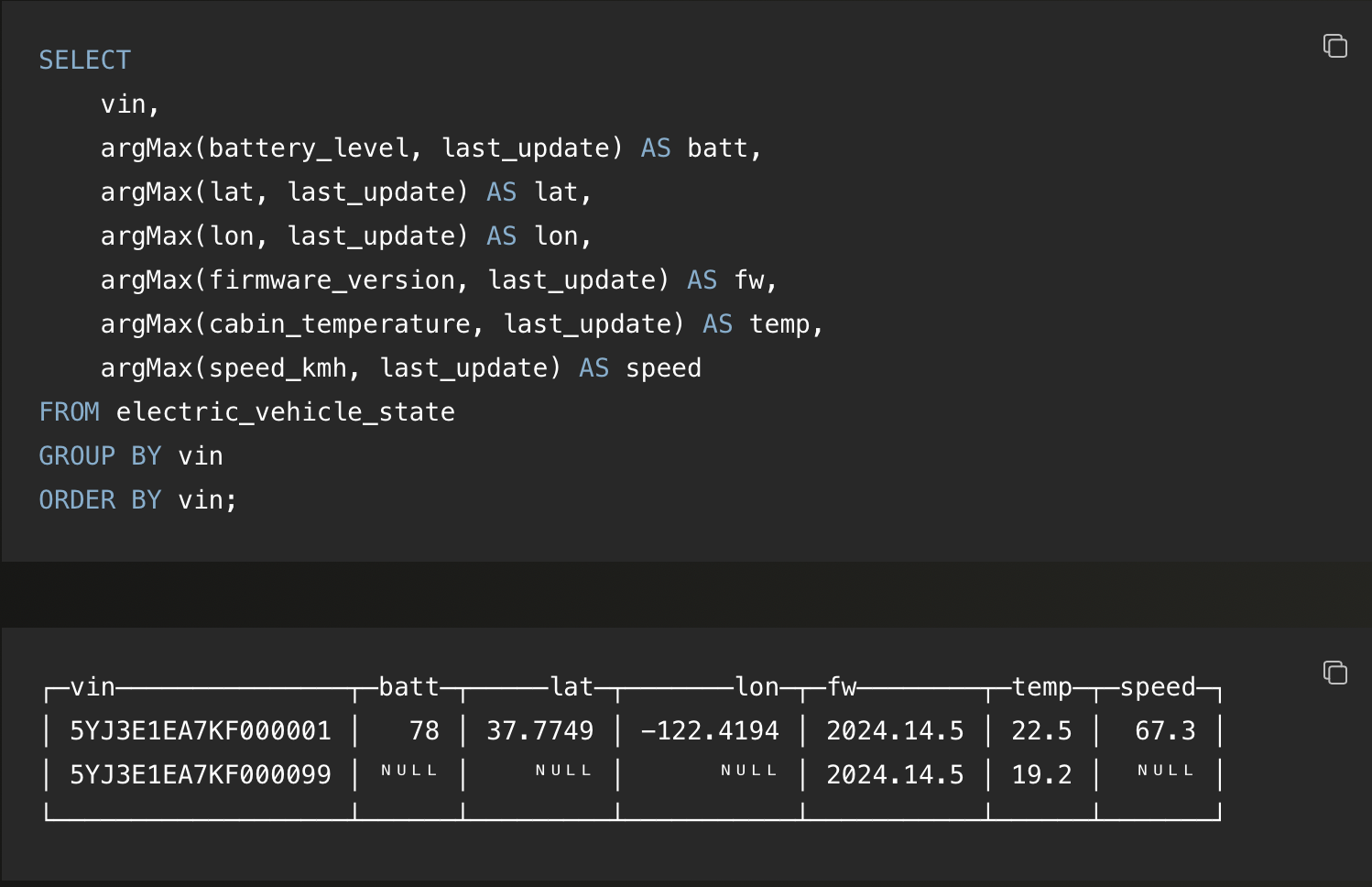
如果所有数据部分已经合并完成且没有新数据插入,直接 SELECT * 查询就可以,不需要再加 GROUP BY。
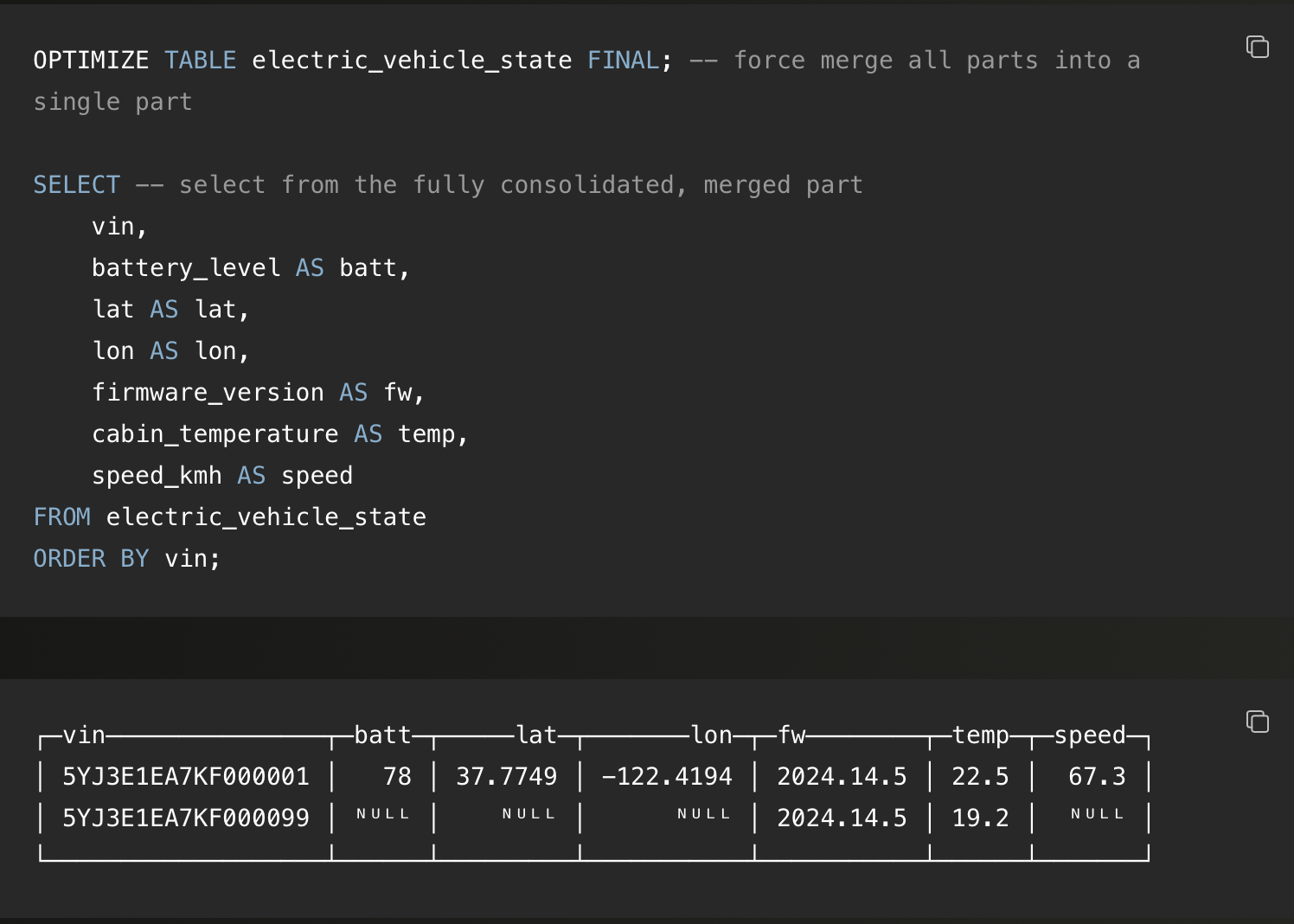
在持续更新的场景下,也可以通过查询时加上 FINAL 修饰符,临时应用 CoalescingMergeTree 的合并逻辑(上文图示已讲解),这样就不用在查询时再做聚合。FINAL 不会将合并结果写回磁盘,而是针对当前查询,在内存中对相关数据做一次合并,生成完整的记录,避免了使用 GROUP BY 或 argMax():
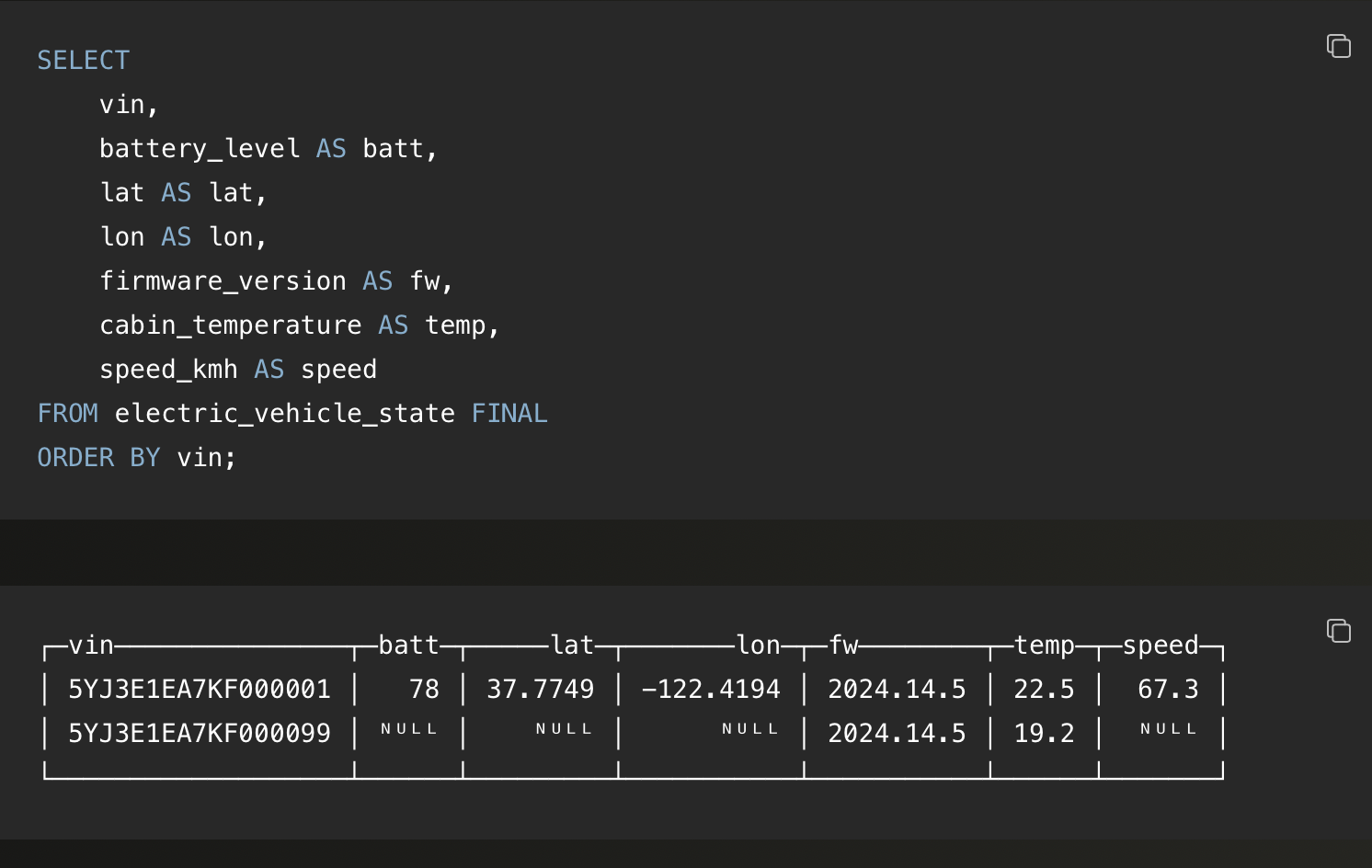
注意,使用 FINAL 后,last_update 字段就不再是必须的,因为 FINAL 在查询时依据插入顺序来判断最新值,不依赖时间戳。
但如果查询不用 FINAL,而是通过 argMax() 来聚合,就仍然需要时间戳列如 last_update。因为当数据部分尚未合并时,查询引擎无法直接知道写入的时间或行的物理顺序,必须借助时间戳来判断。
推荐的存储模式:原始表 + 整合表
我们推荐搭配使用 CoalescingMergeTree 和常规的 MergeTree 表,通常可以通过物化视图来实现[https://clickhouse.com/docs/materialized-views]:
MergeTree 表用来存储原始事件流,完整保留每辆车或设备的所有更新记录。
CoalescingMergeTree 表则用于存储整合后的视图,例如每辆车的最新状态,适合用于仪表盘、定期报表或分析型查询。
这种双表模式,既保证了所有原始数据的留存,又能通过物理行整合,提升查询和存储的效率。更重要的是,如果排序键不能唯一标识每个事件,原始表仍然保留了完整数据,方便日后恢复或重算。
更多应用场景
除了 IoT 快照,任何存在稀疏、追加式更新,逐渐丰富记录的场景,CoalescingMergeTree 都很合适,比如:
用户画像补全:邮箱、电话、位置等信息随着用户交互逐渐补全。
安全审计日志:事件逐步添加更多上下文,如操作者身份、受影响系统。
ETL 流程的迟到维度:后续补充步骤为缺失字段赋值。
患者健康档案:实验室结果、医生笔记和生命体征等来自不同系统,逐步补充。
广告或营销活动跟踪:展示和点击等信息从不同系统在不同时间汇集。
客户支持工单:随着收集更多信息(如严重程度、解决方案),工单持续完善。
这些场景下,CoalescingMergeTree 能在保证数据完整性的同时,降低存储成本,提升查询性能。
就这样,去享受你的夏日时光吧
你的 ClickHouse 知识已经更新,是时候给自己充充电了。
等你回来时,我们还在这儿。🏖️🍹
夏天快乐,查询顺利!

征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出 &图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com。






