
Swiggy 近日推出 Hermes V3,这是一款基于生成式 AI 的 Text-to-SQL 助手,员工可以直接用自然语言向数据发起查询。Hermes 运行在 Slack 中,通过向量检索、会话记忆、智能体编排以及解释层,将日常语言准确转化为可执行的 SQL 查询。
作为一家印度在线食品订购与配送平台,Swiggy 最初推出 Hermes 时,目标很简单:给员工一个轻量级入口,让他们能问一些基础问题,并自动生成对应的 SQL,在内部数据仓库中执行。但在实际使用中,这个早期版本很快遇到了瓶颈,例如难以处理派生指标、无法理解上下文、多次提问结果不一致,以及缺乏对生成 SQL 的校验和解释能力。
为了解决这些问题,Swiggy 工程团队对 Hermes 进行了彻底重构,引入少样本学习(few-shot learning)、元数据检索机制,并围绕大语言模型设计了更加结构化的工作流。
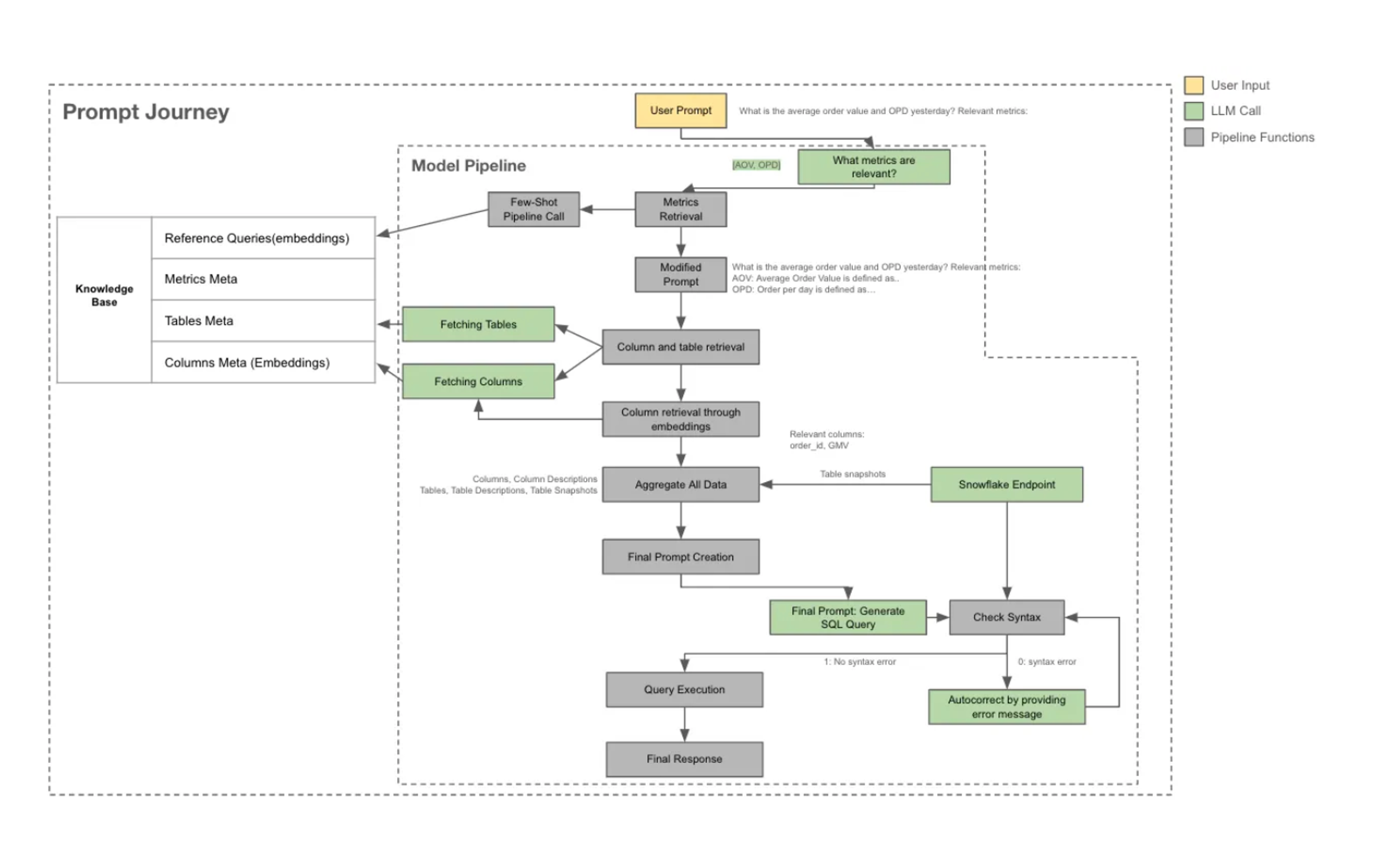
早期版本的 Hermes 整体架构
在第三个版本中,Hermes 的核心升级之一,是基于向量的提示检索系统。该系统建在 Snowflake 中历史执行过的 SQL 查询之上。但一个现实问题是,大多数生产环境中的 SQL 并没有清晰的描述性元数据,很难直接理解查询的真实意图。
为此,团队借助具备大上下文能力的语言模型,将已有 SQL 自动转化为自然语言解释,从而“补齐”这些查询背后的意图信息。生成的自然语言提示随后被向量化并建立索引,在新请求到来时,作为少样本示例注入模型,使 Hermes 能够参考过往的分析模式,显著提升 SQL 生成的准确性。
正如 Swiggy 工程师 Meghana Negi 和 Rutvik Reddy 所总结的那样:
Hermes 现在可以从一个经过整理的历史查询与提示数据库中进行检索,通过向量相似度匹配并结合会话上下文,将 SQL 生成准确率从 54% 提升至 93%,同时支持更加自然的多轮对话。
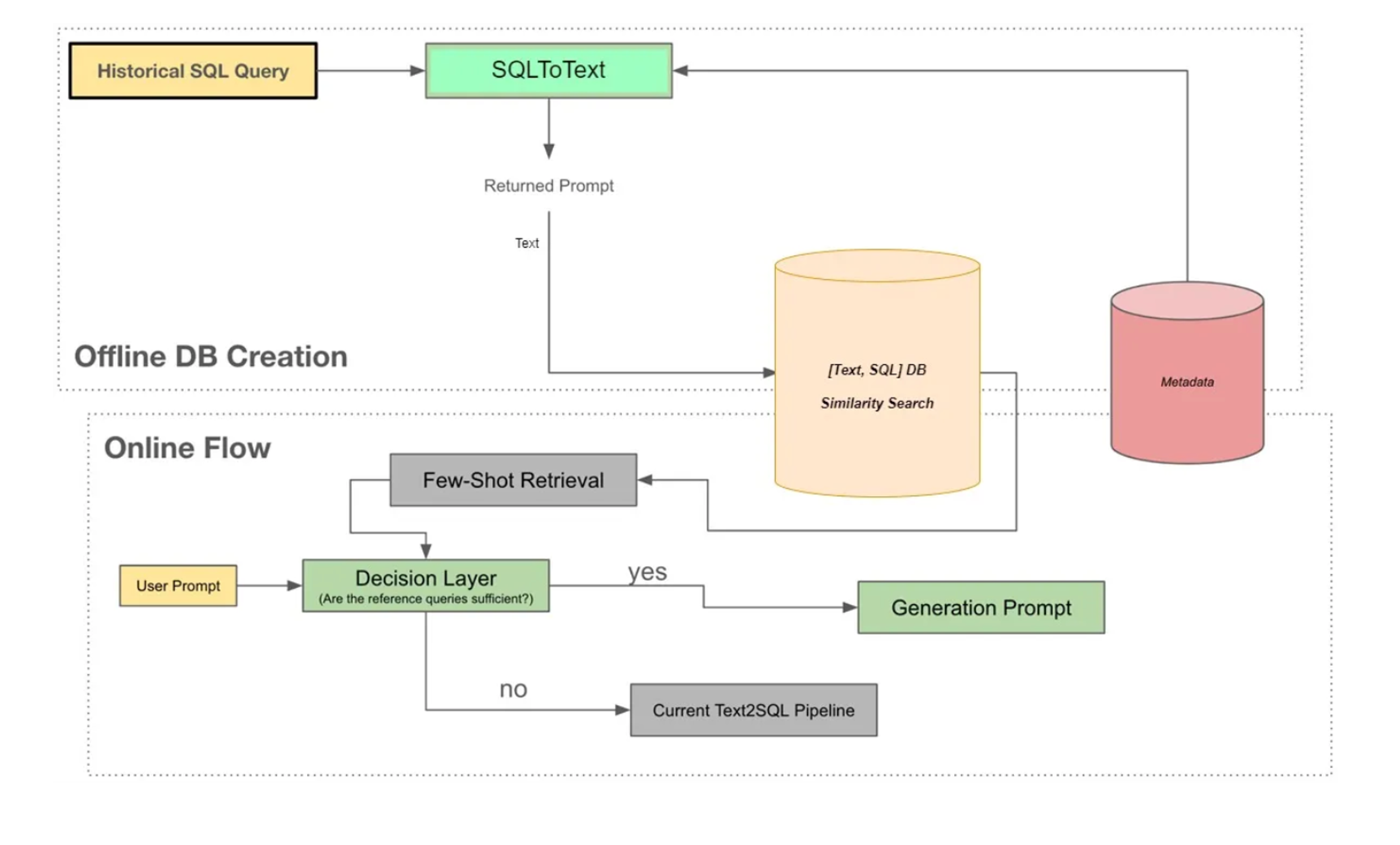
Hermes V3 的整体工作流程
Hermes V3 还引入了会话记忆能力,支持真正的多轮交互。用户在提问时无需反复补充背景信息,系统会自动跟踪当前会话状态,在已有上下文基础上继续推理,将简单指标逐步扩展为更复杂的组合查询。
在系统内部,一个编排型智能体(orchestrator agent)采用类似 ReAct 的推理循环,将复杂问题拆解为一系列清晰、可复用的步骤,包括意图解析、问题完整性校验、元数据查找、示例检索、中间逻辑构建、SQL 生成,以及在必要时向用户发起澄清请求。
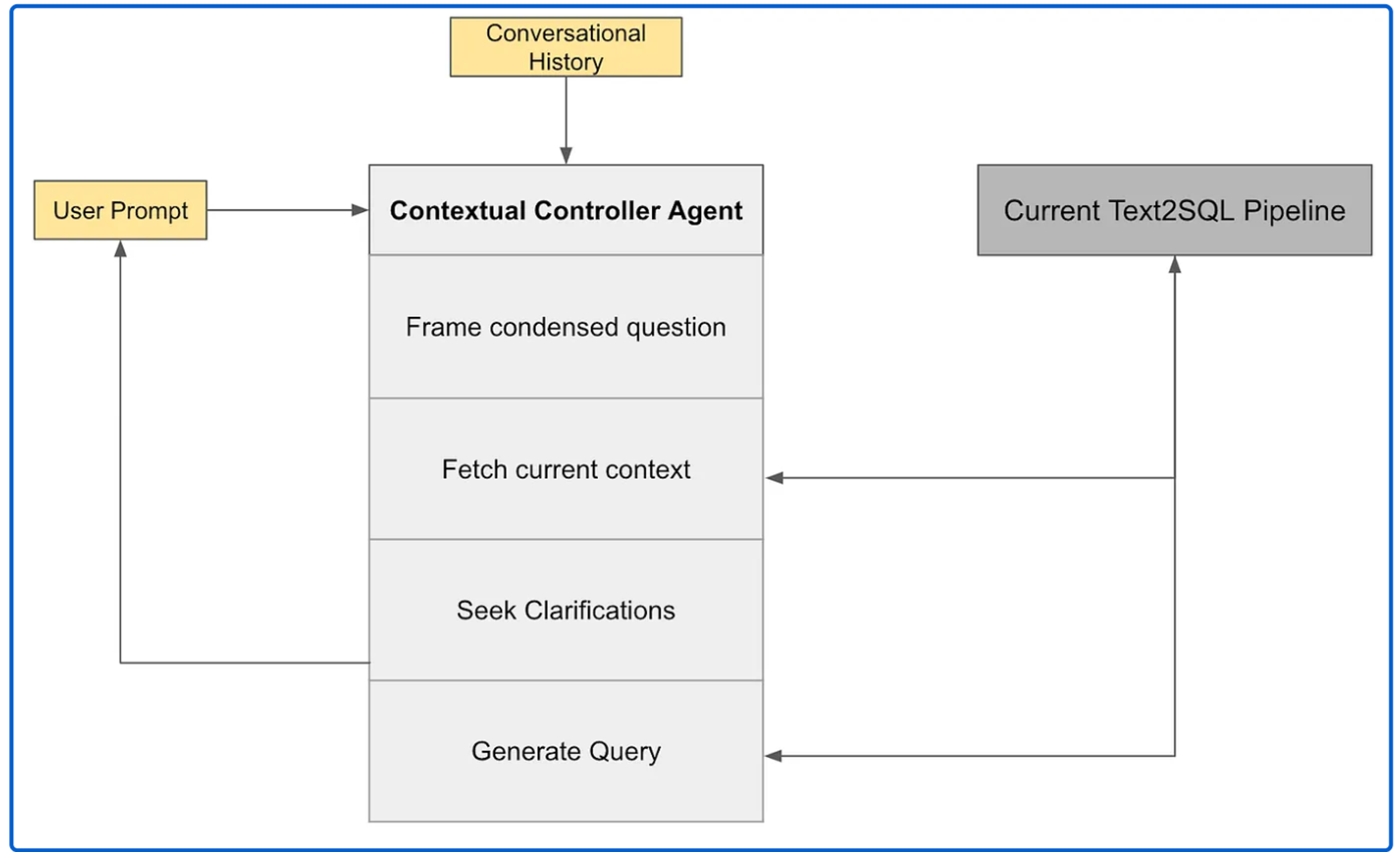
查询生成中的结构化智能体工作流程
另一个关键改进,是 Hermes V3 增加了解释层。系统会主动展示生成 SQL 时所依据的假设,并为结果给出置信度评分。这种做法让非技术背景的业务人员也能理解查询是如何形成的,从而提升对机器生成分析结果的信任度。
在基础设施层面,Hermes V3 与 Swiggy 现有的安全、合规和元数据体系进行了深度整合。通过基于角色的访问控制(RBAC)、单点登录(SSO)、临时响应机制以及审计日志,系统确保对敏感数据的访问符合内部治理要求。同时,Hermes 采用混合式元数据检索策略,高效获取相关 schema、数据表和字段信息,在控制 token 使用量的同时,保证查询性能。
从整体架构来看,Hermes 覆盖了多种开源与云原生技术组件。检索模块基于向量数据库和嵌入模型实现;智能体编排逻辑借助 LangChain 等工具构建结构化提示工作流;数据溯源和运行监控则通过可观测性框架完成。Snowflake 等分析型数据库、PostgreSQL 等事务型数据库,以及 API 网关,共同构成了支撑 Hermes 正常运行的技术生态。
原文链接:
https://www.infoq.com/news/2026/01/swiggy-hermes-conversational-ai/




