Netflix 内容平台工程团队运行由微服务上执行的任务的异步编排驱动的多个业务流程。其中一些是长期运行的流程,跨越几天。这些流程在准备好标题流式传输给全球的观众上发挥关键作用。
这些流程的几个实例是:
- 用于内容提取的 Studio 合作伙伴集成
- 基于 IMF 的内容提取我们的合作伙伴
- 在 Netflix 中设置新标题的过程
- 内容提取、编码和部署到 CDN
传统上,这些流程中的一些已经以 ad-hoc 方式使用 pub/sub 的组合来编排,进行直接 REST 调用,并使用数据库来管理状态。然而,随着微服务数量的增长和进程的复杂性增加,在没有中央编排器的情况下,获得对这些分布式工作流的可见性变得困难。
我们将 Conductor 构建为一个编排引擎,以满足以下要求,取出在应用程序中需要的样板,并提供一个反应流:
- 基于蓝图。基于 JSON DSL 的蓝图定义执行流程。
- 跟踪和管理工作流。
- 能够暂停、恢复和重新启动进程。
- 能够扩展到数百万个并发运行的进程流。
- 由从客户端抽象的排队服务支持。
- 能够通过 HTTP 或其他传输方式进行操作,如 gRPC。
Conductor 是为满足上述需求而开发的,并且在 Netflix 已经使用了将近一年。到目前为止,它已经帮助编排超过 260 万个流程流,从简单的线性工作流到运行多天的非常复杂的动态工作流。
今天,我们为广泛的社区开源了 Conductor ,希望从有类似需求的人那里学习,并增强其能力。你可以在这里找到 Conductor 的开发文档。
为什么不是点对点编排?
随着点对点任务编排,我们发现越来越多的业务需求和复杂性难以扩展。Pub/sub 模型工作的最简单的流程,但很快强调了与该方法相关的一些问题:
- 流程流“嵌入”多个应用程序代码中。
- 通常情况下,有关于输入 / 输出,SLA 等的紧耦合和假设,使其更难适应不断变化的需求。
- 几乎没有办法系统地回答“What is remaining for a movie’s setup to be complete”?
为什么是微服务?
在微服务世界中,许多业务流程自动化是通过跨服务编排来驱动的。Conductor 可以跨服务实现编排,同时提供对其交互的控制和可见性。具有编排跨微服务的能力也帮助我们利用现有服务来构建新流或更新现有流,以便非常迅速地使用 Conductor,有效地提供了一个更容易的途径。
体系结构概述
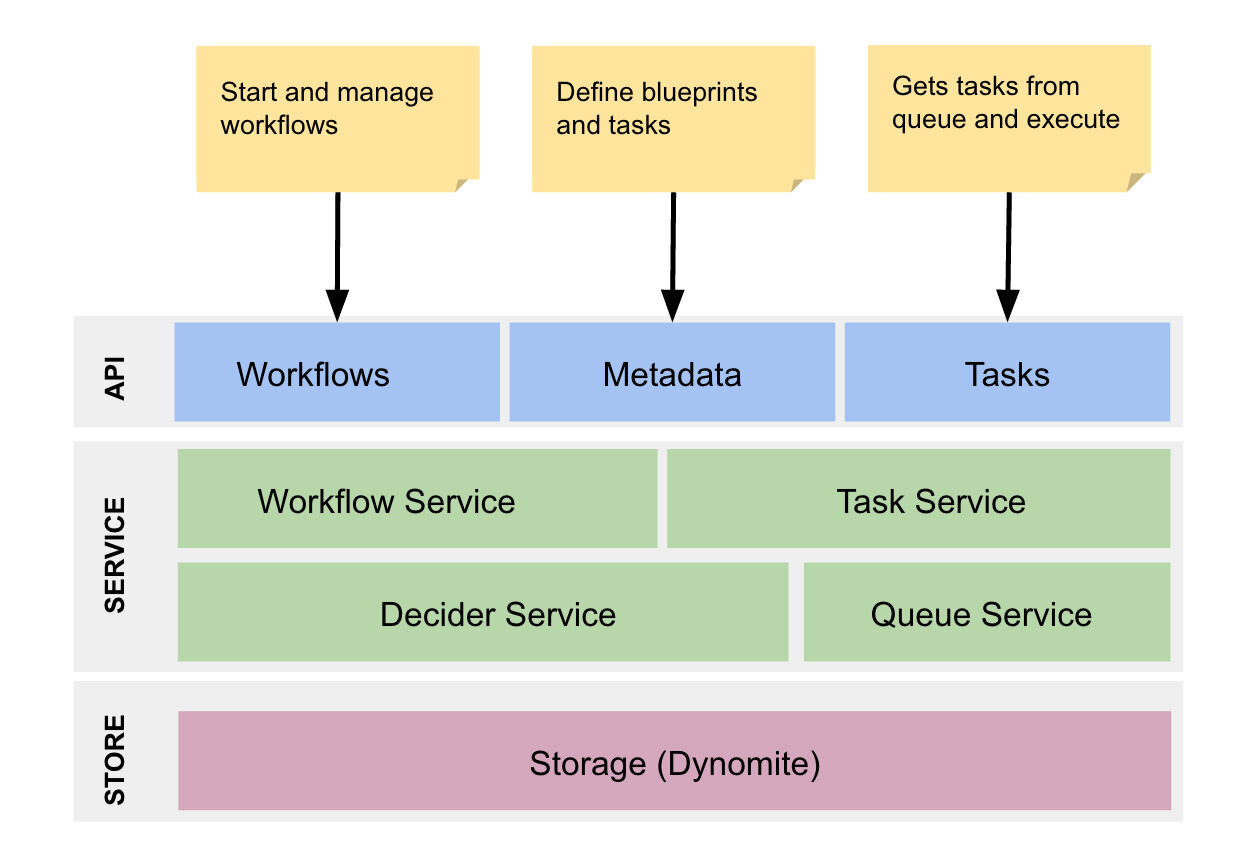
引擎的核心是状态机服务,也称为决策者服务。当工作流事件发生时(例如任务完成、失败等),决策器将工作流蓝图与工作流的当前状态组合,识别下一状态,并编排适当的任务和 / 或更新工作流的状态。
决策者使用分布式队列来管理预定任务。 我们一直在 Dynomite 上使用动态队列来管理分布式延迟队列。队列配方是今年早些时候开源的,这里是博客文章。
任务工作流的实现
由工作应用程序实现的任务通过API 层进行通信。工作程序通过可由编排引擎调用的REST 端点或者通过实现定期检查挂起任务的轮询循环来实现这一点。工作程序旨在实现幂等的无状态功能。轮询模型允许我们处理工作程序的背压,并在可能时基于队列深度提供自动可伸缩性。Conductor 提供API 来检查每个工作负载的大小,可用于自动编排工作程序实例。
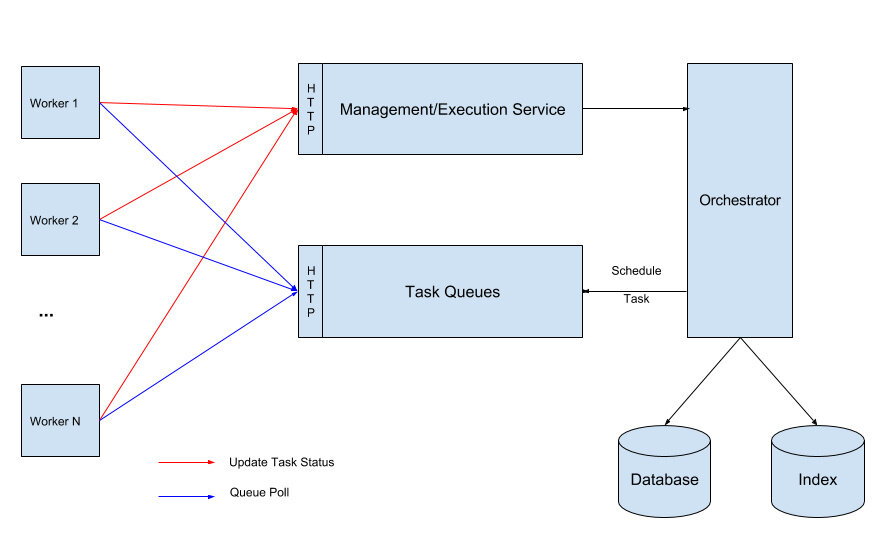
工作程序与引擎的通信
API 层
API 通过 HTTP 公开:允许使用 HTTP 轻松集成不同的客户端。然而,添加另一个协议(例如 gRPC)应该是可能的,而且也相对直接。
储存
我们使用 Dynomite “作为存储引擎”以及 Elasticsearch 用于索引执行流。存储 API 是可插入的,适用于各种存储系统,包括传统的 RDBMS 或 Apache Cassandra,如 NoSQL 存储。
关键概念
工作流定义
工作流是使用基于 JSON 的 DSL 来定义。工作流蓝图定义了需要执行的一系列任务。每个任务是控制任务(例如:fork、join、decision、sub workflow 等)或工作者任务。工作流定义是版本控制的,提供了管理升级和迁移的灵活性。
一个工作流定义的概要:
{
"name": "workflow_name",
"description": "Description of workflow",
"version": 1,
"tasks": [
{
"name": "name_of_task",
"taskReferenceName": "ref_name_unique_within_blueprint",
"inputParameters": {
"movieId": "${workflow.input.movieId}",
"url": "${workflow.input.fileLocation}"
},
"type": "SIMPLE",
... (any other task specific parameters)
},
{}
...
],
"outputParameters": {
"encoded_url": "${encode.output.location}"
}
}
任务定义
每个任务的行为由其称为任务定义的模板控制。任务定义为每个任务提供控制参数,例如超时、重试策略等。任务可以是由应用程序实现的工作任务或由编排服务器执行的系统任务。Conductor 提供开箱即用的系统任务,如 Decision、Fork、Join、Sub Workflows 和允许插入自定义系统任务的 SPI。我们添加了对 HTTP 任务的支持,以便于调用 REST 服务。
一个任务定义的 JSON 代码段:
{
"name": "encode_task",
"retryCount": 3,
"timeoutSeconds": 1200,
"inputKeys": [
"sourceRequestId",
"qcElementType"
],
"outputKeys": [
"state",
"skipped",
"result"
],
"timeoutPolicy": "TIME_OUT_WF",
"retryLogic": "FIXED",
"retryDelaySeconds": 600,
"responseTimeoutSeconds": 3600
}
输入 / 输出
任务的输入是具有作为工作流实例化或一些其他任务的输出的一部分的输入的映射。这种配置允许将来自工作流或其他任务的输入 / 输出作为输入路由到可以对其进行操作的任务。例如,可以将编码任务的输出提供给发布任务作为部署到 CDN 的输入。
用于定义任务输入的 JSON 代码段:
{
"name": "name_of_task",
"taskReferenceName": "ref_name_unique_within_blueprint",
"inputParameters": {
"movieId": "${workflow.input.movieId}",
"url": "${workflow.input.fileLocation}"
},
"type": "SIMPLE"
}
一个例子
让我们看看一个非常简单的编码和部署工作流:
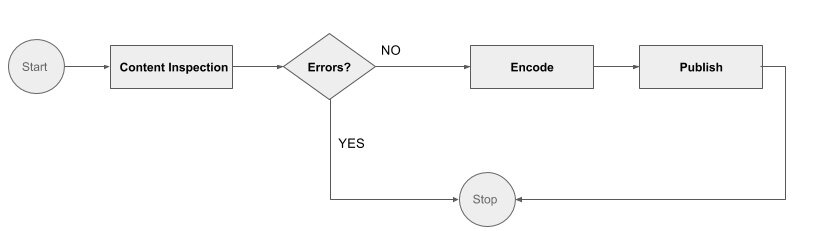
总共有 3 个工作任务和一个控制任务(错误)涉及到:
- 内容检查:在输入位置检查文件的正确性 / 完整性。
- 编码:生成视频编码。
- 发布:发布到 CDN。
这三个任务由不同的工作程序实现,这些工作程序使用任务 API 轮询待决任务。这些是理想状态的幂等任务,它们对给予任务的输入进行操作,执行工作,并且将状态更新回来。
每个任务完成后,决策程序根据蓝图评估工作流实例的状态(对应于工作流实例的版本)并标识要编排的下一组任务,或者如果所有任务完成,则完成工作流。
UI
UI 是监控和故障排除工作流程执行的主要机制。UI 通过允许基于各种参数的搜索来提供对过程的非常需要的可见性,包括输入 / 输出参数,并提供了蓝图的可视化呈现及其所采取的路径,以更好地了解流程执行。对于每个工作流实例,UI 提供每个任务执行的详细信息,具有以下详细信息:
- 任务编排的时间戳,由工作程序及完成时得到。
- 如果任务失败,失败的原因。
- 重试尝试次数。
- 执行任务的主机。
- 提供给任务的输入和完成后任务的输出。
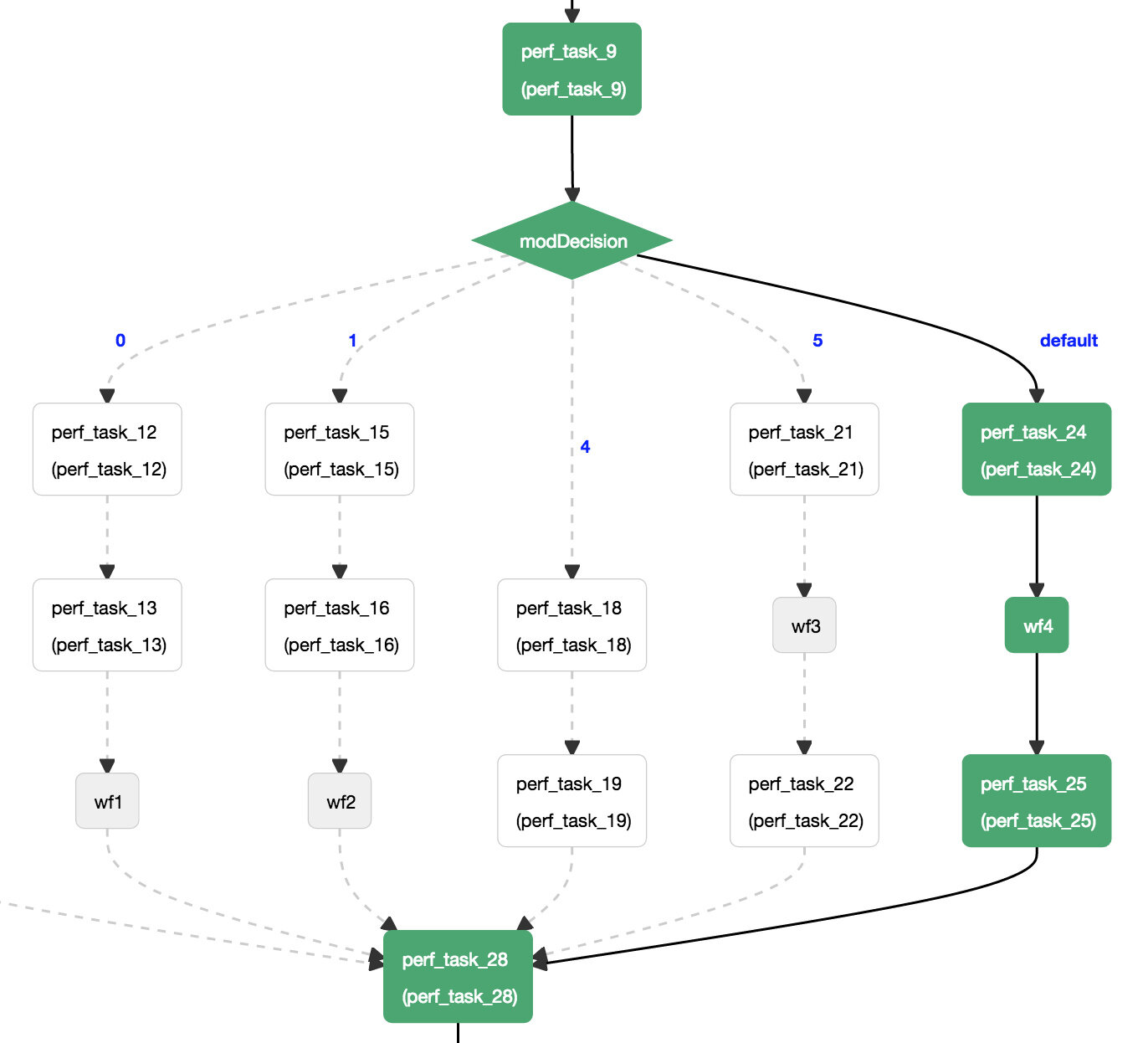
这里是一个来自厨房水槽工作流程的 UI 片段,用于生成性能数据:
其他解决方案
Amazon SWF
我们从使用 AWS 的简单工作流程的早期版本开始。然而,我们选择构建 Conductor 给出了 SWF 的一些限制:
- 需要基于蓝图的编排,而不是 SWF 要求的程序化决策者。
- 流量的可视化 UI。
- 需要更多的同步性质的 API(而不是纯粹基于消息)。
- 需要为工作流和任务建立索引输入和输出,以及基于此来 - 搜索工作流的能力。
- 需要维护单独的数据存储,以保存工作流事件,从故障、搜索等恢复。
Amazon Step Function
最近发布的 AWS Step Functions 添加了我们在编排引擎中寻求的一些功能。Conductor 有可能采用 Amazon States Language 来定义工作流程。
一些统计
下面是一些我们已经运行了一年多的生产实例的统计数据。这些工作流中的大多数被内容平台工程用于支持用于内容获取、摄取和编码的各种流。
Total Instances created YTD
2.6 Million
No. of distinct workflow definitions
100
No. of unique workers
190
Avg no. of tasks per workflow definition
6
Largest Workflow
48 tasks
未来的考虑
- 支持 AWS Lambda(或类似)函数作为无服务器简单任务的任务。
- 与容器编排框架更紧密的集成,这将允许工作实例自动扩展。
- 记录每个任务的执行数据。我们认为这是一个有用的补充,有助于排除故障。
- 能够从 UI 创建和管理工作流程的蓝图。
- 支持 Amazon States Language 。
感谢陈兴璐对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




