
最快的分析查询,总是那些读取数据量最少的查询。我们深知这一点的重要性,因为事实确实如此!
ClickHouse 提供了多种方法来实现这一目标。在本文中,我们将以英国房地产销售数据集为例,深入探讨三种基于索引的剪枝技术——助您精准掌握其适用场景与时机。
剪枝技术 1:主索引 (Primary Index)
首项剪枝技术是主键 (Primary Key),这也是创建数据表时首先需要掌握的概念之一。数据表的主键决定了数据分片 (Data Part) 内数据的排序方式。
数据分片由数据粒 (Granule) 组成,每个数据粒默认包含 8,192 行。ClickHouse 的主索引 (Primary Index) 会存储 每个数据粒中首行的主键列值。
如下图所示,数据按主键 C1 排序,行被组织成多个数据粒(从 g1 到 g4)。为便于理解,图中每个数据粒仅包含 3 行。主索引存储每个数据粒的首个值,例如 g1 为 10,g2 为 20,依此类推。
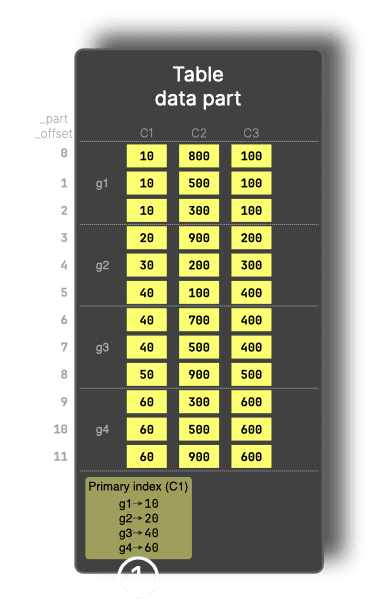
主索引能够根据主键上的过滤条件,在数据读取之前跳过整个数据粒。例如,对于包含 WHERE C1 > 60 的查询,数据粒 g1 和 g2 将通过主索引进行剪枝,从而仅读取剩余的数据。
剪枝技术 2:轻量级投影 (Lightweight Projections)
我们的下一项剪枝技术是 轻量级投影,该功能最初在 ClickHouse 25.6 版本中引入,并在 ClickHouse 26.1 版本中获得了更易用的语法。
ClickHouse 中的投影 (Projection) 是自动维护的隐藏表副本,它们以不同的排序方式存储,因此拥有不同的主索引。这些替代的布局能够加速那些受益于特定排序的查询。但其缺点在于,投影会在磁盘上复制基础表的数据。
轻量级投影 (Lightweight projections) 的行为类似于二级索引,但无需复制完整的行。它们不存储完整的数据副本,而是仅存储其排序键以及一个指向基础表的 _part_offset 指针。这大大减少了存储开销,但意味着任何其他需要返回的列都必须从基础表读取。
我们可以通过更新图表来了解其工作原理,即在 C2 上添加一个轻量级投影:
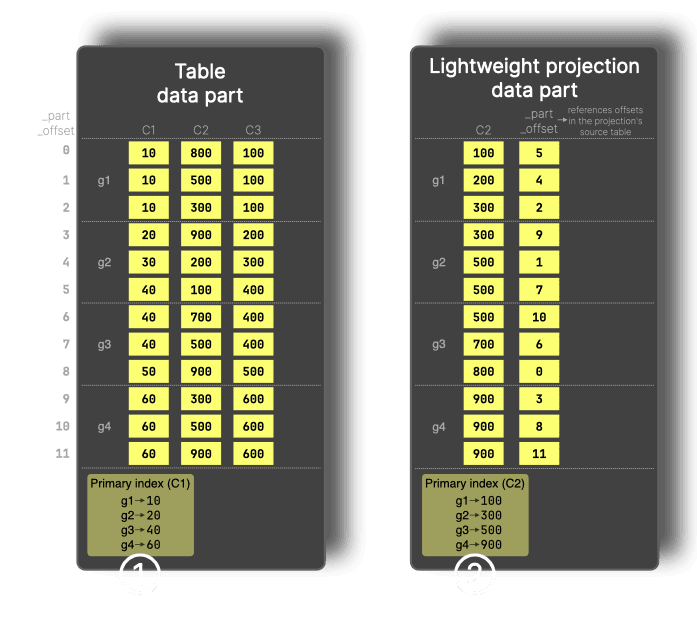
对于不属于主键 (primary key) 的列上的筛选条件,例如 WHERE C2 > 900,ClickHouse 可以使用轻量级投影。这种投影存储排序后的投影键 (C2) 值和 _part_offset 值,并提供其自身的主索引 (primary index) (②),该索引允许根据投影键上的筛选条件对数据粒度 (granule) 进行剪枝 (pruning)。
剪枝技术 3:跳过索引
我们介绍的最后一个技术是跳过索引 (Skip indexes)。其中一种跳过索引是 minmax 索引 (minmax index),它记录了每个数据粒度 (granule) 中某一列的最小值和最大值。
ClickHouse 支持 minmax 索引已有五年多,但我们最近新增了支持,可以自动为表中特定类型的每个列创建这些索引。
minmax 索引相对于轻量级投影 (Lightweight projection) 的优势在于,它不会在磁盘上重复存储列值。然而,需要注意的是,应用 minmax 索引的列需要与主键 (primary key) 具有一定的相关性,否则该索引将无法有效地剪枝数据。
在下图中,minmax 索引 (③) 记录了每个数据粒度 (granule) 中 C3 列的最小值和最大值。
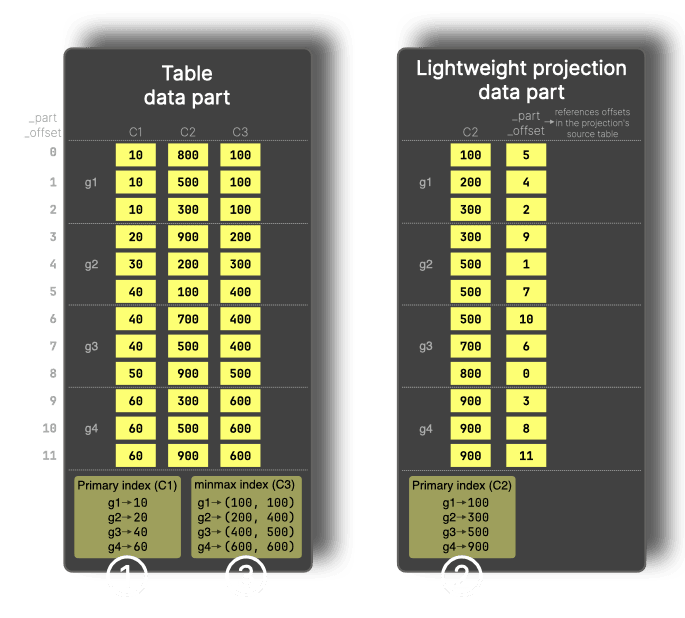
对于 WHERE C3 > 600 这样的筛选条件,由于 g1 到 g3 这些数据粒度 (granule) 的最大值都低于 600,因此可以跳过它们,只需读取 g4。
剪枝实践:英国房地产数据集
既然我们已经对每种剪枝技术有了宏观的了解,接下来让我们学习如何在真实数据集上将它们付诸实践。我们将使用 英国房地产价格数据集,其中包含英国房地产销售的详细信息。
我们将在配备 64GB 内存的 Apple Mac M2 Max 上运行所有查询。
导入英国房地产数据集
让我们首先创建表:
CREATE OR REPLACE TABLE uk_price_paid( price UInt32, date Date, postcode1 LowCardinality(String), postcode2 LowCardinality(String), type Enum8('terraced' = 1, 'semi-detached' = 2, 'detached' = 3, 'flat' = 4, 'other' = 0), is_new UInt8, duration Enum8('freehold' = 1, 'leasehold' = 2, 'unknown' = 0), addr1 String, addr2 String, street LowCardinality(String), locality LowCardinality(String), town LowCardinality(String), district LowCardinality(String), county LowCardinality(String))ENGINE = MergeTreeORDER BY (postcode1, postcode2, addr1, addr2);主键(除非另有说明,它与 ORDER BY 语句的定义一致)是 (postcode1, postcode2, addr1, addr2)。
表创建完成后,我们将导入数据:
INSERT INTO uk_price_paidSELECT *FROM file('uk_all.parquet');我首先从 pp-complete.csv 导入数据(相关文档),然后将其导出为 Parquet 格式,从而创建了 uk_all.parquet 文件。
运行插入查询的输出如下所示:
30452463 rows in set. Elapsed: 5.366 sec. Processed 30.45 million rows, 170.44 MB (5.68 million rows/s., 31.76 MB/s.)Peak memory usage: 774.00 MiB.该数据集包含 3000 万行,按照 ClickHouse 的标准来看相对较小。我们可以通过多次导入 Parquet 文件来增加数据量,但还有一种更快的方法,即使用 ATTACH PARTITION 命令。
以下命令会复制表中的所有数据块 (parts),使数据量翻倍:
ALTER TABLE uk_price_paid ATTACH PARTITION ID 'all' FROM uk_price_paid;我运行了几次该命令,以便我们有足够的数据进行操作。作为参考,以下是运行查询三次的输出:
0 rows in set. Elapsed: 0.167 sec.0 rows in set. Elapsed: 0.458 sec.0 rows in set. Elapsed: 0.412 sec.我们可以编写以下查询来返回表中记录的数量:
SELECT count()FROM uk_price_paid;┌───count()─┐│ 243619704 │ -- 243.62 million└───────────┘1 row in set. Elapsed: 0.001 sec.通过主索引过滤
让我们从编写一个基于主键过滤的查询开始。以下查询返回 Croydon(伦敦的一个郊区)出售的房产数量以及平均销售价格:
SELECT postcode1, count(), avg(price)FROM uk_price_paidWHERE postcode1 LIKE 'CR%'GROUP BY ALLORDER BY count() DESCSETTINGS output_format_pretty_single_large_number_tip_threshold=0, use_query_condition_cache=0;运行此查询的输出如下所示:
┌─postcode1─┬─count()─┬─────────avg(price)─┐│ CR0 │ 573952 │ 264860.4016363738 ││ CR2 │ 219464 │ 287568.45715014765 ││ CR4 │ 192912 │ 218234.12212822426 ││ CR3 │ 155304 │ 306863.8307319837 ││ CR8 │ 147880 │ 373809.7425480119 ││ CR7 │ 141152 │ 211355.8734413965 ││ CR5 │ 123112 │ 355812.51777243486 ││ CR6 │ 47920 │ 384279.0923205342 ││ CR9 │ 352 │ 12324871.113636363 ││ CR24 │ 16 │ 25000 │└───────────┴─────────┴────────────────────┘10 rows in set. Elapsed: 0.030 sec.10 rows in set. Elapsed: 0.015 sec.10 rows in set. Elapsed: 0.021 sec.最好的查询时间为 15 毫秒,对于一个包含超过 2 亿条记录的表的查询来说,这个表现相当不错。
如果我们使用 EXPLAIN indexes=1, pretty=1, compact=1 命令作为查询前缀,就可以查看其查询计划:
┌─explain─────────────────────────────────────────────┐ 1. │ Output: postcode1, count(), avg(price) │ 2. │ │ 3. │ Sorting (Sorting for ORDER BY) │ 4. │ └──Aggregating │ 5. │ └──ReadFromMergeTree (default.uk_price_paid) │ 6. │ Indexes: │ 7. │ PrimaryKey │ 8. │ Keys: │ 9. │ postcode1 │10. │ Condition: (postcode1 in ['CR', 'CS')) │11. │ Parts: 36/36 │12. │ Granules: 235/29751 │13. │ Search Algorithm: binary search │14. │ Ranges: 36 │ └─────────────────────────────────────────────────────┘在第 12 行,我们可以看到查询引擎只需处理 29,751 个数据粒度 (granule) 中的 235 个(不到 1%),即可运行此查询。
我们可以通过查询 system.query_log 表来查看处理了多少行数据:
SELECT event_time, query, read_rowsFROM system.query_logWHERE type = 'QueryFinish' AND query NOT LIKE '%query_log%'ORDER BY event_time DESC LIMIT 1FORMAT Vertical;Row 1:──────event_time: 2026-04-09 10:37:22query: SELECT postcode1, count(), avg(price)...read_rows: 1687552 -- 1.69 million我们的查询从总计 2.43 亿行数据中读取了 160 万行,因此可以肯定地说,主索引在减少所需读取数据量方面发挥了出色作用。
当过滤属于主键的多个列时,只要这些列构成整个主键的前缀,主索引就会非常有效。
我们的主键是 (postcode1, postcode2, addr1, addr2),因此,例如,仅对 postcode1 和 postcode2 进行过滤将是高效的。
SELECT postcode1, postcode2, count(), avg(price)FROM uk_price_paidWHERE postcode1 LIKE 'CR%' AND postcode2 LIKE '4%'GROUP BY ALLORDER BY count() DESC LIMIT 10SETTINGS output_format_pretty_single_large_number_tip_threshold=0, use_query_condition_cache=0;┌─postcode1─┬─postcode2─┬─count()─┬─────────avg(price)─┐│ CR4 │ 4FD │ 2496 │ 136439.84935897434 ││ CR4 │ 4FF │ 2056 │ 111415.15953307394 ││ CR4 │ 4FE │ 1376 │ 98730.37790697675 ││ CR4 │ 4LT │ 1320 │ 104595.98787878788 ││ CR0 │ 4UX │ 1240 │ 118912.51612903226 ││ CR8 │ 4DZ │ 1200 │ 103860 ││ CR0 │ 4TX │ 1184 │ 110415.50675675676 ││ CR0 │ 4HB │ 1152 │ 162919.75694444444 ││ CR0 │ 4FG │ 1144 │ 230394.2097902098 ││ CR0 │ 4GA │ 1032 │ 211535.29457364342 │└───────────┴───────────┴─────────┴────────────────────┘10 rows in set. Elapsed: 0.015 sec. Processed 638.98 thousand rows, 3.30 MB (42.27 million rows/s., 218.59 MB/s.)Peak memory usage: 3.92 MiB.此查询处理了 2.43 亿行中的略多于 63 万行。
如果仅根据 postcode2 进行过滤,尽管它是主键的一部分,但并非第一个键列,效率将不会那么高:
SELECT postcode1, postcode2, count(), avg(price)FROM uk_price_paidWHERE postcode2 LIKE '4%'GROUP BY ALLORDER BY count() DESC LIMIT 10SETTINGS output_format_pretty_single_large_number_tip_threshold=0, use_query_condition_cache=0;┌─postcode1─┬─postcode2─┬─count()─┬─────────avg(price)─┐│ TR8 │ 4LX │ 3328 │ 67047.70913461539 ││ CR4 │ 4FD │ 2496 │ 136439.84935897434 ││ SS16 │ 4TY │ 2328 │ 85003.52233676976 ││ NR29 │ 4NW │ 2328 │ 36411.996563573884 ││ SS16 │ 4TQ │ 2184 │ 88534.72161172162 ││ SS16 │ 4TD │ 2160 │ 67603.75925925926 ││ BS4 │ 4EY │ 2104 │ 100474.69201520912 ││ RG22 │ 4UR │ 2096 │ 143119.3893129771 ││ BB11 │ 4JZ │ 2096 │ 29956.74427480916 ││ LS1 │ 4ES │ 2088 │ 256009.9655172414 │└───────────┴───────────┴─────────┴────────────────────┘10 rows in set. Elapsed: 0.787 sec. Processed 138.82 million rows, 572.89 MB (176.47 million rows/s., 728.26 MB/s.)Peak memory usage: 146.53 MiB.它现在扫描了 1.38 亿行,返回结果所需时间是之前的 50 倍。如果我们解释这个查询,将看到以下输出:
┌─explain───────────────────────────────────────────────────────────┐ 1. │ Expression (Project names) │ 2. │ Limit (preliminary LIMIT) │ 3. │ Sorting (Sorting for ORDER BY) │ 4. │ Expression ((Before ORDER BY + Projection)) │ 5. │ Aggregating │ 6. │ Expression (Before GROUP BY) │ 7. │ Expression ((WHERE + Change column names to column id⋯│ 8. │ ReadFromMergeTree (default.uk_price_paid) │ 9. │ Indexes: │10. │ PrimaryKey │11. │ Keys: │12. │ postcode2 │13. │ Condition: (postcode2 in ['4', '5')) │14. │ Parts: 11/11 │15. │ Granules: 16950/29744 │16. │ Search Algorithm: generic exclusion search │17. │ Ranges: 7066 │ └───────────────────────────────────────────────────────────────────┘查询引擎可以使用主键排除近一半的 granules(第 15 行),但在第 16 行,我们看到它正在使用通用排除搜索算法。该算法的效率取决于 postcode2 列与其前继键列 postcode1 之间的基数差异。您可以在文档中查看一个分步示例,但核心要点是:当前继列具有较低基数时,算法效率较高;而当前继列具有较高基数时,效率则不那么高。
在下一节中,我们将探讨如何通过完全不属于主键的列进行更高效的过滤。
通过轻量级投影过滤
通过主索引过滤是最佳技术,在设计表时,确保数据按您最可能进行过滤的列排序,是应牢记的重要一点。
但通常,我们也希望通过其他列进行查询。例如,假设我们想查找当 district = ‘BURNLEY’ 时,按城镇划分的已售房产数量:
SELECT town, count(), round(avg(price)) AS avgPrice, argAndMax(date, price)FROM uk_price_paidWHERE district = 'BURNLEY'GROUP BY ALLORDER BY count() DESC LIMIT 10SETTINGS use_query_condition_cache = 0;多次运行此查询的输出如下所示:
10 rows in set. Elapsed: 0.428 sec. Processed 240.96 million rows, 480.72 MB (562.98 million rows/s., 1.12 GB/s.)Peak memory usage: 841.37 KiB.10 rows in set. Elapsed: 0.466 sec. Processed 219.79 million rows, 438.38 MB (471.16 million rows/s., 939.77 MB/s.)Peak memory usage: 852.86 KiB.10 rows in set. Elapsed: 0.481 sec. Processed 207.87 million rows, 414.50 MB (432.32 million rows/s., 862.05 MB/s.)Peak memory usage: 844.83 KiB.查询引擎必须处理数据集中的几乎所有行才能响应此查询。
让我们看看是否可以通过在 district 列上添加轻量级投影来提升性能:
ALTER TABLE uk_price_paidADD PROJECTION by_district INDEX district TYPE basic;我们将物化该投影,以便能够立即使用:
ALTER TABLE uk_price_paidMATERIALIZE PROJECTION by_districtSETTINGS mutations_sync=1;0 rows in set. Elapsed: 14.480 sec.现在,让我们使用投影运行查询:
SELECT town, count(), round(avg(price)) AS avgPrice, argAndMax(date, price)FROM uk_price_paidWHERE district = 'BURNLEY'GROUP BY ALLORDER BY count() DESC LIMIT 10SETTINGS use_query_condition_cache = 0, optimize_use_projections = 1;optimize_use_projections 默认是启用的,但我们将其包含在此处为求完整。如果您关闭它,投影将不会被使用。这对于检查您的投影是否确实生效非常有用!
运行上述查询的耗时如下所示:
10 rows in set. Elapsed: 0.023 sec.10 rows in set. Elapsed: 0.056 sec.10 rows in set. Elapsed: 0.046 sec.对于 BURNLEY 查询,在 district 列上使用轻量级投影将查询时间从 428 毫秒减少到 23 毫秒,性能提升了 94%。
现在,让我们深入了解其内部机制。我首先在查询前加上了之前用过的 explain 子句:
EXPLAIN indexes=1, pretty=1, compact= 1 SELECT town, count(), round(avg(price)) AS avgPrice, argAndMax(date, price)FROM uk_price_paidWHERE district = 'BURNLEY'GROUP BY ALLORDER BY count() DESC LIMIT 10SETTINGS use_query_condition_cache = 0, optimize_use_projections = 1;┌─explain─────────────────────────────────────────────────┐│ Output: town, count(), avgPrice, argAndMax(date, price) ││ ││ Limit (preliminary LIMIT) ││ └──Sorting (Sorting for ORDER BY) ││ └──Aggregating ││ └──ReadFromMergeTree (default.uk_price_paid) ││ Indexes: ││ PrimaryKey ││ Condition: true ││ Parts: 6/6 ││ Granules: 29741/29741 ││ Ranges: 6 │└─────────────────────────────────────────────────────────┘这个输出无法提供有效信息,因为它只包含了带有主键索引信息的基础查询计划。我们需要额外添加 projections=1,以便在输出中包含投影(projection)分析:
EXPLAIN indexes=1, projections=1, pretty=1, compact= 1 SELECT town, count(), round(avg(price)) AS avgPrice, argAndMax(date, price)FROM uk_price_paidWHERE district = 'BURNLEY'GROUP BY ALLORDER BY count() DESC LIMIT 10SETTINGS use_query_condition_cache = 0, optimize_use_projections = 1, output_format_pretty_max_value_width=65, output_format_pretty_row_numbers=1;┌─explain───────────────────────────────────────────────────────────┐ 1. │ Output: town, count(), avgPrice, argAndMax(date, price) │ 2. │ │ 3. │ Limit (preliminary LIMIT) │ 4. │ └──Sorting (Sorting for ORDER BY) │ 5. │ └──Aggregating │ 6. │ └──ReadFromMergeTree (default.uk_price_paid) │ 7. │ Indexes: │ 8. │ PrimaryKey │ 9. │ Condition: true │10. │ Parts: 11/11 │11. │ Granules: 29744/29744 │12. │ Ranges: 11 13. │ Projections: │14. │ Name: by_district │15. │ Description: Projection has been analyzed and wil⋯│16. │ Condition: (district in ['BURNLEY', 'BURNLEY']) │17. │ Search Algorithm: binary search │18. │ Parts: 11 │19. │ Marks: 72 │20. │ Ranges: 11 │21. │ Rows: 589824 │22. │ Filtered Parts: 0 │ └───────────────────────────────────────────────────────────────────┘让我们逐一分析这里发生的情况,首先从索引部分开始:
主键索引未能对该查询发挥作用 —— 第 9 行的 Condition: true 表示它没有应用任何过滤条件,因此所有 11 个分片(part,第 10 行)和 29,744 个数据粒(granule,第 11 行)都必须被处理。
接下来是投影部分:
第 22 行的 Filtered Parts: 0 表明没有任何分片(part)被完全排除,这意味着 BURNLEY 出现在所有 11 个分片中;
第 19 行将搜索范围缩小到 72 个数据粒(granule)(或标记);
默认情况下,每个数据粒(granule)包含 8,192 行,由此得出了第 21 行的计数 (72 * 8,192=589,824);
这 72 个数据粒(granule)分布在 11 个分片(part)(第 18 行)中;由于 BURNLEY 的数据行在每个分片内部都是连续存储的,因此每个分片都有一个连续的范围,总计 11 个范围(第 20 行)。
下表展示了与 Burnley 相比,售出房产数量更多和更少的地区,在使用和不使用投影(projection)时的耗时:
我在使用投影(projection)和不使用投影的情况下,分别运行了三次查询,并取其最低耗时。
我们可以看到,当使用投影(projection)时,所有这些地区的查询耗时都实现了至少 75% 的提升。
轻量级投影(lightweight projection)的一个值得关注的特性是,我们可以将它们组合起来,从而在多个独立的排序顺序上实现行级过滤。例如,我们可以在 date 列上添加另一个轻量级投影:
ALTER TABLE uk_price_paidADD PROJECTION by_date INDEX date TYPE basic;ALTER TABLE uk_price_paidMATERIALIZE PROJECTION by_dateSETTINGS mutations_sync=1;一个同时按 district 和 date 进行过滤的查询(例如,查找 2023 年 1 月在 Manchester 售出的房产),将会用到这两个轻量级投影:
SELECT town, count(), round(avg(price)) AS avgPrice, argAndMax(date, price)FROM uk_price_paidWHERE (district = 'MANCHESTER') AND (date BETWEEN '2023-01-01' AND '2023-01-31'GROUP BY ALLORDER BY count() DESCLIMIT 10SETTINGS use_query_condition_cache = 0, optimize_use_projections = 1;┌─town───────┬─count()─┬─avgPrice─┬─argAndMax(date, price)─┐│ MANCHESTER │ 3656 │ 266818 │ ('2023-01-13',3000000) ││ SALFORD │ 24 │ 341667 │ ('2023-01-31',670000) │└────────────┴─────────┴──────────┴────────────────────────┘该查询的 explain 输出如下所示:
┌─explain───────────────────────────────────────────────────────────┐ 1. │ Output: town, count(), avgPrice, argAndMax(date, price) │ 2. │ │ 3. │ Limit (preliminary LIMIT) │4. │ └──Sorting (Sorting for ORDER BY) │ 5. │ └──Aggregating │6. │ └──ReadFromMergeTree (default.uk_price_paid) │ 7. │ Indexes: │ 8. │ PrimaryKey │ 9. │ Condition: true │10. │ Parts: 11/11 │11. │ Granules: 29744/29744 │12. │ Ranges: 11 │13. │ Projections: │14. │ Name: by_district │15. │ Description: Projection has been analyzed and wil⋯│16. │ Condition: (district in ['MANCHESTER', 'MANCHESTE⋯│17. │ Search Algorithm: binary search │18. │ Parts: 11 │19. │ Marks: 247 │20. │ Ranges: 11 │21. │ Rows: 2023424 │22. │ Filtered Parts: 0 │23. │ Name: by_date │24. │ Description: Projection has been analyzed and wil⋯│25. │ Condition: and((date in (-Inf, 19388]), (date in ⋯│26. │ Search Algorithm: binary search │27. │ Parts: 11 │28. │ Marks: 71 │29. │ Ranges: 11 │30. │ Rows: 581632 │31. │ Filtered Parts: 0 │ └───────────────────────────────────────────────────────────────────┘每个投影都会独立计算出哪些部分和数据颗粒符合其过滤条件,而从基表读取的行集则是二者的交集。
为了分别以及共同考察这些轻量级投影的效果,我们将创建两个额外的表,每个表包含一个轻量级投影。
首先,uk_price_paid_by_date 表将仅包含 by_date 轻量级投影:
CREATE TABLE uk_price_paid_by_dateCLONE AS uk_price_paid;ALTER TABLE uk_price_paid_by_date DROP PROJECTION by_district;而 uk_price_paid_by_district 表将仅包含 by_district 轻量级投影:
CREATE TABLE uk_price_paid_by_district CLONE AS uk_price_paid;ALTER TABLE uk_price_paid_by_district DROP PROJECTION by_date;现在,我们将针对每个表运行之前查询 2023 年 1 月在曼彻斯特售出房产的语句。我们将对每个表运行三次,并记录最短耗时和处理的行数:
仅凭 by_date 轻量级投影,我们并未观察到显著的性能提升。尽管该投影已将匹配行数缩小到约 50 万行(即 2023 年 1 月售出的房产),但这些行分散在基表全部 2.43 亿行数据中。因此,查询引擎仍然不得不遍历大部分数据才能检索到它们,然后才能最终过滤出曼彻斯特区域的数据。
我们可以通过编写以下查询来验证上述观察结果,该查询用于计算需要扫描多少数据颗粒才能找到 2023 年 1 月售出房产的所有匹配行:
SELECT uniqExact((_part, intDiv(_part_offset, 8192))) AS granulesWithMatchingRows, ( SELECT sum(marks) FROM system.parts WHERE (\`table\` = 'uk_price_paid_by_date') AND active ) AS totalGranules, round((granulesWithMatchingRows / totalGranules) * 100, 2) AS pctFROM uk_price_paid_by_dateWHERE (date >= '2023-01-01') AND (date <= '2023-01-31');┌─granulesWithMatchingRows─┬─totalGranules─┬──pct─┐│ 29724 │ 29755 │ 99.9 │└──────────────────────────┴───────────────┴──────┘我们正在扫描 29,724 个数据颗粒,即大约 243,499,008 行(29,724*8,192),以找到匹配行。
让我们看另一个例子,在该例子中我们在日期过滤上更精确,在区域过滤上更宽松。以下查询将找出 2023 年 2 月 1 日在曼彻斯特、伯明翰、萨顿和威拉尔售出的房产数据:
SELECT town, count(), round(avg(price)) AS avgPrice, argAndMax(date, price)FROM uk_price_paidWHERE (district IN ('MANCHESTER', 'BIRMINGHAM', 'SUTTON', 'WIRRAL'))AND (date = '2023-02-01')GROUP BY ALLORDER BY count() DESCLIMIT 10SETTINGS use_query_condition_cache = 0, optimize_use_projections = 1;同样,我们将对每个表运行三次,并记录最短耗时和处理的行数:
这次,by_date 在数据过滤方面的表现优于 by_district,但当这两个轻量级投影共同作用时,我们能获得最佳性能。
按 minmax 索引过滤
我们最后一种剪枝技术是 minmax 索引(minmax index),它是一种跳跃索引(skip index)。需要快速提醒的是,任何添加了跳跃索引的列都必须与主键(primary key)相关联;否则,该索引将无法生效。
我们将为 price 列添加一个 minmax 索引,以便更高效地过滤价格。价格与邮政编码(postcode)之间存在一定关联,因为同一地理区域的房产通常会在相似的价格区间内出售:例如,伦敦高价邮政编码(如 SW1、W1)的房产价格普遍偏高,而农村地区的邮政编码则普遍偏低。这意味着查询引擎(query engine)在按价格搜索时应该能够跳过数据粒度(granules)。
我们可以通过以下查询添加 minmax 索引:
ALTER TABLE uk_price_paidADD INDEX price_minmax price TYPE minmax GRANULARITY 1;我们将物化(materialize)该索引,从而能立即投入使用:
ALTER TABLE uk_price_paidMATERIALIZE INDEX price_minmaxSETTINGS mutations_sync=1;接下来,我们将编写一个查询,以找出销售价格超过 10,000,000 英镑的房产最多的行政区:
SELECT district, count(), formatReadableQuantity(avg(price)) AS avgPriceFROM uk_price_paidWHERE price > 10000000GROUP BY ALLORDER BY count() DESCLIMIT 10SETTINGS use_query_condition_cache = 0, use_skip_indexes = 1;
use_skip_indexes设置默认启用,但我们可以将其关闭,以评估跳跃索引带来的影响。
运行查询的结果如下所示:
┌─district───────────────┬─count()─┬─avgPrice──────┐│ CITY OF WESTMINSTER │ 13880 │ 32.61 million ││ KENSINGTON AND CHELSEA │ 7120 │ 19.22 million ││ CAMDEN │ 3616 │ 34.78 million ││ CITY OF LONDON │ 2448 │ 50.09 million ││ TOWER HAMLETS │ 2392 │ 43.70 million ││ MANCHESTER │ 1752 │ 24.71 million ││ SOUTHWARK │ 1712 │ 37.31 million ││ BIRMINGHAM │ 1520 │ 27.66 million ││ ISLINGTON │ 1504 │ 35.81 million ││ LEEDS │ 1328 │ 24.94 million │└────────────────────────┴─────────┴───────────────┘我在未启用跳跃索引(即 use_skip_indexes=0)的情况下运行了三次此查询:
10 rows in set. Elapsed: 0.347 sec. Processed 243.62 million rows, 1.09 GB (701.77 million rows/s., 3.13 GB/s.)Peak memory usage: 6.21 MiB.10 rows in set. Elapsed: 0.506 sec. Processed 243.62 million rows, 1.09 GB (481.02 million rows/s., 2.15 GB/s.)Peak memory usage: 6.21 MiB.10 rows in set. Elapsed: 0.390 sec. Processed 243.62 million rows, 1.09 GB (624.22 million rows/s., 2.78 GB/s.)Peak memory usage: 6.21 MiB.随后,在启用跳跃索引(即 use_skip_indexes=1)的情况下又运行了三次:
10 rows in set. Elapsed: 0.312 sec. Processed 116.41 million rows, 578.67 MB (373.50 million rows/s., 1.86 GB/s.)Peak memory usage: 5.46 MiB.10 rows in set. Elapsed: 0.306 sec. Processed 116.41 million rows, 578.67 MB (380.51 million rows/s., 1.89 GB/s.)Peak memory usage: 5.46 MiB.10 rows in set. Elapsed: 0.304 sec. Processed 116.41 million rows, 578.67 MB (382.48 million rows/s., 1.90 GB/s.)Peak memory usage: 5.49 MiB.未启用跳跃索引(skip index)时的最优耗时为 304 毫秒,而启用跳跃索引后的最优耗时为 234 毫秒,性能提升约 23%。
启用跳跃索引的查询处理的行数减少了约一半。我们可以通过解释查询(explaining the query)来查看被忽略的数据:
EXPLAIN indexes=1, projections=1, pretty=1, compact=1输出结果如下所示:
┌─explain────────────────────────────────────────────────┐ 1. │ Output: district, count(), avgPrice │ 2. │ │ 3. │ Limit (preliminary LIMIT) │ 4. │ └──Sorting (Sorting for ORDER BY) │ 5. │ └──Aggregating │ 6. │ └──ReadFromMergeTree (default.uk_price_paid) │ 7. │ Indexes: │ 8. │ PrimaryKey │ 9. │ Condition: true │10. │ Parts: 11/11 │11. │ Granules: 29744/29744 │12. │ Skip │13. │ Name: price_minmax │14. │ Description: minmax GRANULARITY 1 │15. │ Condition: (price in [10000001, +Inf)) │16. │ Parts: 11/11 │17. │ Granules: 14214/29744 │18. │ Ranges: 6034 │ └────────────────────────────────────────────────────────┘从第 17 行可以看出,跳跃索引排除了略高于 15,000 个数据粒度。
结论
这篇博文向我们介绍了 ClickHouse 提供的三种基于索引的剪枝技术:主索引(primary index)、轻量级投影(lightweight projections)和跳跃索引。
其中,主索引的功能最为强大。在设计 ORDER BY 子句时,应围绕最常用的过滤列进行。
轻量级投影是针对非主键列进行过滤的有效选择。通过结合多个投影,ClickHouse 可以对结果进行交集运算,从而实现更高效的剪枝。
最后,像 minmax 这样的跳跃索引,仅当目标列与主键相关联时最能发挥作用;如果缺乏这种关联,它们的效果将大打折扣。
/END/
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出 &图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com。






